





TechMed
Members
-
Joined
-
Last visited
Everything posted by TechMed
-
HI @Jorgen No I did not. I will dig into that now. I am determined to get this working! On the surface, based on the configuration code I've seen so far, this should be rather easy. I guess that's why I'm getting frustrated with PIA. It is a shame too as I like the service...
-
Sorry, I am not well versed in Linux. Where do these files go; (path(es)). /xxxx and on the flash, cache or both? I can do this, just need the pointers. Thanks again!
-
Hi @ICDeadPpl and @Jorgen, We have been very busy with some of C-19 variant cases. Fortunately, they are responding, albeit slowly, to the standard treatments; 99% were not vaccinated. Just saying... Anyway... This is the first chance I have had to relax and try this. ICDeadPpl... I read the README.md and it appears I do not have the required dependencies. When I tried the first line of the instructions, I got 'apt:' command not found. It does not seem to be in NerdPack either. So, if either of you would be willing to help me get these dependencies installed on unRAID, I am pretty sure I can do the rest on my own. BTW, thanks for the simplified fork, and perhaps this is why I couldn't get the 'official PIA' script to complete.? Thanks in advance!
-
HI @Jorgen and @ICDeadPpl, I tried the script linked below, but it would get most all the way to the end and error out. It would be great if I could get it to work! Just got home and I have another 12 to do so I have to put this off until tomorrow or Saturday. I am more than happy to try again. I will post a screen shot of the error. Maybe someone can help me figure out what I am doing wrong? 😉 Stay safe and thanks for the feedback!!! I truly do appreciate it! Talk soon!
-
Hi @ljm42 & @bonienl, I received an "escalated" reply from PIA and... "I understand that you needed a Wireguard configuration file. Please let know that PIA only has a configuration file available for OpenVPN. Wireguard can only be used using the PIA client app." So I guess I'll be switching over to Mullvad. And @Jorgen... thanks for the suggestion I do use, almost exclusively, Binhex's containers. I just want that particular server to be completely in the blind; just makes it easier for me. But, thanks again for the suggestion! Take care everyone. And please, follow the mask and handwashing protocols for just a while longer. Our case numbers are slowly declining almost every day at the hospital where I work. Hang in there... PLEASE and thank you!
-
Thank you @ljm42 for getting back to me. While PIA does provide a 'script', it fails at the end when attempting to get the certificate from them. I tried working with their support, but we've just been running in circles. So, I am looking for a new, functional provider. (I've been reviewing the first posts suggestions) May I ask you for a recommendation please. I would rather go with something that is recommended by someone here, than guessing for myself. Evidenced based information is far better than simply going on faith or guessing. I have been reading over Mullvad and TorGuard, contacted their support, but before I pull the trigger, I'd really like some knowledgeable feedback from our team here. Thanks again for the assist; it always appreciated !!!
-
Thank you @ljm42, I did read extensively here to try to find a good solution. Might I ask which provider you use? Maybe @bonienl as well? PIA does not work, so I am looking for a new provider that truly works. Thanks!!!
-
Has anyone gotten VPN Tunneled Access working? If so, with what provider? Thank you.
-
Hi - can anyone (maybe @bonienl/ @ljm42 ?) help or tell me if there is a PIA config file? At this point ALL I want is ALL the traffic to go through PIA. a.k.a. "VPN Tunneled Access" I had it working fine with the "Remote Access to LAN" and now I want to change it. Any and all help will be greatly appreciated! Thanks! PS. If there is a better option for a VPN provider, I'm all ears for that too!
-
Greetings - read every post here and found nothing regarding PIA. Since I have a good bit of time left with them I would really like to get it setup with them. However, I am open to other providers if there is more secure option! Finally, @ljm42 posted: This may answer my second question. I am fine with all my traffic from this particular Unraid server (server01) going through PIA VPN. I would like to be able to remote IN to my LAN though. Do I just install WireGuard on another server (server02) for that Peer Connection? As always, all feedback/directions are greatly appreciated!
-
Hi @binhex, ( Wireguard and PIA) I just installed WireGuard and it is working nicely. I did this because I really want the access to my network to be secure, but also so that my SabNzbd traffic would flow through it. That does not appear to be the case. I am using your version of SabNzbd and it has worked flawlessly for years; thanks for that! So, if I install your "binhex - SABnzbdVPN", setup my PIA account info within the container, does that mean my NZBD traffic will go through both Wireguard and PIA? Or does Wireguard simply become my replacement for OpenVPN?
-
Thanks for the quick reply! They are and I did change it, but I will try again quick... (15 minute time lapse) I'll be dipped in dog excrement!!! I KNOW I changed it like a week or so ago and it didn't work. Well all I can say is, this is why we do consults!!! Thank you sir, I greatly appreciate your making me look twice. Happy (insert upcoming holiday(s)) 😊
-
Two weeks behind ☹ Hi All, I have read back about six pages, tried all of the suggestions, but since my last container upgrade (see post name), I have not been able to connect with PIA. I have tried the browser interface too, but still no joy. PIA app connects just fine from the desktop thought. Tried both Toronto and Montreal. Attaching what appears to be the most relevant container info as requested in other posts. All help greatly appreciated!!! D-OPVN_Logs.txt
-
no worries... glad you found it!
-
Go back about two pages...
-
Thanks for the suggestion. (for those that do not know where this is, it is under "EDIT", then change the STRICT_PORT_FORWARDING line to say "no" and your all set. I would restart all your relevant containers. It is not an ideal solution, but at least I can now (after almost a week) get back on!
-
Thanks! Works wunderbar!
-
Based on my readings before and after Roxedus' answer, I figured that was the case. However, it never hurts to get a second opinion/confirmation. 🙂 Thanks for taking the time to respond.
-
Hi @aptalca, Since you appear to have a deep understanding of Let's Encrypt, I am wondering if when you have time, you would take a look at this post from earlier? Either I am missing something obvious or I am not using the correct search parameters to find the answer because I have looked for a while now. Thanks!
-
Edit: just realized I inserted my image over the text @jonathanm as directed LE and NC are on the self-created proxy network. However, they are all on the same IP which is that of the server. Is that what you mean?
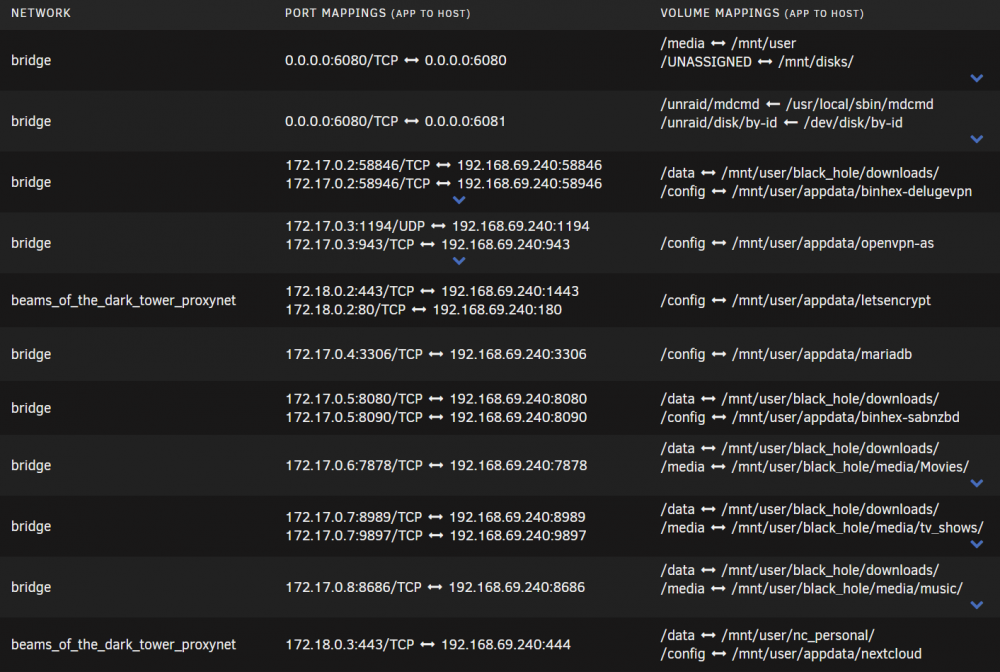
-
@jonathanm 😉that's what I was trying to get at and teach at the same time. BTW... any chance you could shed any light on my question?
-
no problem; wish we could have solved it As Ed makes it pretty straightforward. good luck! maybe post your solution so others that run into the same issue can find an answer.
-
sorry, should have been from this point in the video... If the setup of DuckDNS (the actual DuckDNS container on your server) does not know "subdomain2" exists, it will not resolve and in turn throw a DNS error.
-
Okay... I understand now. Did you add in "subdomain2" to your DuckDNS container as Ed points out here?
-
If you are using his recommended "best" solution, then your mixing up your apples and oranges. The duckdns.org portion is only for pointing to your IP (at your office based on your comments). I am guessing it is setup like "my_office-name.duckdns.org" correct? Assuming you are using your office/company domain name ("best" solution), then you should be able to access your Nextcloud container via nextcloud.my_office_name.com So again, are you using a domain name? (www.my_office_name.com)

