




RobertP
Members
-
Joined
-
Last visited
Everything posted by RobertP
-
WOPR - UR1: 126TB on my backup server (holds backups of multiple family systems), 11 data disks, 2 parity drives. using 75TB (at peak backup time) Xeon E3-1230 [email protected] memory. (Yes, some drives bays are not plugged in the picture. Some are empty, some contain pre-cleared empty drives that I can plug in on a failure or emergency.) WSPR - UR2: 18TB on my file server (holds shared files between family's systems), 3 data disks, 2 parity (overkill on parity!). Only using 4TB at present. i7 11th gen 32gb memory
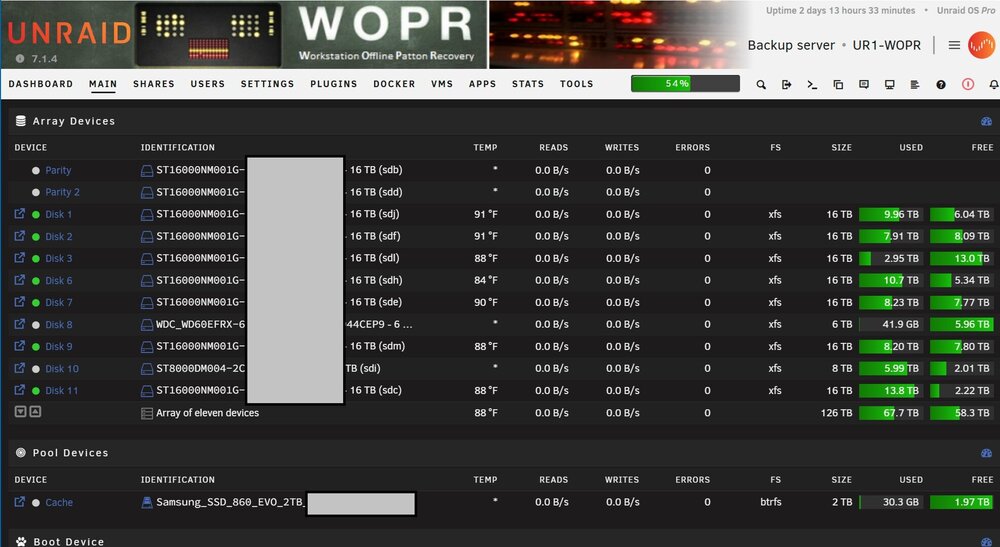
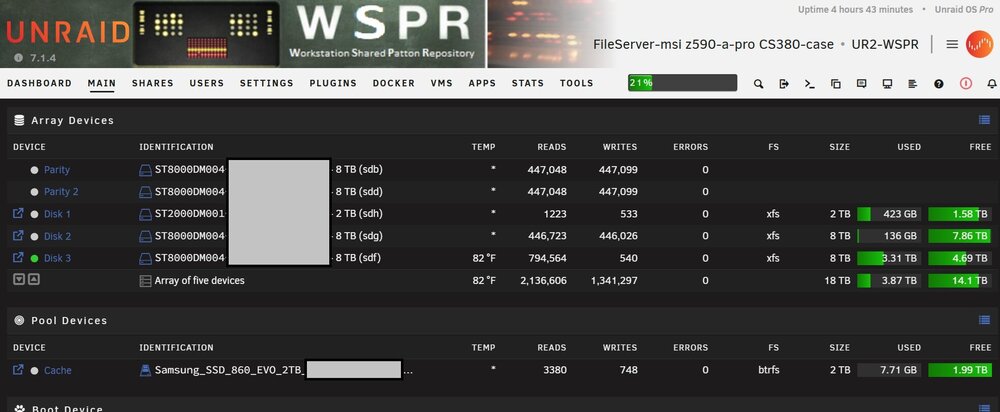


-
Odd – on one system, Tools/Update Assistant reported no issues. I did the upgrade (a couple days ago) to 7.0.0 with no issues. Controlrd works fine. i7 11th gen 32gb memory. 3 drives plus 2 parity (5 total) for 18TB. Other system, a few days later (today), ran Update Assistant and it warned about Unbalanced and ControlRD. I de-installed both, did the upgrade (and rebooted of course) and reinstalled both, and they work fine. Xeon E3-1230 [email protected] memory. 9 drives plus 2 parity (11 total) for 126TB. Both running UnRAID OS Pro.
-
What if I have NO certs on my unRAID? Will I now need to set up a CERT? I've never done CERTIFICATES on home system, would not even know where to begin, what is process, is there a cost, etc, etc, etc. Can I continue to use the new version withOUT a cert? (And what is the value of having a cert?)
-
Working good for me also. Thanks for the fast fix. Bob
-
I understand, no rush. Don't kill yourself by debugging all day . . . lol ! I'll just keep ignoring the msg until you get a fix posted. Bob
-
See attached diag from both servers. Thanks, Bob ur2-wspr-diagnostics-20240428-0953.zip ur1-wopr-diagnostics-20240428-0954.zip
-
More on the error: I have no dockers running and I have no VMs running. My disk timeout is set to 90, same as it always has been. I did have Dynamix's Directory Cache plugin, which Fix-Common-Problems just reported is not compatible w newest unRAID. I de-installed the Directory cache, and have rebooted twice, but the error remains. Attached are my "syslog-previous" files. UR1-wopr-syslog-previous-2024-04-28 unclean shutdown.txt UR2-wspr-syslog-previous-2024-04-28 unclean shutdown.txt
-
Following the most recent update of Parity Check Tuning (2024.04.27), I'm now receiving an "Unclean shutdown detected". Doesn't matter if I do a shut-down or a reboot - the msg shows up the next time I log in. Happening on both my unRAID servers. If it matters - my Parity Checks run monthly on the evening of the 1st of the month - so I have NOT run a parity check since the update. Also rcving msgs that SAYS it kicked in an "Non-Correcting Parity Check" (zero errors), but I have not seen it actually running whenever I've looked. My larger system Parity check usually takes a couple days (16TB), but this "Non-Correcting" check only took 2.5 hrs!? The smaller system parity check usually takes 16 hrs and that matches the time for that system's "Non-Correcting" check.
-
I appreciate the new process, but I think you forgot about (or haven't gotten around to it) an item I suggested a while back (Limetech "liked" the post). I'd still like to see this added to the update process. Here's a copy of my post from July 3, 2023: It is so easy to forget to manually make a backup of a flash drive prior to an OS UPDATE. Granted, with the RESTORE button, one often does not need to use the manual FLASH BACKUP, but it is still a wise thing to do. For example, I had issues with the most recent backup, and the RESTORE option did not work. I ended up having to reformat the flash drive and used the FLASH BACKUP to get back up and running. To assist us, can you either: 1) Add an (optional) flash-drive backup to the UPDATE OS process OR 2) At least add a prompt to the UPDATE OS process – something like: “If you do not have a recent flash drive backup, we suggest you cancel this update and do a flash drive backup (click MAIN tab, the click FLASH, then click FLASH BACKUP and save the ZIP file to your PC). Once complete, begin the UPDATE OS again. CANCEL update CONTINUE update (I need to do a FLASH backup) (I already have a recent FLASH backup) BTW – in the FLASH BACKUP, it would be nice if you included the version in the filename. For example: ur1-wopr-flash-backup-20230703-0052-ver6_12_2.zip
-
Am I confused/mis-understanding something? Am I thinking of a different field? Or is this a bug? (Actually, even if I’m confused, I feel there IS a bug here.) THE ISSUE: MINIMUM FREE SPACE for a share unRAID 6.12.3 Drives in share formatted with xfs HISTORY I used a 3rd party backup program to back up my home PCs. I have the backup program (Macrium Reflect) write the backup files to a share on my unRAID server. YEARS AGO, I had the backup program write each backup as one big file. This caused issues – if unRAID started to write to drive 1 of the share, and that drive only had 1TB free, and the backup file ended up being 1.5TB, the backup would fail due to running out of free disk space on that drive since the one big file could not straddle two physical drives (even if both drives are in one share). I WAS TOLD to do two things: 1) Tell my backup software: Write the backups out in “chunks” (CHUNK is my word for it, that’s not the technical term!). I chose 250GB (yea, I played it overly conservative, bigger chunks would probably be easier to keep track of!). 2) Tell unRAID: Use the MINIMUM FREE SPACE field to tell unRAID to NOT write to a disk within a share if that disk has less than xxGB free – instead pick another disk in the share to write to. This way, no matter what unRAID allocation method was used (high-water, most-free, fill-up) and no matter what the disk size, unRAID would not try to put what MIGHT be a huge file onto an almost full drive. I think I did 500GB (or was it 1TB? Either way, I gave myself extra “elbow room” over-and-above the “chunk size” of 250GB) This worked great for years. THE PROBLEM DETAIL: I recently upgraded to unRAID 6.12.3. Not sure if this issue started with this version or an earlier version. Since the backups have been working OK, I have not looked at that share definition in a long time. I just now looked at the share definition that holds my backups. The MINIMUM FREE SPACE field now has a percentage, not an absolute number. I tried changing it back to a number: 500GB. I hit enter, and it changes that number to 500000000 (a.k.a. 500,000,000), just like it used to. But then it changes it to a percentage!?!? And the percentage does not make sense (to me). This share is made up of 4 physical drives: 12TB (currently 1.3TB free) 12TB (currently 2.6TB free) 6TB (currently 2.81TB free) 16TB (currently 15.2TB free) I put 500GB (or 500 GB) in the MINIMUM FREE SPACE field, and unRAID eventually turns it into 25.6% I don’t see ANY situation using ANY of those numbers above (max individual size, total size, free size) where 25.6% equals 500 GB!?!? If I put in 1000GB (also tried 1tb or 1TB or 1 tb or 1 TB), it expands the number to 1000000000, but then it changes it to 51.2%!?!?!? So is that saying if the entire share is more than half full, a file will not be written? Or if an individual drive is more than half full, a file won’t be written to that drive? That makes no sense at all – 1TB does NOT equal 51.2%!?!? Is this simply a formatting error of how that field is displayed? How can I be sure what the actual value is? Or is unRAID actually doing a bad calculation? FYI - In the attached diagnostics, the share that I'm working with is named: UR-BU-i9 BUT I tried some other shares and they are also showing a similar issue - MINIMUM FREE SPACE is being converted to a weird percentage. ur1-wopr-diagnostics-20230717-2002.zip
-
BTW - in case you have not already done this: Another important thing I found out about using Macrium to put backup's to unRAID - make sure you specify file size maximum! In My Macrium backup definition files, I went into ADVANCED OPTIONS, FILE SIZE, and put a FIXED FILE SIZE of 250GB. This saves the backup file as several files in 250GB chunks instead of one huge single whopping big file (the filenames are numbered, it is easy to see which file goes with which set). If you just do one big file, there is a risk it might fill up one disk and abend instead of putting part on one disk and then jumping to another disk in the share for the other part(s). Then, on the unRAID share, in the MINIMUM FREE SPACE, I put 500 GB. At least I think that's what I put, it was either that or 1000GB (to give myself some "elbow room"). Unfortunately, the most recent unRAID upgrade changed this value to a percentage (for example: 30% instead of xxxGB)! I tried changing it back to the absolute GB value, but it keeps reverting back to a BIG percentage! I'll be posting to the developers to see if there's a way to keep the setting at GB). In case you want to follow it, my report of this MINIMUM FREE SPACE bogus percentage issue has been posted. The subject is: MINIMUM FREE SPACE CHANGES TO A (BOGUS(?)) PERCENTAGE
-
Not sure if I'm understanding the issue, but I've been using Macrium to backup one unRAID server to another unRAID server for quite a while. Yes, I realize there are unRAID backup tools that would backup from one unRAID to another (and would cut out the middle-man - my Windows PC), but I prefer to use the same backup tool for all my backups (Macrium Reflect). I have a share on my unRAID: UR2-i9 In that share I have a folder: winGprog On my Win11 PC, I have a map: G: (\\UR2-WSPR\UR2-i9) In Macrium, I ADD SOURCE FOLDERS: \\UR2-WSPR\UR2-i9\ For my destination (a 2nd unRAID server): \\Ur1-wopr\UR-BU-UR2-WSPR-SELECT\UR-BU-i9-G-i9unique\ And on that 2nd unRAID, I have a share: UR-BU-UR2-WSPR-SELECT under that share I have a folder of: UR-BU-i9-G-i9unique Note that I don't actually use the drive G: mapping in Macrium, I use the UNC names. Also note that it becomes a FILE & FOLDER backup, NOT an IMAGE backup. A but slower, but it still works. This is because the Windows PC does not "own" the unRAID share, so it can't trust the file flags on the unRAID since it has no control over those flags (or so I assume) - so it has to scan/compare the files to see what has changed as part of the actual backup. Macrium backs it up with ALMOST no issue. The only issue I've run into, Macrium apparently has a maximum number of file/folder items it can "keep track of" - if I try to back up my entire drive F: (on same unRAID server, set up similar to above, but has MUCH more data), Macrium fails. So what I had to do was set up 4 backups of F: that ONLY grabbed certain root folders (and below folders). And then on the 5th F: backup, I select all folders EXCEPT for the previous 4. (Again, I used the UNC names in Macrium, not the F: map letter.) Unfortunately I do not know the "breaking point" - it was a matter of a trail and error. Originally I only had to do two chunks, but as I added more and more stuff, I've had to break it up to where I now have 5 chunks (5 different backups for the drive F: share).
-
Thank you JorgeB!
-
On the DASHBOARD tab, can you give us control over the columns that appear in the SHARES tile? In particular, I would like to see the PROTECTION STATUS ICONS in the SHARES tile on the DASHBOARD tab. But I suspect others might like to be able to turn on/off other columns in that tile. On the MAIN tab, can you include the SMART icons for each drive (like it appears in the ARRAY tile on the DASHBOARD)? Thanks, Bob
-
It is so easy to forget to manually make a backup of a flash drive prior to an OS UPDATE. Granted, with the RESTORE button, one often does not need to use the manual FLASH BACKUP, but it is still a wise thing to do. For example, I had issues with the most recent backup, and the RESTORE option did not work. I ended up having to reformat the flash drive and used the FLASH BACKUP to get back up and running. To assist us, can you either: 1) Add an (optional) flash-drive backup to the UPDATE OS process OR 2) At least add a prompt to the UPDATE OS process – something like: “If you do not have a recent flash drive backup, we suggest you cancel this update and do a flash drive backup (click MAIN tab, the click FLASH, then click FLASH BACKUP and save the ZIP file to your PC). Once complete, begin the UPDATE OS again. CANCEL update CONTINUE update (I need to do a FLASH backup) (I already have a recent FLASH backup) BTW – in the FLASH BACKUP, it would be nice if you included the version in the filename. For example: ur1-wopr-flash-backup-20230703-0052-ver6_12_2.zip Thanks, Bob
-
I tried to do upgrade from 6.11.5 to 6.12.2, Same problem * Tried capturing log to flash drive. * Upgrade – OK, Boot – OK * Runs for a while, then just disappears (no GUI access, no data access, not in active IP list). * Concerning the log on flash – after crash, powered down unRAID, put flash in PC, no SYSLOG file. * Did “safe to remove” USB from PC * Put back in unRAID, kept failing in boot (after “waiting up to 30 sec for device with label UNRAID to come online . . .” or after next line of “random: crug init done” (not sure of spelling)) * Powered down unRAID, put USB back in PC, did quick format and then recovered USB from ZIP backup. * Booted up to 6.11.5 OK * Let run for a bit, no issue. * Set up syslog to FLASH, to a share on this unRAID, and to a share on another unRAID. * Tried upgrade again: upgrade OK, boot OK * Ran for a while – eventually noticed on dashboard that CPU cores were intermittently maxing out even though nothing was going on with server. Eventually it froze/disappeared again. * Powered down, put USB in PC, SYSLOG file was corrupt (unable to view nor copy), Windows said problem w drive. * Did Windows scan & repair to USB drive, able to copy SYSLOG. * Put back in unRAID server – boot failed (same place as earlier). * Put back in PC, did full format and recovered from ZIP backup. * Booted up fine to 6.11.5 Attached: * Syslog-from flash after WIN repair to USB (from flash on problem server) * Syslog to share on problem server – failed, NO FILE, NO ATTACHMENT. * Syslog-192.168.50.13 – problem server’s log mirrored to other server * one image of boot failure - not really worried about this since seems unrelated but attaching in case anyone is curious. syslog-from flash after WIN repair to USB.txt syslog-192.168.50.13.log
-
I just upgraded both of my unraids to 6.12.1 (from 6.11.5). One server has been fine. But the other server: * Upgrade appeared to be good * Rebooted, came up fine * Able to log in to GUI and to get to data * It ran for a while (an hour or two?) and then just “disappeared”. Still had power/drive lights, but disappeared from network. Unable to get to data, unable to log in to GUI. * Only recourse was to hard boot it. It seemed to come back up fine. * I was able to log in to GUI, I was able to get to data. * Since it has been hard-shut-down, it kicked in a parity check. * It ran for a while and then just disappeared again. Drive lights stopped flashing so not only was it gone from network (no GUI access, no data access, not showing in active IP list), that implies the parity check also stopped. * Once again, only recourse was a hard boot. * It again appeared to come up fine, I had GUI access, I had data access. * It, of course, started the parity check again. But I noticed instead of the normal 16 hr estimate, the estimate was floating from 2 days to 28 days – back and forth with various different LONG estimates. * I watched it for a while, I was able to grab some screen shots of the log. Other than the long estimate for parity speed, it seemed to be OK. Oh – I also noticed the log had a lot of “took longer than …” msgs for unassigned devices. * I had to step away, and when I came back it was running WAY slow, and then it eventually disappeared again (no GUI, no data access, no drive light flicker from parity check, gone from my active IP list). I was not able to see nor save the final log entries. * I had updated all plug-ins prior to upgrade. VMs and Dockers were NOT started. I ran the UPDATE ASSISTANT and FIX COMMON PROBLEMS prior to update - they came up clean. For now, I’ve restored 6.11.5 on this server. I also shot a video of this server’s boot-up for 6.12.1, but it is 105MB so I have not uploaded it. If you feel it might be helpful, let me know. UR2-WSPR log screen shots.docx ur2-wspr-diagnostics-20230627-0136.zip
-
Solved Since I had de-installed Krusader, I was able to delete all left-over occurrences of Krusader folders on CACHE and DISK3. The SYSTEM files on DISK3 – I renamed them (rather than deleting them – just in case). I then ran MOVER – it moved the DISK3 renamed SYSTEM files to CACHE and deleted them from DISK3. I’ll let them sit on CACHE for a bit in case any issues come up, and then will probably delete them. MOVER now runs instantly once again when there are no files to move, no more 10 minute lag and when I temporarily turned on MOVER LOGGING it was clean. DISK3 no longer has any APPDATA nor SYSTEM files. I re-installed Krusader, it is running fine.
-
I’m a little confused about your comment about disk1/prefer. We have to assign every share (including appdata and system) to a disk, there is not an option (that I see) to assign it to a disk of CACHE. If I leave the disk selection of the appdata share blank, it defaults to ALL, which I don’t want. If cache does fill up, I want to control and know where appdata ends up. But since I have it set to PREFER, it is basically going to ignore that disk location anyway (right? – unless, heaven forbid, my cache drive fills up). I’ve attached the diagnostic info. Bottom line, you concur that I SHOULD be able to safely delete the KRUSADER files on disk 3 since KRUSADER is current no longer installed, correct? Ditto for the APPDATA folder on disk 3 – it will be empty after above, so can safely delete it. But for the items in SYSTEM folder, I’ll have to compare the CACHE version to the disk 3 version to try to figure out which is current (I’m guessing cache version is current, but . . . I’ll have to do some digging to be sure). ur1-wopr-diagnostics-20230505-1158.zip
-
UnRAID 6.11.5 MOVER issue with APPDATA and SYSTEM on cache: I’ve capitalized some names here just to make them stand out – but on the system they are in lower case as normal. I’m having a problem with MOVER on one of my unRAID servers. When there is nothing to move, it still runs for 10 minutes. (By that, I mean the only things on CACHE are APPDATA and SYSTEM folders, nothing else.) I have both APPDATA and SYSTEM set to DISK 1 and CACHE PREFER, so it should not even be trying to move those items. I turned on mover logging, and saw it was trying to move a LOT of Krusader files. I tried setting appdata to CACHE YES and running it a few times – no fix, no change I tried setting it to CACHE NO and running it a few times – runs instant, but no fix when I put it back to CACHE PREFER. I re-ran mover several times under CACHE PERFERE no change, still takes 10 min and still tries to move Krusader. I should note that Krusader is NOT active during all of these tests. Also, Krusader is the only docker I currently have installed on this unRAID server (I did have another docker installed a while back for RGB lighting, but I de-installed that ages ago and no longer have RGB lighting running.) I went to SETTINGS, DOCKER and set it to NO. I then went through the above tests again: MOVE with appdata set to CACHE PREFER – multiple runs. MOVE with appdata set to CACHE YES – multiple runs. MOVE with appdata set to CACHE NO – multiple runs. MOVE with appdata set to CACHE PREFER – multiple runs. (I have not attempted a MOVE with it set to CACHE ONLY.) No changes, MOVER still runs long and tries to move Krusader files. I re-enabled DOCKER, and de-installed Krusader. I then ran through the same tests again. I then disabled DOCKER and ran through the same tests again. No success. MOVE still runs long and tries to move Krusader files. Right now, on the CACHE drive, there is a binhex-krusader folder even though that tool is no longer installed. APPDATA is set to DISK 1 with cache set to PREFER. (same for SYSTEM share). On disk 1, there is no APPDATA folder (and no SYSTEM share). On cache, there is an APPDATA folder (and a SYSTEM folder.). Inside APPDATA is a BINHEX-KRUSADER folder. Inside that are more folders and files. Under the SHARES tab, if I do a COMPUTE for APPDATA it shows there is data on CACHE and DISK 3. As far as I recall, I never had it located on DISK 3, though it could be possible. SYSTEM folder is also on CACHE and DISK 3. (And, of course, the COMPUTE option shows both of the disk 3 shares are outside the list of designated disks.) I just now noticed the LOG file shows it is trying to move KRUSADER from DISK3 – did not see that before. In the log, most lines are white, some are yellow, some blue, some red – but it flies past so quick that I have not been able to catch why the color difference. It LOOKS like they all say “ …file exists”, but it is flying by so fast I can not be sure. The log file is so big and moves so fast, and once done I can only scroll back part way. Is there a way to save the ENTIRE log file to a file so I can look through it more closely? Or a way to pause the log screen display? Since I now see there is a duplicate(?) SYSTEM and APPDATA folder on disk 3, I’d like to verify that it is only DISK 3 that is involved in the MOVE. Disk 3 contents for these two shares: Disk3/system/docker/docker.img (4/29/2023 06:18) Disk3/system/libvirt/libvirt.img (2/12/23 16:46) Disk3/appdata/Binhex-krusader folder Inside that is PERMS.TXT and SUPERVISORD.LOG and a HOME folder with LOTS. (at a QUICK GLANCE, all files/folders appear to be from 2022.) On cache: Cache/system/docker/docker.img (4/27/2023 2:21) Cache/system/libvirt/libvirt.img (4/27/2023 2:22) Cache/appdata/binhex-krusader folder Inside that is PERMS.TXT and SUPERVISORD.LOG and a HOME folder with LOTS. (at a QUICK GLANCE, all files/folders appear to be from 2022.) On disk 1 – neither SYSTEM nor APPDATA show up. My thought is to delete all KRUSADER folders EVERYWHERE since it is no longer installed. But I’m not sure what to do with the other folders/files on DISK 3 – delete them? MOVE them to CACHE (that is, overwrite what’s in CACHE)? How do I tell which version is actually being used (the cache version or the disk 3 version). I have CA BACKUP / RESTORE APPDATA plugin installed. I’ve checked its settings: Source: /mnt/cache/appdata/ Destinations: /mnt/disk10/backupappdata, /mnt/disk10/backupflash/, /mnt/disk10/backuplibvert/ So there are no mis-named locations there. (Why does BACKUP/RESTORE not have a place to put a SOURCE for SYSTEM?) Below are the last few lines of the LOG file – and I now notice that MOVER is trying to move not only /mnt/disk3/appdata/binhex-krusader . . . But also /mnt/disk3/system/ . . . I was able to grab a quick screen print of the front of the log file to see if there is anything showing up before the KRUSADER files –it starts with: /mnt/disk3/appdata/binhex-krusader/home/.build/gtk/config/.gtkrc-2.0 So it would appear the only items are those disk3 folders. . . . MANY more similar entries before this . . . Apr 30 23:06:07 UR1-WOPR move: move_object: /mnt/disk3/appdata/binhex-krusader/home/.themes/Ultimate-Maia-Blue-light/gtk-3.0/assets/[email protected] File exists Apr 30 23:06:07 UR1-WOPR move: file: /mnt/disk3/appdata/binhex-krusader/home/.themes/Ultimate-Maia-Blue-light/gtk-3.0/gtk-dark.css Apr 30 23:06:07 UR1-WOPR move: move_object: /mnt/disk3/appdata/binhex-krusader/home/.themes/Ultimate-Maia-Blue-light/gtk-3.0/gtk-dark.css File exists Apr 30 23:06:07 UR1-WOPR move: file: /mnt/disk3/appdata/binhex-krusader/home/.themes/Ultimate-Maia-Blue-light/gtk-3.0/gtk.css Apr 30 23:06:07 UR1-WOPR move: move_object: /mnt/disk3/appdata/binhex-krusader/home/.themes/Ultimate-Maia-Blue-light/gtk-3.0/gtk.css File exists Apr 30 23:06:07 UR1-WOPR move: file: /mnt/disk3/appdata/binhex-krusader/home/.themes/Ultimate-Maia-Blue-light/LICENSE Apr 30 23:06:07 UR1-WOPR move: move_object: /mnt/disk3/appdata/binhex-krusader/home/.themes/Ultimate-Maia-Blue-light/LICENSE File exists Apr 30 23:06:07 UR1-WOPR move: file: /mnt/disk3/appdata/binhex-krusader/home/.gtkrc-2.0 Apr 30 23:06:07 UR1-WOPR move: move_object: /mnt/disk3/appdata/binhex-krusader/home/.gtkrc-2.0 File exists Apr 30 23:06:07 UR1-WOPR move: file: /mnt/disk3/appdata/binhex-krusader/home/novnc-16x16.png Apr 30 23:06:07 UR1-WOPR move: move_object: /mnt/disk3/appdata/binhex-krusader/home/novnc-16x16.png File exists Apr 30 23:06:07 UR1-WOPR move: file: /mnt/disk3/appdata/binhex-krusader/perms.txt Apr 30 23:06:07 UR1-WOPR move: move_object: /mnt/disk3/appdata/binhex-krusader/perms.txt File exists Apr 30 23:06:07 UR1-WOPR move: file: /mnt/disk3/appdata/binhex-krusader/supervisord.log Apr 30 23:06:07 UR1-WOPR move: move_object: /mnt/disk3/appdata/binhex-krusader/supervisord.log File exists Apr 30 23:06:07 UR1-WOPR move: file: /mnt/disk3/system/docker/docker.img Apr 30 23:06:07 UR1-WOPR move: move_object: /mnt/disk3/system/docker/docker.img File exists Apr 30 23:06:07 UR1-WOPR move: file: /mnt/disk3/system/libvirt/libvirt.img Apr 30 23:06:07 UR1-WOPR move: move_object: /mnt/disk3/system/libvirt/libvirt.img File exists Apr 30 23:06:07 UR1-WOPR root: mover: finished Thanks in advance for any guidance/tips/suggestions. Bob
-
Thanks to all who tried to help. Someplace along the line I must have missed a "parity is valid" check box, so I was unable to do the rebuild. I was able to save a lot of the data first (copied it to my other server), but the two drives that "died" - their data was lost. Luckily it is a server that I only use to house backups of the household PCs. And I was able to get the server back up and running, and I am back to my normal backup routines. It has not been running long enough to verify it is fully stable, but I did replace all the SATA cables, so far so good (knock on wood!) All of the drives that "died" in this server - I was able to put them in my other server and do preclears successfully on all of them. If this server starts flaking out again, I'll try replacing the SATA card. If problems persist, I guess I'll try replacing the drive cages.
-
Sorry for the delay - got side tracked by a "little thing" called Hurricane Ian. (We are OK, no major damage to our property.) How can I re-enable parity2? I don't see anything obvious to me. I realize I could change it to NO DEVICE, reboot, and then put parity2 back to same drive, but I'm afraid the system will then zero out that drvie and try to rebuild parity - and remember that the initial problem is I already have TWO data drives being emulated. (Not sure how TWO can be emulated with only ONE active parity drive!?!?) Can you give me step-by-step on how to re-enable parity 2 (hopefully without losing any data)? Thanks, Bob
-
I swapped out a failed APC UPS with a smaller CyberPower UPS. But the UPS Settings still shows the original Back-UPS NS 900m. I assume that means unRAID will mis-identify the run-time (the new UPS is a CyberPower ST625U) and may not initiate the shut down soon enough. How can I get the unRAID UPS setting to properly identify my new UPS? I've tried disabling and re-enabling the APC UPS Daemon. I've tried disabling daemon, unplugging the USB line, rebooting, re-enabling and then plugging in the USB cable (this is how I understand the manual instructs me to identify the UPS) - but it still sees it as a Back-UPS NS 900M. Or is there a different Daemon/plugin/etc that I should use for CyperPower UPS?
-
Here are the reports with the serial numbers intact. As a reminder - the sequence of events: * Started mover, disk 6 & 8 "failed" immediately. * Took screen shot * Ran and downloaded Smart reports on "bad" drives * powered down, pulled out 6 & 8, replaced w new spare drives (already pre-cleared) * powered up, started rebuild. * Parity 2 died right at start of rebuild. * Canceled rebuild * ran and downloaded smart report on parity 2 * ran diagnostics report a day(?) later (thus the two "bad" data drives were no longer in system for DIAG report). SO - screen shot is from BEFORE parity 2 drive died. If I were to take screen shot now, 6 & 8 would show "emulated" (triangle icon) and parity 2 would show disabled (red X). I have NOT tried reading any data since these two issues occurred. It does seem odd that the rebuild did not cancel itself when it was trying to rebuild 2 drives with only 1 parity drive . . . I have NOT had a chance to pull this beast off the shelf to check cables and SATA card yet. I have tried putting parity 2 drive in various different slots - no change. (Server has 4 drive "cages(?)" w 5 drives slots each - I tried slots in various different cages). If I remember correctly, all SATA cables come off of one "daughter card" - but I did not build the unit and have not been inside it in a long time, so my recollection of the cabling is a bit hazy. So it MIGHT be possible a couple may come directly off of motherboard??? I have thought about replacing the daughter card (SATA card) and cables in past due to odd intermittent things. Any suggestion on a good 20 drive daughter SATA card and cables? System is Intel(R) Xeon(R) CPU E3-1230 v6 @ 3.50GHz motherboard in a full tower case. ST16000NM001G-2KK103_ZL2P6T1L-20220922-1149.txt ST16000NM001G-2KK103_ZL28QVDG-20220922-1155.txt ST16000NM001G-2KK103_ZL28QVAG-20220926-1324.txt
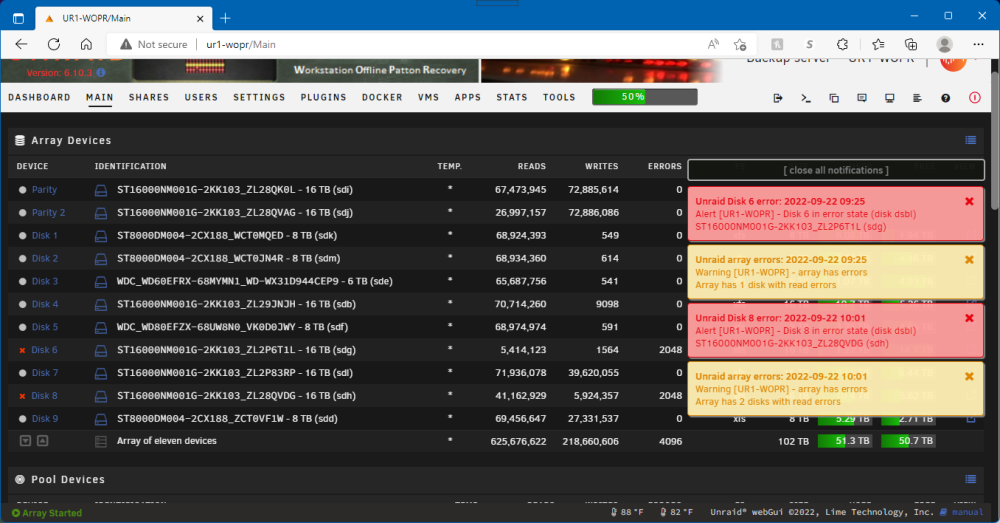
-
Screen shot was from right after 2 data drives failed - before I started rebuild. Parity 2 failed soon as I started rebuild, so screen shot is from before parity 2 death.






