




Froberg
Members
-
Joined
-
Last visited
Everything posted by Froberg
-
I had that setting, yet my piHole had grown to 22+GB's. I removed it entirely and fixed the issue. I did, as I mentioned, have that log max-size setting enabled.. I have it for all my docker containers actually since Plex misbehaved one time. Anyone actually investigate the root cause? I have been noticing that piHole has essentially been blocking nothing in the WebUI. Updated configuration instructions or something, maybe?
-
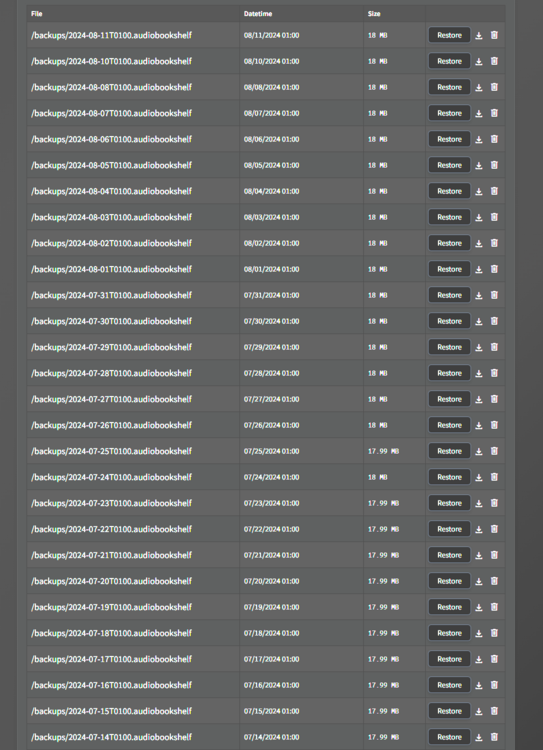
Huh, just randomly checked my settings and noticed that the backups aren't pruning. They're set to ten days but so far I have multiple years available at this point.
-
I'm the sort who doesn't want to subscribe to something for home-use. So either way, the lifetime license is the only thing for me. I recently downsized my UnRAID use from two to one system. However, I would like to be able to contribute to development other than the one time I buy my license. I notice a few people shrinking from the cost due to regional income levels being lower than they are in the US. If I could support development and make someone else happy at the same time, I'd certainly consider doing that. Maybe a lottery type thing where people who want to renew, but can't for whatever reason, can enter and then we can buy a license and it'll get allocated randomly or something. That could be neat. Then I'd help someone out who is less fortunate, and still give a bit of cash to UNRaid, because I do get a lot of mileage out of the OS.
-
Maybe you guys could try to use the extra parameters I'm using on the container.. might be helpful. --memory=2G --restart=always --log-opt max-size=50m --log-opt max-file=1
-
Seems obvious now.. that did indeed fix it.
-
I frequently see the red warning "Socket failed to connect" - but it's yet to cause any actual usage or access problems.. so I've elected to ignore it. I use the app maybe ten hours a week on average. Sometimes much more.
-
@Poprinfollowed your recommendation. My previous strategy of having a secondary unraid box which was booted when I remembered to wasn't working for me. This seems like a viable option. I lost a ton of space though, since the syno could take fewer drives and more were lost on the RAID type. Guess I'll need to toss larger drives at it before I get a working backup again. But it works very well it seems. Very quick to set up.
-
Eh it's not depreciated.. but I get your point from the description. It helps if you're unsure of what to delete. I usually just do terminal to remove appdata folders. But yes, remove your old appdata directories or install in to a new one and you should be good.
-
Just get "Cleanup appdata" from the appstore.. Works well for what you need.
-
Domain helps a lot with self-hosting frankly..
-
I use nginx proxy manager to set up a remote connection with.
-
I use mp3tag to sort files as well as tag them/embed data in them. I haven't had any problems doing so. At all.
-
It's not a general issue. I never touch my install and don't have any issues.
-
Considering you already mentioned using mp3tag, just use that. It works beautifully when using audible for data.
-
Asking here if anyone's actually using it.. Genea was Updated on Mar 23, 2022 last.. doesn't exactly inspire confidence. The issue tracker doesn't appear to be getting responses. Abandonware, or?
-
This sounds like my original issue, where the Noctua fans I had populated my case with were operating at too low RPM's, so the IPMI on the motherboard panicked and made them run full-bore - so the noise floor when up, down, up, down, up down.. irritating to say the least. I raised the minimum fan speed to a fairly high level, but considering it's Noctua fans they're still silent. That made the IPMI shut up. Maybe check if you have events in IPMI concerning fan errors that's how I clued in on mine.
-
Yep, that did it. Cheers!
-
Read the release notes for 6.12. Uninstalled old plugin. Updated OS. Installed this. All settings and options blank pages. Tried uninstalling and re-installing a few times. Where to begin? Even my config you've asked for above seems much shorter. root@FortyTwo:~# cat /boot/config/plugins/ipmi/fan.cfg FANCONTROL="enable" FANPOLL="24" FANIP="" HDDPOLL="24" HDDIGNORE="" HARDDRIVES="enable" FAN_FAN1234="607" TEMP_FAN1234="4" TEMPHI_FAN1234="65" TEMPLO_FAN1234="50" FANMAX_FAN1234="80" FANMIN_FAN1234="39" FAN_FANA="875" TEMP_FANA="138" TEMPHI_FANA="65" TEMPLO_FANA="50" FANMAX_FANA="80" FANMIN_FANA="39" root@FortyTwo:~# Any advice?
-
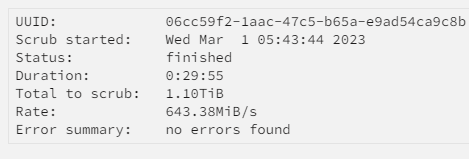
So I woke up early this morning, had to go pee, checked my phone and UnRAID had notified me of corruption on my cache pool again. It's been a long while since I last had an issue with BTFRS - the proposed problem back then was my memory but I was never able to find any faults with it. Of course it has to happen the one time I'm away on vacation.. but that's just a law of nature at this point I built an entirely new server and everything seemed to be going OK, until today. I set up the userscript to monitor as recommended by JorgeB.. Output: root@FortyTwo:~# btrfs dev stats /mnt/cache [/dev/sdb1].write_io_errs 0 [/dev/sdb1].read_io_errs 0 [/dev/sdb1].flush_io_errs 0 [/dev/sdb1].corruption_errs 6 [/dev/sdb1].generation_errs 0 [/dev/sdc1].write_io_errs 0 [/dev/sdc1].read_io_errs 0 [/dev/sdc1].flush_io_errs 0 [/dev/sdc1].corruption_errs 8 [/dev/sdc1].generation_errs 0 Scrub didn't see anything: Which just seems.. odd. So as per Jorge's recommendations I used btrfs dev stats -z /mnt/cache and am now rebooting with my fingers crossed and my cheeks clenched. Please advise! fortytwo-diagnostics-20230301-0534-anon.zip
-
Works fine on my 'droid..
-
Can we send you a few $$$ yet? You've saved my daily commute, must contribute beer or coffee or just discretionary funds.
-
nerdtools, isn't that depreciated?
-
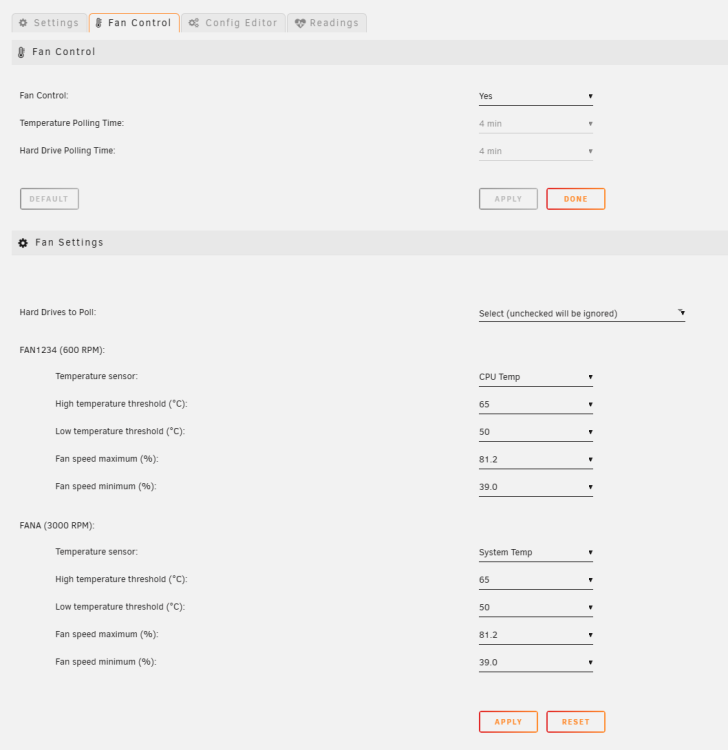
Assuming you actually installed the plugin already... These settings work for me.
-
Yeah that works. Was worried about fan noise but raising the floor to 39 it remains silent under load.. so yay.
-
Hi guys I'm running a SuperMicro board and it doesn't like my Noctua fans, they run too slowly. I've adjusted the curves in the config file to 200,300,400 for lower thresholds - as recommended by SuperMicro themselves (if unsupported) but that just floods the system with fan-speed errors and makes them sound like they're starting and stopping constantly. As it is, I have to set it to "full speed" to not have fluctuations in noise levels. Not sure how to go about fixing this any more. Here's what SuperMicro wrote: IPMI FAN thresholds: Linux: $ sudo ipmitool sensor thresh FAN1 lower 200 300 400 Locating sensor record 'FAN1'... Setting sensor "FAN1" Lower Non-Recoverable threshold to 200.000 Setting sensor "FAN1" Lower Critical threshold to 300.000 Setting sensor "FAN1" Lower Non-Critical threshold to 400.000 $ sudo ipmitool sensor thresh FAN5 lower 200 300 400 Locating sensor record 'FAN5'... Setting sensor "FAN5" Lower Non-Recoverable threshold to 200.000 Setting sensor "FAN5" Lower Critical threshold to 300.000 Setting sensor "FAN5" Lower Non-Critical threshold to 400.000 Now as I said, I modified the FAN values I could find in the config and set the fan-profile in IPMI (SuperMicros own) to "standard" and it just kept start/stopping the fans. Please let me know if anyone has a solution to this, other than not using Noctua fans.



