




Kaldek
Members
-
Joined
-
Last visited
Everything posted by Kaldek
-
Can someone tell me what the status is of snapshots on 7.3? I have a VM we tried to take a snapshot of today and it offered me the FS Native snapshot using ZFS. A snapshot was created and listed. We tried to revert it, and sure enough it disappeared. But the VM did not revert and no changes were rolled back. What gives? The Domains share is on the ZFS pool. It's a VM using qcow2. Is this not supported and just...silently breaks?
-
OK the logic was flawed. I kept going and found the actual root cause. I have some file backup trimming scripts that were still running on non-existent directories with poor logic. The directories didn't exist, and the file deletion runs in whatever directory cron is running from. You can see where this is going.
-
Currently running 7.3.0-rc1 but I loaded this to see if it fixed the issue. Was also occurring on 7.2. Error 404 when accessing the web GUI, happens every week or so. I let Claude have at this and it resolved the issue, but I can't speak for all of its logic. However, I did manage to get the web interface up again. After that, I ran diagnostics but I'm not sure what evidence it will have in it. Claude's summary below of what it found and how it got the GUI running again. SynptomsWeb GUI returns 404 SSH works fine diagnostics command exits silently with no output Array, Docker, and VMs keep running normally Syslog shows monitor cron failing every minute with exit status 255 CauseThe /usr/local/emhttp/webGui/ directory had been deleted from the /usr overlayfs (with lots of *- backup files left lying around in the plugins tree). PHP's auto-prepend file lives in webGui, so every PHP page failed to render → nginx serves 404/500. A reboot fixes access. Fix (no reboot)Mount the squashfs (/boot/bzmodules) to get pristine webGui files, copy them into the overlay's upper layer at /var/local/overlay/usr/local/emhttp/webGui/, then mount -o remount /usr so the kernel picks up the change. unraid-diagnostics-20260501-0945.zip
-
The "rebuild" has completed. This time when I asked it to format the disk it started and completed successfully. What a weird sequence of events.
-
Hi folks I am running unRAID 7.1.2 and have a 34TB array with 5 disks. I went to add a sixth disk today, one which had previously been precleared. I stopped the array and added the disk to the array, then restarted the array. unRAID reported the disk as ""unmountable: unsupported or No File System". The format option was available on the Main page, at the bottom, where the Start Array command is. Formatting failed, or more to the point it never even tried? Each time I refreshed the page, it would just offer the Format option again. So, I stopped the array and rebooted the server. Same problem. Stopped the array and tried adding a different disk to the array. The array just said "wrong" then, as if the first disk had already been successfully added to the array, even though it never formatted. So, array stopped again, then added the different disk. This time, it is now doing a complete flipping "rebuild" of a drive that was never formatted in the first place and never had any data on it! What the heck is going on here. unraid-diagnostics-20250519-1348.zip
-
I cannot reboot my unRAID server without terminating the diagnostics process, nor can I run diagnostics. This is because I have a share used by Frigate NVR called "cctv" with 53,000 small MP4 files inside it and 3,400 of these are on the cache right now. The diagnostics process tries to collect data on all of these files and when running diagnostics via the GUI the web interface hangs after a few minutes of reporting the logging of all these file names. At reboot time, all I see is "starting diagnostics collection". How do I stop collection of data on all these files so that diagnostics completes?
-
Unfortunately I do not have any diagnostics files from during this issue as the system insta-reboots when this issue occurs and leaves no logs at all. I recently enabled link bonding (active/backup) on unRAID 6.12.6 between a dual port Intel 10Gb/s XFP module (ixgbe driver) using eth0, and the onboard gigabit Intel NIC (igb driver) at eth2. My server started rebooting every few days, with no pause for kernel dumps or anything. The issue did not go away until I removed the active/backup link bond and shut down the eth2 NIC again. Some additional useful information is that, whilst in the same Layer-2 broadcast domain, eth0 and eth2 are connected to different switches. Diagnostics file attached but note that it does not have the active/backup config in it. unraid-diagnostics-20240110-1155.zip
-
Was this plugin never updated? Is it now an orphaned plugin?
-
Support had to do a manual key replacement to fix this issue. I literally just listened to the unRAID podcast where the support guys were saying license key management was a major headache. Guess there's still a lot of work to do at the back end.
-
I have access to all that, and it looks like the image below. Unfortunately there appears to be no documentation on "Signing Out" a key and what that all means. It drives me up the freaking wall when I find this lack of documentation update. Documentation must never be delayed and must be part of the release process! It keeps a high workload on the tech support folks when there's just no need if the damned documentation would be updated.
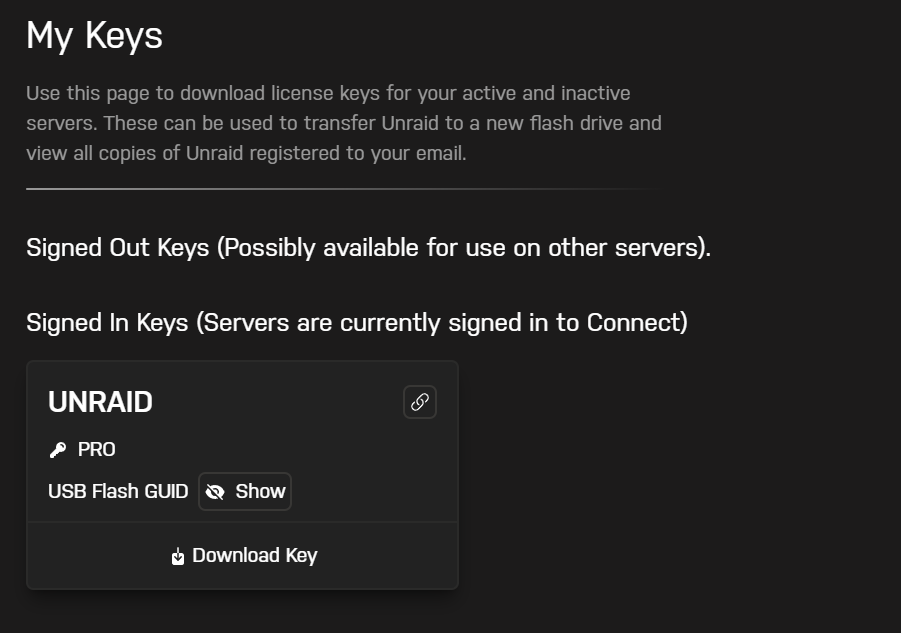
-
I bit the bullet and did it. I confirmed that keeping Pool Slot assignments also keeps ZFS pools.
-
I just installed a new DOM-based USB key for my server, following all of the instructions located at https://docs.unraid.net/unraid-os/manual/changing-the-flash-device. There is NO "Replace USB key" option, and it appears this is because I upgraded my license on the 14th of July. I have had this USB key for over four years. This is ridiculous, why is a license upgrade classed as a "key replacement"?
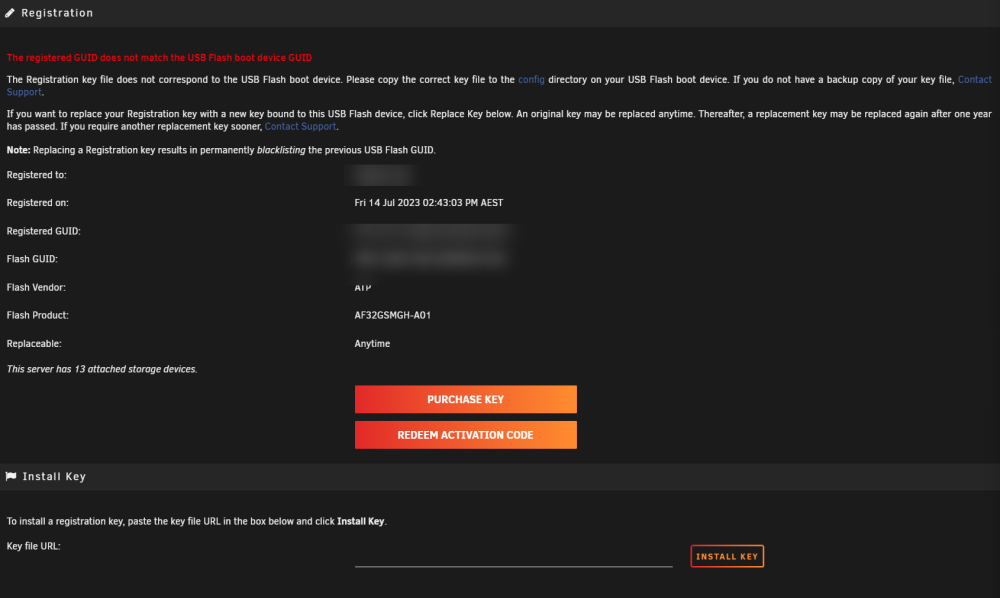
-
Folks it's a bit of a worry that I'm getting zero response to this question, and makes me scared to use ZFS on unRAID at all. Can *somebody* reply?
-
I will admit that my current flash drive - a SanDisk Cruzer Fit 32GB has lasted me a very long time without issue, when connected to a USB2 port.
-
Ah, I seem to have missed the part where you wrote you're running unRAID on a QNAS box.
-
Nobody?
-
Likely. Also I'm a bit surprised your motherboard has *no* USB2 headers. They're common even on new stuff, even it's only a single two-port header.
-
I burned through a few flash drives before using USB2 ports only. My current unit has lasted 3 years now. However, I am switching to a USB DOM (Disk On Module) shortly for some extra reliability. They are more expensive but use quality SLC flash. The only downside is that it's mounted to a motherboard header, and harder to get to. But, it should be unlikely I ever need to touch it.
-
I'm in the middle of some major array disk maneuvering which will require a "New Config" in a few days to remove some drives from the array. However, I have both a BTRFS cache pool (mirrored 1TB SSDs) and a ZFS RAIDz Pool of 4x 480GB Enterprise grade SSDs. All of my Appdata and Domains lives on the ZFS pool. If I lose that, I'm hosed. So, does the "New Config" option support keeping of both traditional "pools" and also ZFS pools? It just says "Pool Slots" but doesn't clarify if that will retain ZFS pools.
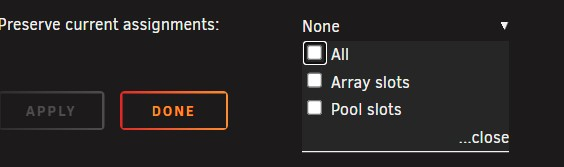
-
Hi folks, long time user here. Upgraded to 6.12 and then 6.12.2 and decided to create a 4-drive SSD ZFS RaidZ pool using some enterprise grade SSDs I was given, and use that pool for all my VMs and Docker containers. Everything went great, except when I moved the libvirt.img file from the old cache pool to the new zfs pool. Here's what I did: Set the system share to use the new ZFS pool Shut down the Docker engine via Settings-->Docker "mv /mnt/cache/system/docker /mnt/zfs-cache/system" Restarted Docker - no issues. Shut down the VM engine via Settings-->VM Manager "mv /mnt/cache/system/libvirt /mnt/zfs-cache/system" Validated that the file exists within /mnt/user/system/libvirt but physically exists only on the ZFS pool Attempted to restart the VM engine This gave me "libvirt service failed to start" and the system logs gave me a bunch of errors about btrfs saying that the "file already existed" and information about /dev/loop4 and duplicate entities. The issue went away after the reboot, but, why did it happen in the first place? I did not have this issue when I moved the docker.img file. Diagnostics file also attached. unraid-diagnostics-20230710-1317.zip
-
This issue appears to be occurring every few days. I can't ping any hostnames from the CLI, and /etc/resolv.conf is blank. I do not use DHCP for the server address, and my DNS servers are statically assigned. In addition, when it happens I am unable to reboot the server as the shares will never unmount as it constantly tells me /mnt/cache is busy. There are definitely no clients holding shares open when this happens. I have attached diagnostics of when the server is working, and will attach again when it next fails. I have made one change today after the last failure, and that was to disable IPv6. My dual stack ISP connection isn't always the best when it comes to IPv6 working all the time, so I've disabled IPv6 to see if that helps, since this seems to mainly be a network issue. unraid-diagnostics-20230521-1953.zip
-
For what it's worth, here's the code from my discussion with ChatGPT. This is - as yet - untested. But knock yourselves out if you want to see what was generated. Note that this script is intended to be run "After start of array". #!/bin/bash CONTAINER_NAME="frigate" # Wait for 2 minutes for container to start sleep 120 # Get the current container configuration CONFIG_JSON=$(docker inspect --type container --format '{{json .}}' ${CONTAINER_NAME}) # Extract the current command and entrypoint CMD=$(echo ${CONFIG_JSON} | jq -r '.Config.Cmd | join(" ")') ENTRYPOINT=$(echo ${CONFIG_JSON} | jq -r '.Config.Entrypoint | join(" ")') # Extract all options from the HostConfig property HOST_CONFIG_OPTIONS=$(echo ${CONFIG_JSON} | jq -r '.HostConfig | to_entries | map(select(.key != "Devices")) | map("--" + .key + "=\"" + (.value | tostring) + "\"") | join(" ")') # Replace the USB device option with the new bus ID HOST_CONFIG_OPTIONS=$(echo ${HOST_CONFIG_OPTIONS} | sed 's@--device="/dev/bus/usb/004/002@--device="/dev/bus/usb/004/003@g') # Extract the image name IMAGE=$(echo ${CONFIG_JSON} | jq -r '.Config.Image') # Build the new container run command NEW_CMD="docker run --name ${CONTAINER_NAME} ${HOST_CONFIG_OPTIONS} ${ENTRYPOINT} ${CMD}" # Stop the existing container docker stop ${CONTAINER_NAME} # Run the container with the new configuration eval ${NEW_CMD}
-
Not technically true since I have it working as long as I boot the container twice with the two different USB bus entries.
-
Depends what the question is but yes, it's amazing for turning ideas into code. I don't trust it 100% of course, and I'm using it to give me ideas and examples. I get to bypass all the grief I'd get by asking a human. In my view, these generative AI models are necessary. The amount of time we all burn on questions when the respondee of the question has their own emotions around the question and how they want to answer it is utterly insane. ChatGPT in particular has a very simple, concise and objective response to everything asked of it. The trick is knowing how to phrase your questions, hence the term "prompt engineering". I'm much better at this than I ever was at "Google-Fu".
-
So folks my unRAID server has an Intel server NIC in it with dual XFP ports and runs the ixgbe driver. Over a few uNRAID revisions now, there are random instances where the NIC driver dies (and yes, I uploaded the diagnostics files when it happened). There's really been no solution to this issue, and it of course usually happens when I'm overseas for work and it's 12+ hours before I can remote in to PikVM and bounce the server to get the network back up. I got a little tired of this, so here's the result of me and ChatGPT4 having a bit of a discussion about how to deal with it automatically. The solution documented here is a pair of User scripts, one a "Ping Watchdog" and the other a supervisor for the watchdog (in case the watchdog dies). Here is the watchdog script, called "ping_watchdog" and is running a ping against a pair of IP addresses (my core switch and my gateway) so that one single IP being down doesn't trigger the reboot. Sometimes my gateway is off the air for a while as I do some arcane Mikrotik things on it. This script is set to run at the first array start only and stays running forever (unless it dies for some reason; see the supervisor script below). #!/bin/bash TARGET_IP_1="192.168.0.254" # Replace with your gateway router IP address TARGET_IP_2="192.168.0.240" # Replace with your core switch IP address PING_COUNT=4 # Number of pings to send PING_TIMEOUT=5 # Timeout for each ping in seconds FAIL_THRESHOLD=30 # Number of consecutive failed ping checks before restarting CHECK_INTERVAL=60 # Time in seconds between ping checks failed_pings=0 ping_check() { local target_ip=$1 ping -c $PING_COUNT -W $PING_TIMEOUT $target_ip >/dev/null 2>&1 return $? } while true; do ping_check $TARGET_IP_1 result1=$? ping_check $TARGET_IP_2 result2=$? if [ $result1 -ne 0 ] && [ $result2 -ne 0 ]; then failed_pings=$((failed_pings + 1)) echo "$(date) - Pings to $TARGET_IP_1 and $TARGET_IP_2 failed. Consecutive failed ping checks: $failed_pings" else failed_pings=0 fi if [ $failed_pings -ge $FAIL_THRESHOLD ]; then echo "$(date) - Restarting unRAID server due to $FAIL_THRESHOLD consecutive failed ping checks" /usr/local/sbin/powerdown -r exit 0 fi sleep $CHECK_INTERVAL # Wait for the specified time before the next iteration done Next is the "ping_watchdog_supervisor" which is set to run every hour. If the first script is seen as not running, it kicks it off again. #!/bin/bash PING_WATCHDOG_SCRIPT="ping_watchdog" pid=$(pgrep -f "^/bin/bash.*/tmp/user.scripts/tmpScripts/$PING_WATCHDOG_SCRIPT") if [ -z "$pid" ]; then echo "$(date) - Ping watchdog script not running. Restarting..." /usr/local/emhttp/plugins/user.scripts/start_script.sh "$PING_WATCHDOG_SCRIPT" else echo "$(date) - Ping watchdog script running with PID $pid" fi Coupled together, these two scripts ensure that if my NIC ever dies, uNRAID performs a clean reboot without hurting the array.


