




s449
Members
-
Joined
-
Last visited
Everything posted by s449
-
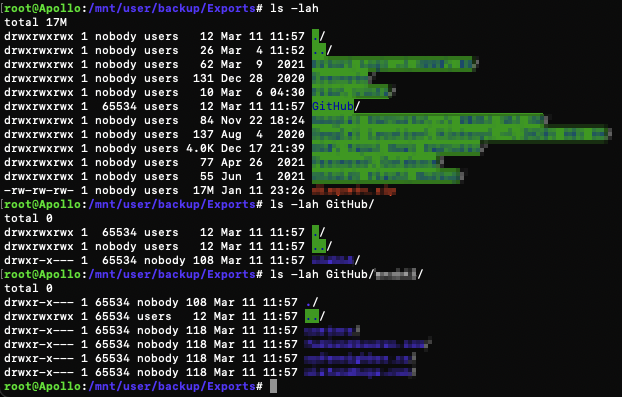
Not sure if this is changed or something weird on my end, but I just installed this and by default my GitHub folder is owned by "65534". The folders inside it are part of the group "nobody" so I think something went weird, like an overflow. I ran sudo chown -R nobody:users -R GitHub/ But after restarting the container it just went back to 65534:users I just saw this docker today in the community apps spotlight but it looks like it hasn't been updated in a year and no responses here. Is this project abandoned? Do you need someone to take it over?
-
This seemed to stop working for me. Haven't changed anything but the logs are now just: Writing shreddit.yml file... Writing praw.ini file... Traceback (most recent call last): File "/usr/local/bin/shreddit", line 33, in <module> sys.exit(load_entry_point('shreddit==6.0.7', 'console_scripts', 'shreddit')()) File "/usr/local/lib/python3.9/dist-packages/shreddit/app.py", line 44, in main shredder = Shredder(default_config, args.user) File "/usr/local/lib/python3.9/dist-packages/shreddit/shredder.py", line 28, in __init__ self._connect() File "/usr/local/lib/python3.9/dist-packages/shreddit/shredder.py", line 80, in _connect self._r = praw.Reddit(self._user, check_for_updates=False, user_agent="python:shreddit:v6.0.4") File "/usr/local/lib/python3.9/dist-packages/praw/reddit.py", line 150, in __init__ raise ClientException(required_message.format(attribute)) praw.exceptions.ClientException: Required configuration setting 'client_id' missing. This setting can be provided in a praw.ini file, as a keyword argument to the `Reddit` class constructor, or as an environment variable. Looking inside the Docker, my praw.ini file is empty. But my docker config is set up with all that information. Maybe it's not connecting somehow?
-
Having the same issue. Came here to say so and saw this, what are the odds? I tried an Xbox Core Controller over Bluetooth to my Apple TV 4K, worked in Steam Big Picture menus just not in any games. I also tried touch controller on my iPhone, same deal. Interestingly mouse controls with the touch screen did work fine. Both scenarios do work when streaming from other devices on my network which leads me to believe it’s an issue with this container specifically. Everything else is working flawlessly for me, though. I’m really excited about this project.
-
That fixed it! Thank you!
-
Awesome container, really excited to test this. I do have this issue on Safari, doesn't happen in Firefox. I can still use the VNC, it just is in the way. No big deal, I can set up in Firefox and shouldn't need to touch it again. Thank you for making this!
-
I read this a while back and a few weeks ago finally decided to give it a try. I’m the main user of my server and don’t plan on sharing Dockers to people outside of my home (except for Plex). I used reverse proxy for my own convenience. So it did make me wonder why am I opening more ports and adding more steps, more points of failure, and an increased security risk for convenience? How convenient is reverse proxy, really? After over a month of ditching reverse proxy and using exclusively WireGuard outside of network to access my server I can confidently say its been barely a thought. I would definitely recommend others consider giving it a try if your situation is similar. It’s not at all annoying the few times I need to right click > activate on an icon in my taskbar or open up the WireGuard app > toggle on. Hopefully one day I can add a pfSense router to my home network to add another level of convenience but for now I’m very happy simplifying my set up. I’ve even ditched Nextcloud and use SyncThing because of it and have been very happy. So much less maintenance between ditching the two. I remember I used to s waste entire afternoons debugging reverse proxy on a few especially difficult Dockers and never succeeding. Thanks for this post!
-
Wow! This is exciting. I've been interested in this for months. How does this compare to Calibre? And does it support sending books to Kindle over email? I wonder if this app is overkill for someone who reads maybe 1-3 books a year and doesn't follow any authors in particular. I just like the idea of sticking to the *arr ecosystem. Thanks for this! Excited to give it a try regardless.
-
My whole backup solution is a bit messy right now. Currently I use Rclone, Google Drive, and BackBlaze B2. The way it works is that I have about 70GB of important data (documents, music/video projects, graphics, etc) in a Google Drive folder on my Mac. If there's anything I'm done with, like if I finish a video project, that gets manually transferred to "cold storage" on Unraid and eventually up to B2 through Rclone (User scripts plugin, once a day). But for security, I keep an offline version of Google Drive on my server and also back that up to B2. So basically when it comes to my daily-use files: desktop Google Drive folder -> Google Drive cloud -> Unraid Google Drive share -> BackBlaze B2. And of course I also have more cold storage shares on Unraid that also go to BackBlaze B2. What I'm thinking is skipping the Google Drive middle-man and just using Rclone from my Mac to Unraid shares. Maybe even making like a "warm storage" intake share on Unraid so I can still manually move stuff to the cold storage shares. But how well would Rclone work for this? I know it's CLI only which is fine, I'm comfortable with that, but I'm worried it won't be as robust. As in, I won't really know about errors or issues. I'm also worried about how it handles constant file changes, like if I'm working on a music project in a folder that Rclone touches and files get frequently created/deleted. Also, what would happen if an Rclone Mac -> Unraid sync happens at the same time as the Unraid -> B2 sync? Do they communicate with each other somehow? Is this worth looking into? Any tips would be appreciated. I'm trying to de-google and simplify a bit in general. How do you all manage your daily storage and cold storage backup?
-
Hey is there any way to run this with the OBS virtual webcam? I'm not seeing "start virtual camera". I'm trying to use it as a way to stream video files from my server through "VLC Video Source" and into Discord. It sounds like no matter what I'll need to run Discord + OBS on a VM and tunnel the stream to it. But I assume that would be better performing considering with an OBS docker I can pass through my GPU (which is shared with Plex) and solely use the VM to upload the stream.
-
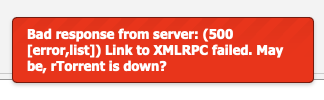
Hello, lately I've been having an issue where some of my torrents from public trackers get stuck at 99.9% done. This then doesn't trigger the stop ratio rule so I end up just endlessly uploading and wasting bandwidth. I try to be a good seeder but not that good lol. The only manual solution I've found is if I right click on the torrent and do "force re-check", rTorrent will throw this error: And then it will crash: But once it's backed up, it's instantly fixed: Does anyone know what's going on here? It seems like it's actually done on rTorrent's end and it's just not reporting to ruTorrent? And therefore not reporting to Sonarr to import.



-
I set my media share to not touch the cache. But yesterday I thought, I don't remember why, let me set it to use cache. Today I realized why. Mover doesn't seem to like the hard linked files in the cache and now they're stuck. Mover won't touch those files no matter how many times I invoke it. So, I figured I could manually move the files in /mnt/. I know the hard links will break, but I'll just re-import with Sonarr/Radarr, no big deal. My question is, what's the right terminal command? I wanna make sure I don't mess anything up. Would I use: mv /mnt/cache/media /mnt/disk4/media ? Thanks for the help!
-
Yes I did finally! Thanks to this: Looks like you don't need the /mnt/user/ part of the path. Ended up adding some exclusions and my full excluded folders path is this: binhex-plex/Plex Media Server/Crash Reports/,binhex-plex/Plex Media Server/Logs/,binhex-plex/Plex Media Server/Media/,binhex-plex/Plex Media Server/Cache/,.DS_Store,*.log,*.log.*,*.tmp,.Recycle.Bin Adding that made my appdata backup go from 4 hours to 15 minutes, and 149 GB (compressed) to 11.1 GB (compressed).
-
What's the format for excluding folders with spaces in the path? And multiple paths? I'm trying to exclude: /mnt/user/appdata/binhex-plex/Plex Media Server/Cache /mnt/user/appdata/binhex-plex/Plex Media Server/Media Currently I have this: "/mnt/user/appdata/binhex-plex/Plex Media Server/Cache","/mnt/user/appdata/binhex-plex/Plex Media Server/Media" Is that the correct format? Also it doesn't look like you can use spaces in the field. I can only copy and paste space.
-
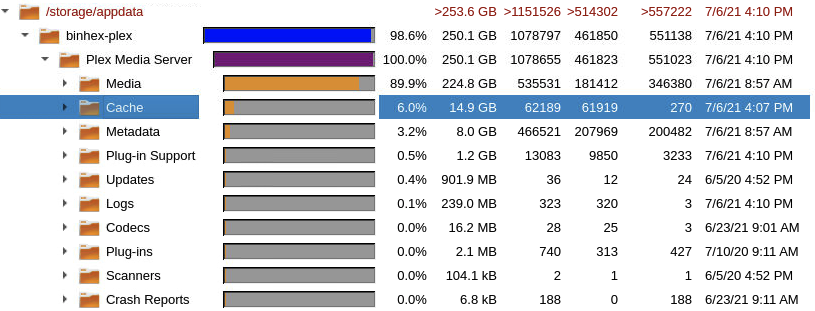
I was wondering why my appdata backups were so huge. I looked at my appdata on QDirStat and noticed these two folders were taking up 99% of the space: Is it safe to exclude /Media and /Cache from CA Backup and Restore? From what I understand Cache is just, well, cache. And /Media stores thumbnails which I do actually really like and prefer to keep on. My only concern about what I don't want to lose in a failure and restore situation is: collections, play history, user history, playlists, and custom posters/backgrounds that I've made and uploaded for various items.
-
Only one of my remote users is having issues the past week or two where on different TVs (Roku TV), iOS, and a Macbook some episodes won't play or will get stuck at the 33% mark. They tried it on two networks in different houses. We also tried on a new Plex account and same issues. It's really a long shot because this is so oddly specific and I'm not even sure what kind of debugging I can do, but does anyone have any ideas if this sounds remotely familiar to other common issues? Once again none of my other users using varying devices, some of them using the same platforms, are having issues. My port is open, internet is working, I've tried playing the same episodes and they worked fine. On my end it shows that the episode is playing but on his end it's not.
-
I ended up making this folder: appdata\binhex-rtorrentvpn\rutorrent\user-plugins\tracklabels\labels which didn't exist before. And did what I outlined before and after restarting ruTorrent it works! I made a backup in case a docker update breaks it, as you mentioned. If so then I can copy that script. Thanks for the help!
-
This isn't an important issue but I was curious if there was a way to upload icons for more specific labels? I just prefer using, for example, the word "movies" which doesn't trigger an icon over "movie" (which does). I also have other words I'd like icons on. In other seedbox installs of ruTorrent I managed to find the folder that contained these icon files and it was as simple as copy/pasting the movie.png file and renaming it to movies.png. I couldn't find that folder in this docker, though. Best I could find is this folder that does contain all those icons: https://github.com/Novik/ruTorrent/tree/master/plugins/tracklabels/labels. So at least I have the files I could download and rename but I'm just not sure where to put them. Anyone know? Thanks!
-
Thank you so much for the response! Yeah I know I've read before that around 2000 torrents is where it can slow down which is why I was so confused. I know my system isn't that powerful, my CPU (Xeon E3-1230 v3) passmark's at 6806 and ruTorrent only gets half the cores and shares those cores. Although I've never seen my CPU max load due to anything going on with ruTorrent. It does go up if it's checking torrents but nothing concerning. Yeah I'm an Unraid user, my shares are on xfs and my cache is btrfs. I actually have always had my media share, where my torrent downloads go, set to "No" for using the cache since I did the math and figured out that SSD is pointless if I'm writing at my internet/VPN's half gigabit speed. So torrents should be downloading to xfs file system. As far as performance I noticed changing my UI update to 3000ms (vs 1000ms) helped a tiny bit for preventing timeouts. And I disabled some plugins that I was clearly not using, although that didn't seem to help honestly. Yeah definitely leaning more towards that my hardware is just not up to what I was asking it to do. I know binhex just said btrfs can be an issue in the cache pool, but I'm considering switching back to cache "prefer" so new downloads will be on the SSD vs HDD. Maybe that could help because I think my performance issues are usually when new stuff downloads. If nothing is downloading it can be a bit more stable. Couldn't hurt to try. I'll have to do more research on btrfs vs xfs for cache but I'm not sure if that's too off topic for this support thread. Thanks again!
-
So I got my client down to about 800 torrents and it seemed to improve. However, I added 3 torrents that were 100GB and another that was 50GB. I've had some pretty big torrents before but I'm not sure ever this big, plus trying to download it all at once. Extremely slow UI and it kept crashing and because of that kept trying to re-check everything and crashing again. I even had my Unraid shares crash to where I had to reboot my server to see them again, even once had to fix a drive's file system. Not sure if it's related, I'm on Unraid 6.9.0-RC2. Anyway, when the UI would load it just wouldn't download/upload anything. I had zero peers across the board. After the stability being on-and-off it ended up getting stuck in a loop of rTorrent just crashing at start. It wouldn't start at all and just stopped working 99% of the time. I checked the rtorrent session folder and there was almost 2000 files created in the past day. I think it was stuck in a loop trying to fix itself or something. After loads of debugging all week I ended up just going with a fresh install and configuration of the docker and so far it seems to be stable and working just fine. It's a pain to have to re-add all my torrents, still working on that, and that I lost all my stats. I'm just dying for this docker to feel stable again. I feel like I've spent 1000 hours debugging it the past few months. So my question is once again...does it sound like I just hit some sort of performance bottleneck? Can the docker just not handle large size or large amounts of torrents? I just want to know if this sounds even remotely like a simple performance issue so I can conclude my endless debugging as: keep the torrent list low, don't flood the docker with big downloads all at once, and download beefier torrents on another desktop PC. It seems similar to the issue this user had, at one point I had the same exact error (which is how I found this post): Any advice is appreciated. Thank you!!
-
Is the docker just having issues lately or is it because I've grown to about 1000 torrents in the past few months? I have it pinned to 2 cores, 4 threads, on an E3-1230 v3 (3.3GHz processor). I know that's a really general question, but I just have no clue if my server is the bottleneck or the container is just having performance issues. I'm finding it times out often, crashes often, very slow UI updates, and can't seem to handle more than 5-7 active downloads now without crashing. If it helps, I'm using AirVPN which doesn't seem to have any reports of issues as far as I've seen.
-
I got this set up through SWAG for a reverse proxy. All my other containers I run through them work fine and are secure (https). But this one wasn't. Firefox alerted me it wasn't secure. Is there any way to make it secure? I used the CONF sample file from SWAG and tried tweaking the configuration a few ways.








