




Kaldek
Members
-
Joined
-
Last visited
Everything posted by Kaldek
-
Hi folks. About to upgrade to Frigate 0.12.0 in case that answers this but I have an issue with my Frigate install on unRAID. That is, my Coral TPU busID changes after Frigate loads the Tensor code into it. At boot time this device is at /dev/bus/usb/004/003 but it then flips to /dev/bus/usb/004/002 after Frigate loads the Tensor software into it. I'll be damned if I'm going to run this container as privileged and expose all of /dev/bus/usb to it, just to deal with that issue. Right now I'm in the middle of a rather long chat with GPT4 about how we can get around this issue (currently, dumping the JSON config of the running container, finding the BusID, changing it and then restarting the container with the Google-ified BusID using the same JSON code method). Total pain in the ass of course just to flip a couple of bits and then restart a container. Don't suppose 0.12.0 resolves that issue with the Coral TPU by any chance?
-
Hi mate, I have set up the Docker container from the official repo and it's working well, with a few items that I suspect you are a good source to discuss them with: Access via the tunnel to the myunraid.net URL does not work unless I set TLS to "Yes" rather than "strict" so that it uses the self-signed certificate (and I set TLS verification to off in the Cloudflare portal What is the correct setup if the internal host is accessed via DNS (e.g. host.mydomain.local) rather than IP address? It's literally day 1 here so these are questions I would probably be able to work out later anyway. Figured it can't hurt to ask.
-
So Linux Tech Tips just released this video about server grade USB 2.0 storage which should be excellent for unRAID OS. What are the community thoughts on this?
-
Hi there, I've just started using this. It's working great, thanks for your efforts.
-
Perhaps the better question is whether Limetech are aware they are actively being probed to find a way in. It happened to Solarwinds, it can happen here. It's just way too easy to do this stuff and is asymmetric warfare. We get one chance to detect the breach whilst the attacker has unlimited time to perfect it by finding even the remotest weakness and using that as the beachhead.
-
As someone whose full time job is InfoSec for a multinational, I need to reply here. Saying not to expose stuff to the Internet is obvious but it doesn't remove the problem. The biggest concern I have with unRAID is a supply chain attack, and unRAID is popular enough now that e-Crime actors will already be looking at targeting the platform. The question is this: who validates all the plugins etc to make sure they don't have malicious code in them or the ability to subsequently download malicious payloads? Never mind Docker or VMs, those are the responsibility of the end user - period. The risk is going to come from the commonly used plugins that everyone uses: Unassigned Devices Nvidia Fix Common Problems Nerd Tools Preclear disks etc So, what's Limetech's response? Better to get ahead of this before it actually happens. if the risk lies with the end user for 3rd party plugins the link to this in customer agreements need to be pointed out.
-
My server using an Intel dual-port 10Gb XFP NIC is routinely removing the driver with the following syslog message which removes all network connectivity. Mar 17 08:18:19 MU-TH-UR kernel: ixgbe 0000:03:00.0: Adapter removed Mar 17 08:18:19 MU-TH-UR kernel: ixgbe 0000:03:00.0: Warning firmware error detected FWSM: 0xFFFFFFFF I have serial console and local access so I am at least able to bounce the server to bring it back. Diagnostics file attached. Not sure what to do here as I cannot find any references to firmware error 0xFFFFFFFF and can only find references to error 0x0118801B and 0x00000000. I note the driver used in 6.9.1 is Intel version 5.10.21 and there is a 5.11.3 available which mentions "bug fixes" (no details provided). mu-th-ur-diagnostics-20210317-0927.zip
-
I agree with this. I recently went back to unBALANCE and went to move half of my videos folder (just movies) from my current Videos drive to the other three, with an expectation it would do what unRAID shares does - try to balance how much of a disk is used (depending on settings of course). It is, really, a "fill up each disk in sequence" effort rather than a re-balance. So, now I'm gathering everything back onto my Videos drive and will have to manually balance my existing content by creating a new share and copying everything to the new share to let unRAID manage the disk usage balancing. When finished, I'll have to rename the shares.
-
To update this topic for those using USB serial adapters (which I assume is realistically most of us), so far I have not managed to get kernel boot and shutdown messages to show but you can at least get the ability to login via the USB serial port. Essentially, you don't need the "SERIAL 0 115200" line, nor the changes to the "append" line" at all to get the ability to login via the USB serial adapter. Getting the ability to login via the USB to serial adapter only requires the addition to the /boot/config/go file as follows: sed -i -e "/^#s1/ i s1:12345:respawn:/sbin/agetty -L ttyUSB0 115200 vt102" /etc/inittab Note that my device is ttyUSB0 and it's set to 115200 baud rate as I'm connecting from a Mikrotik router. This will allow you to login via serial. What it won't do is let you see kernel messages via the serial port. There's a couple of issues with even trying to do this, including the fact that the USB driver loads quite late in the boot order and so you won't see a whole bunch of boot messages anyway. I am still looking into whether I can get kernel events posted to the USB serial console but for now this should help anyone who would like to restart their unRAID server even if network connectivity gets lost due to a NIC module errors or macvlan callbacks that kill the network stack. You may ask "what is the point since you can just walk up to the monitor and login via keyboard" but if I'm away from home and my unRAID server barfs, the ability to connect to it via serial through my Mikrotik router using Serial Terminal means I can kick it in the pants even without fancy stuff like an iLO card. My Mikrotik gear is the most reliable stuff in the house, so it makes sense to use this as the pivot point (I even use this for my VPN rather than a VPN container in unRAID). It may ultimately be that because USB is loaded so late in the kernel boot process, anything more than just basic login capability is a lost cause. I haven't given up yet, but it's very possible this is the case. For those of us that are desperate, I recommend a dedicated serial port as a hardware UART serial port will be loaded very early by the Linux kernel. There are a bunch of PCI-e serial port cards you can buy for this purpose.
-
These keep cropping up on RC2. I've had a couple of callbacks related to netfilter, as well as some kernel panics. Two examples posted as well as my diagnostics file, however note that at the time of this diag file I had stopped my Shinobi Pro docker container which I could swear is the catalyst. I am leaving Shinobi disabled to see if unRAID stays up longer. I mark this as "Urgent" only because system stability is really poor at the moment. mu-th-ur-diagnostics-20201222-1354.zip
-
I for one would be happy to move to subscription licensing. Even if that means free upgrades for XXX years in one purchase, further cost if you want to upgrade after that. I get people's concern, but devs have to eat. As for the statement about not liking "forcing people to update", as an InfoSec guy that kind of thinking drives me mad. The amount of back doors and crap I have to deal with on a daily basis due to old software is ridiculous. I just spent the last 6 months fighting hard to ensure our desktop standard going forward is cloud-first, Azure AD Joined and up-to-the-minute patched for our supported software. Your app not work with Windows 10 20H2? Get the vendor to fix it as it's not on the supported software list. What has to change is not the need to update software, it's the resistance to change that has to go, which also means that systems and applications need to be coded so that unexpected downtime related to the update is eradicated.
-
Got this rather odd Kernel Panic from unRAID 6.9.0-rc1 that appears to be caused by nf_nat_setup which is part of netfilter. mu-th-ur-diagnostics-20201214-0924.zip
-
I'll add some experience here with Shinobi Pro. I recently downgraded my unRAID server from an i7-6950X to a Xeon E5-2630L and thought it would be a good idea to use the hardware decoding of my Quadro P400 GPU to save CPU cycles and therefore power consumption, plus leave more headroom for other containers and VMs. Anyway it turns out that this actually increased my power consumption and the stability of Shinobi was a bit all over the place. I suspect it was also the cause of it consuming all of my memory (prior to me setting an 8GB limit as discussed by others previously). I've now allocated three CPU cores (inc. the hyperthread, so 6 virtual cores) and it's handling 5 cameras at 2560*1920 15FPS at 40% CPU across those cores.
-
It looks like this:
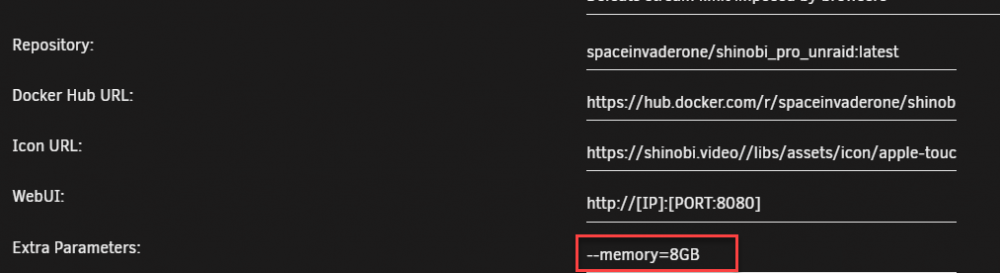
-
Never mind I just doubled the size of my docker image.
-
Hello folks, my Shinobi pro container is consuming 5.5GB of disk space within docker.img: root@unraid:/var/lib/docker/btrfs/subvolumes# docker ps -s CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE b01cdfb65ee9 spaceinvaderone/shinobi_pro_unraid:nvidia "/opt/shinobi/run.sh…" About an hour ago Up 3 seconds shinobipro 180MB (virtual 5.51GB) Any idea what's gone wrong here? This is causing my docker.img disk usage alert to keep tripping as it's now over 75%.
-
My unRAID 6.9.0beta35 (required as I'm running Nvidia acceleration) keeps having issues with the intel dual-port XFP card which is installed. This card uses the ixgbe module. The behaviour is that the machine loses network connectivity. Link lights stay up but the OS unloads the module. I get these errors which happen frequently. If they self correct it keeps going but if it fails with a fatal it requires a reboot: I only have an image of the fatal error unfortunately rather than text.

