





TechMed
Members
-
Joined
-
Last visited
Everything posted by TechMed
-
In keeping with Ed's (SpaceInvader One's) examples... Are you using your own domain name? This is where Ed talks about putting Sonarr and Nextcloud as subDOMAINs i.e. nextcloud.mydomain_name.com sonarr.mydomain_name.com Or Are you using subfolders off of your DuckDNS account? i.e. mymadeupname.duckdns.org/nextcloud mymadeupname.duckdns.org/sonarr
-
This is where I would go to; assuming your forwarding is setup on your router correctly. Most providers will assist you in getting the DNS (aka: CNAME) setup with a simple chat. I struggled initially with it too. I got on a chat with support and I was up and running in about 10 minutes (takes a few minutes for the DNS to propagate)
-
Does LE utilize a private macvlan? I am trying to figure out why other subnets and vlans cannot access the containers (namely Nextcloud) behind LE. If I understand macvlans correctly, this would explain why I cannot get them all to talk; unless there is a better answer or solution to my issue. Thanks!
-
Hi all, I am looking for documentation or directions (searched G and NC forum) on how to access (LSIO) Nextcloud from a vlan/subnet that is different from the server NC is running on. NC is behind (LSIO) Letsencrypt and works perfectly, both internally and externally, on the server subnet. Server: 192.168.69.xxx Vlan/Subnet: 192.168.169.xxx (note the ‘1”) Need to have the vlan/subnet 192.168.169.xxx be able to get to the NC server. (All other services work perfectly on the vlan/subnet 192.168.169.xxx). Thanks in advance for any direction/assistance.
-
Edit: 02/11/20 @binhex, just checking to see if you'll have any time this week to mess with this. No worrries if not, just checking in. Later... So yeah, I stumbled across them as factory refurb’s, < $200 each, direct from WD, and couldn’t pass them up. Caught six kinds of H@(( for spending the money, but… Plus, I do not have the overhead anymore like you do. Which reminds me, are ‘congrats’ in order yet? ☺️ Okay, I ran the 10TB again anyway, with the command discussed (adding the -A) and it just straight up disappeared at or around the end of the ‘zeroing’ phase. Disappeared meaning, I checked on it (via No VNC) before bed and it was at 86% ‘zeroing’ then I shutdown my desktop. Started up desktop next day expecting to be able to see the end results like before, but there was nothing! No logs, no errors, no nothing. It was as if I never even ran the disk through preclear. That was the morning of February 4. So, I collected diagnostics, drive logs, preclear logs and have them all zipped up and attached. Note: some of the logs include old data from the Preclear Plugin. I am not good enough yet to understand all of the error messages, but there appear to be a a number of them related to UD at the bottom of the “Disk Log Information” log. ****EDIT: It just dawned on me that I think there was an UD update that night. If UD updated, that would have hosed the preclear, wouldn't have it???*** Sorry, not sure I understand. Are you saying here to uninstall UD then run Preclear? Also, I am still not getting any notifications at all. I will try adding my email addy next go round but, Frank1940 had a good idea and asked me to test my SMTP settings, but they worked fine. Dunno? Let me know what you want me to try next and I will get it going using the 10TB. I will post preclear progress when I can; busy end of the week with better availability over the weekend. Diag Zip Files.zip
-
Absolutely no rush at all @binhex, I mean that. When you have the spare time, let me know on the below. Thanks again for all your hard work! ------------------------------------------------------------------------------------------------ Apologies for the delayed reply... Do you want me to use the 10TB drive(s) or something smaller? Yes. I have attached a screenshot of the Disk Settings anyway. Disksettings_01-20.pdf Via Chenbro NR40700 SAS backplane -- SAS connector and cable -- (from Tools >>> SysDevs) IOMMU group 43:[1000:005d] 01:00.0 RAID bus controller: Broadcom / LSI MegaRAID SAS-3 3108 [Invader] (rev 02) JIC you need to know, this MB is a SM X10DRH-CT V 1.1 - Dual Xeon E5-2620 V4 - 64GB - a mix of 14 WD and HGST drives - Crucial MX-500 Cache So, let me know if you want me to test the 10TB drive or something smaller. Also, Is this the command you want me to use?:: preclear_binhex.sh -f -c 1 -A -M 4 /dev/sdX
-
I am happy to assist. Just need a few to get some other things wrapped up. Talk soon...
-
I read this entire thread before starting and it was that post, about it showing up as "msdos" that made me question the result(s). So... just "format" them? Not sure I understand... sorry 🤔 Yup! Pretty anal about those sorts of things. Cool. Thanks for confirming.
-
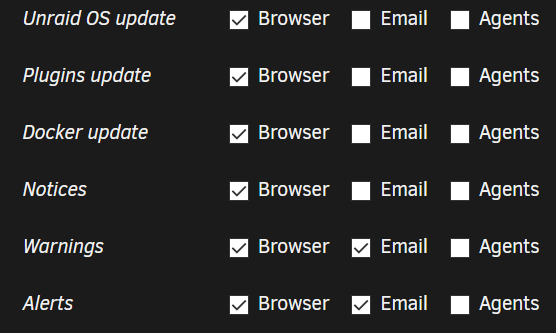
Sorry for the misleading comment; the “62” was just exaggeration for illustration purposes. It was just that I was receiving an annoying amount of emails with the “Notices” via email also turned on. I was just trying to separate the email wheat from the chaff; I have since turned it back on. During my reading on the setup/configuration of the container, I noticed that Dynamix.cfg was being used and I checked it to make sure my smtp email info was in there, and it is. And yes, I did add the two additional Path’s as indicated in the instructions before starting the container and preclear process. I am under the impression that if an email addy is not specified in the preclear cmd line script, that it defaults to the system email, is that correct? Also, this was the output from the “Parted -l” for the two drives: Model: ATA WDC WD101XXXXXX (scsi) Disk /dev/sdp: 10.0TB Sector size (logical/physical): 512B/4096B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags Is this correct, particularly the “msdos” partition table? Finally, is this process like (way) back in the day when you had to run “fdisk” on a new drive before you could format it?
-
It works. Actually, it is because I was getting 62 emails a day that I trimmed what all sent emails in Notification Settings 😉. Here is the output from the Test: Event: Unraid Status Subject: Unraid SMTP Test Description: Test message received! Importance: alert
-
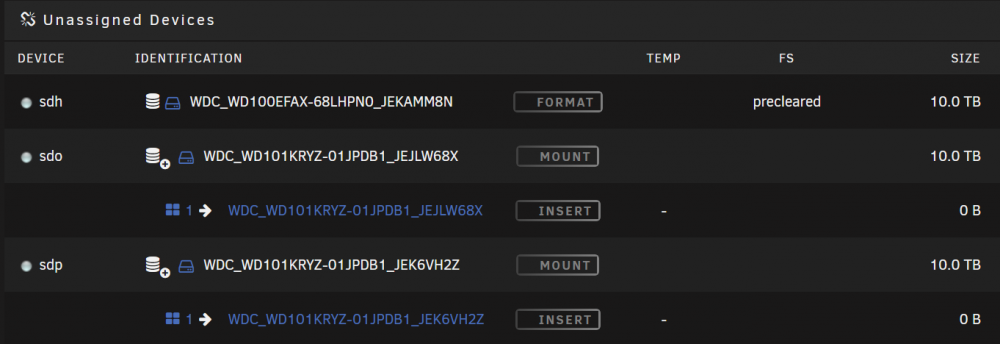
Awesome container @binhex! And, thanks @Frank1940 for the documentation! I cleared two 10Tb simultaneously (took a bit under 50 hours for a single pass) with the following command: preclear_binhex.sh -f -c 1 -M 4 /dev/sdo …(and sdp); ran great! Two questions: 1. I am pretty sure I already know the answer but I just want to be sure: I did not receive any emails, even with M 4 being set. I am betting it is because I have “Notices” turned off under Notification Settings, correct? 2. While the reports (I am ECSTATIC that we can go look at the results well after the fact) indicate the drives both “…[have] been successfully precleared,” it does not show that way in UD. The one showing as “Precleared” in the image below is from a previous run with the preclear PLUGIN, not this container. Thoughts? I am not concerned so long as the drive does not clear again when finally put into the array; not a deal breaker by any means though, just an ugh. So, GREAT job on the container, thank you, and when money for more drives permits, I give the mail option another try.
-
Hi All, This may be a “duh” question, but I am trying to learn and not hose this box’s dialed in setup in the process. So, my question is, should I just change the ip addy/subnet for the LetsEncrypt (LE) container? Background: br0: 192.168.69.0/24 eth2: 192.168.169.0/24 I originally installed LE using the bonded (br0) interface which is working perfectly. I have since added a small 10Gb second subnet (eth2) which includes my servers and one desktop. When I have the desktop on the original br0 subnet, I can access anything behind the LE proxy as expected. When I switch the desktop over to the new eth2 subnet I can do everything BUT access anything behind the LE proxy. Therefore, it seems to me that by simply changing the LE proxy’s subnet to that of the eth2 interface, I should be able to utilize my 10Gb interface on the desktop for everything, including those services behind the LE proxy. However, if I am overlooking a better way of doing this, I am open to suggestions and the ‘why’ so I understand for future needs and having the ability pay it forward. As a sample, here is info from the Nextcloud config.php file and the Docker network: Config.php snippet: 'trusted_domains' => array ( 0 => '192.168.69.xxx:aaa', 1 => 'daxxxxx.aaaaaa.bbbbbbbfe', ), 'dbtype' => 'mysql', 'version' => '17.0.2.1', 'overwrite.cli.url' => 'https://da daxxxxx.aaaaaa.bbbbbbbfe', 'overwritehost' => 'da daxxxxx.aaaaaa.bbbbbbbfe', 'overwriteprotocol' => 'https', 'dbname' => 'dbname', 'dbhost' => '192.168.69.xxx:aaaa', 'dbport' => '', 'dbtableprefix' => 'oc_', 'mysql.utf8mb4' => true, Docker: Thanks!!!
-
No problem at all 😊 @gfjardim. These are spares anyway. Enjoy your trip! Safe travels 👍
-
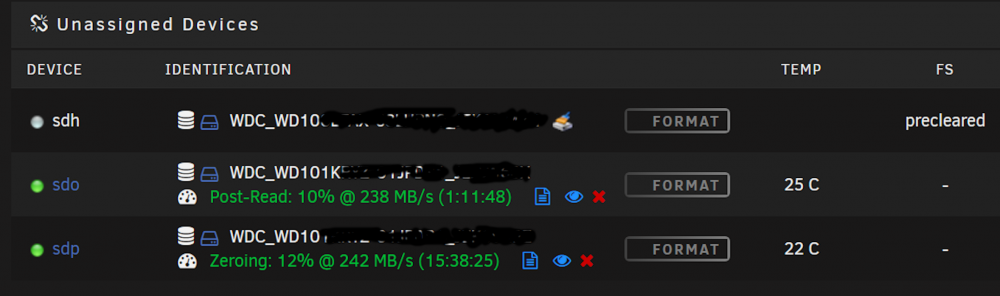
Hello - Having same issue of continuous "Zeroing" while pre-clearing a drive(s) - see attached logs. Notes: - had to pause process and sping down array for network issue. started array and preclear resumed as expected. - two - 10Tb WD sata drives (internal, not USB) - both drive preclear operations started at the same time - watched first drive switch from Zeroing to Post-read (NOTE: first drive initially showed it was starting the Zeroing process again, but then flipped to Post-read and continues to run correctly. Also, noted the following message "unraids signature on the master boot record is valid" when the first Zeroing finished and it started teh Post-read) - watched second drive finish first Zeroing process and start Zeroing all over again - stopped the process on this drive for now and pending feedback Any further thoughts on this? @gfjardim? Thanks!

-
@tazire - Check out CHBMB's post here for your answer. Hope this helps! Have a good rest of your day.
-
Actually, yes. Just not recently.
-
Awww D@#$%!!! I thought for sure I had it figured out... grrrr. Okay, so is there a 6.8.1 build?
-
PLEX throwing error at container startup - "Execution Error: Bad Parameter" d/t the expert tutelage of all of our fine community members (who also do not seem to need any form of sleep! 😴) I was able to figure this error out on my own, and decided to post the solution for others, JIC they run into the same error. Situation: Updated unRAID OS to 6.8.1 and received this error when trying to start the PLEX container: “execution error: bad parameter.” Background: Ran pre-upgrade “Update Assistant” under TOOLS, did everything form there and updated the OS with no OS upgrade issues. Assessment: Since the error indicated “bad parameter” that told me it has something to do with the Parameters set at install and subsequently used by the RUN command (thanks to Saarg for that education in particular). Since I had not changed anything in my PLEX setup, I was able to conclude I was missing something the RUN was looking for. Fix: The missing item was the Nvidia drivers (again!). Reinstalled them (6.8.0 version as there was none listed for 6.8.1) and voila, container is running and no more evil looks/texts from everyone using the Docker. Thanks again to the community for helping me quickly figure out, on my own, how to fix this error! Hope this post helps someone else.
-
Cool! Thanks for the quick response. Have a good day!
-
Thanks @gfjardim I was unaware of the terminal command; I will look into it shortly. I was more concerned about if I completely hosed up the currently running preclear/clear, despite their continuing to chug along nicely. And if the event might prove useful somehow. Based on my readings here this may need to be posted elsewhere, but it would be nice if the unRAID 'clearing' had feedback on the GUI like yours does. Just a thought. Thanks for your help and continuing to support the plug-in. So at this point in time, are we to use the plug-in, assuming we want to of course, or is it being shelved for a bit? From what I have been following here it seems to be still up in the air?
-
Not sure if this is relevant to the discussion, but yesterday I started preclearing two drives and did something stupid shortly after midnight… I updated the plugin in the middle of the process.; rookie move, I know. Needless to say, the preclear halted. So I figured, ‘what the heck, they are new drives’ and put one into the array (the second is being used for Parity so I wanted that thoroughly checked first). At this point I stopped the array, added one of the drives to array and started the array, knowing unRAID would 'clear' the drive for me. Well, the array would not start. Since I had already screwed up from being tired, I quit there and just left everything running as is until today. However, before I hit the sack I noticed that the second drive picked up the preclear process where it left off; array still showing ‘starting’; it is not though. Is this an expected chain of events? Now, looking at the event times it appears that the array did eventually start, but the time indicates it was after the second drive preclear had finished ‘zeroing’ and was starting the 'Post-Read'. Now that the array was finally started, the first drive I had added to the array began the unRAID ‘clearing’ process. To recap, preclearing two drives, updated preclear plugin during, hosed the preclear process, added one drive to array, array would not start, but second drive restarted the preclear process where it stopped (it is currently in Post-Read), first drive started ‘clearing’ about the time when second drive finished ‘zeroing’ and is continuing the unRAID clearing process at this time. As of right now, everything appears to be as it should; we’ll see later today. Should I just let it all finish and see what the end result is? I am posting all this in case there is useful info for anyone. Not sure if the logs are necessary, but attached them anyway. Thanks!!! 5000cca23b05c734.resume 5000cca23b063a1c.resume preclear.disk-2020.01.11b.md5 preclear.disk-2020.01.11b.txz tmux-3.0a-x86_64-1.txz thedarkvault-diagnostics-20200112-1006.zip
-
I read in Binhex's FAQ that the Docker which makes perfect sense. My ponder is if it is seasoned enough. I just need to read the posts about each for a bit. Like most of you, I will probably DL the Docker to my test machine and see how it does. Thing is, while I do not have any issues with using the CLI, there are those that do. Frank1940 made a great point about those that are not comfortable with it: This way folks could copy and paste, for the most part, and reduce the likelihood of trashing one of their existing data drives. Dunno... just need to 'give it a think' and play with it (Docker) for a while. The past couple of days have been a great educational conversation though!
-
Ya know, I wasn’t going to chime in here as I am just beginner. However, like Cybrnook I too There have been a number of occasions where I thank those of you (to an empty room or one of my other personalities 😊) who take the time to write these sorts of programs and keep them up to date. Unfortunately for me, just today I discovered there is a Docker for preclear. Now I need to figure out which to use… plugin or Docker. Does anyone know of thread discussing the pros and cons so I can make a decision on that? 🤔 Again, just my two cents about preclearing and a thanks to a great supportive Community.
-
Question about 'pre-clear' vs 'clearing'. Situation -a 'pre-cleared' drive is now 'clearing' after adding it to the array. Background - bought two ‘renewed’ drives so ran them through pre-clear; one failed “Post Read” while the other completed without error. Sending one back, kept the other Passed drive in the system. Pre-clear is up-to-date and running unRAID 6.8 stable. Question - curious why drive that completed full ‘pre-clear’ is now also doing a 12 hour “clearing’? BTW, I am asking as I have used the pre-clear method for a couple of years now and this is the first time I have come across just 'clearing' or read about it. So, why the ‘clear’ after ‘pre-clear’ and thoughts about whether or not I should be suspicious about the accuracy/longevity of the drive? Reports attached. Thanks all! 13117689437580.sreport.sent 16882006332408.sreport.sent 01-07-19_HGST_8TB_logging.pdf
-
Understood and appreciated (literally and figuratively). As systems start to get larger and more complex, the need for 'graceful' dismounts and shutdowns become greater. I for one am moving towards relying heavily on two of my boxes. I am big into automation, particularly as it relates to healthcare, so stability and reliability become exponentially more more important. Even though many use unRAID as a media storage/delivery platform, losing that data is a big deal as well; just look at some of the near panicked posts people have made because they think it has all gone to Byte Heaven! I have a few ( wink wink nudge nudge) TB myself and would be darn near inconsolable if it went away. Ergo, redundancy, backups, and application of Best Practices, as outlined in the earlier referenced post. Hopefully this info will help someone else in the future. Thanks again to everyone who contributed!





