




jaylo123
Members
-
Joined
Everything posted by jaylo123
-
I know this is an old thread, but I just changed ISPs and had to make some upstream firewall changes. UnRAID's docker containers stated this and force-updating the first container, then doing a full check resolved this. Unraid v7.1.4
-
Yea, doesn't work. Fresh install. Logs just contain the following: started 240711 as root (amd64-prod) init: account with the user id 99 already exists init: updating filesystem permissions PHOTOPRISM_DISABLE_CHOWN="true" disables permission updates Problems? Our Troubleshooting Checklists help you quickly diagnose and solve them: https://docs.photoprism.app/getting-started/troubleshooting/ file umask....: "0002" (u=rwx,g=rwx,o=rx) home directory: /photoprism assets path...: /opt/photoprism/assets storage path..: /photoprism/storage config path...: default cache path....: default backup path...: /photoprism/storage/backups import path...: /photoprism/import originals path: /photoprism/originals switching to uid 99:100 /opt/photoprism/bin/photoprism start /opt/photoprism/bin/photoprism start /opt/photoprism/bin/photoprism start Here is what I see. It "refused" to connect, which tells me it is responding but won't serve any web traffic:
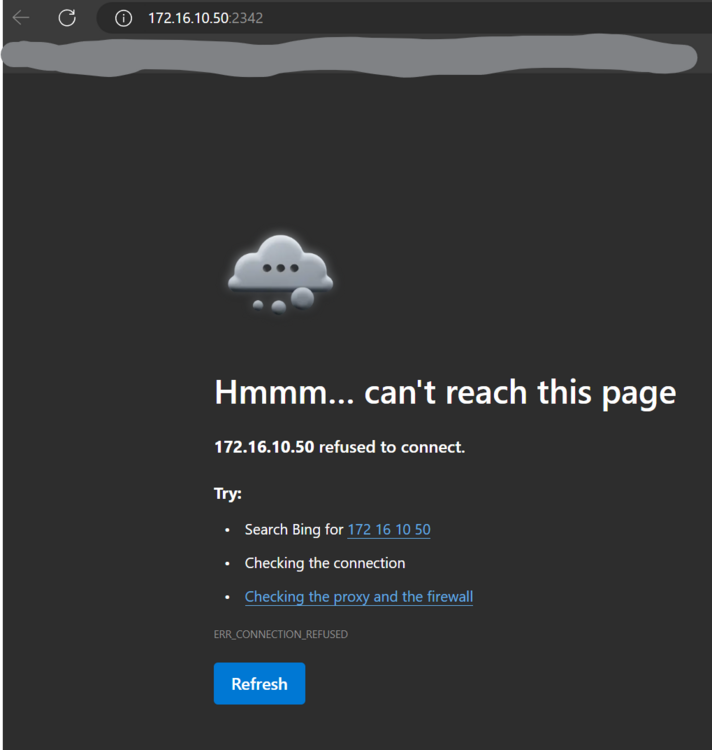
-
+1. MTR is invaluable. Traces each hop and helps track down which hop has latency / dropped packets. Invaluable information when troubleshooting networks with multiple switches or internet issues. I came across this thread after looking for MTR in the current release of UnRAID. It's a pretty standard package, and I'm pretty surprised it isn't included with Nerd Tools as an installable package.
-
Had the same issue. Figured maybe it was a widespread thing. Nope. I checked the Radarr logs going back over a month old (max) and every single entry has some message about a malformed DB. No idea when it started, but we're in the same boat: blow it away, start from scratch, assuming your backups are also invalid. I only wish I could get notified about this - might need to set up a cronjob to troll the logs and shoot me an email alert if the word 'malformed' ever appears so I can jump right on it. I did a cursory check of all my other apps and everything else seems fine. Just this one, on my local storage. /shrug
-
I've read the above. I still don't understand why this is even required. Responses above have said that this isn't a bug in .8. Yet, this "patch" exists as a thing in our collective universe. Either this "patch" should be included in UnRAID's base code and a .9 release addresses this, or I should uninstall "Fix Common Problems" / tell it to ignore this issue. I completely understand and appreciate that none of the above is part of the UnRAID native operating environment, but I also shouldn't be getting nightly reminders that I require a "patch" for something that doesn't impact me at all. And if I install it to quiet my alerts, I then have to remember to uninstall it when it isn't an issue.
-
Didn't even think to check there. And I clearly missed that the log file isn't automatically rolled. I'll add to logrotate/tmpwatch/whatever Unraid uses (I float between different distros at work and can't remember what Unraid uses lol). Thanks again!
-
This is filling up my /var/log dir. How do I stop it from creating a runaway .csv? root@mediasrv:/var/log# ls -l|grep cache_dirs -rw-r--r-- 1 root root 1.4M Feb 11 18:43 cache_dirs.log -rw-r--r-- 1 root root 42M Feb 11 18:43 cache_dirs.csv root@mediasrv:/var/log# df -h . Filesystem Size Used Avail Use% Mounted on tmpfs 128M 76M 53M 60% /var/log
-
I know this is an older post now, but don't forget to go back and reset the vDisk bus from SATA to VirtIO! This significantly increases read/write speeds on disks in VMs managed by KVM.
-
For those reading in September of 2023, this app is done upstream since Dec 2022. See: GitHub - JasonHHouse/gaps: Find the missing movies in your Plex Server Maybe someone will pick up the mantle in the future. Does anyone know of any alternatives? Or did I miss this in a comment above?
-
Found it. /boot/config/plugins/dockerMan/templates-user/<container name>.xml Update it, restart docker via Settings -> Docker -> Enable Docker: No Save Set Enable Docker: Yes I guess this is the correct method: Apps -> Previous Apps -> Reinstall -> Remove offending entry -> Success
-
Hello - I updated an application in docker with an invalid configuration setting. I meant to add a port to a container's configuration but forgot to change the setting from 'volume' to 'port' in the web gui. Now the container is gone, with an orphan image. Reinstalling from 'previous apps' produces the same issue. I'd prefer to not wipe/reload the entire container and start over from scratch because the configuration is quite tweaked overall. I've tried to locate the file in the OS but I'm not having much luck. I was hoping to just remove the last update I did to the config from the configuration file / template but I cannot seem to locate the data. I've checked the docker.img mount point under /var, appdata and /boot. Where would one go to quickly edit the config so I can fix my 'uh-oh'? I'm fine once I know where the app configurations are stored and can figure it out from there, I just need some guidance on where to look. Thanks in advance!
-
Very excellent point. The server is actually within reach, but of course it is also always on and I'm not always at home. I did slyly purchase this setup with the intent of turning it into a gaming rig and grabbing a Rosewill chassis or whatever and moving my server duties to that. I built the system in 2020 and the last component I was missing was a GPU. Well, Etherium put a stop to those plans. I did have an M60 available from work that I used up until 6 months ago for vGPU duties but ... eww. Maxwell. It got the job done though for vGPU passthrough for my needs, which mostly consisted of either Plex transcoding (I've since flipped to QuickSync from Intel) or a VM running a desktop so my daughter could play Roblox / Minecraft / whatever remotely using Parsec. And Maxwell was the last generation of GRID GPU that didn't require a license server. That all started with Pascal and continues on with Turing, Ampere and now (I assume) Lovelace. Now, however, E-VGA GeForce GPUs are about to go on a firesale so maybe I can continue with those plans - albeit 2.5 years later. I already have my half-height rack in my checkout box on Amazon but I'm still struggling with a case that meets my needs.
-
32GB dual channel, non-ECC (hope to switch to ECC soon as I'm about to flip to ZFS) Here is my full component list: Completed Builds - PCPartPicker And yes yes, I know, I don't need an AIO for this setup. But I hadn't installed one before and I had the scratch available.
-
Interesting. Saw 40GB and my brain went "wait, what?" Dual channel I assume since you're using 2x pairs? Same model, just a different size?
-
Nope. I did have the parity drive operational and the array online, other than the single disk that I removed from the array. That's why /mnt/user/ was my <dest> path, and I was getting those speeds. And the amount of data being transferred was 6x the size of my SSD cache disk. My signature has the drives I use, which are Enterprise Seagate Exos disks. I guess their on-disk cache is able to handle writes a bit more efficiently than more commodity drives? /shrug - but 240MB/s is the maximum for spinning disks w/o cache and I assume the writes were sequential. Oh that's interesting (Turbo Write Mode). That ... probably would have been beneficial for me! But I got it done in the end after ~9 hours. Of course, as a creature of habit, I re-ran the rsync one more time before wiping the source disk to ensure everything was indeed transferred. I didn't measure IOPS but I'm sure they would have been pretty high. I just finished benchmarking a 1.4PB all-flash array from Vast Storage at work and became pretty enamored with the tool elbencho (a pseudo mix of fio, dd and iozone, with seq and rand options - and graphs!) and after spending basically 4 weeks in spreadsheet hell I wasn't too interested in IOPS - I just needed the data off the drive as quickly as possible . That said, making 16 simultaneous TCP connections to an SMB share and seeing a fully saturated 100GbE line reading/writing to storage at 10.5GB/s felt pretty awesome! For anyone interested in disk benchmarking tools I highly recommend elbencho as another tool in your toolkit. The maintainer even compiles a native Windows binary with each release. Take a look! breuner/elbencho: A distributed storage benchmark for file systems, object stores & block devices with support for GPUs (github.com) Oh certainly and yes, I knew there was a performance hit using the unraidfs (for lack of a better term) configuration/setup. And agreed too, eschewing the UnRAID array entirely and hacking it at the CLI to set up ZFS is a route one could do. But at that point, it would be better to just spin up a Linux host and do it yourself w/o UnRAID. Or switch over to TrusNAS. The biggest draw for me to UnRAID was/is the ability to easily mix/match drive sizes and types into one cohesive environment. I guess I was really just documenting how I was able to achieve what OP was trying to do for future people stumbling across the thread via Google (because that's how I found this post).
-
No need to apologize! DEFINITELY appreciate the work you've done! I was probably a bit too discerning myself. I've just seen soooo many apps on CA sit there in various states of functionality (even 'Official' ones) so I kind of soapboxed a bit. This thread was probably the wrong place for it. Your work here is great and I actually use your contribution for Homarr in CA every day! Cheers
-
Yep. I came across this thread (now years later via google) because the speeds were horrible. I didn't even consider taking the disk I want to remove out of the array. I stopped the array, went to Tools -> New Config and set everything up the same way except I didn't add the disk I wanted to repurpose outside of UnRAID. When the disk was in the array I was getting ~50-60MB/s using rsync on the command line while transferring large (5+GB) files. After I removed the disk from the array, restarted the array w/o the disk, then SSHed into the UnRAID system and manually mounted the disk I wanted to remove and re-ran the same rsync command, I was getting ~240MB/s. Which is the maximum my spinning disks can do for R/W ops. I would expect a destination array setup using SSDs to also reach their theoretical maximum throughput, depending on your data of course (block size, small files vs large files, etc). It meant the difference between a 32 hour transfer and just over a 9 hour transfer for 7TB of data. Steps I used, hopefully someone else that finds this thread via a Google search like I did finds it useful. Full warning: The below is only for people that understand that UnRAID Support on these forums will only help you as a 'best effort' and you are comfortable with the command line. There is no GUI way of doing this. You've been warned (though, that said, this is fairly easy and safe but since we are "coloring outside of the lines", BE CAREFUL). After removing the drive from the array via Tools -> New Config and starting the array without the drive, manually updating all shares to a configuration where the mover will not run, and assuming /dev/sdf1 is the drive you want to remove, install 'screen' via the Nerd Pack plugin, launch a console session (SSH or web console via the GUI - either works) and type: # Launch Screen root@tower# 'screen' # Create mount point for drive you want to remove data from root@tower# 'mkdir /source' # Mount the drive you want to remove data from root@tower# 'mount /dev/sdf1 /source' # Replicate the data from the drive you intend to remove TO the general UnRAID array root@tower# 'rsync -av --progress /source/ /mnt/user/' # --progress is optional, it just shows speed and what is happening # Press 'CTRL+A, then the letter D' to DETACH from screen if this is a multi-hour process or you need to start it remotely and want to check on it later easily. # Press 'CTRL+K, then the letter Y' to kill the entire screen session. Note that this WILL stop the transfer whereas 'CTRL+A, then D' will not. # # To reconnect, SSH back into the system and type: root@tower# 'screen -r' (wait for rsync to complete) root@tower# umount /source root@tower# rmdir /source # IMPORTANT: If either of the above commands fail, you have ACTIVE processes that are using the drive you want to remove. # Unless you know what you're doing, do not proceed until the above two commands work without any warnings or errors. Shut down server, remove drive, turn server back on, and change the shares that were modified at the start of this process to their original state so mover will run once again. Why use screen? You can certainly do this without screen, however if you don't use screen and you get disconnected from your server during the transfer (WiFi goes out, you're in a coffee shop, etc), your transfer will stop. Obviously this is not an issue if you're doing this on a system under your desk. But even then, it is probably still a good idea. What if the X session crashes while you're booted into the GUI? Screen does not care - it will keep going, and you can reattach to it later to check on the progress. I did try to use the Unbalance plugin in conjunction with the Unassigned Drives plugin so that the drive I wanted to copy data FROM was not in the array, however Unbalance doesn't work that way - at least not that I could dig up.
-
Well, I can see both sides. I've certainly also abandoned perfectly working apps because of similar issues. While they are maintained by volunteers, it would seem that in at least some cases (especially with lesser-known apps) the volunteer in question just abandons it and it languishes. Maybe it's a larger discussion for CA where the program requires a twice-a-year check-in from the volunteer or the app gets tagged with something like 'possibly no longer maintained' so people browsing the store know that they may have issues. Folks like binhex are notoriously reliable, but "johnsmith1234" with one app may publish it once and then never re-evaluate it for any required updates ever again even though the docker version it was created against is now 8 major releases ahead, yet the CA offers it as if it works just fine out of the box. If the volunteer doesn't check in within a 'renewal month' check or something - maybe twice a year? - it gets an 'unmaintained' flag so the community knows they may have issues and/or need to have deeper Linux and Docker knowledge if they wish to use the app. If the volunteer wishes to remove the flag, they just go to their app and maybe check a box that says, "This app has been validated to still be functional" or something. netbox by linuxserver is a perfect example of this. It gets you around 70% there but unless you're fine dabbling with command line edits of an application you've never messed with and know where to look for the right log files to debug / troubleshoot, you're just going to give up after a few minutes. Just thinking out loud, certainly not knocking anyone in particular but I do think some additional QC of CA wouldn't be too much.
-
Hi folks. I know it's an old thread but just sharing in case anyone else from Google searching ends up here. This seems to have done the trick for me (note that I'm not running Hyper-V or Windows in my VM so I cannot confirm on Hyper-V): https://stafwag.github.io/blog/blog/2018/06/04/nested-virtualization-in-kvm/ Specifically, editing the VM XML and changing the cpu mode section with this: <cpu mode='host-model' check='partial'> <model fallback='allow'/> </cpu> Of course, you also need to ensure the intel-kvm.nested=1 change is applied to your grub config, the first step OP mentioned. The link I shared shows how you can do this without rebooting as well. You can also of course just add the change to /boot/config/modprobe.d/<filename> as mentioned in the linked article (in Unraid, modprobe.d is in this location). My VM (proxmoxtest in this case) detects vmx as a CPU feature now, and the XML was updated automatically with all of the features: root@mediasrv:~# virsh dumpxml proxmoxtest|grep feature <features> </features> <feature policy='require' name='ss'/> <feature policy='require' name='vmx'/> <feature policy='require' name='pdcm'/> <feature policy='require' name='hypervisor'/> <feature policy='require' name='tsc_adjust'/> <feature policy='require' name='clflushopt'/> <feature policy='require' name='umip'/> <feature policy='require' name='md-clear'/> <feature policy='require' name='stibp'/> <feature policy='require' name='arch-capabilities'/> <feature policy='require' name='ssbd'/> <feature policy='require' name='xsaves'/> <feature policy='require' name='pdpe1gb'/> <feature policy='require' name='ibpb'/> <feature policy='require' name='ibrs'/> <feature policy='require' name='amd-stibp'/> <feature policy='require' name='amd-ssbd'/> <feature policy='require' name='rdctl-no'/> <feature policy='require' name='ibrs-all'/> <feature policy='require' name='skip-l1dfl-vmentry'/> <feature policy='require' name='mds-no'/> <feature policy='require' name='pschange-mc-no'/> <feature policy='require' name='tsx-ctrl'/> <feature policy='disable' name='hle'/> <feature policy='disable' name='rtm'/> <feature policy='disable' name='mpx'/>
-
See if this helps.
-
Oh, interesting. That would explain how the same port # was listed twice and yet the container still started - one for TCP and one for UDP. I normally just set up my container (in this case, your delugevpn was set up in 2018), ensure it works and only check support threads like this one if I notice an issue. I would assume many others do the same. I do have daily updates of containers enabled. I guess a container update sometime early the week of July 3rd created that extra entry. My VPN is never turned off. I just know that whatever was recently added created a duplicate "Host Port" entry and it prevented Deluge from functioning normally (VPN and Privoxy and all other components worked fine). Removing it resolved the issue. And it seems others are having some kind of similar issue connecting to trackers. Also, just wanted to say thanks for how you keep your containers updated and your dedication to the community here!
-
I'm battling what seems to be the same issue. Using PIA and OpenVPN. I've switched OVPN .conf files for endpoints but no luck. The /mnt/user/appdata/binhex-delugevpn/deluged.log file states this in every container restart. These are the only log entries I can see in either my container logs or in my pfsense logs that are pointing to any sort of error. pfsense actually doesn't show anything being blocked and I haven't made any firewall changes in ... jeez, months: [19:57:15 [INFO ][deluge.core.rpcserver :179 ] Deluge Client connection made from: 127.0.0.1:42028 19:57:15 [INFO ][deluge.core.rpcserver :205 ] Deluge client disconnected: Connection to the other side was lost in a non-clean fashion: Connection lost. 19:57:16 [INFO ][deluge.core.rpcserver :179 ] Deluge Client connection made from: 127.0.0.1:42030 19:57:17 [INFO ][deluge.core.rpcserver :205 ] Deluge client disconnected: Connection to the other side was lost in a non-clean fashion: Connection lost. 19:57:18 [INFO ][deluge.core.rpcserver :179 ] Deluge Client connection made from: 127.0.0.1:36762 19:57:18 [INFO ][deluge.core.rpcserver :205 ] Deluge client disconnected: Connection to the other side was lost in a non-clean fashion: Connection lost. 19:57:19 [INFO ][deluge.core.rpcserver :179 ] Deluge Client connection made from: 127.0.0.1:36770 I've changed from Austria to Switzerland and still the same result. But I don't think the VPN is the issue here. The startup logs indicate that the VPN is working. The startup logs indicate that amazonaws returns an address that I expect (meaning, not my own). The container itself has internet access. Deluge accepts download requests from Prowlarr, etc. Deluge just ... never actually starts downloading anything. This all started in the last few days. Was working fine last week (and indeed, for years up until maybe this past weekend). UPDATE - RESOLVED I have no idea how or why, but for some reason my binhex-delugevpn container ended up with TWO port definitions pointing to port 58946. The container definitions explicitly called out each line as "Host Port 3" as 'Port 58946' and "Host Port 4" with the same port address. Normally this does not allow the container to start because of a port conflict. Yet, somehow, it did. I removed the "Host Port 4" line in my docker compose instructions via the UnRAID web GUI and now things are ticking along just fine. Note that you should NOT do this unless you see a duplicate entry and 'Host Port 4' is a duplicate of 'Host Port 3'. Curious that the container still started with duplicate port entries in the same container and Docker didn't at least throw a WARN. I ... I swear I didn't do this myself. I don't run any docker-compose scripts or commands outside of the UnRAID GUI. I tinker on other systems. I largely leave this server sitting in my network closet and only connect to it to add things to the DL list. Like Anton from the TV Show 'Silicon Valley', my server: Anyway, if anyone else here is having issues with this container downloading files yet otherwise successfully running, take a look in your configuration and ensure you don't have any extra "Host Port" lines or other duplicate entries.
-
Great. I fat fingered my login because my password locker wasn't available at the time. This isn't seeing the forest for the trees. The Web UI wouldn't be a vector of attack. SSH is already open - this is where attackers would focus their efforts in a serious security breach. Well, maybe the web ui could be used for a 'bobby tables' type of situation. Sigh. I guess it would be a vector of attack... (yes I just literally talked myself out of my own argument)
-
Yea. I can see both sides certainly!
-
Well, this may come back to bite ya. Yes, there could be reasons to 'balance the load out'. I know this is 3 years old, but I was looking up another issue for clearing out my cache disk and wiping/formatting to XFS from BTRFS and while that's happening this comment caught my eye. I could sit here and say the same thing, in a sense. "I have never heard any good argument for *not* "balancing the load out"". I suppose on a technical level, without having much understanding about how the UnRAID FUSE FS works under the hood, sure. Maybe its fine to frontload a bunch of drives with data and default to a high-water setup. But from an end user perspective (read: optics), it gives a sense of comfort in knowing that your disks are being used efficiently. Even if you and I know it doesn't mean that on the technical side.



