




Froberg
Members
-
Joined
-
Last visited
Everything posted by Froberg
-
Config has been set to disallow local logon, so connection gets refused. Still the same result using 9444 instead of 444.
-
444 is nextcloud. 8083 is the test-wordpress. # curl https://192.168.1.101:444 curl: (35) OpenSSL SSL_connect: SSL_ERROR_SYSCALL in connection to 192.168.1.101:444 Using linuxserver nextcloud container.
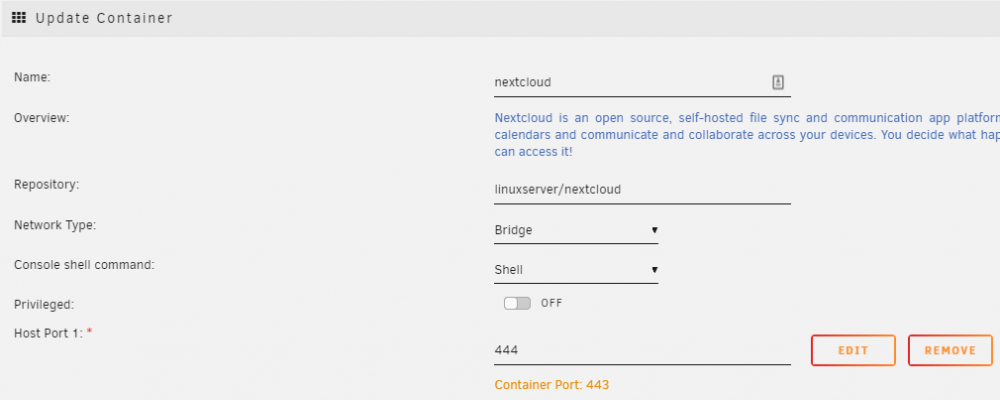
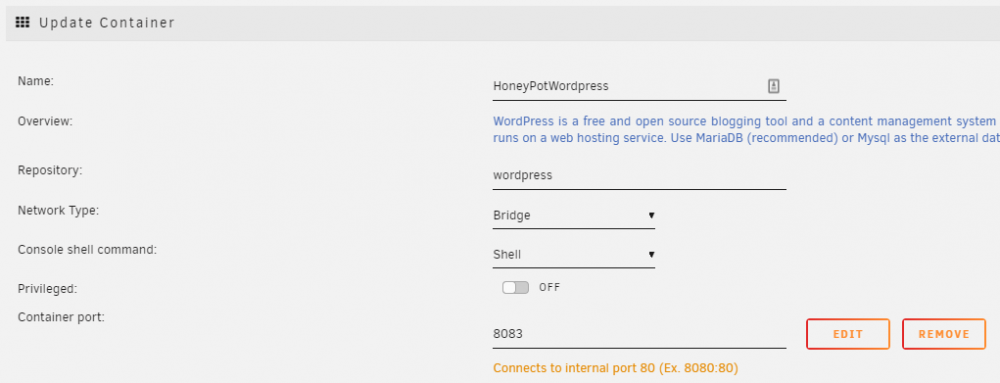


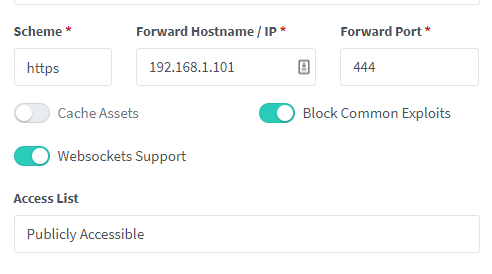

-
As nothing has been typed, both NPM and the Nextcloud container are in bridge mode, I don't see how I could input anything manually. The nextcloud container should forward all http requests to https. (As should NPM, by the way.) Here's doing it to the root IP: # curl http://192.168.1.101 <html> <head><title>302 Found</title></head> <body> <center><h1>302 Found</h1></center> <hr><center>nginx</center> </body> </html> # curl https://192.168.1.101 curl: (60) SSL: no alternative certificate subject name matches target host name '192.168.1.101' More details here: https://curl.haxx.se/docs/sslcerts.html curl failed to verify the legitimacy of the server and therefore could not establish a secure connection to it. To learn more about this situation and how to fix it, please visit the web page mentioned above. Here's connecting to the wordpress container that I set up to test - and the nextcloud docker respectively on both http and https: # curl https://192.168.1.101:8083 curl: (35) error:1408F10B:SSL routines:ssl3_get_record:wrong version number # curl http://192.168.1.101:8083 # curl https://192.168.1.101:444 curl: (35) OpenSSL SSL_connect: SSL_ERROR_SYSCALL in connection to 192.168.1.101:444 # http://192.168.1.101:444 sh: 13: http://192.168.1.101:444: not found But url's from the outside result in bad gateway though: 502 Bad Gateway openresty I'm sure I'm just missing something obvious but I've tried so many different configs now that I've lost count trying to get this working again.. and it HAS been working previously.
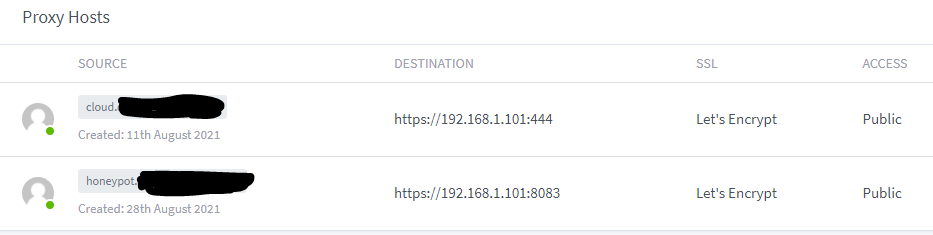
-
I tried that for my issue; # curl http://192.168.1.101:444 curl: (3) Failed to convert 192.168.1.101 to ACE; could not convert string to UTF-8 # curl https://192.168.1.101:444 curl: (35) OpenSSL SSL_connect: SSL_ERROR_SYSCALL in connection to 192.168.1.101:444 Any ideas on what's going on here?
-
Just to sanity-check I changed both containers to br0 and gave them dedicated IP's. Nothing worked. Now changed both back to bridge and I'm getting bad gateway. I don't see from your table how that should be the expected result. I tried booting up a wordpress container and that also gets bad gateway.
-
Okay I give up. I've had NPM working for ages now, but suddenly I'm having issues. I've been changing networks and setup so much that it's laughable at this point and I'm probably only making myself confused at the moment. NPM > NextCloud is the goal. Current setup: Current forwarding rules: Using a random domain to test I get a refusal because HSTS is enabled, so presumably NPM is getting the traffic. I tried using NPM on bridge instead, but that resulted in Bad Gateway. I tried setting up a wordpress container to see if my Nextcloud install was b0rked - but that can't be reached, either. Clearly it's some simple mistake doing all this. As mentioned I've tried various config changes and I even tried putting both NextCloud & NPM on the same network to no avail. Again I probably screwed something up even worse by just trying a slew of different things.. I'm fairly sure I didn't use to have NPM on a dedicated IP either.. but here we are. Please advise as I'm sure it's simple and I've just gone and FUBAR'ed it. Been trying to bring it back after some DB corruption due to a MariaDB update erroneously made me think my old NPM setup was the cause and I rebuilt it.. clearly not well enough. So it's been.. a while.. now.
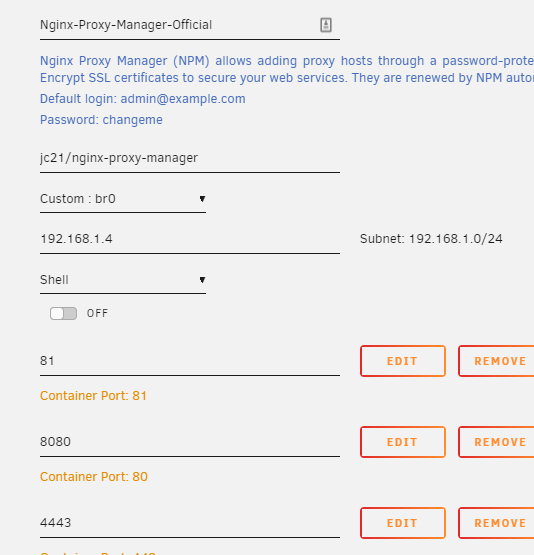


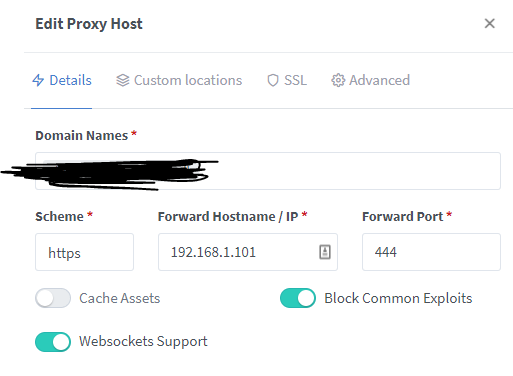

-
I'm sure there can be a myriad of other factors at play.. just figured since I've done nothing to change the container, other than adding a few more folder-mappings, that it might happen to others, too. After removing 600+ seeding torrents and restarting the container, it immediately re-added them all again. So I had to remove the .torrent files manually in the appdata directory too. Here's hoping it doesn't happen again. It's been rock solid otherwise.
-
Fair warning for anyone who manages to read this before updating. My transmission update today resulted in the nulling of all download locations, immediately triggering a few TB's of downloads before I caught it. Not sure what went wrong, all my settings seem to be there, but the "move to x folder" history was lost and everything was reset to the standard downloads folder.
-
Agreed.. been unsuccesful thus far in reviving it.. 502 Bad Gateway. The DB is up, as I could upgrade it through console, which I assume required DB connectivity.. so I'm a bit stumped atm.
-
"Fix" worked for me, at least I can access the db through phpmyadmin again. Nextcloud is still b0rked though. Have to get some rest, but specifically the fix that worked in my case: And then switching to :latest.
-
Never happened yet. Even replaced my dual 250G drives with dual 1TB drives just to eliminate that the drives themselves were faulty. Never at risk of running out of space on cache now, not even with large data ingress.
-
Hi all All issues I've had running UnRaid, without fail, for the last few years, has been down to the RAID1 cache in my system. I am, once again, moving everything off the cache, suffering the Docker downtime because of it, and reformatting. It's taken all day so far. (Plex has soooo many files..) I am pondering splitting up my two 1TB drives and simply using one as an "unassigned device" as a backup location or even a hotswap if the primary drive fails. I have yet to have an SSD die on me though, so it's doubtful anything should happen.. I've just had so many issues by now and it's frustrating to keep restarting and spending days of time relocating files in the process. Any thoughts on this? Am I alone in suffering these corruption and filesystem problems with the RAID1 cache under BTFRS?
-
Cheers mate. Reading your suggestion made me realize "hey, it wasn't that tough setting up in the first place.." so I just changed the folder and started over. Back up n' running. Thanks for the help though!
-
Help please. I just moved everything away from cache to replace my dual 256G drives with dual 1TB drives. Everything seems to have transferred nicely, but nginx is broken - and as a consequence as is my Nextcloud instance. nginx: [emerg] cannot load certificate "/etc/letsencrypt/live/npm-5/fullchain.pem": BIO_new_file() failed (SSL: error:02001002:system library:fopen:No such file or directory:fopen('/etc/letsencrypt/live/npm-5/fullchain.pem','r') error:2006D080:BIO routines:BIO_new_file:no such file) Is what it's saying in the log file. I assume I must have lost something in transit. I tried removing the container and re-adding it, hoping that would help resolve it. So what do I do? Transfer any necessary configs, remove the old directory and start over? Please advise I'm a bit out of my depth on this one.
-
I just use the update button in the unraid interface. I've never actually seen an update inside the webUI.
-
I posted a bit above you about this exact same issue. No response. Have you gotten it fixed? I hate that it keeps resetting itself to Google. I don't want to use Google.
-
Can someone tell me why or how the DNS settings keep resetting themselves to google? I actively avoid Googles DNS and it's frustrating to log on and find that it's been using google again for weeks. Is there something I can do. Is it a bug that it just resets the DNS provider?
-
It takes a while to index the files before transferring starts usually. An hour seems like a long time though.
-
How many remote files can the clients see?
-
I know. But this is automated
-
Got this running now. Is it possible to have it just keep a copy of the flashdrive backup in .zip format instead? I like that it's at least ON a disk this way, but having a few copies wouldn't hurt, either. Or maybe it's unnecessary and I'm making it overly complicated.
-
Maybe use something like nginx proxy manager to pass through to it. Assuming you have static IP and a domain of course.
-
Flash stick creation aside, it's entirely likely you'll never want to use anything else ever again. (famous last words) I even have two licenses now. I have tried everything else out there. UnRaid, by and large, just works. As for USB. 2.0 is basically required, as is a low capacity drive like 2-8GB in size as preferred. Quality drive, too. Other than that, yes, they really need to fix this utility.
-
I really fear this is causing a hindrance for some people who are new to UnRaid.
-
That would be exactly how my own nextcloud container is running. Not sure how you'd get it to do that in the first place. Maybe it's a nextcloud config issue. i set up sub.tld.dom for mine and it works just fine.













