




whwunraid
Members
-
Joined
-
Last visited
Everything posted by whwunraid
-
Have a large drive that has issues and needs replaced. Curious if anyone has a per terabyte time for drive rebuilds. Or in this case an 8tb drive. Thanks for your help 😁
-
Was wondering if anyone did a summary of the do's and esp. the dont's of upgrading to 6.9.x as has been done in the past. Bad plugins, unsupported HW now, etc.... Thanks...
-
I have a similar issue when I read the help clip. I assigned a SSD (mistakenly) as a data drive and now need to remove it, thus leaving the slot open for a future drive. I assume same process applies, unassign the drive, do the New Config and Preserve option? Then rerun parity? Is a restart needed, or other steps? Will shares and data remain intact?
-
Yeah that was my 1st thought, new 500GB cache drive and 473GB free..
-
For the last 2 weeks I have been having an issue where Deluge will download torrents just fine then will put any torrent into Pause, existing download or new. It will continue that behavior for a few days and then works fine again. Have rebooted the server, no help, input VPN credentials again and again, no help. So not sure what might be happening here. Log has nothing unusual in it. Any one have this issue lately? Any thoughts as to remedy would be appreciated.
-
In regards to the LANSpeed app mentioned above, if you have a cache drive/pool all this will measure is the speed between that and your workstation, so no matter what share we point it at the results should be the same I would assume. The comment about having all HDDs spun up made me stop and think about that, but I suspect not everyone is using a cache drive/pool.
-
unRAID Play Store - wahoo!!!!
-
I have installed the Calibre Docker and the web interface will not start; I go to the webpage http://ServerIP:8080/#/, started from the unRAID dashboard icon, just a blank page. Not sure why "/#/" is appended on to the web IP? Here are my settings if it helps:
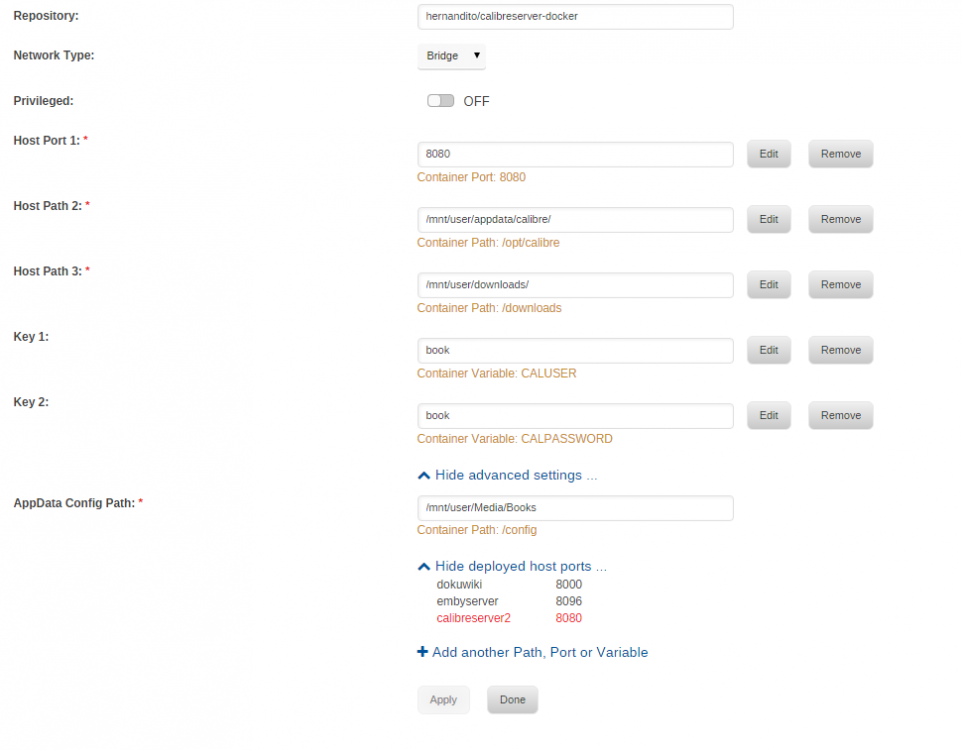
-
My issue is getting LIbrary setup, cannot use UNC paths, it shows me my disks (1-7) instead of shares and when I pick a disk and go to the share it only gets a handful of the items on the share and not all of them. I have the Media share set to split directories as needed so I assume media as spread across the 7 disks. Is this my issue? Why is not allowing UNC paths even though it says you can use them?
-
This would appear to be quite the nice plugin, except I am having the ATA no data shown issue in drive layout that was apparently fixed some time ago. Not sure where to start, the plugin was installed from the unRAID GUI so I know it is current; I'm on version 6.2.4. Any thoughts would be helpful. Thanks...

