broncosaddict
Members
-
Joined
-
Last visited
Everything posted by broncosaddict
-
On the scheduler tab (screenshot 3), mover shows running...and I can verify files are being moved. On the Main page and from command line (screenshot 1 and 2) it is not showing mover is currently running. I don't know about the command line, but normally, the Main page indicates mover is running. holmes-diagnostics-20241013-1022.zip
-
Docker is showing it consumes 12% of the memory which it calculates to be 206G. I only have 128G. The other 3 look to be accurate. holmes-diagnostics-20240404-1847.zip
-
I Love you man!!! Never knew this was even a thing....I've always been adding dockers back one at a time. 😞
-
I know what you mean, it's annoying....just hasn't been annoying enough for me to do any digging. Great find! Thanks, you saved from having to do any digging. 🙂
-
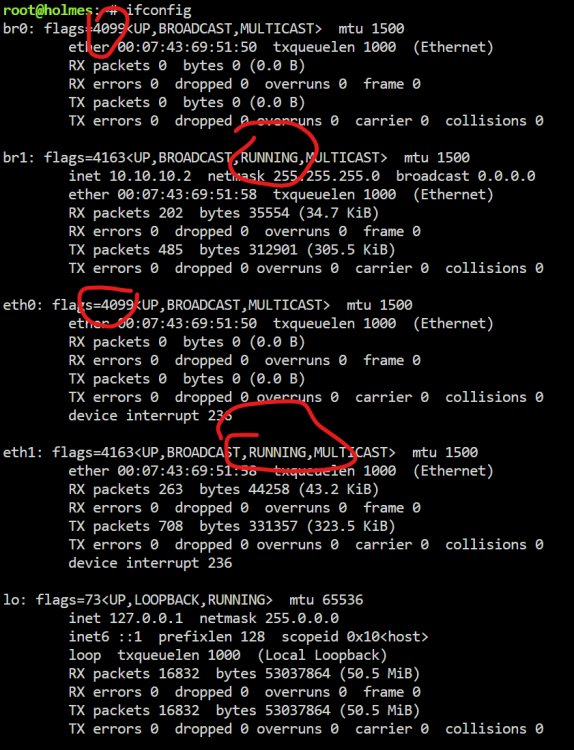
2 ports on each server. 1 port on each server going to switch, 1 port direct connect to the other server (static IP, different subnet) Why a direct connection? Lots of data moving back and forth between them, keeps the traffic off the switch, is a good deal faster.....plus, I had nothing else to do with the ports 🙂 eth1 is the direct connect with the other server, and yes, I noticed eth0 was missing the "RUNNING" piece (I posted a screenshot and talked about it in the first post) This next question actually didn't have anything to do with the problem, but it put me in a position to see the problem!! (I'm such an idiot) What happens when I remove the direct connect? I hadn't even thought to try that since I wasn't having an issue with that port, so I was going to give it a shot, I had nothing to lose. I went to the server and traced both cables coming out to make sure I was going to pull the right one. I had gone over the cables many, many times over the last couple of days, verifying where they were going and reseating the connections on both ends....but it never sunk in and clicked. It wasn't going into the switch, it was going directly to the spare port on my opnsense server. A few months ago, I moved it from the switch to the spare port. It had been in the switch for a couple of years, so it was ingrained in my head that it was connected to the switch regardless of what my eyes were telling me. When I was running untangle I had bridged the interfaces so it was all the same network/subnet. When I moved to opnsense on Saturday, I completely forgot about the creating the bridge....even though I had a screenshot of the old setup showing the bridge. Not only did I not bridge the interface, but I also disabled it. So there was no way the server was going to be talking to anybody from that port. Once I recreated the bridge, everything worked as expected. I just had to go through and undo all the changes in unraid I made during troubleshooting. So long story, short, Thanks for the nudge!!....I was finally able to sleep peacefully 🙂
-
I've tried using the default parameters from that note I've referenced, I tried using the same network.cfg as the working server, tried removing it so it would rebuild, all nada. You did have a couple of parameter I hadn't tried, I added them in and gave it a bounce, no joy. Same as my tests with hardcoding the ip. Regarding the ports, yes they are both dual port. Both have one going to a switch and the other going to the other server. I don't have any reason to suspect it, but I have a feeling something in the firewall may be screwing things up....I just don't know what. I would also think both servers would be equally affected. Aside from the dhcp static settings, it's pretty vanilla. Once I had everything working/functioning I would go back and tighten the screws so to speak. Currently the rules are let anybody on the LAN see/access everyone else on the LAN.....it's also all one subnet. Here is the network.cfg I just rebooted with: # Generated settings: IFNAME[0]="br0" DHCP_KEEPRESOLV="no" DHCP6_KEEPRESOLV="no" DNS_SERVER1="192.168.1.1" BRNAME[0]="br0" BRNICS[0]="eth0" BRSTP[0]="no" BRFD[0]="0" PROTOCOL[0]="ipv4" USE_DHCP[0]="no" IPADDR[0]="192.168.1.7" NETMASK[0]="255.255.255.0" GATEWAY[0]="192.168.1.1" METRIC[0]="1" IFNAME[1]="br1" BRNAME[1]="br1" BRSTP[1]="no" BRFD[1]="0" BRNICS[1]="eth1" PROTOCOL[1]="ipv4" USE_DHCP[1]="no" IPADDR[1]="10.10.10.2" NETMASK[1]="255.255.255.0" SYSNICS="2"
-
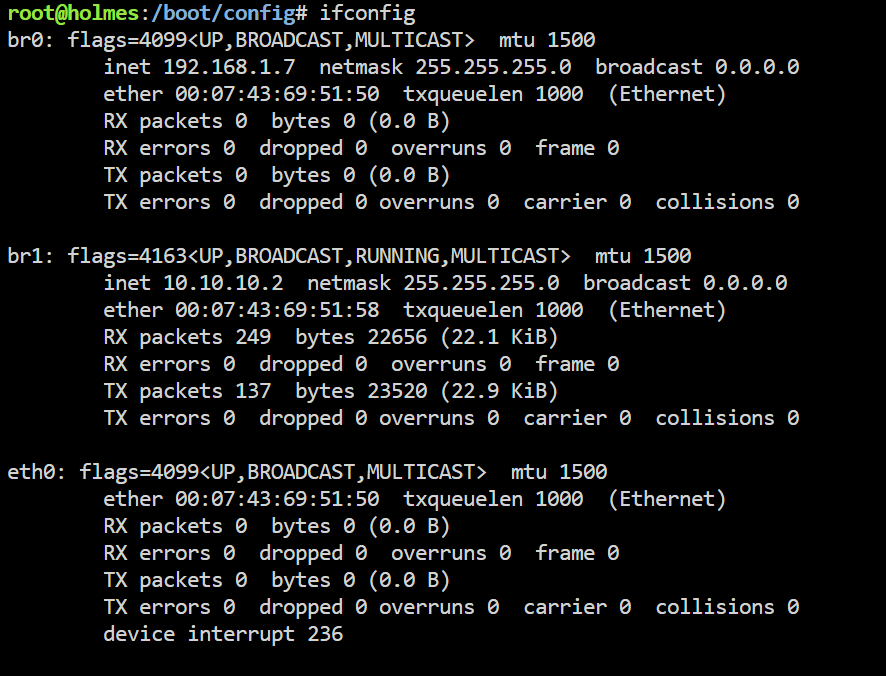
So yesterday was an adventurous day where I probably made more changes at once than I should have. 1) Changed firewall: Untangle -> opnsense w/ zenarmor and surciata 2) Changed the host name of the servers 3) Changed the static dhcp ip for the server I have 2 unraid servers configured very similar, both of them same subnet, same changes to both, etc. I have direct 10g wire between them as well and they both use the same make/model 10g card (chelsio) 1 servers behaved exactly as expected (no issues) with the changes. Works and accessible just as it was before. The other server, no matter what I do, the interface will not pick up an IP address. I can hardcode an IP and it takes it, but it doesn't look like the interface is active....and no matter what I do, I can not access it via the GUI except when connected directly to the server. When I try to ping the gateway, I get the network is unreachable. I can ssh between the servers via the direct link, but those are static ip's and it sets it up correctly everytime. I changed the static dhcp entry on the firewall to a different IP in case it was somehow used already. I tried removing the static dhcp and just have one assigned. I've tried removing the network.cfg file I've tried updating it with default values using this post: One thing I have noticed that stays consistent is never changes from having a flag of 4099 and never shows RUNNING on br0/eth0. Comparing it to the other server, it should be 4163 and show RUNNING. Additionally, at the end of the eth0 entry is an error "device interrupt 236", originally it was 140, I don't know if the change is progress. Comparing to the other server, I do know it shouldn't be there. Scouring the web, I cannot find any information on the 140 or 236 interrupt's or even a hint at what they might mean. I did find the flags are decimal versions of some hex values reflecting card settings, but none on how to control/change those values. No matter what I do I can't get it working...at this point I haven't the foggiest idea on what to try or look at next. I'm hoping somebody can shed some light my way... I have attached diagnostics. EDIT: Forgot to mention, I believe it's when I remove network.cfg and reboot. It assigns an IP from a different subnet and has all the interfaces bonded. The interface still isn't active. While I will take anything at this point, I don't want any of them bonded, which is the way they both are/were configured when it was working. holmes-diagnostics-20240317-1744.zip
-
I may be misunderstanding what each is displaying, but my SYSTEM tile memory usage is not aligning with memory usage shown on docker tab. The system tile is showing 7.6 GB used out of 125.3GB, but looking at the docker page, they alone are consuming about 14.5GB out of 125.3. I would expect the RAM on the SYSTEM tile to be at least 14.5G...plus whatever memory is being used elsewhere on the server.
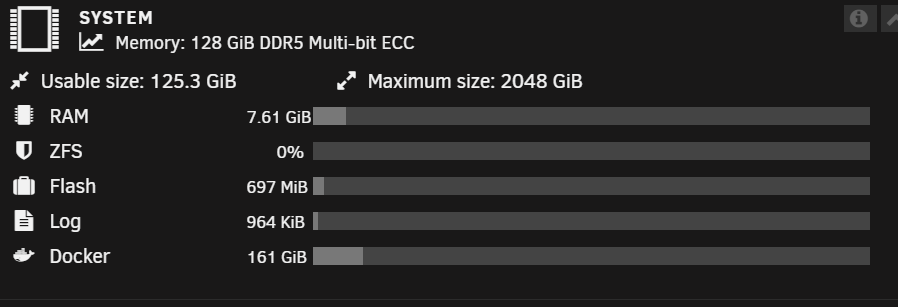
-
Not a problem, happens to me all the time between bash and pl/sql. The solution you provided with the script I think will actually work better for me as it mounts it immediately before the dockers start up. A couple of dockers reference the link and I always feel better when the share is mounted before they start. (I saw somewhere the normal automount function doesn't start until after docker) Thanks again for your help. Much Appreciated!
-
I just looked at the script log and I see what happened. I didn't really think about it, but just I cut and pasted your code in and only changed sleep 10 to sleep 300. What I assume you meant as comments used the // instead of #, so it caused sleep to fail due to syntax and ran the automount right away...which is why it mounted immediately after the array started. I am perfectly fine with this as a solution, I don't think you need to change any time delays. Let me know if you need/want any other testing. For the next week or so, I'll be working on setting everything up so it's not really "live" yet which means I can mess with it any way needed. Thanks for your help!!
-
So rebooted again and watched it. As soon as it the array and cache drives were mounted and turned green, the share went grey for about 5-10 seconds and changed to orange "UN-MOUNT". I timed it, I logged in immediately when the login page was displayed, the share was mounted in just under 2 minutes. Very odd considering the only thing we did was add a script to sleep for 5 minutes before doing the automount.
-
It never responds. I checked my other server as well as pc and same thing. Thinking about, I think set it somewhere to not respond to ping. I don't know if it matters, but in this particular case the mount would not be hitting the network. It is directly connected to the other unraid server and is pingable from the start. Something odd as well, I set the script to sleep for 300 (5 minutes), however once the array was done (maybe even before, I'll bounce again to confirm) the mount was mounted. Uptime of the server was 3 minutes....so it should have still been sleeping....right?
-
So the automount is working with the script....yay!! I'll bounce again to see about the ping and verify the automount still works.
-
I have no problem giving it a shot. Let me get the script in place and bounce.
-
Same output and that was before it even mounted the first disk of the array. I repeatedly ran it through the entire startup sequence thinking maybe it drops or hiccups, but it constantly returned the same 192.168.1.1 When the array finished the ud button went grey and after about 10 seconds or so it turned back orange saying "mount". Was running the command repeatedly during the entire time and it never hesitated or paused giving me the same output.
-
yea, that's not a problem. It takes a minute or two for the array to finish starting. Give me a minute
-
It returned the firewall/gateway IP. root@rivers1:~# route -n | awk '/^0.0.0.0/ {print $2; exit}' 192.168.1.1 root@rivers1:~# Do you want me to reboot and do it before the array gets up?
-
I thought that was the problem, the automount was starting before the network came up, wouldn't this delay the mount until after? Is it possible, the network not up is a false positive? I just rebooted it, logged in immediately, it was just starting to do the array. I open an ssh window and was able to resolve and connect to the other unraid server both via ip and server name. The array was still coming up when I finished those tests. Wouldn't that mean the network is actually up?
-
So the "Remote share mount wait time:" in the common settings is for something different?
-
Yep. I absolutely can. It does turn grey for a short time after the array is done starting, but then comes back to orange. Click and connects no problem. Is there anyway I can change the 2 minute delay to be longer? Ok. I'm a dork, it's right there is the config settings. I've upped it to 10 minutes...fingers crossed
-
No dockers, docker's not even enabled. No VM's, though it's enabled, have not created any. Don't know if it matters, but I'm not using any of the onboard ethernet, I have a 10g NIC, with one direct connect to the other unraid server (same type 10g NiC card) and the other to network. If the network was not up or was blocked, wouldn't that also block me from the unraid GUI?
-
I've been having problems with remote shares not automounting (it's never worked, I've always had to hit the mount button). I'm rebuilding/upgraded one of the servers and it still won't automount. I'm assuming I'm missing something somewhere, but for the life of me I can't figure it out. The share is from my other unraid server, both are at 6.12.6 using the latest UD plugin. Hoping someone can point me in the right direction. Thanks! rivers1-diagnostics-20240112-1345.zip
-
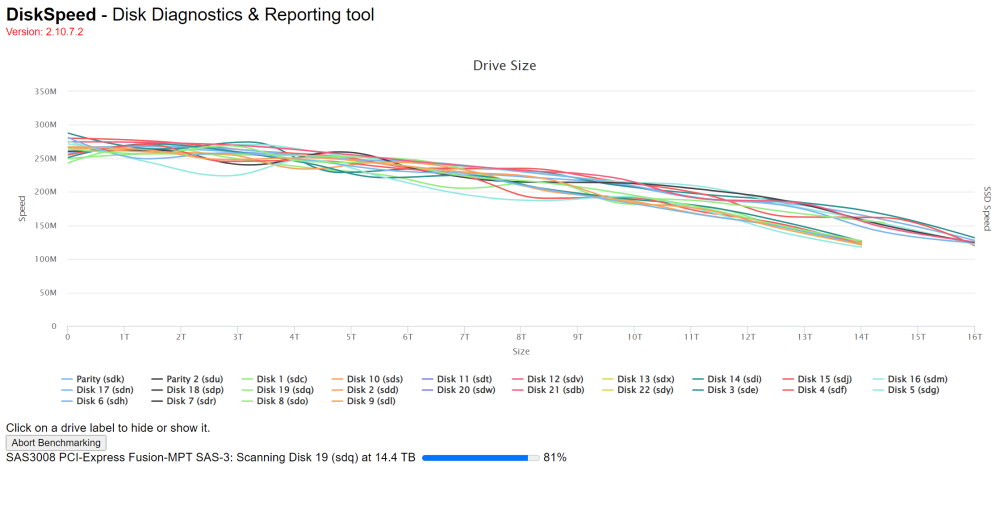
That resolved the issue, both servers finished without any issue. Thanks! Having never studied/reviewed this type of output before, I have a few questions regarding the output as I'm not really sure how to interpret what I'm looking at nor any actions I need to take. 1) The sharp drop of the black and yellow lines is bad? (start looking for replacements?) 2) The flat lines that remain below 50M the entire time. Same as number 1? 3) When it looks like a piece of a sine wave like the pink line. Is that the drive speeding up/slowing down and what is labeled a speed gap? 4) I'm confused with "Bandwidth was capped on Disk 15". Disk 15 is one those 3 flat lines that remain straight across below 50 the entire time. a) Is that because it's flat it interprets it bandwidth being capped? b) It mimics 2 other drives with the same line, why would they not be listed? c) What would cause a drive going so slow to have anything capped? 5) The verbiage at the bottom "A speed Gap was detected on a drive which means the amount of data reach from one second to the next...." a) How to determine which drive? b) Is "reach" a typo in "amount of data reach from"? I'm thinking you meant "received", but if not, what does that mean? 6) If you keep getting speed gap warnings, the solution is to disable speed gap detection, so why have the warning in the first place? --This is my older server so drives on their last legs is not surprising
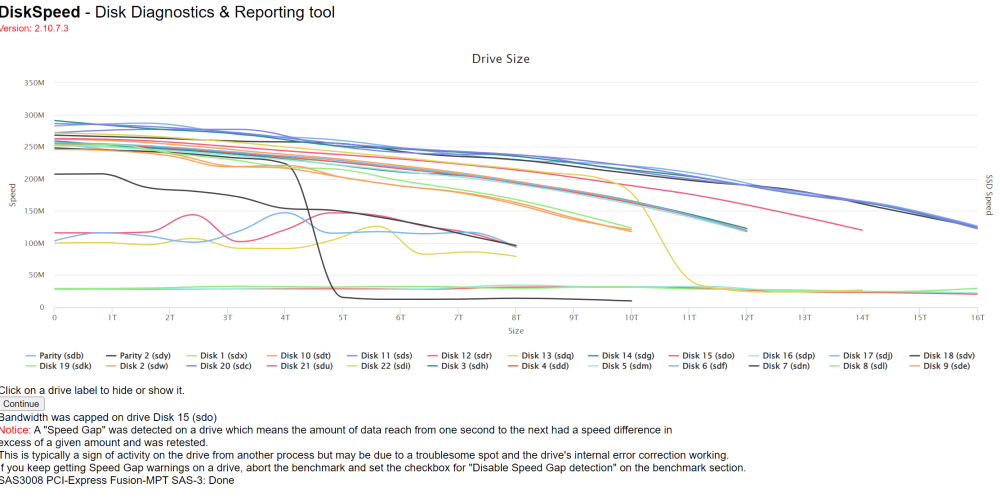
-
Thank you!! I will give it a shot tomorrow. So the parity check slowed down toward the end so it took 26 hours instead of the estimated 20 hours at the start....but that's still about a reduction of 50%....I'll take that every day and twice on Sundays. 🙂 Thanks again!!

-
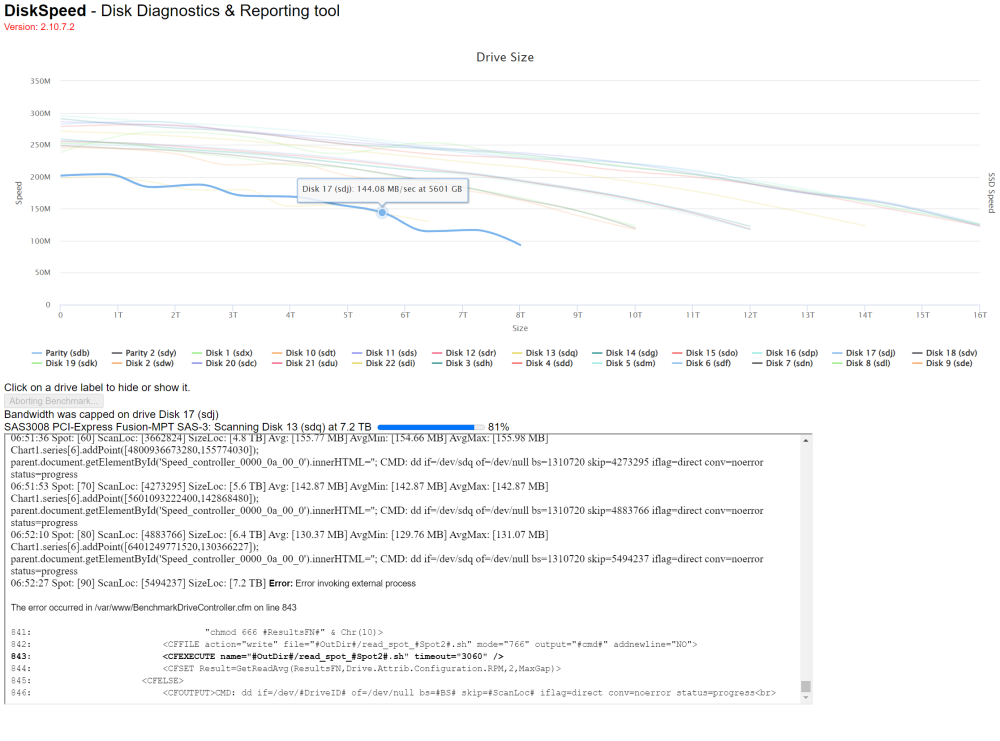
I was referring to my ssd's. When I drilled into them, the information was a little off. The vendor field was blank, but the vendor name was prepended to the model number....so I thought the information was being parsed incorrectly. I didn't see anything indicating retrying anything. If there's a way to shoot ones self in the foot, I will find it....so there's a very good chance that I am that someone. 🙂 I have 24 drives in each server. The above server still gets the error even with the speedgap box checked. The below server, also with speedgap box checked, just stops/freezes. The screenshots are where they errored (above) or froze (below). You mentioned a 50 minute timeout...I don't know if that's exactly how long they ran for but it's really close to about an hour when I either get the error (above) or it freezes (below)....is there a way for me to increase to see if it makes a difference.? --For the below server, there were a few changes since last time which may be why it no longer errors but freezes. 1) Changed out the backplane from 6g to 12g 2) Changed the hba from 6g to 12g 3) Dual linked the hba to the backplane (it had been single link) 4) Moved the hba from x4 to x8 slot (the card is x8) I suspect 3 and 4 had the most impact. Want to really, really thank you for this tool!! Until I ran the controller benchmark, I never realized my storage was so bottlenecked and misconfigured. Previously, my parity checks would take about 50 hours....running it now and it's flying, should complete it in about 20 hours. I have some changes to my other server as well based on what I learned with your tool. So again, thank you so much!!