




Hawkins12
Members
-
Joined
-
Last visited
-
This is the 2nd I've run into an issue with my Unraid server in the last month or two. My server is seemingly on and working. I can connect to the various dockers that are running and there are no known issues with those. The problem is when I go to my browser and try to get the server login page I keep getting the "Unable to Connect" message. In addition, when I try to SSH into the server, I get "connection refused". Also, my shares that I can access via my Windows PC on the same network don't connect either. Is there a way to troubleshoot this without doing a hard restart of the server? Any issues I should check on with this? Obviously I can't provide diagnostics because it'll be immediately after a restart and likely won't show much but it's odd. I went out of town for a day, server worked fine when I left, and when I returned home, I can't log on. EDIT: I can ping the server from my desktop PC and there appears to be no issues there.
-
I have been having a lot of issues with "Waiting for connection". I tried to clear the cache and that didn't seem to help at all. The other day, I added a new folder to a "Backup Set", it read all the files, did about 10% of them and then kept going to "Waiting for connection". I was able to ping 8.8.8.8 from the container so I know it has internet access. No obvious errors in the logs. I did reinstall the docker and that didnt work either. Any suggestions?
-
Thank you. The uninstall and reinstall worked. I was afraid to lose my previous settings on the uninstall which made me hesitant but all seemed to roll over correctly.
-
Have you seen this with the app? For some reason, the status is showing as "Not Available" for several weeks and no updates are actually being pushed through. I can see the plugin has updates via the "Action Center" in Apps section; however, if I click update, nothing actually gets updated or pushed through. If I uninstall the plugin and reinstall it, is there a way to get my existing DB back? I don't want to have to go in and re-identify my drives/array/settings if it can be avoided as this could be cumbersome but I do want to keep the plugin up to date.

-
Suggestion to docker: In the recent update, there was a change that "broke" the template. See comments below as I figured out how to fix the issue: In the template, the container path was still listed as "Container Path: /App/wwwroot/documents" and "Container Path: /App/wwwroot/images" I updated the container path to be "data" instead of "wwwroot" as noted above and the installation worked. This is consistent to the update notes provided by the Dev (https://github.com/hargata/lubelog/discussions/787): In 1.4.3, user uploaded files (documents, images, translations, etc) will be moved out from the wwwroot folder, also known as the WebRootPath onto the data folder. The files will be automatically copied over like so: wwwroot/images -> data/images wwwroot/documents -> data/documents wwwroot/translations -> data/translations
-
I might have more information. I checked logs when trying to pull a certificate and got this: "Timeout during connect (likely firewall problem)" My NGINX is setup exactly the same as SWAG (and I know i did port forwarding for SWAG). Here is my NGINX PM: and note I also have this on the "Custom: Proxynet" network type as my SWAG is on that too. Here is my SWAG:


-
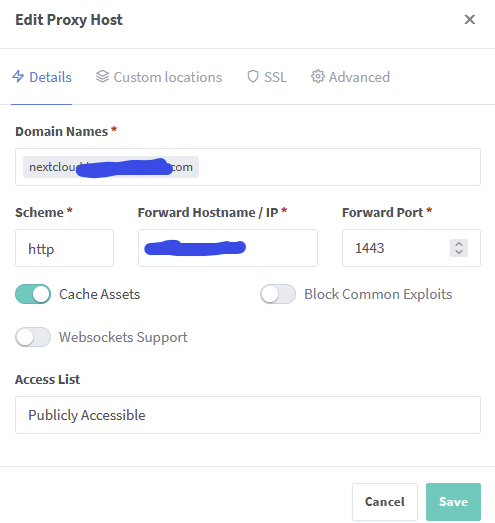
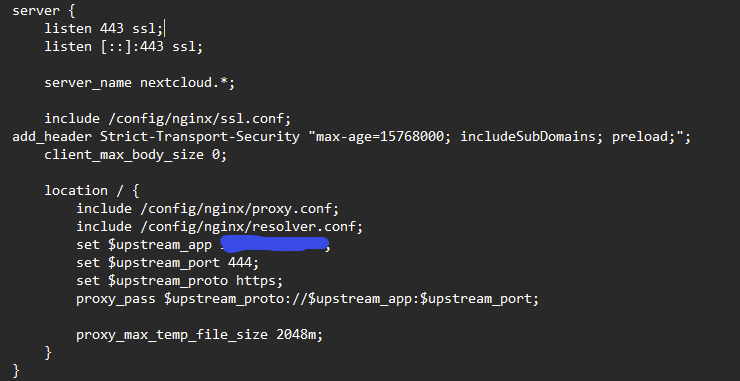
I'll clear and restart. My only other guess is I am not setting up the Proxy Host right. NNote I have tried EVERY combination in port (ie. I've tried http/https for 443, 444, 1443, etc). Here is how I have it set up. What do you think I should be using? And my SWAG config file looks like this:
-
So the dropdown shows: Note that what I highlighted out was my attemp to manually add my Certs from Cloudflare to NPM. It does not related to my nextcloud proxy. In my SSL Certs, I only have this manually added Cert from Cloudflare. Note I only added this cert because of the issues I was having trying to get nextcloud to work here. It didn't work prior to this (or after the fact).
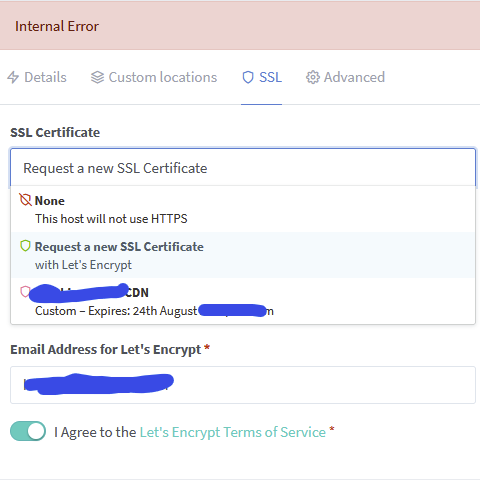
-
So when I try to obtain new SSL, I get this. Not that I do have HSTS enabled via cloudflare. However, when I uncheck the box, it seems to work but I get this: It seems to not want to issue a new cert because one is already issued. I actually tried to revoke (and delete) my cert in SWAG but that didnt seem to work either
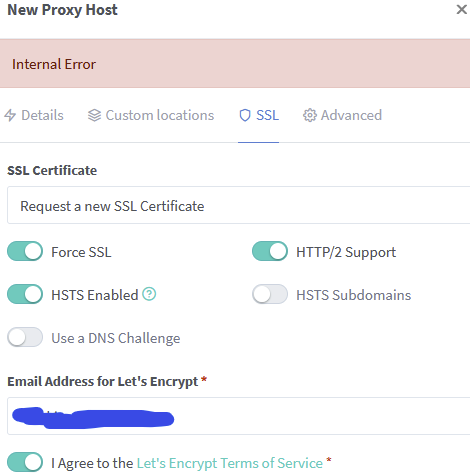
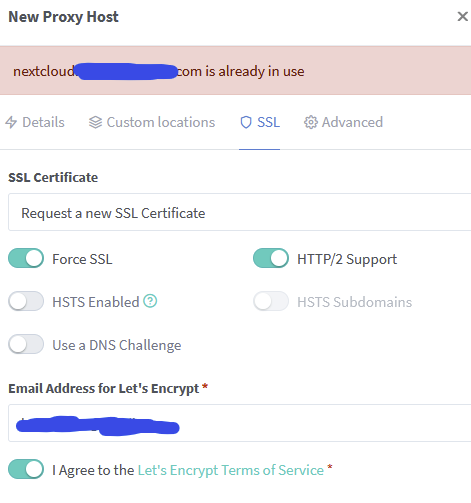
-
I have been using SWAG for some time but would like to transition to NGINX PM for various reasons (really ease of use). When I installed and went to set up the proxy, I got the error that the domain was already in use. I tried revoking my certificates via SWAG/Cert Bot however, I still wasn't to fix the issue. Do you have or are you aware of the steps on how to migrate (certificates) from SWAG to NGINX PM? Particularly, I am using SWAG for Nextcloud.
-
SO I have been using SWAG for some time but would like to transition to NGINX PM for various reasons (really ease of use). When I installed and went to set up the proxy, I got the error that the domain was already in use. I tried revoking my certificates via SWAG/Cert Bot however, I still wasn't to fix the issue. Do you have or are you aware of the stops on how to migrate from SWAG to NGINX PM? Particularly, I am using SWAG for Nextcloud.
-
Hoping someone can help me out. I've installed the OnlyOfficeDocumentServer file and it successfully runs. Once it's running; however, I am unable to actually see the GUI (and unable to link to Nextcloud). I followed SpaceInvaders setup vid basically to a "T" (changing out letsencrypt to swag) and confirmed the settings all appear right. What could be my issue. For reference, here's the logs for OODS: * Starting PostgreSQL 14 database server ...done. * Starting RabbitMQ Messaging Server rabbitmq-server ...done. Starting supervisor: supervisord. * Starting periodic command scheduler cron ...done. * Starting nginx nginx ...done. Generating AllFonts.js, please wait...Done Generating presentation themes, please wait...Done Generating js caches, please wait...Done ds:docservice: stopped ds:docservice: started ds:converter: stopped ds:converter: started * Reloading nginx configuration nginx ...done. ==> /var/log/onlyoffice/documentserver/converter/err.log <== ==> /var/log/onlyoffice/documentserver/converter/out.log <== [2024-08-23T21:50:39.352] [WARN] [localhost] [docId] [userId] nodeJS - num of CPUs: 20; availableParallelism: undefined [2024-08-23T21:50:39.353] [WARN] [localhost] [docId] [userId] nodeJS - update cluster with 1 workers [2024-08-23T21:50:39.359] [WARN] [localhost] [docId] [userId] nodeJS - worker 865 started. [2024-08-23T21:50:39.360] [WARN] [localhost] [docId] [userId] nodeJS - num of CPUs: 20; availableParallelism: undefined [2024-08-23T21:50:39.360] [WARN] [localhost] [docId] [userId] nodeJS - update cluster with 1 workers [2024-08-23T21:51:00.991] [WARN] [localhost] [docId] [userId] nodeJS - num of CPUs: 20; availableParallelism: undefined [2024-08-23T21:51:00.992] [WARN] [localhost] [docId] [userId] nodeJS - update cluster with 1 workers [2024-08-23T21:51:00.997] [WARN] [localhost] [docId] [userId] nodeJS - worker 1169 started. [2024-08-23T21:51:00.999] [WARN] [localhost] [docId] [userId] nodeJS - num of CPUs: 20; availableParallelism: undefined [2024-08-23T21:51:00.999] [WARN] [localhost] [docId] [userId] nodeJS - update cluster with 1 workers ==> /var/log/onlyoffice/documentserver/docservice/err.log <== ==> /var/log/onlyoffice/documentserver/docservice/out.log <== [2024-08-23T21:49:53.788] [WARN] [localhost] [docId] [userId] nodeJS - Express server listening on port 8000 in production-linux mode. Version: 8.1.1. Build: 26 [2024-08-23T21:50:21.979] [WARN] [localhost] [docId] [userId] nodeJS - start shutdown:true [2024-08-23T21:50:21.979] [WARN] [localhost] [docId] [userId] nodeJS - active connections: 0 [2024-08-23T21:50:21.980] [WARN] [localhost] [docId] [userId] nodeJS - end shutdown [2024-08-23T21:50:39.607] [WARN] [localhost] [docId] [userId] nodeJS - Express server starting... [2024-08-23T21:50:39.608] [WARN] [localhost] [docId] [userId] nodeJS - Failed to subscribe to plugin folder updates. When changing the list of plugins, you must restart the server. https://nodejs.org/docs/latest/api/fs.html#fs_availability [2024-08-23T21:50:39.777] [WARN] [localhost] [docId] [userId] nodeJS - Express server listening on port 8000 in production-linux mode. Version: 8.1.1. Build: 26 [2024-08-23T21:50:59.535] [WARN] [localhost] [docId] [userId] nodeJS - Express server starting... [2024-08-23T21:50:59.536] [WARN] [localhost] [docId] [userId] nodeJS - Failed to subscribe to plugin folder updates. When changing the list of plugins, you must restart the server. https://nodejs.org/docs/latest/api/fs.html#fs_availability [2024-08-23T21:50:59.651] [WARN] [localhost] [docId] [userId] nodeJS - Express server listening on port 8000 in production-linux mode. Version: 8.1.1. Build: 26 ==> /var/log/onlyoffice/documentserver/nginx.error.log <== ^A
-
Thanks for this. I was thinking a list of all the Dockers would pop up and I would select the ones that I want to be part of the group. What you provided obviously works and makes sense. Thanks for the response!
-
I am a bit confused on the settings surrounding "member of group". It shows up for me as this: However, it doesn't matter how many times I click, no "list" of groups pops up for me to select. My backup type is set correctly "Stop, backup, start each container" Do I have to type each docker in? Is that a valid workaround? It'd be nice to have a list pop up that allows me to group but not sure if my app is bugged. Thanks.

-
No change that I am aware of. I have all dockers up to date and plex still announces (checked as of today).











