




faxxe71
Members
-
Joined
-
Last visited
Everything posted by faxxe71
-
Clear and functional. I was able to remove my existing duplicates right away. Great job! -faxxe
-
I had a similar issue when 7.3.x came up and i had to add this key to the frigate docker: -faxxe

-
Entschuldige die unklare Beschreibung: Ich hab jedes Update am Server durchgeführt außer 7.3.0. Wo ich beim Erstellen des TM Backups im Nov.2024 war, weiß ich nicht mehr. Aber zu 99.9% auf der zu dieser Zeit aktuellen Version von Unraid. Nach Erscheinen der 7.3.1, habe ich von 7.2.7 auf diese aktuellste Version das Update durchgeführt. Incl nun booten von internen NVME Disks bin ich nuin auf 7.3.1 Möglicherweise ist mein TM Backup aus 11/2024 sogar noch auf einer 6.x.x erstellt worden (chatgpt meint das zu dieser Zeit noch 6. aktuell war). Ich habe gerade ein 10 MB pdf am Desktop von Dez 2024 testweise wieder hergestellt. Also ich denke, das Backup ist fehlerfrei.
-
Es ist schon irgendwie merkwürdig und hilft euch auch wenig aber ich hatte außer 7.3.0 sämtliche Versionen laufen und auf beiden Macs nie Probleme mit den TM Backups. Das TM Backup habe ich Ende 2024 eingerichtet und es ist lesbar. Zwar kommt manchmal im Unraid Log ein Eintrag sinngemäß mit einem Sparse Bundle blabla Error irgendwas aber macOS meint trotzdem, das immer alle Backups erfolgreich waren.
-
That worked for me. Customize it to fit your data I used it in Docker Compose on Unraid, and it worked. It comes from the Synology NAS guide available here: SparkyFitness on Your Synology NAS services: sparkyfitness-db: image: postgres:15-alpine container_name: SparkyFitness-DB hostname: sparkyfitness-db security_opt: - no-new-privileges:true environment: POSTGRES_DB: sparky POSTGRES_USER: sparkyuser POSTGRES_PASSWORD: sparkypass volumes: - /mnt/cache_ssd/dockers/fitness/sparkyfitnessdb:/var/lib/postgresql/data:rw restart: on-failure:5 sparkyfitness-web: image: codewithcj/sparkyfitness:latest container_name: SparkyFitness-WEB ports: - 13003:80 depends_on: - sparkyfitness-server restart: on-failure:5 sparkyfitness-server: image: codewithcj/sparkyfitness_server:latest container_name: SparkyFitness-SERVER environment: SPARKY_FITNESS_LOG_LEVEL: INFO SPARKY_FITNESS_APP_DB_USER: sparkyuser SPARKY_FITNESS_APP_DB_PASSWORD: sparkypass SPARKY_FITNESS_DB_USER: sparkyuser SPARKY_FITNESS_DB_PASSWORD: sparkypass SPARKY_FITNESS_DB_HOST: sparkyfitness-db SPARKY_FITNESS_DB_NAME: sparky SPARKY_FITNESS_DB_PORT: 5432 SPARKY_FITNESS_SERVER_PORT: 3010 SPARKY_FITNESS_EXTRA_TRUSTED_ORIGINS: "*" ALLOW_PRIVATE_NETWORK_CORS: true NODE_ENV: production TZ: Europe/Bucharest SPARKY_FITNESS_API_ENCRYPTION_KEY: 8b21ebe710cd46d4894f463264480f78fbf864b2ff0ee106b8d63ad434476eae JWT_SECRET: mVql49lpEas2imJWcNPKnbfLsWrfoh7rAyCiNRXEz7g= BETTER_AUTH_SECRET: mVql49lpEas2imJWcNPKnbfLsWrfoh7rAyCiNRXEz7g= SPARKY_FITNESS_FRONTEND_URL: https://*****.your.site.com********* SPARKY_FITNESS_DISABLE_SIGNUP: false #or true to Disable Sign Up after first registration. ports: - 4059:3010 depends_on: - sparkyfitness-db restart: on-failure:5
-
if i try to scan my media folder i got this message: 404This page could not be found.
-
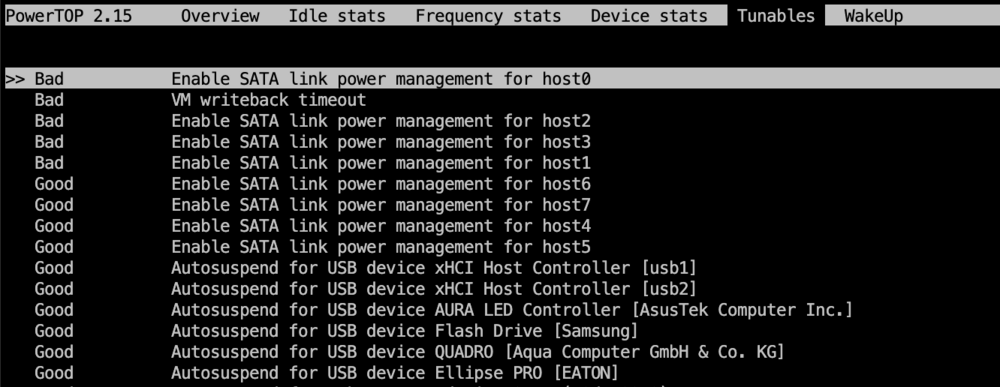
Ich hab in powertop bei den 4 dummy ports "BAD" stehen. Eigentlich nachvollziehbar aber warum gibt es dummy ports?Ich hab nur die 4 ports am Mainboard. Keinen zusätlichen Controller o.ä. -faxxe May 13 05:18:03 Raider kernel: ata1: DUMMY May 13 05:18:03 Raider kernel: ata2: DUMMY May 13 05:18:03 Raider kernel: ata3: DUMMY May 13 05:18:03 Raider kernel: ata4: DUMMY May 13 05:18:03 Raider kernel: ata5: SATA max UDMA/133 abar m2048@0x85702000 port 0x85702300 irq 146 lpm-pol 0 May 13 05:18:03 Raider kernel: ata6: SATA max UDMA/133 abar m2048@0x85702000 port 0x85702380 irq 146 lpm-pol 0 May 13 05:18:03 Raider kernel: ata7: SATA max UDMA/133 abar m2048@0x85702000 port 0x85702400 irq 146 lpm-pol 0 May 13 05:18:03 Raider kernel: ata8: SATA max UDMA/133 abar m2048@0x85702000 port 0x85702480 irq 146 lpm-pol 0
-
Danke, aber ist das die Lösung oder die Ursache? Man müsste den Kernel mit den geänderten Parametern neu kompilieren und dann mit diesen Bootparametern starten? Klingt nicht nach Tätigkeiten für mich gewöhnlichen User 🫣 -faxxe
-
I briefly tried 7.2.5, but I ran into some Docker issues. So I went back to 7.2.4 and am now on 7.3.0. The upgrade went almost flawlessly. Only one Docker instance was thrown off by the time zone setting. Otherwise, it’s been stable for over 24 hours. -faxxe
-
I also had connection issues for a long time, and adding these two additional flags to the Collabora Docker configuration was the solution for me. The first entry is the web address of your personal Nextcloud domain name. Note the syntax with a backslash (\) in between. And the second entry is the domain name of your personal Collabora server address.

-
Auch hier mit 7.2.6 Ich denke, bei mir hängen da die ST16000NM001G-2K 16TB Exos dran Irgendwas is immer ☹️ -faxxe
-
I also had too many glitches with 7.2.5, so I went back to 7.2.4. I was able to do it without any problems using the “OS Downgrade” menu option. -faxxe
-
7.2.4->7.2.5: The three Docker containers essential for Nextcloud—which I built and ran using the docker-compose plugin—stopped starting. Despite multiple attempts to rebuild them, it seems that some old IDs in the Docker database were the cause of the problem. I then deleted all 34 Docker containers and reinstalled them. Now they’re all running again.
-
Das sind meine SMB Einstellungen bei 7.2.3 interfaces = 10.80.51.254 bind interfaces only = no server multi channel support = no server min protocol = SMB2 server max protocol = SMB3 vfs objects = catia fruit streams_xattr fruit:metadata = stream fruit:posix_rename = yes fruit:loglevel = 1 veto files = /._*/.DS_Store/ aio read size = 1 aio write size = 1 strict locking = No use sendfile = No -faxxe
-
Auch hier läuft es am Mac Studio ohne Probleme. -faxxe
-
This system has been running without problems for over two years, but since version 7.2.3, a worrying message has appeared about five times: Jan 1 22:54:54 Raider kernel: r8125: eth0: link down Jan 1 22:54:54 Raider kernel: br0: port 1(eth0) entered disabled state Jan 1 22:54:57 Raider kernel: r8125: eth0: link up Jan 1 22:54:57 Raider kernel: br0: port 1(eth0) entered blocking state Jan 1 22:54:57 Raider kernel: br0: port 1(eth0) entered forwarding state It appears that the eth:0 LAN port disappeared for about 3 seconds. I thought it was due to the cable or port on the switch, but even replacing the cable didn't help. The strange thing is that this message has appeared about 5 times since the 7.2.3 update, with several days in between. It seems to be a very rare occurrence. However, it never happened before 7.2.3. It's so rare that it will probably be extremely difficult to find the cause. If you have any ideas, please let me know. BR raider-diagnostics-20260102-1438.zip
-
Sehr interessant; danke für den Test -faxxe
-
Thanks from me too. It looks really modern and stylish. -faxxe
-
Spannend.... arcstat geht bei mir: root@Raider:~# arcstat time read ddread ddh% dmread dmh% pread ph% size c avail 07:01:26 0 0 0 0 0 0 0 7.7G 7.8G 17.8G root@Raider:~#
-
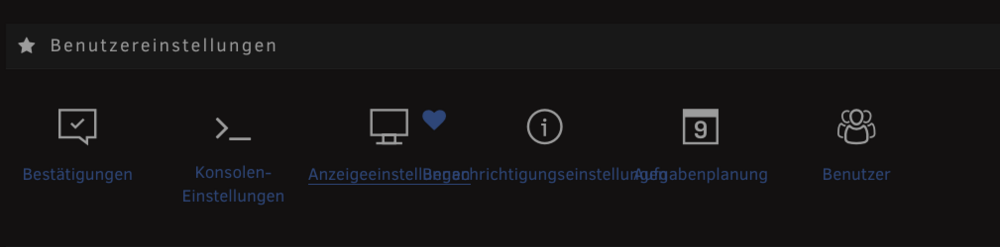
The update to version 7.2 ran without errors on my main server. All 25 Docker and Home Assistant instances in a VM are working. There is a minor visual inconsistency in one menu (see screenshot). Many thanks to the Unraid Team ! -faxxe
-
Ich hab noch ein N100 Backup Unraid System. Ich werde demnächst versuchen, wie es sich mit allen Docker vom i3 schlägt.inclusive Frigate. Der Umbau/Versuch wird aber noch etwas zuwarten müssen weil ich es zuerst in thermisch besseres Gehäuse verbauen muss. -faxe
-
Here is my SMB config. I use a Mac Studio. I connected it at 2.5 Gbit, but it also worked flawlessly at 10 Gbit and had the full expected bandwidth. Time machine works also well. interfaces = 10.80.51.254;capability=RSS,speed=2500000000 veto files = /._*/.DS_Store/ aio read size = 1 aio write size = 1 strict locking = No use sendfile = No server multi channel support = Yes readdir_attr:aapl_rsize = no readdir_attr:aapl_finder_info = no readdir_attr:aapl_max_access = no fruit:posix_rename = yes fruit:metadata = stream vfs objects = catia fruit streams_xattr -faxxe
-
PicoPSU ist natürlich auch eine gute Lösung wenns um den Wirkungsgrad geht... die mir bautechnisch nicht gefiel 🫠 Ich hatte bei allen von mir versuchten Lösungen immer das Problem mit sporadischen SATA Error Meldungen im Log. Ich bekam das erst in Griff, wenn ich vom Netzteil zumindest 3 zusätzliche Masse/12/5 Volt Versorgunsgleitungen zur Backplane der 4 Platten installiert habe. Die ganzen möglichen Adpater die es so gibt waren da auch nicht zielführend. Bei PicoPSU wird das aus meiner Sicht eine Challenge hier zusätzliche Leitungen zu montieren. Möglich, klar...aber aus diesem Grund habe ich es gecancelt. Die Impulse die große Platten beim Anlaufen haben, sind nicht zu unterschätzen. Wenn jetzt noch ordenlich Kabellänge dazu kommt, kommts eben gerne zu diesen SATA Errors im Unraid Log. Soweit meine Erfahrungen..... .-faxxe
-
Zu Frigate: ob man es braucht muss man natürlich selbst entscheiden. Aber die Stabilität und der einfache Umgang von Frigate ist schon klasse. Du hast die Videos sämtlicher Kameras zentral liegen und verwaltet. Das das dann auch stabil auf allen mobilen Endgeräten (per VPN dann auch von unterwegs). Und beim Stromverbrauch muss man natürlich auch die Verbräuche der Kameras selbst berücksichtigen. Die Kameras liegen bei mir bei ca 30 Watt. Der Verbrauch des Server steigt mit Frigate um etwa 4 Watt. Also wenn die Kameras sowieso laufen spielt IMHO der Server dann auch keine große Rolle mehr. Ausser man dreht ihn ansonsten komplett ab. Ich habe viel Zeit (und Geld 🤫) in die Optimierung des Unraid Server investiert weil 24/7 mein Ziel war. So verwende ich zB dieses Netzteil : HDPlex 250 Netzteil Ist Referenzklasse beim Thema Wirkungsgrad. Aber vermutlich wirds den Mehrpreis nie wirklich rein spielen 🙃 Anyway -faxxe
-
Ich habe unter anderem 9 Reolink Kameras per Frigate an einem i3-13100 mit 64 GB Ram laufen. Coral TPU. So läuft das seit Monaten 24/7 und schreibt alles auf eine Lexar NM790. Ich würde da niemals eine HDD dafür her nehmen. Im 21. Jh halte ich eine hochwertige NVME dazu passender. Lt Hersteller hat die Lexar eine TBW von 3 PB. Ich habe sie seit knapp 5 Monaten laufen und sie hat lt Unraid ca 50TB geschrieben und 90TB gelesen. Es werden aber auch nur Videos mit dezitierten Objekten geschrieben und 30 Tage behalten. Weiters schreiben neben 20 Docker (nextcloud plex etc) noch eine Homeassistant VM ihre Daten auf diese NVME. So sie in 3 oder 4 Jahren "tot" geschrieben wäre, schmeiss ich sie halt weg und kauf eine neue. So meine Meinung..... Mein System braucht mit dem 13-13100 auf einem Gigabyte B760B Gaming, 4 Stk Exos 16TB Platten i mStandby etwa 26-28 Watt. Tiefe C States Stromsparmodis spielts bei Frigate natürlich nicht mehr. -faxxe






