




sjerisman
Members
-
Joined
-
Last visited
Everything posted by sjerisman
-
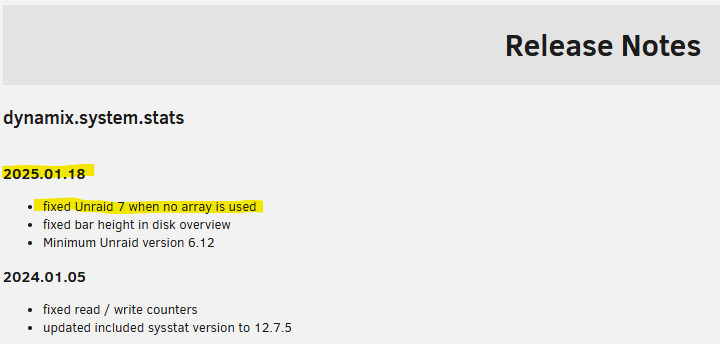
@NoRaid99 - My PR was merged and a new version of System Stats was released. Working fine on my systems. Hopefully it fixes the plugin on your systems as well.
-
@Rysz (or whoever maintains this currently) I've traced the issue down to a divide-by-zero error that causes the page to stop rendering. I've opened a Pull Request that fixes the issue by bypassing the array calculation logic (and display logic) if there isn't an array found. https://github.com/bergware/dynamix/pull/97 This seems to fix the issue on my test system (although it looks like there might be a unrelated style issue on the Disk Stats page still). EDIT: I've since been able to fix the display issue as well (it was actually a pre-existing issue affecting anyone with a small number of disks). Can someone please review the PR and release an update for this plugin?
-
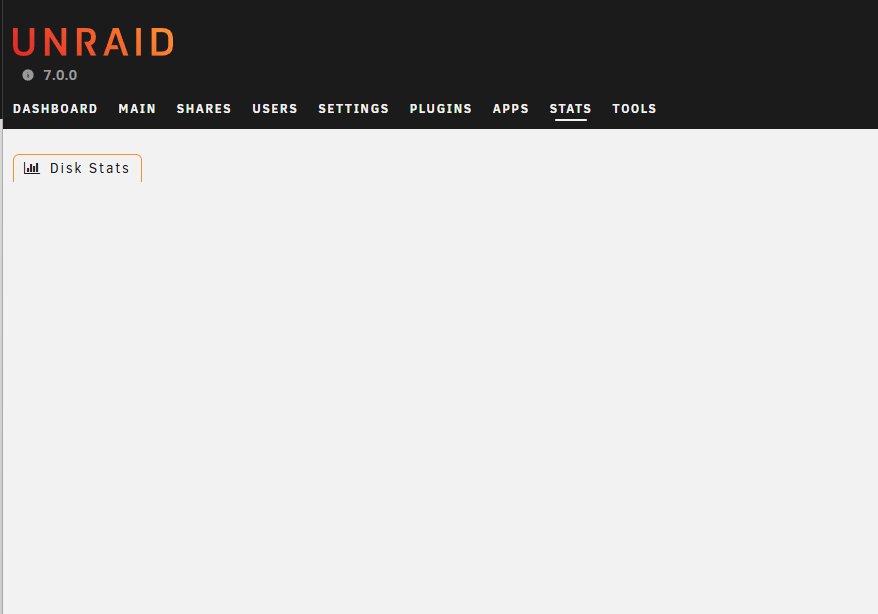
The System Statistics plugin is not working with the newly released UnRaid 7.0.0 when only Pool drives are used (i.e. no Array). Navigating to the Stats tab just renders a blank page: I was seeing the same behavior on the beta and rc builds. Priority is a bit higher now that the official stable build has been released.
-
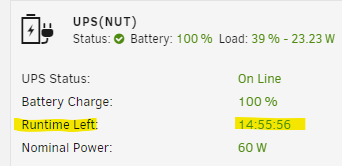
Hi there. I have a custom battery backup with a huge battery that provides multi-day uptime. I noticed that this plugin seems to truncate anything over a day of runtime and just reports the remaining time as 'HH:MM:SS', which is a bit misleading. Would it be possible to change the display format to report as 'DD HH:MM:SS' (or maybe just 'DD.X days') if the runtime is more than a day?

-
Ok makes sense. beta2 did come out yesterday and has the exact same style issues. But again, no rush, just wanted to make sure you knew.
-
System Statistics seems to be broken with the v7.0.0 beta. I just get an empty page when I navigate to the 'Stats' tab. This is on a system with only a ZFS Pool where the UnRaid Array has been removed. Possibly the plugin currently needs an UnRaid Array to operate?
-
@Iker - Not sure if you've tried out the v7.0.0 beta yet? One (extremely minor) issue I noticed with this plugin is the usage information is offset vertically now. Probably some style(s) changed with v7.
-
My PRs got merged, so it looks like these bug fixes / enhancements will be part of the next release (whenever that is).
-
Ok, I've submitted a PR for this 'enhancement' as well: https://github.com/unraid/webgui/pull/1551
-
I've submitted a PR to fix this issue: https://github.com/unraid/webgui/pull/1550 I'll try and work on another one for my original enhancement suggestion.
-
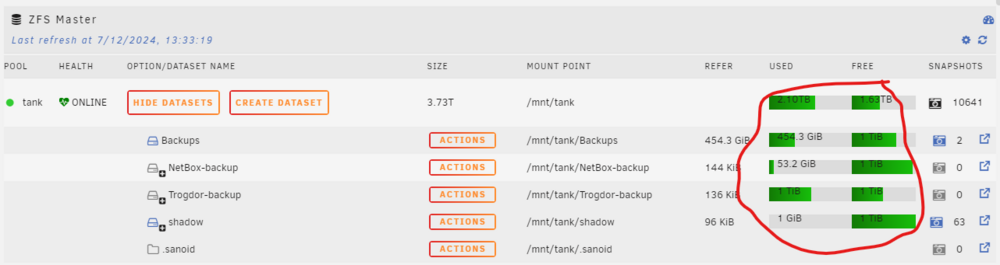
@Iker - Thanks for the great plugin! I'd like to propose two possible enhancements for a future version: Have a refresh icon per pool. Right now there is only a global refresh icon. This will cause disks in the array to spin up if any of them are formatted as zfs even if I'm only interested in getting updates for a 'cache' pool at the moment. A 'refresh' icon per pool would allow targeted refreshing. I could refresh just a 'cache' or UD' pool and let the array drives stay spun down. Another possible option is to ignore refreshing pools where the datasets are currently hidden. Would it be possible to add the 'written' property to the Snapshot Admin table view. It can be queried with `zfs list -o written` similar to how you are getting the other properties. I usually find 'written' is more meaningful to me than 'used' when looking at historical snapshots. My understanding is that 'written' refers to how much space was written to a filesystem or snapshot relative to the previous snapshot, whereas 'used' refers to the amount of unique data that applies to only that snapshot (not reused by any other further snapshots) and the amount that would be freed if it was deleted. Both are useful, but I think 'written' is actually more relevant usually (at least to me).
-
@SimonF - Thanks for the great plugin! I was able to fairly easily get it to do most of what I want. I did have to go research elsewhere how to setup the keyfiles for remote ssh access, but that was fairly easy to figure out and get working as well. I'm stuck on retention for the remote server though. I understand that this is still not implemented on the source server side, but is there something I'm missing to be able to apply retention directly on the remote server? What are other people doing to cleanup old snapshots that have been sent from another server? In my case, I have a BTRFS pool with some subvols on a 'source' UnRaid server that I want to keep ~3 days worth of hourly snapshots on, and then send them to a BTRFS pool on a 'remote' UnRaid server. The remote server should then keep 14 days of the hourly snapshots, but then also take daily and weekly snapshots, each with their own retention periods. So, I have one schedule on the source server to create the hourly snaps, tag them with 'Hourly' and send them to the remote server. Then, I have two schedules on the remote server to create the daily and weekly snaps, tagged as 'Daily' and 'Weekly'. I think the retention of the hourly snaps on the source server is working ok, and I think retention of the daily and weekly snaps on the remote server is working ok as well, but what should I do about the hourly snaps on the remote server? I tried creating an hourly schedule on the remote server, basically just to handle the retention cleanup, but it doesn't seem like it considers the received incremental snaps when it applies retention. Is this just a bug, or does it purposely exclude snaps that were received from a different server? So, again... what are other people doing for retention on 'remote' servers? Maybe custom scripts, or am I just missing something obvious? And, just because it is fresh in mind... here are a few general useability observations: It would be nice to be able to sort the list of snaps from newest to oldest instead of the current default of oldest to newest. It would be nice to see the schedule's tag on the list view, maybe instead of the slot #. Or, maybe allow a short description that could be shown there. I keep accidentally clicking on the schedule's + icon thinking I'm editing the schedule row. I'm not sure why that moves down from the subvol row to the schedule row once there are schedules? Maybe leave the + on the subvol row, and then move the clock icon over to where the + currently is on the schedule row? Maybe change the clock icon to a 'edit' icon as well?
-
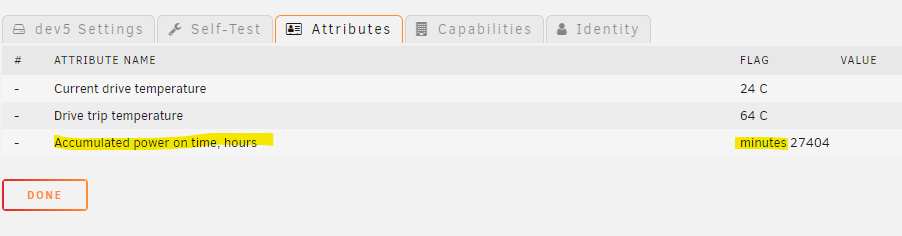
I also noticed that SAS SSDs or HDDs that show 'Accumulated power on time, hours' incorrectly show 'minutes xxxxxx' instead of 'hours xxxxxx' or just 'xxxxxx'. Example: Raw data: > smartctrl -a /dev/xxx ... === START OF READ SMART DATA SECTION === SMART Health Status: OK Percentage used endurance indicator: 22% Current Drive Temperature: 31 C Drive Trip Temperature: 64 C Accumulated power on time, hours:minutes 27404:25 ... 27404 is the number of hours, not minutes. Not sure if it is scrapping the value wrong, or just displaying it weirdly.
-
Hello, I have a bunch of SAS SSDs that currently only display drive temperature information in the SMART Attributes tab. The SSDs in question are: Toshiba PX04SVB096 and PX04SRB096, but I assume this applies to other SAS SSDs as well. It would be really nice if we could also see the 'Percentage used endurance indicator'. This value is available as `Percentage used endurance indicator: xx%` through either of these commands: smartctl -a /dev/xxx smartctl -l ssd /dev/xxx Or, as `"scsi_percentage_used_endurance_indicator"= xx` though the JSON command: smartctl -a -j /dev/xxx Examples: > smartctl -a /dev/xxx ... === START OF READ SMART DATA SECTION === SMART Health Status: OK Percentage used endurance indicator: 10% ... > smartctl -l ssd /dev/xxx ... === START OF READ SMART DATA SECTION === Percentage used endurance indicator: 10% > smartctl -a -j /dev/xxx ... "smart_status": { "passed": true }, "scsi_percentage_used_endurance_indicator": 10, "temperature": { "current": 25, "drive_trip": 64 }, ...
-
Just a thought... What if any old backup files were converted to the new format after a plugin upgrade or after opting into the new naming convention? (i.e. use the filenames read and then remove the timestamps and move the files to new subfolders)
-
Yep, no problem. Results are definitely looking promising. More details on the other thread: Hopefully these changes will be integrated into this GUI plugin sometime next week.
-
@Squid - Sorry up front if this has already been asked, but any thoughts on an option to use zstd compression instead of gzip? Here are some quick tests I did on two of my systems that shows much improved speed and slightly smaller sizes: System 1: > cd /mnt/user/appdata > du -d 0 -h . 1.6G . > time tar -czf /mnt/user/UnRaidBackups/AppData.tar.gz * real 1m17.710s user 1m6.245s sys 0m6.219s > time tar --zstd -cf /mnt/user/UnRaidBackups/AppData.tar.zst * real 0m24.039s user 0m10.248s sys 0m5.330s > ls -lsah /mnt/user/UnRaidBackups/AppData.tar.* 814M -rw-rw-rw- 1 root root 814M Jan 16 14:28 /mnt/user/UnRaidBackups/AppData.tar.gz 783M -rw-rw-rw- 1 root root 783M Jan 16 14:20 /mnt/user/UnRaidBackups/AppData.tar.zst System 2: > cd /mnt/user/appdata > du -d 0 -h . 8.9G . > time tar -czf /mnt/user/UnRaidBackups/AppData.tar.gz * real 4m55.831s user 4m19.009s sys 0m27.770s > time tar --zstd -cf /mnt/user/UnRaidBackups/AppData.tar.zst * real 2m1.380s user 0m35.069s sys 0m23.054s > ls -lsah /mnt/user/UnRaidBackups/AppData.tar.* 4.6G -rw-rw-rw- 1 root root 4.6G Jan 16 14:39 /mnt/user/UnRaidBackups/AppData.tar.gz 4.4G -rw-rw-rw- 1 root root 4.4G Jan 16 14:34 /mnt/user/UnRaidBackups/AppData.tar.zst
-
@JTok - Thanks for the shout out, and thanks for reviewing and releasing my changes so quickly! I did this as much for my own benefit as anything else. Just to give everyone a bit of an idea of how much faster and more efficient this new inline compression option is, here are some results from one of my UnRaid servers: I currently have 4 (fairly small) VMs on this server (Win10, Win7, Arch Linux, and AsteriskNOW) running on a NVMe unassigned device and backing up directly to a dual parity HDD array (bypassing the SSD cache) with TurboWrite enabled. This is running on a 4th Gen quad core CPU (i7-4770) with 32GB of DDR3 RAM. * The 4 VMs have a total of 60 G of raw image files with a sparse allocation of 33 G * The old post compression option took 55 minutes and produced a total of 17.15 G of compressed .tar.gz files * The new inline zstd compression option took less than 3 minutes and produced a total of 16.83 G of compressed .zst image files (using the default compression level of 3 and 2 compression threads) * Some of these VMs (Win10 and ArchLinux) have compressed file systems inside the vdisk images as well. Without this, the vdisk sparse allocation would have been larger and the old compression code would have been even slower. OS Size Alloc .tar.gz .zst ----------- ---- ----- ------- ---- Win10 30G 9.1G 6.7G 6.7G Win7 20G 18G 8.4G 8.2G ArchLinux 5.0G 2.0G 1.4G 1.4G AsteriskNOW 5.0G 3.9G 645M 573M I feel MUCH better now about having daily scheduled backups that go directly to the HDD array and allowing the disks to spin back down again so much more quickly!
-
@JTok - I was able to do some more coding and testing on my open pull request: https://github.com/JTok/unraid-vmbackup/pull/23/files?utf8=✓&diff=split&w=1 Additional changes: * I added seconds to the generated timestamps and logged messages for better granularity * I refactored the existing code that deals with removing old backup files (both time based as well as count based) to make it more consistent and easier to follow * I added support for removing old .zst archives (both time based as well as count based) using the refactored code above * I did a bunch of additional testing (including with snapshots on) and I think everything is working properly Let me know if you would like to see any other changes on this PR. I can make a similar PR for the GUI/Plugin version after this one is approved and after I figure out how to properly test changes to the GUI/Plugin.
-
And, I repeated the same Windows 7 'real' VM test one more time, but this time used the SSD cache tier as the destination instead of the HDD... With the old compression code, it took 1-2 minutes to copy the 18 GB image file from the NVMe UD over to the dual SSD cache, and then still took 13-14 minutes to further .tar.gz compress it down to 8.4 GB. The compression step definitely seems CPU bound (probably single threaded) instead of I/O bound with this test. With the new inline compression code, it still only took about 1-2 minutes to copy from the NVMe UD and compress (inline) over to the dual SSD cache and still produced a slightly smaller 8.2 GB output file. The CPU was definitely hit harder, and probably became the bottleneck (over I/O), but I'm really happy with these results and would gladly trade off higher CPU for a few minutes for much lower disk I/O, much less disk wear, and much faster backups.
-
And here is another test that is closer to real world (and even more impressive)... I took a 'real' Windows 7 VM with a 20 GB raw sparse img file (18 GB allocated) and ran it through the old and new compression code. With the old compression code, it took 3-4 minutes to copy the 18 GB image file from a NVMe UD over to a HDD dual-parity array, and then another 14-15 minutes to .tar.gz compress it down to 8.4 GB. With the new inline compression code, it only took 2-3 minutes to copy from the NVMe UD and compress (inline) over to the HDD dual-parity array with a slightly smaller 8.2 GB compressed output size. The CPU usage was marginally higher than during the .tar.gz step but was over much quicker.
-
Yep, that makes sense. I hadn't really considered backing up directly to the cache tier because for a lot of people that means their VMs and backups are on the same storage device(s) and it could fill up the cache quickly and add a lot of wear to the SSDs. In thinking about it, I agree that backing up to a share that has cache: Yes, cache: Prefer, or cache: Only would definitely help with the I/O performance bottleneck. But I think the script would still be doing things a bit inefficiently (including wearing out the cache faster) and would still be slower than inline compression. Yes, I agree that backwards compatibility would be nice to maintain. My suggestion is to introduce a new option that, when set performs inline zstd compression, but when not set still behaves like before. That makes sense. I think a large part of the point of zstd compression, however, is that most modern processors can easily handle real-time compression. So, technically it will be faster to do inline compression because the bottleneck will still usually be I/O, but the amount of data that even needs to be written will usually be reduced. Yep, no problem. Here is a preliminary pull request to your script only GitHub repo: https://github.com/JTok/unraid-vmbackup/pull/23/files?utf8=✓&diff=split&w=1 I still need to finish some testing (i.e. I have no idea what will happen with snapshots enabled), as well as implement the removal of old .zst archives based on age or count limits, but the base code seems to be working well on my test system. My current test VM is a single vdisk Windows 10 image, 30GB raw, 8 GB sparse, and compresses down to about 6.2GB. With the old compression turned on it took between 2-3 minutes to copy the 8 GB sparse vdisk over to the array (from a NVMe cache tier), and about 8 minutes to compress it. With the new compression turned on, it took between 1-2 minutes to perform the inline compression over to the array and then it was done. The CPU usage was marginally higher, but in either case the primary bottleneck was array I/O (turbo write enabled). This is running on my test UnRaid server which has a 4th Gen quad-core CPU (with not much else going on) and a 2x 2.5" 500 GB disk single parity array (writes cap out at around 80-90 MB/s). Obviously results will vary depending on other hardware configs and VM disks. I have .log files if interested.
-
I assume most people host their VM image files on faster storage (i.e. SSD or NVMe cache or unassigned devices) and write their backups to the array. The I/O performance bottleneck is mostly going to be with the array. Currently, the script copies the image files from source to destination and then afterwards compresses them. This results in writing uncompressed image files to the array, then reading uncompressed image files from the array, compressing them in memory, and finally writing the compressed result back to the array. (i.e. READ from cache -> WRITE to array -> READ from array -> COMPRESS in memory -> WRITE to array) So, what about an option to use inline (zstd) compression per image file and eliminating the entire post compression step? This would mean that all reads go against the faster storage tier and are compressed in memory prior to writing to the slower array tier. (READ from cache -> COMPRESS in memory -> WRITE to array). Something like this (possibly with options to tweak the compression level and number of threads): zstd -5 -T0 --sparse "$source" -o "$destination".zst instead of this (and the later tar/compression step): cp -av --sparse=always "$source" "$destination" In my testing, this dramatically reduces I/O and backup durations, and even results in slightly smaller archives (depending on compression levels chosen). Or, is there a reason the image files have to first be copied and later compressed? I might be able to whip up a pull request if that would be helpful.









