




SavellM
Members
-
Joined
-
Last visited
Everything posted by SavellM
-
At least your drive can still give you the power of AI to help you with your poems 😂
-
Makes sense, thanks Jorge for helping me out
-
Yeah I've left it as a Bond as per the image above. If I disable that I lose everything. Is it worth uncommenting out that blacklist and just leaving it default until we get some sort of solution?
-
namek-diagnostics-20250103-1212.zip Thanks
-
@JorgeB I did the command: echo "blacklist cdc_ether" > /boot/config/modprobe.d/cdc_ether.conf Restarted and I still see ETH0. I did see during boot up: And I still cannot disable or remove this ETH0, so I have to leave it there otherwise I get no network. If I click the bonding and change type or anything else I just get nothing.

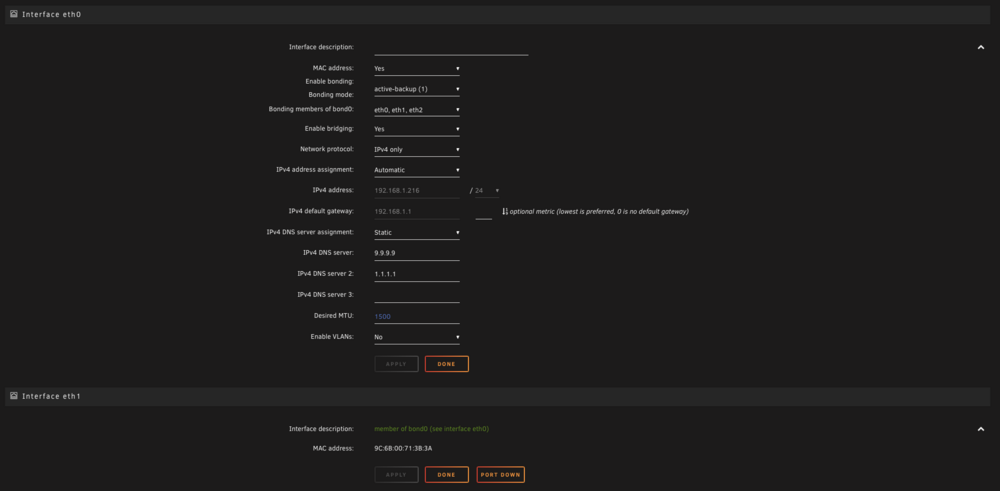
-
Yes I did see that, let me try it again with a fresh install of unRAID. I did find that IP would work but only after about 5mins of being booted... Its like it tries ETH0 and then goes yup its defo down, and then does the br0 failover to ETH1. And sorry for the multiple posts.
-
Current setup:
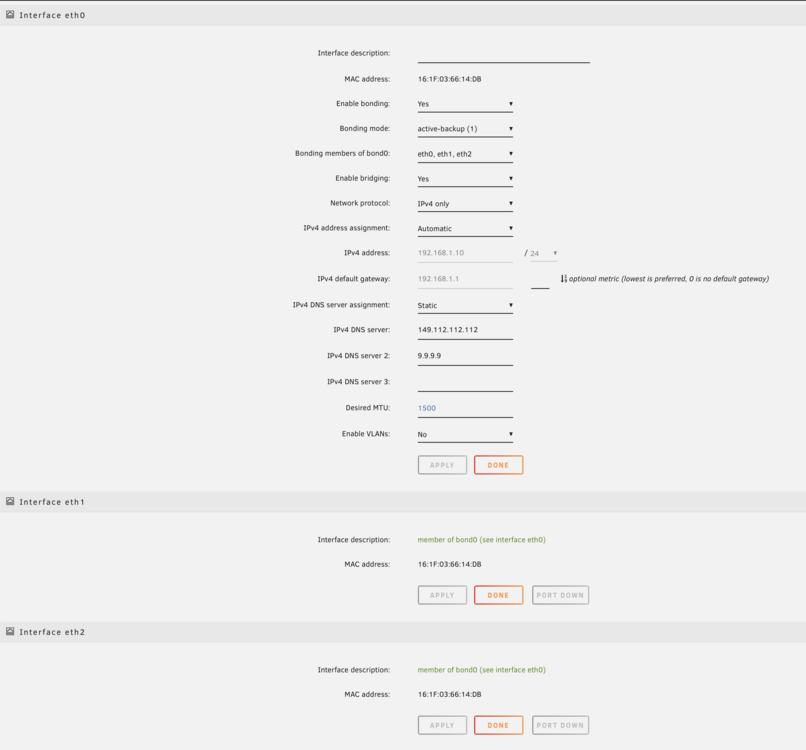
-
So ETH0 is somehow connected to my BMC (ASRock ROMED8-2T) I think I figured out it's some sort of USB NIC that gets pushed through. This causes delays when booting, and changing any network related options, I would like to just disable this random ETH0 and use ETH1/2 as my main networks. But for whatever reason as soon as I mess with it, I lose all connection. I would love some assistance here if anyone knows? lsusb Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 004 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 005 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 005 Device 002: ID 05e3:0608 Genesys Logic, Inc. Hub Bus 005 Device 012: ID 046b:ff01 American Megatrends, Inc. Virtual Hub Bus 005 Device 013: ID 046b:ffb0 American Megatrends, Inc. Virtual Ethernet Bus 005 Device 014: ID 046b:ff10 American Megatrends, Inc. Virtual Keyboard and Mouse That virtual ethernet I believe is what is causing my pain. namek-diagnostics-20250102-0958.zip
-
Sorry I thought it was a bit of a mess and no other responses. Sorry I didnt see any message from you there. I did manage to get a IP via GUI but when booting headless no IP. No idea why... namek-diagnostics-20241221-1744.zip
-
Hi all. I picked up a ROMED8-2T and am battling to get an IP. For some reason there is an ETH0 which is a different MAC to the ETH1/2 (Intel 10gbe NICs) and my server keeps picking it up as the main internet and gives it a self assigned IP. I have disabled Network Stack in bios which didn’t help. I am at my wits end as I can’t get my server to work correctly even if I bring up ETH1 and it gets an IP like it should the server won’t communicate to the outside world as it’s trying to use ETH0. Please could anyone help me figure out where this random ETH0 is coming from? I have the mother board, 4070ti, Quadro 8000, and a LSI SAS controller plugged in. Nothing else. I also don’t believe it’s the IPMI as it’s a different MAC
-
Well I do actually need some help. For something is taking ETH0 (I think IPMI) so I still cannot get my unRAID server to reach out to the outside world. I can finally access it from the ETH1 IP address as it should be. But ETH0 is always taking up primary duty and it's a self assigned IP. I have unplugged my IPMI so ONLY have 1 Ethernet cable into ETH1 (10gbe NIC) and still cannot get it to be ETH0 within unRAID. I wiped my USB and did a fresh install, and same dice. I'm struggling here, please save a n00b. ETH0 is a MAC address I dont recognise, it is not the IPMI MAC.
-
Ok I figured it out. For whatever reason its showing as 3x ETH devices. Previously I switched off ETH1 So now for some reason this is showing up at ETH 1 and no idea what ETH 0 is. Enabled this and finally got an IP... Anyone know what ETH 0 would be
-
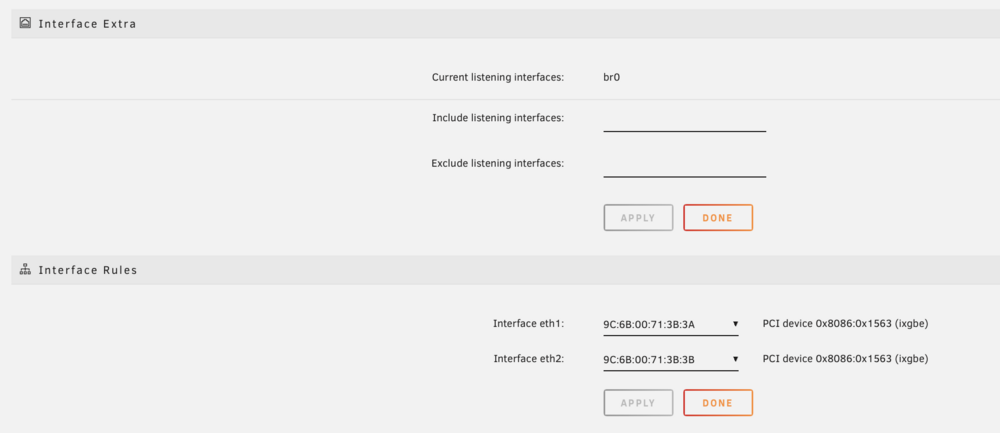
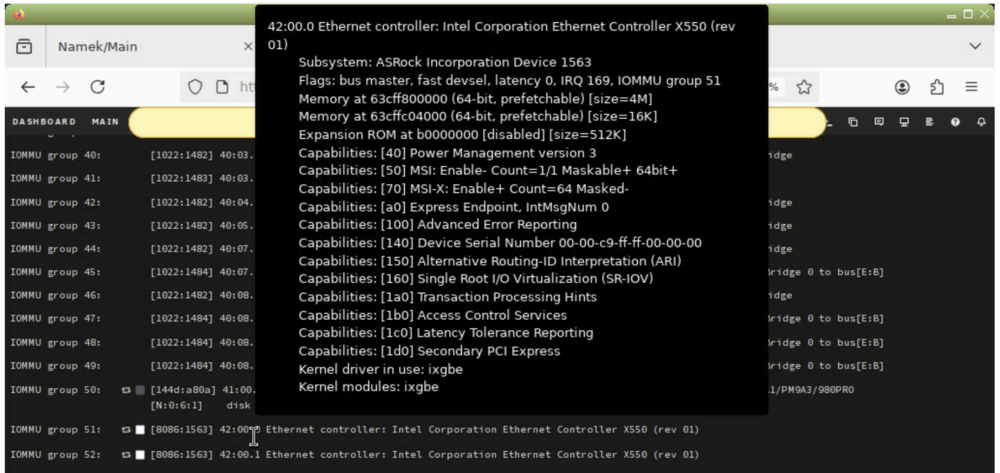
I managed to get into GUI via IPMI. I see Is there something I need to do? It seems like it's there? Do I need to enable SR-IOV?
-
Hi all, I'm in desperate need of help. I broke my old Intel based motherboard, so upgraded to a AsRock ROMED8-2T with AMD I have it booting just fine, BMC is fine and I can see the NIC is showing up in Unifi. But when unRAID boots (from my old USB) on RC 7.0.0 RC1 I get a self assigned IP address and I cannot access my server. I know this NIC does 1gb or 10gb and I have tested both but neither gets an IP. I have changed SPF+ adapters and also network cables but I just cannot get an IP. I saw in the BMC there was Network Bonding so I disabled that and still no dice. Is there something in BIOS I need to set to get the NIC to work and unRAID to see them?
-
Ok thanks JorgeB
-
Is there a guide on how to switch my cache and another SSD pool from BTRFS to ZFS? I am running 7.0.0 RC1 if this is of help. Also once I switch is there any maintenance stuff that I should be looking at, like scrubs and snapshots and whatnot once I switch over?
-
Ironically thats even worse Its showing its bouncing between 999 and 1000 and no higher Then I remembered I had set the 'Power Mode' to Best power Efficiency I switched it to Best Performance and its up to 3700! So I'll leave it back on Balanced... Thanks And thank you for the quick reply!
-
Hi all, Bit of a random question. So I have a Xeon Gold 6148 base clock 2.4Ghz with a boost up to 3.7Ghz Thing is in the unRAID dashboard it never changes, it only reports 2.4 which is fine. But then I created a Windows VM and it too never changes when looking in task manager. I just setup the Windows in Docker and same thing, 2.4Ghz and never jumps around like a normal PC. This made me wonder if the CPU is boosting or not? I am running 7.0.0RC1 but it was the same on the 6 series too. Is there a linux command I can run on the unRAID terminal to check if it's boosting or not on the host? Or is there some BIOS setting I'm missing thats causing it to just chill at base clocks? Thanks
-
-
Thanks JorgeB, Would it hurt to just do a monthly Scrub on the array? I've not got any errors just want to make sure I dont have any furture issues if I can help it.
-
Hi all, Wondering if someone can help me. I setup the Parity Tuning to mainly stop during Mover. But for whatever reason it keeps stopping after 2mins saying: Manual Correcting Parity-Check I cant see why or how long it'll take. Do I just leave it to do its thing? namek-diagnostics-20241202-1039.zip
-
Yes ie not Cache Although I wouldnt mide advice on this too?
-
Hi all, So I have seen some mixed reports and also nothing recent. I am wondering if we should schedule both the Scrub and the Balance specifically for HDD's within the normal pool if not using XFS? I currently had my scrubs to weekly but its messing with the parity checks. So I am just trying to find the right balance here and what is required or not?
-
@Taddeusz can you pull in the latest Apache updates? Seems like the container hasn't been updated in 5 months but there is a new version of Guacamole 1.5.5
-
Can you upgrade to docker v25 as im trying to include some health checks which require docker v25 or later. Or would this need a unRAID update to update the docker engine on the background?







