Jarsky
Members
-
Joined
-
Last visited
Everything posted by Jarsky
-
Apologies I never replied. The new v6 Pi-Hole has the API @ pi.hole/api while the admin interface is still pi.hole/admin
-
I'm using the new v6 of Pi-Hole and the Prometheus Pi-Hole Exporter plugin. It's unable to connect to the API; and theres no configuration option in the plugin to change the target address 2024-05-03 15:56:11.607 WARNING API: Bad request (The API is hosted at pi.hole/api, not pi.hole/admin/api) 2024-05-03 15:56:26.604 WARNING API: Bad request (The API is hosted at pi.hole/api, not pi.hole/admin/api) 2024-05-03 15:56:29.006 WARNING API: Bad request (The API is hosted at pi.hole/api, not pi.hole/admin/api) 2024-05-03 15:56:39.005 WARNING API: Bad request (The API is hosted at pi.hole/api, not pi.hole/admin/api)
-
Since you have quite small disks, i'd change that Minimum free space to something like 10GB; or your disks are going to stop allocating data with 58GB free on them. As to the allocation; you're using High-water so it will try to fill up the disk to 50% then move to the next and do the same...then cycle back through them again. It does this progressively though; so if youre copying a large directory to the array it will allocate it all to the disk its currently targeted with High-water. You can read more about it in the docs here: https://docs.unraid.net/unraid-os/manual/shares/user-shares/#high-water-method Do you have other shares as well on these disks? The allocation is a per share setting; if you have other shares that are using Primary Storage "Array" then they will also affect how full the disks get in total Edit: If you want them to be as equal as possible; then change it from High-water to Most-free
-
Apr 21 03:00:21 Tower kernel: BUG: kernel NULL pointer dereference, address: 0000000000000030 Apr 21 03:00:21 Tower kernel: RIP: 0010:uncharge_folio+0xe/0xd8 Apr 21 03:00:21 Tower kernel: __mem_cgroup_uncharge_list+0x49/0x84 Apr 21 03:00:21 Tower kernel: release_pages+0x2de/0x30e Apr 21 03:00:21 Tower kernel: truncate_inode_pages_range+0x15a/0x382 These lines in particular from your logs are interesting; as they all pertain to memory management. The kernel panicked with a memory access issue; then the following messages all relate back to physical memory (only some relate back to swap). Also you updated the BIOS recently as your revision is from March 2024 Apr 21 03:00:21 Tower kernel: Hardware name: ASUSTeK COMPUTER INC. System Product Name/Pro WS W680-ACE IPMI, BIOS 3401 03/19/2024 Reading the notes for that BIOS; they have made changes to memory management PRO WS W680-ACE BIOS 3401 Version 3401 12.5 MB 2024/03/22 1.Improved DDR5 compatibility 2.Further optimized CEP settings when disabled I see in your logs you're running them at 4800Mhz; did you run them with XMP disabled (which IIRC is 3200Mhz)? Check that the RAM slots are free from any debret or dust as well. You could also try rolling back the BIOS revision; otherwise could be the CPU on it s way out, and the IMC (Integrated Memory Controller) is faulting. I had an issue with one of my Ryzen9's...it was always a bit buggy and the other day it just completely died (thankfully replaced under Warranty).
-
Nevermind. I was on 6.12.9 when this started. Upgraded to 6.12.10 yesterday. Unmounted and Remounted the VM's and other Servers today, and its all back to normal. I guess it was an issue with the fixes put in for SMB on 6.12.9? https://docs.unraid.net/unraid-os/release-notes/6.12.10/
-
Hi team, Just checking if something has changed with Unraid in regards to SMB/CIFS versions? UnRaid Version: 6.12.10 I've noticed just today that every single one of my VM's which is mounted the Samba shares is getting the error: $ df -h df: /mnt/share: Resource temporarily unavailable These are mounts on physically connected devices as well as VM's hosted on the UnRAID server itself. I have not changed configus on any of my machines. Theyre all Ubuntu 22.04 Servers. They're configured to use SMB v3; but have also tried changing some to auto which I believe is connecting at SMB v3.1.1 Still the same error. This isnt affecting NFS shares theyre mounting fine. The mounts are still accessible; however theyre sporadic. The problem im seeing is that the flow is getting disconnected so writes are failing for example. Apps are also reporting unknown disk size as the VMs arent properly calculating disk free Seeing these errors in the machines affected (locally hosted VM's as well as Network attached servers) jarskynas-diagnostics-20240420-2326.zip
-
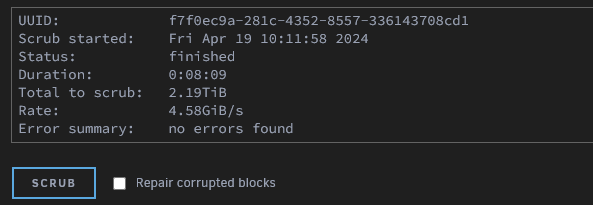
This is an old thread, but i've seen others having the same issue of being able to find the file associated. I just ran into it again yesterday after a power outage rebooted my server several times. So for records sake.... Select your pool, tick to "Repair Corrupted Blocks" and click "SCRUB"; you should see an error log like below: Apr 18 19:57:42 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 5, gen 0 Apr 18 19:57:42 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 5507816349696 on dev /dev/nvme0n1p1 Apr 18 19:57:46 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 5, gen 0 Apr 18 19:57:46 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 5507816349696 on dev /dev/nvme1n1p1 This gives you the device; if you have a lot of mounts you can check the mount point running this: root@TOWER:/var/log# cat /proc/mounts | grep '/mnt/' | grep -v -E 'tmpfs|shfs' /dev/md1p1 /mnt/disk1 xfs rw,noatime,nouuid,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0 /dev/md2p1 /mnt/disk2 xfs rw,noatime,nouuid,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0 /dev/md3p1 /mnt/disk3 xfs rw,noatime,nouuid,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0 /dev/md4p1 /mnt/disk4 xfs rw,noatime,nouuid,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0 /dev/md5p1 /mnt/disk5 xfs rw,noatime,nouuid,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0 /dev/md6p1 /mnt/disk6 xfs rw,noatime,nouuid,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0 /dev/md7p1 /mnt/disk7 xfs rw,noatime,nouuid,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0 /dev/md8p1 /mnt/disk8 xfs rw,noatime,nouuid,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0 /dev/md9p1 /mnt/disk9 xfs rw,noatime,nouuid,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0 /dev/md10p1 /mnt/disk10 xfs rw,noatime,nouuid,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0 /dev/md11p1 /mnt/disk11 xfs rw,noatime,nouuid,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0 /dev/nvme2n1p1 /mnt/cache btrfs rw,noatime,ssd,discard=async,space_cache=v2,subvolid=5,subvol=/ 0 0 /dev/nvme0n1p1 /mnt/nvme_mirror btrfs rw,noatime,ssd,discard=async,space_cache=v2,subvolid=5,subvol=/ 0 0 The one we're looking for here is /mnt/nvme_mirror We can then run an inspect-internal like below to find the culprit file that occupies that block root@TOWER:/var/log# btrfs inspect-internal logical-resolve -o 5507816349696 /mnt/nvme_mirror/ /mnt/nvme_mirror//VM/VM1/vm1.img So we can see that our offending file is /mnt/nvme_mirror/VM/VM1/vm1.img We can move this offending file somewhere else e.g mv /mnt/nvme_mirror/VM/VM1 /mnt/user0/share Repeat for any other offending logical block numbers reported. We can then re-run the scrub and should find no errors. Move the files back to their original directories Re-run the scrub one more time; and should still come back with no errors.
-
Hey im trying to do this as my telegraf just stopped working when I upgraded to Unraid 6.12 Heres the run command, but its failing even though the path to the entrypoint.sh file is correct. Any ideas? docker run -d --name='telegraf' --net='host' --privileged=true -e TZ="Pacific/Auckland" -e HOST_OS="Unraid" -e HOST_HOSTNAME="TOWER" -e HOST_CONTAINERNAME="telegraf" -e 'HOST_PROC'='/rootfs/proc' -e 'HOST_SYS'='/rootfs/sys' -e 'HOST_ETC'='/rootfs/etc' -e 'HOST_MOUNT_PREFIX'='/rootfs' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.icon='https://github.com/atribe/unRAID-docker/raw/master/icons/telegraf.png' -v '/var/run/utmp':'/var/run/utmp':'ro' -v '/var/run/docker.sock':'/var/run/docker.sock':'ro' -v '/':'/rootfs':'ro' -v '/sys':'/rootfs/sys':'ro' -v '/etc':'/rootfs/etc':'ro' -v '/proc':'/rootfs/proc':'ro' -v '/mnt/nvme_mirror/Docker/telegraf':'/etc/telegraf':'rw' -v '/run/udev':'/run/udev':'ro' --user=root --entrypoint=/mnt/nvme_mirror/Docker/telegraf/entrypoint.sh 'telegraf:1.7.1-alpine' 5e74b7db49a5a52cf0f26b0d4897f84fea8e1bcbef3e8a69e82d497e888915e7 docker: Error response from daemon: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: exec: "/mnt/nvme_mirror/Docker/telegraf/entrypoint.sh": stat /mnt/nvme_mirror/Docker/telegraf/entrypoint.sh: no such file or directory: unknown. The command failed.
-
I disabled the cache for all shares and moved the tdarr-temp share away from it (which was Cache only), deleted the tdarr-temp folder (even though it was empty), and ran the mover again and it cleared it this time. Moved the folder back to the cache and re-enabled it and its been fine since. Not sure what happened but for some reason the BTRFS Data "partition" just stayed as this "Data, single: total=16.00GiB, used=15.81GiB" even with multiple balance attempts. Sorted now though
-
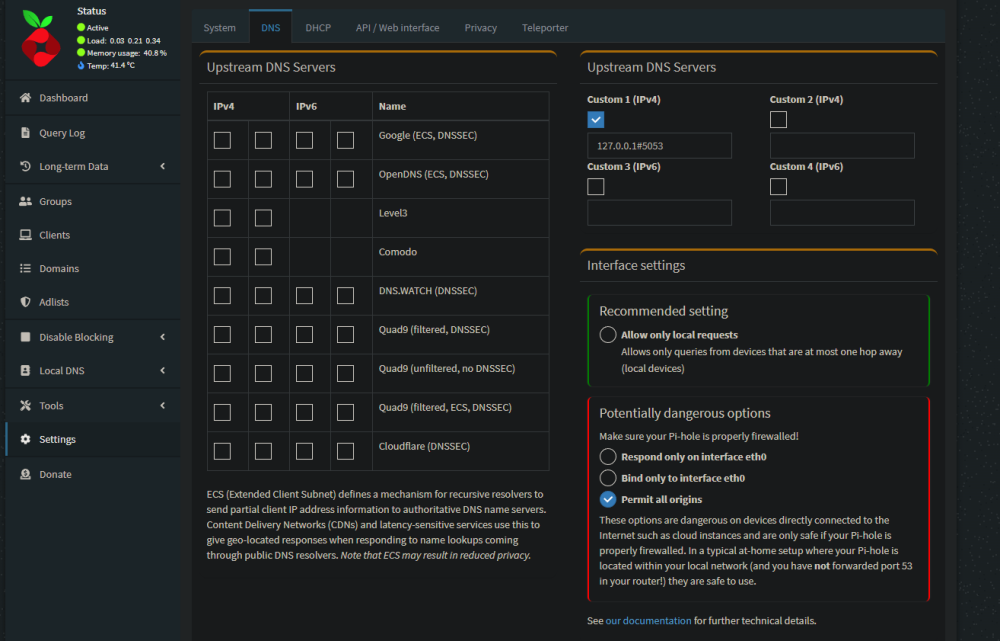
Since your VPN allocates IP addressess in a different subnet (10.253.x.x), in Pi-hole did you try change Interface settings to "Permit all origins" ?
-
I'm also having issues with constantly getting FlashBackups from Dynamix monitor.ini When a disk hits its warning threshold for temp or capacity then it modifies this monitor.ini file. We just moved into summer so my NVMe's have been going above 55C so been triggering FlashUpdate 30x or more per day. Ended up raising the temp limits and putting in a .gitignore for the monitor.ini file commit 567886bd602fe3cb5275d3226c1763ab542c1758 (HEAD -> master, origin/master) Author: gitbot <[email protected]> Date: Fri Dec 16 15:39:07 2022 +1300 Config change diff --git a/config/plugins/dynamix/monitor.ini b/config/plugins/dynamix/monitor.ini index 610b6e4..74c5dbe 100644 --- a/config/plugins/dynamix/monitor.ini +++ b/config/plugins/dynamix/monitor.ini @@ -14,3 +14,4 @@ parity.ack="true" [temp] cache="55" nvme_mirror="60" +nvme_mirror2="60" commit e91ca96edaaf3a23c86d1ec5df8214945ef9a617 Author: gitbot <[email protected]> Date: Fri Dec 16 15:33:07 2022 +1300 Config change diff --git a/config/plugins/dynamix/monitor.ini b/config/plugins/dynamix/monitor.ini index 4fe88ac..610b6e4 100644 --- a/config/plugins/dynamix/monitor.ini +++ b/config/plugins/dynamix/monitor.ini @@ -11,3 +11,6 @@ disk9="94" [smart] parity.187="1" parity.ack="true" +[temp] +cache="55" +nvme_mirror="60" commit dabafbd261a8709783feba83c394d33e7d445dfe Author: gitbot <[email protected]> Date: Fri Dec 16 14:58:05 2022 +1300 Config change diff --git a/config/plugins/dynamix/monitor.ini b/config/plugins/dynamix/monitor.ini index e1fd020..4fe88ac 100644 --- a/config/plugins/dynamix/monitor.ini +++ b/config/plugins/dynamix/monitor.ini @@ -11,5 +11,3 @@ disk9="94" [smart] parity.187="1" parity.ack="true" -[temp] -nvme_mirror="60"
-
Pulling the Warranty info from UnRAID isn't working. It wasnt working in 6.9.xx I'm now on 6.11.5. Tried deleting the database, uninstalling the plugin and reinstalling the plugin, but still not pulling the warranty info. All the Warranty info is agains the drives e.g But still not showing in DiskLocation, have tried rescanning as well.

-
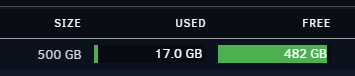
I just noticed today, that my cache isnt completely emptying. The BTRFS Data gets stuck at ~16GB usage. Any ideas on how to resolve, or do I need to reboot? root@TOWER:~# btrfs device usage /mnt/cache /dev/nvme2n1p1, ID: 1 Device size: 465.76GiB Device slack: 0.00B Data,single: 16.00GiB Metadata,single: 1.00GiB System,single: 32.00MiB Unallocated: 448.73GiB root@TOWER:~# btrfs scrub start /mnt/cache scrub started on /mnt/cache, fsid c20831e7-b715-430c-9d21-3fff9f3daae4 (pid=27825) root@TOWER:~# btrfs scrub status /mnt/cache UUID: c20831e7-b715-430c-9d21-3fff9f3daae4 Scrub started: Thu Dec 15 20:23:05 2022 Status: finished Duration: 0:00:04 Total to scrub: 15.82GiB Rate: 3.96GiB/s Error summary: no errors found root@TOWER:~# btrfs filesystem df /mnt/cache Data, single: total=16.00GiB, used=15.81GiB System, single: total=32.00MiB, used=16.00KiB Metadata, single: total=1.00GiB, used=17.89MiB GlobalReserve, single: total=20.45MiB, used=0.00B root@JARSKYNAS:~# btrfs filesystem du -s /mnt/cache Total Exclusive Set shared Filename 0.00B 0.00B 0.00B /mnt/cache root@TOWER:~# ls -la /mnt/cache total 16 drwxrwxrwx 1 nobody users 20 Dec 14 17:30 ./ drwxr-xr-x 19 root root 380 Dec 14 17:20 ../ drwxrwxrwx 1 nobody users 0 Dec 15 19:47 tdarr-temp/ root@JARSKYNAS:~# ls -la /mnt/cache/tdarr-temp/ total 16 drwxrwxrwx 1 nobody users 0 Dec 15 19:47 ./ drwxrwxrwx 1 nobody users 20 Dec 14 17:30 ../
-
Hey all, Just wondering if i've done this wrong....i'm replacing my 2 x Crucial P1 1TB NVMe's with 2 x Samsung 970 Evo Plus 2TB NVMe's in my secondary cache pool, which hosts my Dockers & VM's. The cache pool is a RAID1. I followed this FAQ, which said just to stop the array, replace the drive and select the new drive and start the array In the UI I can see that the BTRFS operation is running, and I can see some activity on the NVMe drives every now and then. I can see in the log that its relocating blocks Dec 12 15:04:11 TOWER kernel: BTRFS info (device nvme1n1p1): found 5463 extents, stage: move data extents Dec 12 15:04:22 TOWER kernel: BTRFS info (device nvme1n1p1): found 5463 extents, stage: update data pointers Dec 12 15:04:29 TOWER kernel: BTRFS info (device nvme1n1p1): relocating block group 1086715854848 flags data|raid1 Dec 12 15:06:18 TOWER kernel: BTRFS info (device nvme1n1p1): found 4546 extents, stage: move data extents Dec 12 15:06:22 TOWER kernel: BTRFS info (device nvme1n1p1): found 4546 extents, stage: update data pointers Dec 12 15:06:44 TOWER kernel: BTRFS info (device nvme1n1p1): relocating block group 1085642113024 flags data|raid1 Dec 12 15:08:47 TOWER kernel: BTRFS info (device nvme1n1p1): found 5386 extents, stage: move data extents But its excrutiatingly slow. It's been 2 hours and its only done 70GB which means its going to take approx a full day for less than 1TB on each of the NVMe drives. It also looks like its draining the secondary drive in the mirror, and putting it on drive 3 rather than to copy it. Is this normal behavior? I thought the new device should replace device 1? root@TOWER:~# btrfs device usage /mnt/nvme_mirror missing, ID: 1 Device size: 0.00B Device slack: 0.00B Data,RAID1: 788.05GiB Metadata,RAID1: 2.00GiB System,RAID1: 32.00MiB Unallocated: -790.08GiB /dev/nvme1n1p1, ID: 2 Device size: 931.51GiB Device slack: 0.00B Data,RAID1: 857.05GiB Metadata,RAID1: 3.00GiB System,RAID1: 32.00MiB Unallocated: 71.43GiB /dev/nvme0n1p1, ID: 3 Device size: 1.82TiB Device slack: 0.00B Data,RAID1: 69.00GiB Metadata,RAID1: 1.00GiB Unallocated: 1.75TiB root@TOWER:~# iostat -m Device tps MB_read/s MB_wrtn/s MB_dscd/s MB_read MB_wrtn MB_dscd loop0 0.00 0.00 0.00 0.00 0 0 0 loop1 0.00 0.00 0.00 0.00 0 0 0 loop2 0.00 0.00 0.00 0.00 0 0 0 loop3 0.00 0.00 0.00 0.00 0 0 0 nvme0n1 16.90 0.00 6.03 0.00 0 60 0 nvme1n1 78.30 0.18 4.53 0.25 1 45 2
-
I'm interested in this feature as well. My VM's & Dockers run on their own pool (NVMe mirror) so have nothing to do with the main array. Some of them may access an SMB/NFS share as a mount, but in the case where the array is down that mount will just go unreachable in the VM. Theres times I do storage maintenance like the last 2 weeks, where there shouldn't be a need for me to stop every Docker & VM to just replace/upgrade a drive in the primary array. I get this might be complicated though when users have VM's that have vdisks on /mnt/user
-
FYI: The UnRAID notification doesnt show any release notes. Proactively came here to check what the update is
-
Since it's late hours I decided to shut everything down and put the array into maintenance. The NVMe drives showed they were doing a bunch of read/write for about a minute. It seemed to correct the remaining BTRFS errors with the pool. Scrub started: Tue Aug 16 01:06:35 2022 Status: finished Duration: 0:23:17 Total to scrub: 1.53TiB Rate: 1.12GiB/s Error summary: no errors found
-
I already showed the syslog after a scrub above Aug 15 23:01:21 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 1, gen 0 Aug 15 23:01:21 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 513608630272 on dev /dev/nvme1n1p1 Aug 15 23:02:08 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 2, gen 0 Aug 15 23:02:08 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 189270196224 on dev /dev/nvme1n1p1 Aug 15 23:02:27 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 1, gen 0 Aug 15 23:02:27 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 513608630272 on dev /dev/nvme0n1p1 Aug 15 23:03:09 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 2, gen 0 Aug 15 23:03:09 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 189270196224 on dev /dev/nvme0n1p1 Aug 15 23:06:16 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 3, gen 0 Aug 15 23:06:16 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 380153503744 on dev /dev/nvme1n1p1 Aug 15 23:08:23 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 4, gen 0 Aug 15 23:08:23 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 1217718784000 on dev /dev/nvme1n1p1 Aug 15 23:09:18 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 3, gen 0 Aug 15 23:09:18 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 380153503744 on dev /dev/nvme0n1p1 Aug 15 23:09:34 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 5, gen 0 Aug 15 23:09:34 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 567391494144 on dev /dev/nvme1n1p1 Aug 15 23:09:42 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 6, gen 0 Aug 15 23:09:42 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 573802946560 on dev /dev/nvme1n1p1 Aug 15 23:11:45 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 4, gen 0 Aug 15 23:11:45 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 1217718784000 on dev /dev/nvme0n1p1 Aug 15 23:13:47 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 5, gen 0 Aug 15 23:13:47 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 567391494144 on dev /dev/nvme0n1p1 Aug 15 23:14:04 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 6, gen 0 Aug 15 23:14:04 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 573802946560 on dev /dev/nvme0n1p1 Aug 15 23:17:45 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 7, gen 0 Aug 15 23:17:45 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 1173223571456 on dev /dev/nvme1n1p1 Aug 15 23:18:44 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 8, gen 0 Aug 15 23:18:44 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 1263566585856 on dev /dev/nvme1n1p1 Aug 15 23:25:39 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 7, gen 0 Aug 15 23:25:39 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 1173223571456 on dev /dev/nvme0n1p1 Aug 15 23:28:13 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 8, gen 0 Aug 15 23:28:13 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 1263566585856 on dev /dev/nvme0n1p1
-
How can I identify the files though? Using inspect-internal its giving me nothing root@TOWER:/mnt/nvme_mirror# btrfs inspect-internal logical-resolve -v -P 513608630272 /mnt/nvme_mirror ioctl ret=0, total_size=65536, bytes_left=65520, bytes_missing=0, cnt=0, missed=0 root@TOWER:/mnt/nvme_mirror# echo $? 0 I thought from the remaining errors, they were a filesystem issue on nvme0n1p1?
-
I don't think theres an issue with my Ram. It's a Zen2 and has been running @ 3000Mhz for 2.5 years. Its only the single pool that has corruption. The array and cache have no errors. I already repaired the file that didnt pass checksum from my main array. I'm pretty confident the corruption occured when electricians switched off the power abruptly several times, and I dont currently have it on a UPS (since the last battery died). I've restored my VM from backup and updated it so no longer receiving checksum errors with the vdisk for that. However I still have uncorrectable errors on the pool. It's a mirrored pool, so what is the best way to resolve this? Can I break the pool, format the drive and resync? Or do I need to copy everything off that pool to somewhere else and reformat the pool?
-
Looks like from a scrub, the corruption is in a VM disk image. I have a backup from a few months ago, but is there any other repair activities I can do, short of restoring from a backup? Aug 15 18:48:14 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 795, gen 0 Aug 15 18:48:14 TOWER kernel: BTRFS error (device nvme0n1p1): fixed up error at logical 566991183872 on dev /dev/nvme0n1p1 Aug 15 18:48:14 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 796, gen 0 Aug 15 18:48:14 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 567391494144 on dev /dev/nvme0n1p1 Aug 15 18:48:21 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 797, gen 0 Aug 15 18:48:21 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 573802946560 on dev /dev/nvme0n1p1 Aug 15 18:50:44 TOWER kernel: BTRFS warning (device nvme0n1p1): checksum error at logical 824454868992 on dev /dev/nvme1n1p1, physical 729911062528, root 5, inode 819355, offset 12810076160, length 4096, links 1 (path: VM/Windows Server 2022/vdisk1.img) Aug 15 18:50:44 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 797, gen 0 Aug 15 18:50:44 TOWER kernel: BTRFS error (device nvme0n1p1): fixed up error at logical 824454868992 on dev /dev/nvme1n1p1 Aug 15 18:50:51 TOWER kernel: BTRFS warning (device nvme0n1p1): checksum error at logical 817108246528 on dev /dev/nvme1n1p1, physical 736523083776, root 5, inode 819355, offset 1667567616, length 4096, links 1 (path: VM/Windows Server 2022/vdisk1.img) Aug 15 18:50:51 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 798, gen 0 Aug 15 18:50:52 TOWER kernel: BTRFS error (device nvme0n1p1): fixed up error at logical 817108246528 on dev /dev/nvme1n1p1 Aug 15 18:51:01 TOWER kernel: BTRFS warning (device nvme0n1p1): checksum error at logical 835594616832 on dev /dev/nvme1n1p1, physical 745345777664, root 5, inode 819355, offset 7420325888, length 4096, links 1 (path: VM/Windows Server 2022/vdisk1.img) Aug 15 18:51:01 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 799, gen 0 Aug 15 18:51:02 TOWER kernel: BTRFS error (device nvme0n1p1): fixed up error at logical 835594616832 on dev /dev/nvme1n1p1 Aug 15 18:51:11 TOWER kernel: BTRFS warning (device nvme0n1p1): checksum error at logical 1063512186880 on dev /dev/nvme0n1p1, physical 666227712000, root 5, inode 819355, offset 9483952128, length 4096, links 1 (path: VM/Windows Server 2022/vdisk1.img) Aug 15 18:51:11 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 798, gen 0 Aug 15 18:51:11 TOWER kernel: BTRFS error (device nvme0n1p1): fixed up error at logical 1063512186880 on dev /dev/nvme0n1p1 Aug 15 18:53:36 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 800, gen 0 Aug 15 18:53:36 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 1173223571456 on dev /dev/nvme1n1p1 Aug 15 18:53:42 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 799, gen 0 Aug 15 18:53:42 TOWER kernel: BTRFS error (device nvme0n1p1): fixed up error at logical 967017721856 on dev /dev/nvme0n1p1 Aug 15 18:54:11 TOWER kernel: BTRFS warning (device nvme0n1p1): checksum error at logical 1234893328384 on dev /dev/nvme1n1p1, physical 940633542656, root 5, inode 819355, offset 6063378432, length 4096, links 1 (path: VM/Windows Server 2022/vdisk1.img) Aug 15 18:54:11 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 801, gen 0 Aug 15 18:54:11 TOWER kernel: BTRFS error (device nvme0n1p1): fixed up error at logical 1234893328384 on dev /dev/nvme1n1p1 Aug 15 18:54:23 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 802, gen 0 Aug 15 18:54:23 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 1263566585856 on dev /dev/nvme1n1p1 Aug 15 18:54:41 TOWER kernel: BTRFS warning (device nvme0n1p1): checksum error at logical 1145505271808 on dev /dev/nvme0n1p1, physical 868479881216, root 5, inode 819355, offset 9617289216, length 4096, links 1 (path: VM/Windows Server 2022/vdisk1.img) Aug 15 18:54:41 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 800, gen 0 Aug 15 18:54:41 TOWER kernel: BTRFS error (device nvme0n1p1): fixed up error at logical 1145505271808 on dev /dev/nvme0n1p1 Aug 15 18:54:42 TOWER kernel: BTRFS warning (device nvme0n1p1): checksum error at logical 1147382370304 on dev /dev/nvme0n1p1, physical 870356979712, root 5, inode 819355, offset 7115976704, length 4096, links 1 (path: VM/Windows Server 2022/vdisk1.img) Aug 15 18:54:42 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 801, gen 0 Aug 15 18:54:43 TOWER kernel: BTRFS error (device nvme0n1p1): fixed up error at logical 1147382370304 on dev /dev/nvme0n1p1 Aug 15 18:54:43 TOWER kernel: BTRFS info (device nvme0n1p1): scrub: finished on devid 2 with status: 0 Aug 15 18:55:26 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 802, gen 0 Aug 15 18:55:26 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 1173223571456 on dev /dev/nvme0n1p1 Aug 15 18:56:53 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 803, gen 0 Aug 15 18:56:53 TOWER kernel: BTRFS error (device nvme0n1p1): unable to fixup (regular) error at logical 1263566585856 on dev /dev/nvme0n1p1 Aug 15 18:57:17 TOWER kernel: BTRFS info (device nvme0n1p1): scrub: finished on devid 1 with status: 0
-
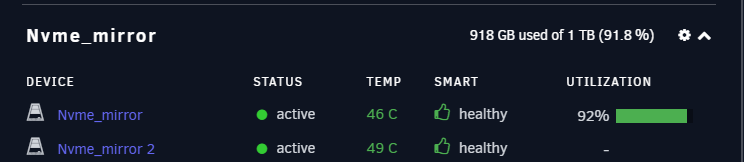
Hi all, I just logged into my UnRAID and noticed a popup about checksum issues from file integrity. On looking at the log, I realised there are ongoing BTRFS error notifications for my NVMe drives Im running UnRAID 6.10.3. ASRock X570 Taichi with 4.60 BIOS (November 2021). 2 x 1TB Crucial P1 M.2 NVMe's on the board. The drives are in a "cache pool" that are a Mirror, used for holding my Dockers & VM's I'm seeing these errors in the Log Aug 13 06:46:20 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 752, gen 0 Aug 13 06:46:20 TOWER kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 819355 off 11784499200 (dev /dev/nvme0n1p1 sector 1268009080) Aug 13 06:46:31 TOWER kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 819355 off 49962971136 csum 0x53014952 expected csum 0x26cf4179 mirror 2 Aug 13 06:46:31 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 753, gen 0 Aug 13 06:46:31 TOWER kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 819355 off 49962971136 (dev /dev/nvme0n1p1 sector 1671624720) Aug 13 07:52:39 TOWER kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 819355 off 50563215360 csum 0x4fe4c983 expected csum 0x7c3f67e3 mirror 1 Aug 13 07:52:39 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 754, gen 0 Aug 13 07:52:40 TOWER kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 819355 off 50563215360 (dev /dev/nvme0n1p1 sector 1019641256) Aug 14 02:06:16 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 755, gen 0 Aug 14 02:07:54 TOWER kernel: BTRFS warning (device nvme0n1p1): checksum error at logical 516561707008 on dev /dev/nvme1n1p1, physical 469262540800, root 5, inode 819355, offset 1276887040, length 4096, links 1 (path: VM/Windows Server 2022/vdisk1.img) Aug 14 02:07:54 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 756, gen 0 Aug 14 02:07:59 TOWER kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 757, gen 0 The NVMe drives look physically healthy from smartctl root@TOWER:~# smartctl --all -H /dev/nvme0n1 root@TOWER:~# smartctl --all -H /dev/nvme1n1 I ran a check on the file system with BTRFS, and im getting errors with nvme0n1p1 root@TOWER:~# btrfs check --force /dev/nvme0n1p1 root@TOWER:~# btrfs check --force /dev/nvme1n1p1 Is this an issue from space? I have 80GB total free left of the 1TB Do i need to delete/move data? Do i need to unmount it and run a repair? e.g btrfs check —repair /dev/nvme0n1p1 Some help would be appreciated jarskynas-diagnostics-20220815-1745.zip
-
Mine was embarssingly stupid. I had already generated new keys, it was the first thing I did. I assumed from the logs on the clients saying they were Active that it was finding the server so Wireguard was "running" Turned out after restoring, I needed to reactivate the Tunnel. Super basic, but perhaps for future there should be like a red banner or something saying the Tunnel isnt active, or that toggle should be red? Did a lot of unnecessary troubleshooting because it wasnt easily apparent that I needed to switch that being grey. Since I set up Wireguard so long ago.

-
Hi all, So a few days ago my USB failed for UnRAID. I formatted the USB drive and restored my flashbackup from My Servers. The server came back up and all my array etc...are intact fine. I also recently upgraded to the latest UnRAID 6.10.3 so WireGuard is now a native package as part of the OS.. I just had a reason to use my VPN now, and realised that my WireGuard VPN isn't working. I'm not sure if its from the upgrade or the restore, since I havent used the VPN for about a month or so. From testing,my clients do connect to Wireguard and show status Active. However nothing will load. On checking the log I see the error "Handshake for peer 1 (myipaddress:51820) did not complete after 5 seconds, retrying (try 2). I've tried deleting the VPN and recreating it, and recreated all my keys etc...but still no change. It looks like something happened to my UnRAID's networks perhaps I looked at the wg config in UnRAID (nano /etc/wireguard/wg0.conf) and noticed it should be trying to create some network rules PostUp=logger -t wireguard 'Tunnel WireGuard-wg0 started' PostUp=iptables -t nat -A POSTROUTING -s 10.253.0.0/24 -o br0 -j MASQUERADE PostDown=logger -t wireguard 'Tunnel WireGuard-wg0 stopped' PostDown=iptables -t nat -D POSTROUTING -s 10.253.0.0/24 -o br0 -j MASQUERADE PostUp=ip -4 route flush table 200 PostUp=ip -4 route add default via 10.253.0.1 table 200 PostUp=ip -4 route add 192.168.1.0/24 via 192.168.1.254 table 200 PostDown=ip -4 route flush table 200 PostDown=ip -4 route add unreachable default table 200 PostDown=ip -4 route add 192.168.1.0/24 via 192.168.1.254 table 200 I spun up a test machine, and tried to set this up with Wireguard and again I have the same issue with no data transfer. if I try and run these rules manually, I do get an error with adding the default rule "Nexthop has invalid gateway." This is the same on both my test and production UnRAID servers. root@Tower:~# logger -t wireguard 'Tunnel WireGuard-wg0 started' root@Tower:~# iptables -t nat -A POSTROUTING -s 10.253.0.0/24 -o br0 -j MASQUERADE root@Tower:~# ip -4 route flush table 200 root@Tower:~# ip -4 route add default via 10.253.0.1 table 200 Error: Nexthop has invalid gateway. root@Tower:~# ip -4 route add 192.168.1.0/24 via 192.168.1.254 table 200 root@Tower:~# When I look at network routes on both UnRAID servers, I don't see any entry for the 10.253.0.0/24 network root@TOWER:~# ip route show default via 192.168.1.254 dev br0 proto dhcp src 192.168.1.205 metric 1010 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 172.31.200.0/24 dev br-746f3d6b4b8d proto kernel scope link src 172.31.200.1 linkdown 192.168.1.0/24 dev br0 proto dhcp scope link src 192.168.1.205 metric 1010 Can anyone shed some light on how to get this working again?
-
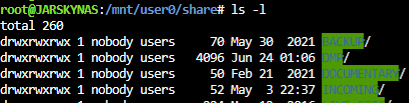
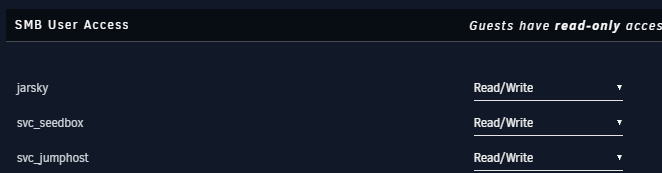
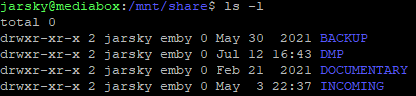
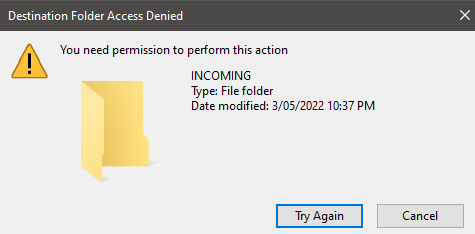
So today I had my USB stick corrupted. I downloaded my flashbackup, created a new flash drive and restored the flashbackup. My UNRAID server, array, VM's and Docker all came up successfully with no issues. However I noticed that my VM's which use service accounts to mount the share, are unable to write to the array. My share for example is named 'share' I checked /mnt/user0/share permissions and it still has the same permissions of nobody:users with 777 permission My VM's are using accounts such as "svc_jumphost"...I checked the SMB configuration in the GUI and svc_jumphost is indeed there, and it says that the user should have Read/Write . However when I try to create a folder on the share it gives me permission denied. Looking at the SMB mounts in the VM's, theyre missing the write permission, its the same wether im trying from one of my Linux or my Windows VM's both which use different Unraid user accounts Ive tried unmounting and remounting the shares, rebooting the VM's, rebooting UnRAID but stil the same. If I check the NFS share, I can write to that just fine; I just cant get the SMB shares to mount as writable. I can also write to my Public shares that are publically writable. Its only to the private shares, as if they are just mounting as guest rather than the privileged accounts. I've tried removing the mounts, and manually mounting them specifying the username & password for the privileged accounts, and theyre still mounting as read-only.