




madejackson
Members
-
Joined
-
Last visited
Everything posted by madejackson
-
Basically the title. I added a L2ARC cache to my ZFS-disk in the array (zpool add [pool name] cache [disk identifier]) Upon restarting the array, the disk goes unmountable. Removing the cache disk fixes the issue (zpool remove [pool name] [device name])
-
Not sure exactly what you're saying but yeah, you cannot have one single L2ARC for all ZFS-pools. You can partition an ssd into multiple smaller L2ARC-caches though. One partition for every ZFS-Disk. Of course, this wastes some space, but that's how L2ARC works right now and I don't think that is gonna change anytime soon. Even though there is a commit on github to make L2ARC unified for multiple pools.
-
So this is probably the same issue as the other posts. First disable ZFS Master or close the main-tab. If this does not solve the issue, see my solution I just found out:
-
I think I found the issue leading to this thread and I explained my solution here:
-
So after recognizing that WD does not use SATA in their external HDD's, I now realized, that the 5TB WD Drives i got out from an external intenso HDD is dogshit as well. The WD50NPZZ that i took out of the intenso case has write speeds below 5MB/s after a brief amount of constant writing to it. TLDR: Avoid WD / Western Digital and Intenso at all cost when shucking external 2.5" drives.
-
I just realized that diskspeed does not test write-speed on HDD's. This led me to believe that the WD50NPZZ (WD disk sold from intenso) is a good disk for use in unraid because its read-speed are at about 75-150MB/s. I now realized, it's write speed slows down to <5MB/s after a very brief amount of constant writes to it. Hence it's more or less completely useless. For comparison: the ST5000LM000 (seagate) has constant write speeds of about 40MB/s for the same files. >8x times as fast. Everything was tested inside the array.
-
Edit: solved. I was able to find the culprit: It's the hard-drives from WD (WD50NPZZ). I can write to my Toshibas and Seagate ST5000LM000 with about 35Mbit/s, but the WD (WD50NPZZ) is stuck at <5MB/s. I'm on 6.12.2 now and suddenly have some very slow speeds (<4MB/s), when trying to copy from btrfs pool to my newly zfs formatted array disk. I am 100% sure that nothing else is accessing my disks (fresh reboot, docker+VM stopped). Any Idea what this could be? In the last couple of transfers on 6.12.1 from xfs disk to zfs disk I usually got 20-30MB/s. Speed Fluctuate a bit. Sometimes it goes up to 25MB/s for a short time only for then to fall back down to 3MB/s, grinding to a complete halt and then speed up again. The Files are regular sized MP4's and maybe some .srt subtitels. There are no errors in the logs. Diskspeed lists the speed of this particular WD disk at about 90-150MB/s unbalance.log
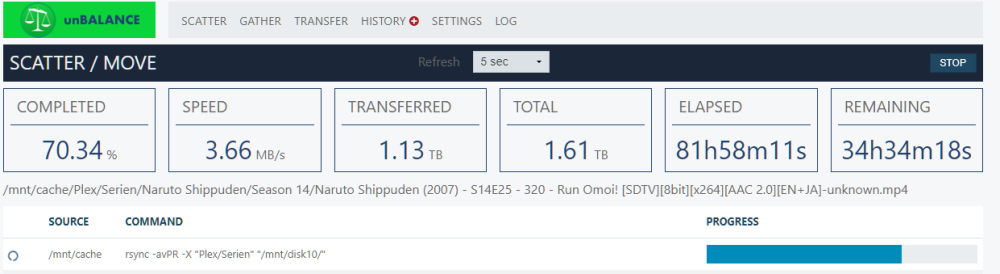
-
Free Space calculation is fine as far as i can see. It's just the total size that's wrong. Updated screenshots, unRAID and ZFS-Master as comparison:


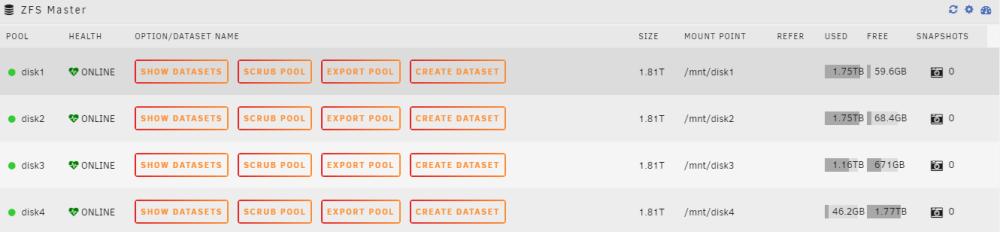
-
So as with isvein discussed on reddit (here and here), unBALANCE does not create the nececcary datasets in advance of moving the files over (unlike core unRAID functions like mover that do work as they should). But I also experienced another issue with zfs and unBALANCE: unBALANCE is unable to read the size of a zfs-formated disk correctly. As soon as there is some data filled onto the zfs formated disk, it just shows the remaining free space as "size":

-
Yeah this is insane. But this only works for 7mm drives, so for 5tb HDD's this would only be 12x2.5" (15mm). At the moment you'd still have more usable TB's with 5x22tb than 12x5tb. When you go 7mm 24x8tb ssd's though
-
Interestingly, i bought 3x Intenso 5tb last year which featured regular WD50NPZZ with SATA inside. So I was under the full impression buying a WD drive is a "safe" bet. It isn't that much of a difference actually. cheapest 3.5" are going for $13/tb in my region, so about 20% less than cheapest 2.5". But I'd need to upgrade my parity drives and cages which could get costly fast. I like to keep it 2.5" for my server as I have 2x 8x2.5" hot-swap cages and 2x5tb parity. In the process of replacing the last old 2tb ones, getting to a final size of 80TB (70TB usable) until i can omit 3.5 completely and switch to an SSD-Only Solution in the next 5-10 Years (hopefully). SSD's are going for $34/tb right now. I expect them to be on par with HDD's in the next couple of years.
-
I've been shucking 2.5" HDD's since the beginning of my unraid days as the same internal only drives are always at a significant upcharge. Recently I bought 5 TB WD Elements for under $16/TB. To my surprise they do not feature a SATA-Port anymore. The installed HDD has a Controller with USB directly. Last time I bought Western Digital. From now on, it's seagate only (usually ST5000LM000).
-
Unfortunately, with 6.12 it is not possible anymore to replace a drive while keeping parity intact. The corresponding script or the manual command "dd bs=1M if=/dev/zero of=/dev/mdX status=progress" does nothing in regard of writing zeros to the drive. The script doesn't recognize the error and "thinks" it has finished correctly. corresponding docs entry: https://docs.unraid.net/de/legacy/FAQ/shrink-array#the-clear-drive-then-remove-drive-method Log of script: *** Clear an unRAID array data drive *** v1.4 Checking all array data drives (may need to spin them up) ... Found a marked and empty drive to clear: Disk 2 ( /mnt/disk2 ) * Disk 2 will be unmounted first. * Then zeroes will be written to the entire drive. * Parity will be preserved throughout. * Clearing while updating Parity takes a VERY long time! * The progress of the clearing will not be visible until it's done! * When complete, Disk 2 will be ready for removal from array. * Commands to be executed: ***** umount /mnt/disk2 ***** dd bs=1M if=/dev/zero of=/dev/md2 You have 60 seconds to cancel this script (click the red X, top right) Unmounting Disk 2 ... Clearing Disk 2 ... dd: error writing '/dev/md2': No space left on device 1+0 records in 0+0 records out 0 bytes copied, 0.000486246 s, 0.0 kB/s A message saying "error writing ... no space left" is expected, NOT an error. Unless errors appeared, the drive is now cleared! Because the drive is now unmountable, the array should be stopped, and the drive removed (or reformatted). Script Finished Jun 19, 2023 09:22.50 Full logs for this script are available at /tmp/user.scripts/tmpScripts/Shrink Array/log.txt
-
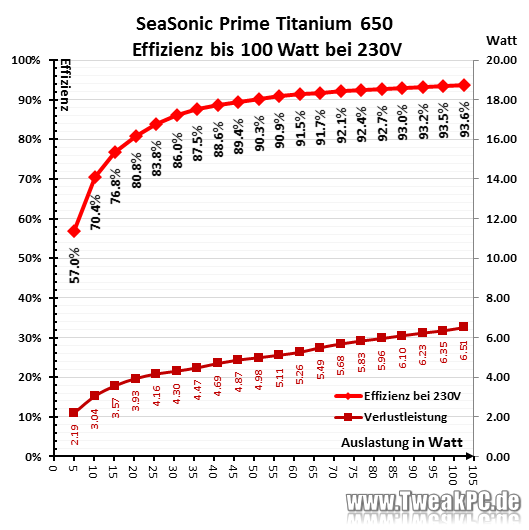
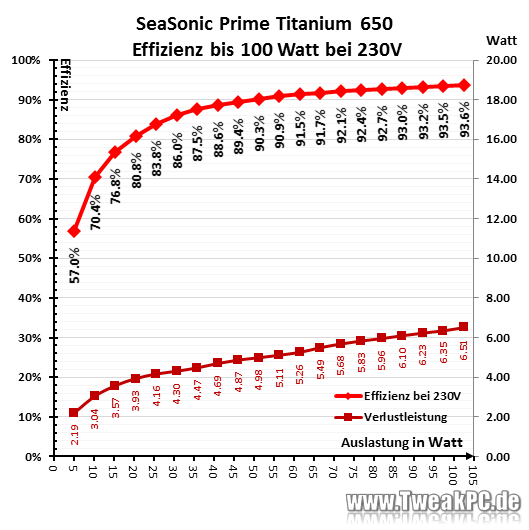
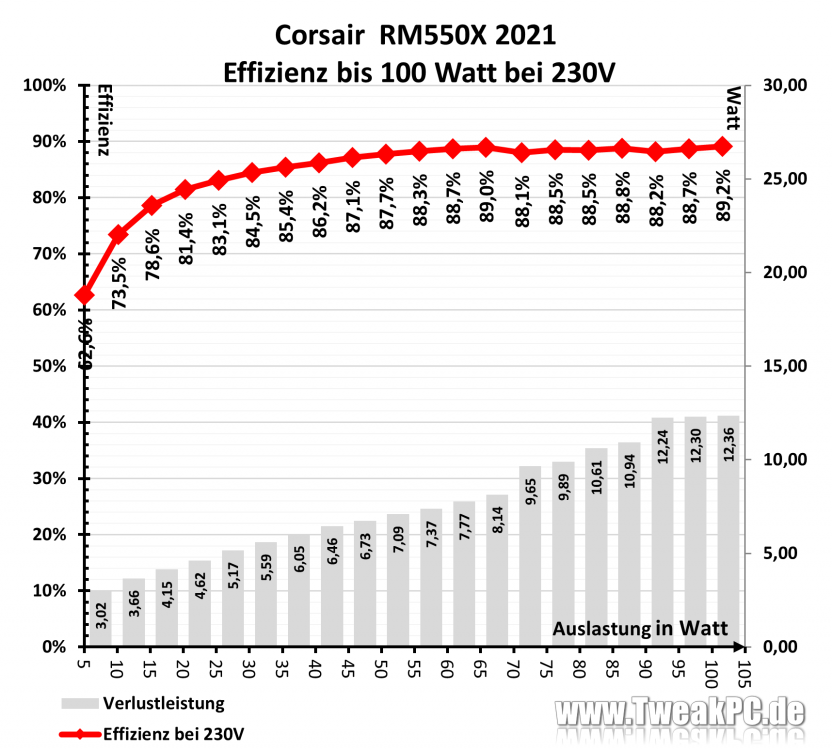
I have the Seasonic PRIME TX-650 (80+ Titanium) installed in my unraid-server. I'm pretty sure, it's more efficient than the 2021 rm550x in the usual power range of low power unraid sytems (20-30W). In higher load scenarios, the TX-650 blows the rm550x out of the water. Source: https://www.tweakpc.de/hardware/tests/netzteile/seasonic_prime_titanium/s03.php
-
With 6.12 and its ZFS-Introduction, this script could get much more interesting. In Theory, it should be possible to cache the beginning of every single movie and episode into L2ARC, hence onto an SSD-Cache. So we should be able to use much more space as cache than just 50% of free RAM. As soon as 6.12 is released I'm gonna try it and see if it's possible in practice.
-
I tried to implement this script and I had a couple of issues. I have about 4x srt-files for every Film/Episode. As the script doesn't take the filename into account it still loads tons of subtitles, usually from all episodes in a season hence taking very long to finish. My solution is to disable srt preloading and move all srt files to ssd. The script also takes files on the ssd pool into account. This makes the script basically useless in my case whrere I store new films and episodes on ssd pool. I editet the script on line 89/90 to only take files from array (user0) into account: video_files+=("${file/\/user0\//\/user\/}") done < <(find "${video_paths[@]/\/user\//\/user0\/}" -not -path '*/.*' -size +"$video_min_size"c -regextype posix-extended -regex ".*\.($video_ext)" -printf "%T@ %p\0") It seems my RAM is quiet slow, longest time needed is 317ms for fetching a preloaded file from RAM after multiple runs (increased to 0.330 instead of 0.150 per default settings) It's even worse. Sometimes it takes up to 1.25s for Preloading a file from RAM, for whatever reason.
-
i get an error when i try to disable update Notifications: Warning: Invalid argument supplied for foreach() in /usr/local/emhttp/plugins/ca.update.applications/include/exec.php on line 61 Update Notifications always revert to yes:


-
Sorry to resurrect this thread, but I'm quiet surprised, that this issue still persists exactly as described by @mgutt more than 1.5 years ago. I am increasing my storage at 2MB/s, so I am running into this exact issue 1-2 per weeks when my 2tb ssd's are filling up. Workaround I did for anyone interested: https://www.reddit.com/r/unRAID/comments/10fwzin/stop_mover_on_plex_playback/
-
Unfortunately they do, probably due to lack of alternative? radarr, sonarr, Plex etc. all have Logs in appdata. Last Week I found a Logfile with 8GB Size in appdata. Probably some old culprit or misconfiguration, but still. As Template-Creator I'd strongly encourage Data Integrity / Data Safety as the default setting. But me as a user should have the option to change that. A better solution should come from unraid or a plugin rather than the container templates. (f.e. optional ramdisk-cache for specific shares or folders)
-
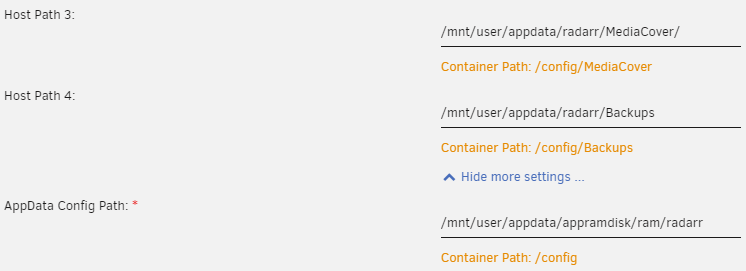
I want to commit my two cents to this thread. Thanks everyone for their commitement to this thread. I have now come up with my own version of a solution based on OP's and mgutt's solutions. My Solution is also 3-step based but more streamlined in my opinion. Step 1: Get rid of all uneccecary log and temp writes in appdata. I searched for every file- or folderchange containing "log","temp" or "cache" in appdata using inotify. inotifywait -e create,modify,attrib,moved_from,moved_to --timefmt %c --format '%T %_e %w %f' -mr /mnt/user/appdata --includei="(cache)|(te?mp)|(logs?)" Then you can mount this to tmpfs in bad behaving containers. Easiest way is to add it as "--tmpfs <path>" into Extra Parameters. mgutts command works as well. Step 2: Move /var/lib/docker to ramdisk and create ramdisk in appdatata for regularly written files. Thanks mgutt for the hard part of the script in the go-file. I allowed myself to extend it a bit to allow a ramdisk on /mnt/user/appdata/appramdisk/ram. This is basically part 3 of OP's post but included in mgutt's solution. Add the script, create the folders in appdata and reboot. Don't forget to add an exclusion for appramdisk/ram in the "Backup/Restore Appdata"-Plugin, otherwise the backup could fail ( I need to test this more, still better safe than sorry). Step 3: rsync desired folders/files to appdata/ram and change docker templates accordingly. Using inotify once again in find candidates for changing the mount to ramdisk: inotifywait -e create,modify,attrib,moved_from,moved_to --timefmt %c --format '%T %_e %w %f' -mr /mnt/user/appdata --exclude appramdisk example for radarr: rsync -avH /mnt/user/appdata/radarr /mnt/user/appdata/appramdisk/ram/ --exclude MediaCover --exclude Backup During the whole step 3 you should always consider less is more as you don't want to waste your precious limited ram. hence why I exclude MediaCover in the example above as this holds about 1GB of data for me. The rest of radarr-appdata is a mere 36MB. Also, If only 1 file is accessed often, try to change the path of this file into a seperate folder and only sync this folder to ram. I did this for home-assistant_v2.db for example. I'm sure I will come up with some updates in the future and will post this accordingly. Cheers. Update concerning Plex / or whitespaces in paths: I experienced some issues with Plex. I suspect it's due to whitespaces in the paths. I rsynced the folder to ramdisk, deleted it and created corresponding symbolic links to /Logs and /Databases in the corresponding paths and then created the paths in my appramdisk/ram-folder which resolved the issue completely. ln -s /Logs /mnt/user/appdata/PlexMediaServer/Library/Application\ Support/Plex\ Media\ Server/Logs/




-
Followup to this, I found the results for the PSU Seasonic Prime TX-650. It is even more efficient than the Corsair RM550x 2021, altough at low load not by very much 0.5-2W: Seasonic Prime Titanium im Test | TweakPC.de
-
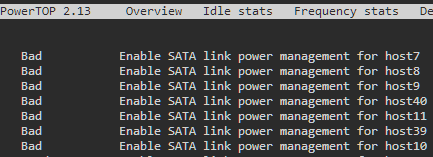
Thanks for all your help. Especially mgutt. I now did several Improvements to reduce my consumption from ~65W to 33W on "idle". See following graph, last improvments were made on 11:00 (measured from the wall with mystrom-Plug): Xeon E3-1245v5 with Fujitsu D3417-B1 with 4x8GB ECC RAM (bought 2015) Got rid of my SAS3008 (10W) and small disks. I now have only the Chipset C236 and 1x ASM1166+JMB575 and 1x ASM1062 (2W) (-10-15W) Due to the high power usage, I cannot recomment any SAS HBA card. I'd say for a good build stay on asmedia or JMicron. Disabled "Dynamix Cache Directories" setting "Scan user shares (/mnt/user):" (led to high cpu usage on idle, constantly ~15% load) (-10-15W) Should be disabled by default, seems like I enabled it by accident in the past enabled Powertop improvements as this thread suggests (-1-3W) Important: ASM1166 and ASM1062 do not work with med_power_with_dipm (aka "Good" in following Screenshot) and leads to disks in error state (You are going to have to rebuild parity) i used this script to find the correct hosts to leave at default aka "Bad" in Powertop: identify scsi_host / ata devices + Diskspeed App Todo: replacing 1x ASM1166+JMB575, 1x ASM1062 --> 2xASM1166. expected savings: 2W (one Chip less: JMB575) The JMB575 is already not in use due to bad performance (ca. 30MB/s with 5x Disks during parity sync = 60% speed loss) Done: Power savings not measurable 2x PC's, 1x Switch, 1x PSU: Running 2x PC's + 1x Switch off of one PSU expected savings: 5W I do have another system running as a 25G-firewall at ~25W idle with i7-6700 and picoPSU. I try to run both systems off of 1x PSU. The Seasonic Prime TX-650 has far enough Power and Outputs for both systems exept the 24Pin. I ordered a 24-Pin Splitter and will try this out. The Switch runs on 12V so no issue there as well. Done: Power Draw reduced (-10-15W) from ~61W (33W+23W+5W) to ~50W for 2x Skylake Systems + 1x 10G-Switch. More Info: see following Graph:
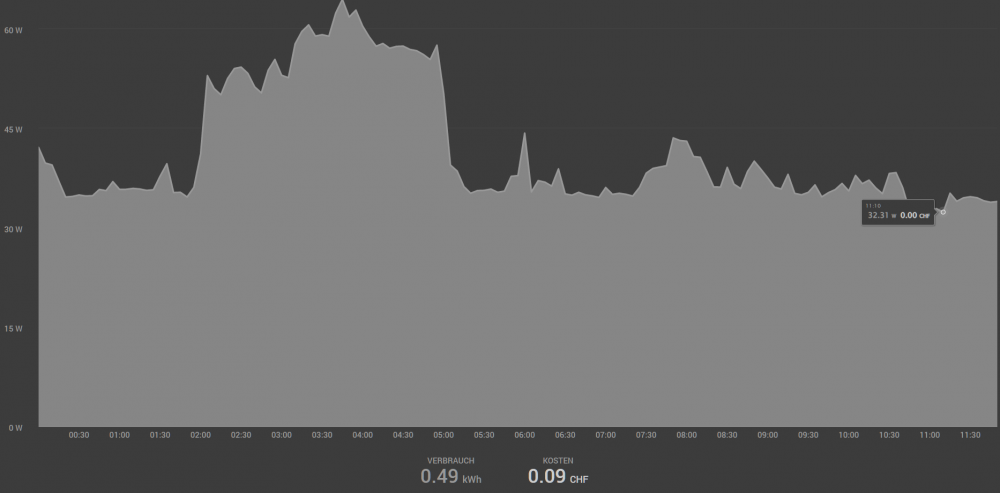
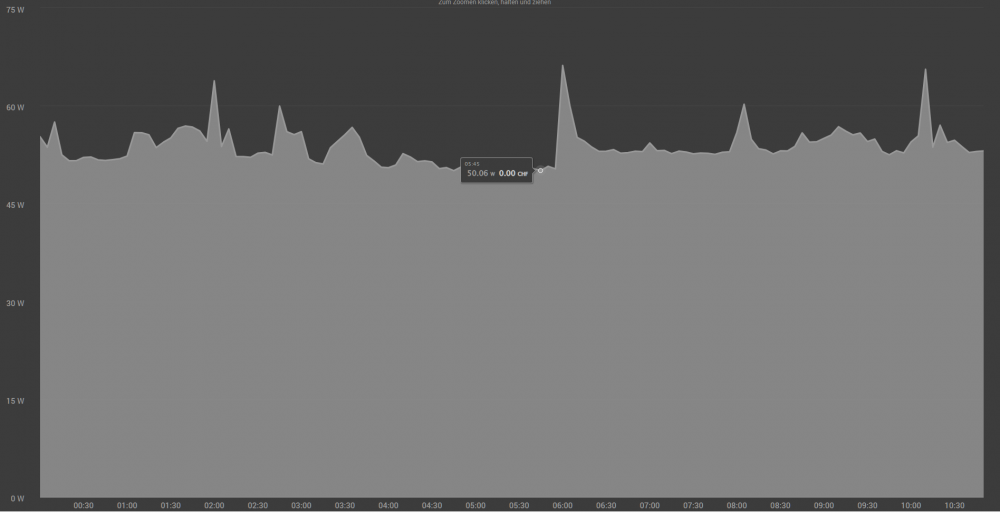
-
Yeah... I can only dream of such low Power usage. In the beginning, my Unraid was idling at about 20W as well (2015). But now, with 13x 2.5" HDD's, 7x SSD's, 4x SATA-Controllers and 40x Dockers for gaming servers, transcoding and keeping track of downloads those days are long gone. atm, I'm sitting at 60W "idle", I'm looking into getting rid of old disks (- 4x HDD's, 5xSSD's) and my SAS3008 which should give me another 10-30W savings.
-
Thank you The article is very interesting. Finally someone asking the right questions. In Theory, the Seasonic Prime TX-Line should still be somewhat more efficient. The Titanium-Certification mandates 90% Efficiency at 10% load. The two tested PSU's are at ~88% at 10% load. Nevertheless the efficiency is still quiet impressive at only 50% the cost of the Seasonic.
-
This sounds very interesting. Do you have a source or any more info / comparison on that? f.e. efficiency compared to a picoPSU. Did I invest in the wrong horse with a Prime TX-650 from Seasonic with Titanium Certification? My picoPSU didn't have enough max Power.




















