




SimpleDino
Members
-
Joined
-
Last visited
-
I do not know how you guys pull/download a model from Hugginface, but I've "created (using AI as a tool) so I absolutely take no credit for this in any way)" a script on how to download a specific model/.safetensor to your desired directory/location: #!/bin/bash # Define variables # Your HF and model info HF_API_TOKEN="YOUR HF API" MODEL_URL="https://huggingface.co/stabilityai/stable-diffusion-3-medium/resolve/main/sd3_medium_incl_clips_t5xxlfp8.safetensors" # Your descired location OUTPUT_DIR="/mnt/user/stable-diffusion/models/stable-diffusion" OUTPUT_FILE="$OUTPUT_DIR/sd3_medium_incl_clips_t5xxlfp8.safetensors" # Create the output directory if it doesn't exist mkdir -p $OUTPUT_DIR # Download the model curl -L -o $OUTPUT_FILE -H "Authorization: Bearer $HF_API_TOKEN" $MODEL_URL echo "Model downloaded to $OUTPUT_FILE"
-
@jbartlett, have your VM's been effected or anything by unraid version 6.12.4? My ones have stopped outputting display picture to monitor but are accessible with RDP, anydesk etc...but not with sunshine/moonlight because of encoder/decoder (RTX3060) is not working properly.
-
I have the same issue since the upgrade, all of my VM's with GPU passthrough don't work anymore. I can access them through RDP, anydesk etc. but not with sunshine/moonlight without proper encode/decode function. I can see the GPU's in all device managers and ...(kinda working?!) but none outputs any display to monitors. Have any of you found any solution to this? Br,
-
SOLVED https://github.com/ausbitbank/stable-diffusion-discord-bot/issues/41 Volume mapping in docker-compose.yaml did it: volumes: - /mnt/user/appdata/stable-diffusion/outputs/03-InvokeAI:/app/output - ./db:/app/db and setting basepath in .env: basePath="/app/output/"
-
Thanks for the quick response. I'm curious about whether the pcie_aspm=off command will affect all PCIe slots on a global level. Specifically, I'm wondering if it will have an impact on the 4xM.2 PCIe adapter. Given the circumstances, pci=noaer might be the preferable solution for the time being. The peculiar thing is, I hadn't experienced any issues until recently. The problem likely originates from PCIe slot 3, which houses the RTX 3060. As mentioned in my post, Unraid and the VM only freeze when the GPU is passed through to the Windows VM. The GPU in PCIe slot 3 operates fine outside of the VM when used for stable diffusion or other tasks. However, the AER error persists, and this error first appeared after the initial system freeze.
-
@Squid @ghost82 Do you guys have any clues?syslog.txt
-
Yesterday, I remotely accessed one of my VMs with Nvidia GPU passthrough, and suddenly the whole VM froze and disconnected. Subsequently, the entire UNRAID server became unresponsive, and unfortunately, the only solution was a hard reset. This has occurred twice, and I'm now concerned that if I tempt fate and start the VM a third time, it could cause irreparable damage to the server, potentially leading to data loss. memtest is OK! Below is a snippet of what the logs show. Note that the Docker log is also 100% full: May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: device [10b5:8714] error status/mask=00000080/0000a000 May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: [ 7] BadDLLP May 12 14:54:03 Tower kernel: pcieport 0000:40:01.3: AER: Multiple Corrected error received: 0000:46:02.0 May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: PCIe Bus Error: severity=Corrected, type=Data Link Layer, (Receiver ID) May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: device [10b5:8714] error status/mask=00000080/0000a000 May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: [ 7] BadDLLP May 12 14:54:03 Tower kernel: pcieport 0000:40:01.3: AER: Corrected error received: 0000:46:02.0 May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: PCIe Bus Error: severity=Corrected, type=Data Link Layer, (Receiver ID) May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: device [10b5:8714] error status/mask=00000080/0000a000 May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: [ 7] BadDLLP May 12 14:54:03 Tower kernel: pcieport 0000:40:01.3: AER: Multiple Corrected error received: 0000:46:02.0 May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: PCIe Bus Error: severity=Corrected, type=Data Link Layer, (Receiver ID) May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: device [10b5:8714] error status/mask=00000080/0000a000 May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: [ 7] BadDLLP May 12 14:54:03 Tower kernel: pcieport 0000:40:01.3: AER: Corrected error received: 0000:46:02.0 May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: PCIe Bus Error: severity=Corrected, type=Data Link Layer, (Receiver ID) May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: device [10b5:8714] error status/mask=00000080/0000a000 May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: [ 7] BadDLLP May 12 14:54:03 Tower kernel: pcieport 0000:40:01.3: AER: Corrected error received: 0000:46:02.0 May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: PCIe Bus Error: severity=Corrected, type=Data Link Layer, (Receiver ID) May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: device [10b5:8714] error status/mask=00000080/0000a000 May 12 14:54:03 Tower kernel: pcieport 0000:46:02.0: [ 7] BadDLLP The log entries show recurring PCIe interface issues. "BadDLLP" is possibly because of corrupted data?? The device [10b5:8714] see IOMMU GROUP below is probably the because it's connected to the PCIe port. The repeating "severity=Corrected" error suggests an underlying issue that, while currently correctable, persists. The 'AER: Multiple Corrected error received' messages from the PCIe port indicate multiple corrected errors from the device at 0000:46:02.0 PCIe ACS override is set to = both Attached, you will find the diagnostics.zip folder. OS: unRAID 6.12.0-rc5 Hardware: Threadripper 1950x ASUS Zenith Extreme PCIE 1: PNY NVIDIA Quadro P2000 5GB PCIE 2: M.2 X16 Adapter GEN 3 PCIE 3: Nvidia RTX 3060 12GB PCIE 4: HBA Card LSI SAS 9207-8i tower-diagnostics-20230512-2120.zip
-
Hello Unraid community, I've been working on integrating the Stable Diffusion Discord Bot (ausbitbank/stable-diffusion-discord-bot) with the superboki or Sygils container on Unraid, and I've encountered some issues along the way. Despite several attempts to resolve these errors/issues, I've been unsuccessful so far. I've also posted about the issue on the bot's GitHub repo (ausbitbank/stable-diffusion-discord-bot/issues/41). The problem I'm experiencing is that while the Discord bot successfully generates an image upon receiving a prompt, the image doesn't appear in the Discord channel. I can find the generated image in the Invoke Docker container output folder, but the path logic seems to be causing issues. I receive the following error from the Discord bot container: logs: I've made adjustments to the .env file and docker-compose.yaml file, as shown below: .env file: docker-compose.yaml: Dockerfile: I would greatly appreciate it if someone could help me create a working Docker container for the Stable Diffusion Discord Bot that can be integrated with the superboki or Sygils container on the Unraid CA App Store. Any assistance or guidance would be immensely helpful. Thank you in advance!
-
Should be one! I have an issue where InvokeAI (option: 03) works but when using A1111 (02) it crashed when pressing generate and Easy Diffusion (1) the webui doesn't even start. No clue why because it doesn't give any error logs either...really weird!! Anyone experiencing something like this?
-
[SOLVED] Thanks for all the input, unfortunately it did not help! Figured out the issue... Apparently if you populate the last PCIe GPU slot on the X570 Taichi Motherboard then the first one becomes inactive somehow. Second one is also populated, used in VM's etc. I populated the last gpu slot as mentioned with a PCIE M.2 Adapter with four 970 Plus 1TB nvme's but I did not use or activate in Unraid until the other day and that is when nvidia-plugin gave out a warning and first gpu slot (P2000) got inactive but recognized in devices. I've removed the M.2 PCIE card until I get hold of an Threadripper system.
-
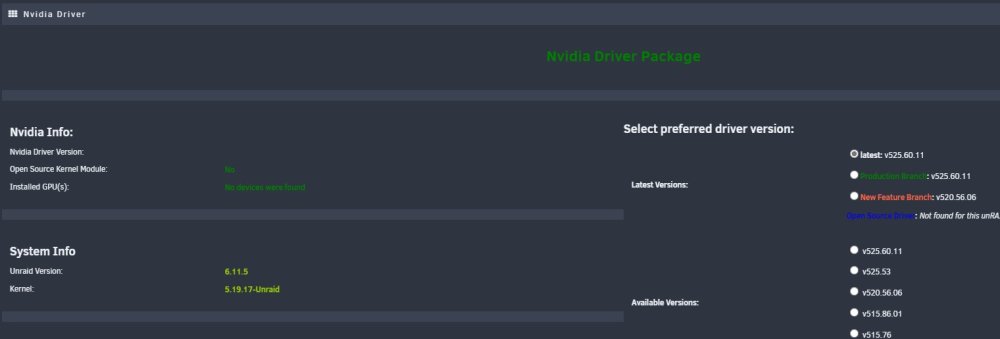
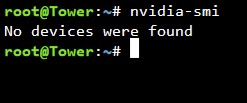
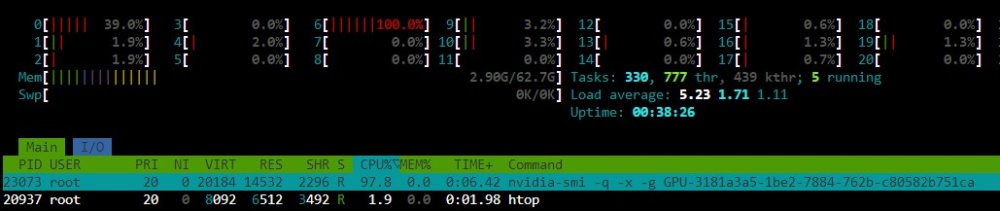
Hi, Today I got a notification saying nvidia-plugin had crashed (don't remember the detail...and yes I am ashamed) and when I tried to go to the Nvidia-plugin under settings the whole screen/UnRaid froze! After rebooting I deleted the plugin and re-installed to the letter according to your instructions etc. No more freezing issues and the plugin is OK, but now I can not find the Nvidia P2000 gpu card under the info section in the plugin (see picture). Has anyone encountered this issue? Or have I just missed a step during uninstall & install part... Any idea?! The card is no connected to any VMs or bound to VFIO. Also at htop am getting high cpu usage for this: nvidia-smi -q -x -g GPU-3181...........this is the gpu ID I guess. Could this be the p-state script for power consumptions or me trying nvidia-smi command in console and it's not finding anything? Steps taken: 1. Uninstall plugin 2. Reboot 3. Install according to instructions 4. Reboot 5. Downgrade to previous driver...no luck 5.1 Reboot 6.0 Upgrade to current version 6.1 Reboot. tower-diagnostics-20221208-1504.zip
-
Solved! My bad, I've pointed the source file to opencore image instead of MacOS disk image in the same folder! Great when you discover your own mistakes...but you learn from them I guess!
-
<devices> <emulator>/usr/local/sbin/qemu</emulator> <disk type='file' device='disk'> <driver name='qemu' type='qcow2' cache='writeback'/> <source file='/mnt/user/domains/Ventura/Monterey GPU/Monterey GPU/BigSur-opencore.img'/> <target dev='hdc' bus='sata'/> <boot order='1'/> <address type='drive' controller='0' bus='0' target='0' unit='2'/> </disk> Here is the format of vdisk
-
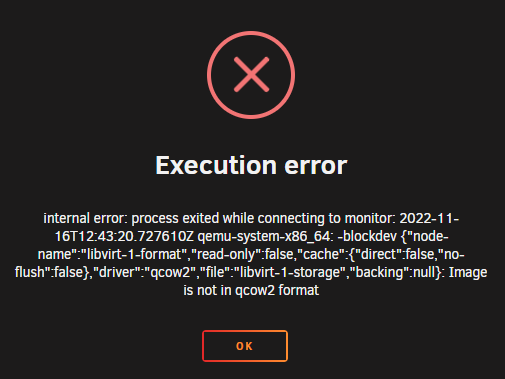
Hi! Just want to say that I've done this many times and created several VMS of the original VMs (copy or cloned) without issues before. Steps done to Clone/copy VM: 1. Copy Full folder containing VM from domains 2. Paste in a new folder with new name in domains. 3. Start new Custom VM, copy and paste the XML from original VM 3.1 Give it a new name, delete uuid (new will be generated) 3.2 Delete previous source file and point to the new one (the new folder with copied VM in it) 4. Edit helper script and replace the name of vm with the new and run the script. 5. Voila! as I said, this method has worked until now. But now after updating to the latest UnRaid OS, I am getting this error when trying create & fire up a NEW VM. Any clues how to fix the image file or some other related issue? Br,
-
Hardware recommendations for unRAID servers with VM's https://r.tapatalk.com/shareLink/topic?share_fid=18593&share_tid=54248&url=/index.php?/topic/54248-Hardware-recommendations-for-unRAID-servers-with-VM%27s&share_type=t&link_source=app Skickat från min iPhone med Tapatalk





