




deusxanime
Members
-
Joined
-
Last visited
Everything posted by deusxanime
-
I fired up your MKVToolNix container today (I thought I applied an update after shutting it down last time I used it a couple days ago, but can't remember for sure) and it was running but I couldn't connect to the web UI and got this error constantly going in the container log: [emerg] 3758#3758: socket() [::]:5800 failed (97: Address family not supported by protocol) I checked for another update in hopes there was a fix and there was one available, so I applied it. I started it after updating and it just immediately comes to a stop now with this in the container log: [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] 00-app-niceness.sh: executing... [cont-init.d] 00-app-niceness.sh: exited 0. [cont-init.d] 00-app-script.sh: executing... [cont-init.d] 00-app-script.sh: exited 0. [cont-init.d] 00-app-user-map.sh: executing... [cont-init.d] 00-app-user-map.sh: exited 0. [cont-init.d] 00-clean-tmp-dir.sh: executing... [cont-init.d] 00-clean-tmp-dir.sh: exited 0. [cont-init.d] 00-set-app-deps.sh: executing... [cont-init.d] 00-set-app-deps.sh: exited 0. [cont-init.d] 00-set-home.sh: executing... [cont-init.d] 00-set-home.sh: exited 0. [cont-init.d] 00-take-config-ownership.sh: executing... [cont-init.d] 00-take-config-ownership.sh: exited 0. [cont-init.d] 10-certs.sh: executing... [cont-init.d] 10-certs.sh: exited 0. [cont-init.d] 10-nginx.sh: executing... ERROR: No modification applied to /etc/nginx/default_site.conf. [cont-init.d] 10-nginx.sh: exited 1. [cont-finish.d] executing container finish scripts... [cont-finish.d] done. [s6-finish] syncing disks. [s6-finish] sending all processes the TERM signal. [s6-finish] sending all processes the KILL signal and exiting. Tried deleting and re-pulling the container image but no joy. Then tried deleting the appdata mkvtoolnix directory and re-pulling again, but still same thing. Any ideas?
-
Got a chance to try this, though I'm not sure the conditions were clean. Something seems to be bogging down my system, or causing slow write speeds (both to array and cache). But I gave it a try anyway. I copied a ~15 GB file from my array to cache disk(s). Before I started my Load Average (first number since I didn't realize there were 3, not sure what they are for) was hovering anywhere from 1.5 ~ 5. While the copy was going, here's around where it topped out and hovered: load average: 22.64, 19.19, 16.37 I accidentally copied just from array to array as well and saw similar Load Average numbers while that was going on, so not sure if that does anything to help or hinder you, but FYI. Also not sure if something is going on with my system but it seemed to be doing slow copies in general. Copying from array to cache I was only getting 35-40 MBps and array to array was 20 MBps if I was lucky. I know parity calculations can slow down writes to the array, but I still usually got 50-55 MBps previously, and cache should be even faster since there is no parity I would think. It would only be limited by the spinning disk in the array's read speed. edit: Btw, here's my btrfs filesystem show/stats: Label: none uuid: 5130d84d-e43f-45ed-9fa1-5a50be7ab49c Total devices 2 FS bytes used 224.38GiB devid 1 size 931.51GiB used 284.03GiB path /dev/sdc1 devid 2 size 931.51GiB used 284.03GiB path /dev/sdb1 I see there is a Balance Status section and a Balance button below that. Any reason not to use that rather than the command from the previous posts in this thread?
-
Probably not, but you never know. Easy enough to run the balance command just to see what it is at. Anyway, thanks for "thinking of me", I hadn't gotten a chance to create a new thread yet on it!
-
I do have the Dynamix SSD Trim plugin installed and set to run once a week as well, but the balance command they are talking about is new to me. I'll have to give that a try when I get some time this weekend maybe, but these are pretty new drives and not heavily utilized yet, so I would think they wouldn't be pushing up against any limits. Also back when I first was trying rtorrentvpn and ran into these issues it was even less so. Then were only in service for a couple days and just had a few other containers running on them, probably 10% or less used.
-
Yeah looks similar. I posted in there to +1 if nothing else. Would like to remove the old drive I had to put in for a torrent download location that is taking up a drive slot in my server!
-
Not sure if related, but it seems suspect that it could be a similar issue. I am just getting into unRAID and have built a server within the past couple months and have setup my cache pool as BTRFS RAID 1 using 2x1TB Samsung EVO 850s. I bought these large (expensive!) SSDs specifically because I wanted a large cache pool to put torrents and other downloads on so my array disks can be kept spun down, and of course for containers and VMs, all while maintaining minimum foot print and keeping drive bays open for my array data disks. Also, since I'm using such large cache disks where data could potentially reside for a while before being moved to the main array, I wanted to mirror them to avoid potential data loss and downtime if there is a failure. The cache pool is pretty underutilized right now. I have a handful of containers and a few VMs (one active and a couple usually shut off) on there and only using about 20%. I tried running binhex's rtorrentvpn docker container for torrent downloading and immediately ran into problems. I have the container running in appdata which is of course on the mirrored cache pool, and I also setup a cache only "downloads" share to put the torrents in. Running the container by itself was fine, but as soon as I loaded some torrents I would start getting timeouts from the rutorrent web GUI and, even though initially the torrents would seem ok (hitting 3-400+ kbps), in an hour or less though they would basically die off and barely be able to maintain 5-10 kbps. The initial torrents I put on for testing were a few at ~10gb each, so around 25-30gb of data. The first time it happened it did hose up the unRAID web GUI and SSH as well, making them extremely slow, but I was able to get the server to reboot eventually. After that I continued to run into the torrents slowing down to nearly 0 issue, but at least it never caused a complete hang of unRAID itself like the first time. Anyway I posted to binhex's support thread for the container and we weren't able to figure out much. He uses it in a similar way without problem, docker and download location both on cache, but the difference is he does not have it in RAID 1 / mirrored (not sure on filesystem). Playing around though eventually I figured out if I put in another disk and mounted it with unassigned devices, then moved my torrent download location to there instead of the cache pool, all problems were solved - torrents run great and fast (steady, constant 500+ kbps on multiple torrents with no slowdown) and the rutorrent web GUI never gets the timeout messages now. Unfortunately though that means now I have a drive bay taken up by a non-array disk just for torrent downloading, which I'd rather avoid. So not sure how much else I can do, though if you want me to try something non-destructive I might be able to, but wanted to at least +1 that there definitely seems to be something afoot with running a BTRFS mirrored SSD cache pool. At least for me and others in this thread.
-
So the best way to ensure it shuts down in an order we want is to add something like "aaa" to the beginning of names of containers we want it to shut down first, or at least before others?
-
Does the CA Backup/Restore plugin respect the settings of CA Docker Autostart Manager when bringing containers up after a scheduled backup runs as well? Also, when it shuts down containers before running the backup, any chance it does this in reverse? Not only would I like to be sure certain containers come up first, but also they shutdown last. A good example is MariaDB where it needs to be running before things that use it (of course), but also don't want it to shut down first and not be available for containers to do any last writes/flushes to it before they go down. Also, tangentially related, after a scheduled backup runs, what containers does it bring back up? Only those set to autostart, eveything, or only things that were previously running? I have some containers I'm just playing with so they don't run all the time, and wondering if they would get started after a backup completes.
-
I moved the download location to an unassigned drive and started it up again this morning. It ran great all day! I got good consistent speeds with no drop offs after an hour or so like before and the files I was downloading (about 5, each 6-7GB), which had reached less than 30-40% over the last couple days, all completed in a few hours. My issue definitely is downloading to my mirrored cache pool. Not sure if that is due to just the fact that it is mirrored, because the docker container is also running on the cache pool, or a combination of the two. You run the container and download location both off your (non-mirrored) cache drive at the same time as well, correct? Any ideas what may be the issue? If not, I can maybe post in the general support section to see if I can catch the eye of a unRAID dev. edit: Almost forgot to add... also, no "request has timed out" errors in the ruTorrent web GUI that I was getting constantly before.
-
I haven't used iotop much, so I thought that might be the case of it not using 99% of the i/o but still interesting that that means it is waiting as there isn't much going on other than that. 1. I have 64 GB of memory in the system and only a couple used, so that shouldn't be a problem 2. No issues on the disks that I can see. It is my cache pool which is brtfs raid1 of 1 TB samsung SSDs. Both brand new and just bought a few weeks ago for this unraid build and none of the other dockers running on there having issue. No smart errors being reported. I'll dig into syslog a bit more and see if anything, but so far no indication of problems on the drives. I'm wondering if there is something conflicting or that it doesn't like about writing to cache - either the btrfs filesystem or that it is mirrored or something?? I found a port conflict in that openvpn-as also uses port 9443 so I changed rtorrentvpn to use host port 9444 instead, but no help. I thought maybe network issue with bonded (have server motherboard with dual NIC and that was default when I installed unraid), so I removed that and now just using eth0 with no bonding. No joy. Current experiment is I put in a plain drive that will not be part of the array. I'll mount with Unassigned Devices and set that as my download location.
-
OK, good to know. It was probably something with my particular system then. I would have been surprised if something like that slipped through this long, but wanted to be put it out there just in case. Thanks!
-
Not sure if this is expected/known, but just wanted to say... I stopped my unRAID array and while I had it down I figured I'd poke through settings on everything in the web GUI to see if there was anything I wanted to change that I couldn't normally do while the array was up. I tried to open the settings for Recycle Bin and it completely hung up my browser (latest Chrome) tab. I tried reloading the browser just back to my main unRAID webpage, but did not work either. After 10-15 minutes I logged into my server via SSH and poked around the processes. I found the php process trying to open Recycle Bin settings and tried to kill <PID> it, but browser tab was still hung up. The proc stayed around as [defunct] so I found the parent process was the emhttp background process. Killed and and then restarted that with "&" cmd and was able to access the web GUI again. Restarted the whole server from there just to be safe. So FYI, maybe you know this or maybe my system was just acting up, but might need to add check not to do something that causes that hang if the array is down when a user opens RB settings so it doesn't crap out.
-
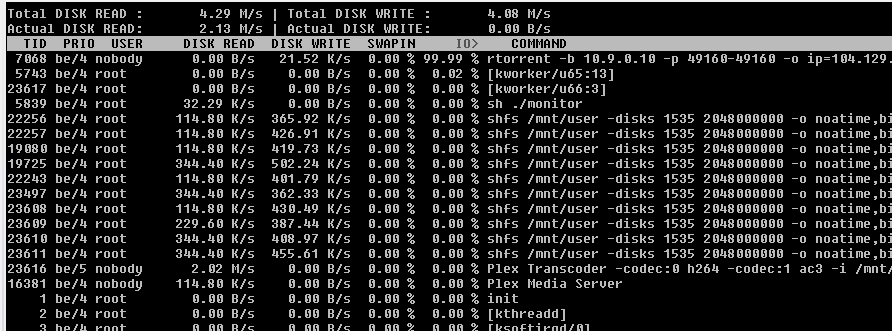
I'd love to figure out what is causing it. Not excited to stand up a VM for what has a nice docker container sitting here available! I don't have an active incoming port because my VPN provider (TorGuard) doesn't have a way to automate that happening. So every time I disconnect/reconnect I get a new IP and would of course have to go in to their webpage and manually change around the requested port to my new VPN IP. I use both rtorrent here (previously on CentOS7) and uTorrent in Windows with the VPN though and have never had a problem with speeds. Downloads go fast enough that they've been close to saturating my connection, such that I don't even bother manually updating the port forwards anymore. I don't think that would be the issue. Even in the docker container I have seen it jump up to very good speeds with multiple torrents hitting 500k - 1Mbps or better, but it doesn't seem to take long and they drop way down to 20kbps if I'm lucky. After some more searching of running rtorrent in a container on linuxserver.io and googling, I've tried a couple things. One is to just delete the container image, remove anything left over in the session folder, and rebuild. Also I've seen suggestions of this being caused by DHT, so I disabled that. Neither have really seemed to improve the performance. Let me know if you'd like to have me upload anything (rc file, logs, etc) to help with troubleshooting. If you can help me figure it out, would save me from having to create a separate VM which would be great. Thanks! edit: poking around and was looking at iotop at the unraid CLI: rtorrent is basically pegging at 99.99% the majority of the time. I'm not sure if that is just a percentage of all activity, in which case it might make sense because not a lot else is going on, or more of overall capacity. Anyway it seems to be chewing up quite a bit. Also in the rtorrent process I see a -p which defines the port I believe correct? But I have a different port defined in my .rc file, so odd it is passed at the command line as well. Is that just done to have a default value and the port in the rtorrent.rc overrides it?
-
Seeing similar performance problems mentioned in linuxserver's rtorrent docker thread. Might be torrenting is just not suited to containers... Though I assume there are many people here who use it just fine? Update on my binhex-rtorrentvpn setup here though. It seems to be running really slow (when it is going). Have some stuff that has been running a few days that is not even half done that would usually have completed overnight easily on my old VM setup. I think rtorrent is constantly crashing and restarting which is also causing the rutorrent timeouts. Of course this just builds up and makes things worse because stuff isn't completing and I keep wanting to add more...
-
Just to +1, I just installed and started using this container today and get the same thing. I was trying to flip through settings to configure and it kept locking up. I'd have to restart the container to get it responsive again. After reading through this thread, I made myself be patient and wait until the orange bar was gone before clicking something new and no more hangs/lock ups. Think I'm going to wait until more stable though before giving out to users and just stick with the request channel for now. Hope he gets the new v3 going soon!
-
Do your downloads write to cache pool, to your array, or to another disk using unassigned devices? If you see my post from a few days back, I've run into some performance issues as well using this rtorrentvpn container and I'm using the cache pool as my download location. Still testing and monitoring, but starting to wonder if torrents would be better suited to a VM than a container.
-
You should be able to add as many mounts/mappings as needed to a docker. When you say restart do you mean unraid or just the container? You may have to tell UD to auto mount the disk is you mean unraid. If just the docker that should survive a reboot and come back if you added it to the definition, as far as I know.
-
I am writing torrents/downloads to a directory on my cache pool which is using SSD, so I don't think I should have any problems with that. I'm only running one VM and the rtorrentvpn docker + its downloads at this point on the SSD so I don't think it should be overworked already either, I would hope. I suppose I could try to move the downloads to a separate SSD mounted with Unassigned Devices, but pretty much out of space on my server so that would be complicated to physically arrange. It actually got worse and I think brought networking to its knees yesterday on my entire unRAID server and had to reboot the whole server. Posted in this thread about it: Since rebooting entire server it has been running ok, though I still get the timeout errors frequently in ruTorrent. Keeping an eye on it for now. As binhex said, I think this is a prime usage for Unassigned Devices. Put in a dedicated non-array drive and mount with UD so that you aren't constantly reading from/writing to entire array and causing drives to be spinning 24/7 (unless you are ok with that, then just put on array somewhere).
-
Is there a way to get this working with VPN providers that aren't PIA or AirVPN? Specifically I use TorGuard. I currently have a rTorrent + OpenVPN client working in a CentOS VM and would like to convert over to a container such as this. It works fine with a standard OpenVPN install and using TorGuard's conf/ovpn file plus ca.crt, so nothing crazy or special. edit: So I just started fiddling with it to see what I could do. Upon adding the container there is an option for "custom" provider which I didn't see documented anywhere (I could have missed it, been skimming lots of stuff). So I selected that and also defined the vpn user/password and changed paths, other settings, etc and started it up. It shut down right away and looking at the log it was asking for an ovpn file in the /config/openvpn directory. I put TorGuard's ovpn file along with the ca.crt (referenced in the ovpn) and restarted. Seems to be working so far, now I need to do some testing to see if it actually is connected and such, but good start! Can I just stop the container now and copy over my previous rtorrent.rc to /config/rtorrent/config (editing paths as appropriate of course)? Or better to configure stuff through the ruTorrent web GUI? edit2: Verified VPN working with http://ipmagnet.services.cbcdn.com/ (I like that one better than TorGuard's IP checker), all is good! Now just to sort out config of rTorrent itself. edit3: OK I think I have the config all figured out. OpenVPN is configured for TorGuard using ovpn file and that is good as I said before. Container started, then I stopped and configured rtorrent.rc, and started again. ruTorrent works and I can connect. I can then add torrents and they download. BUT, it seems once I add some torrents and they start downloading (sometimes just 1 or 2 even), then I start getting "The request to rTorrent has timed out." errors in ruTorrent. Sometimes it seems to recover, other times I have to restart the container to get connected again. Any thoughts/ideas? edit4: After a bit more testing/playing, if I let it sit it does seem to reconnect after a while, basically once all the torrents have completed downloading. Having downloads in progress though seems to kill the connection between ru- and rTorrent or something.
-
Ouch thanks for the heads up. Guess I'll leave it off for now and turn it on later once things have settled in.
-
Just building my first unRAID and copying TBs of data to it. Would it be best to wait until all data is copied over and then run the Build? Or should I just enable it right off the bat and let it compute checksums as stuff is copied to the array? Any major perf hit by just turning it on now and having it start doing its thing while I copy data? Also I'm copying the files in SSH screen by using unassigned devices mounts and cp direct from my previous NTFS drives directly to the /mnt/diskN/share locations. Does it still compute the checksum when moving files around this way rather than via SMB shares and such?


