




mbc0
Members
-
Joined
-
Last visited
Everything posted by mbc0
-
This sounds interesting! I have 4 AP's connected directly to my switch on POE, the 5th one would be in my in-laws house but connected wirelessly as we are detached, there is no realistic way of running a cable. I just want to provide internet to them, nothing else! I will have a read of that link, it sounds perfect if compatible with my setup!
-
If I were to configure a "guest" Wifi within the unifi controller for my in-laws, would that still allow access to the rest of my network?
-
Thank you, I do have a GS1900-24 managed switch but I am using it as a "dumb" switch currently, everytime I have tried to configure a vlan on it, I end up factory resetting (almost certainly due to my lack of understanding) but it looks like I am going to have to try again! :--)
-
OK, thank you very much for the detailed reply! I need to have a think about the best & easiest way to do this as it is not my strong point!
-
Hi, thanks for your reply, I do not want to add hardware, I can create a vlan with OPNsense I just cannot work out if it would be possible with my existing hardware as the Unifi AP would be meshed as I cannot get a physical wire to my in-laws AP
-
Hi! I have just moved to this docker from the old version and although I had some adoption problems, all is working great now, thank you! I just have a question that I thought I would ask here if that's ok as my setup is using unraid. I have 4 Unifi AP's that I manage with this docker, my in-laws have bought the house next door and seeing as I have full fibre I thought it would make sense to let them share our internet. I will be adding a 5th AP for them that will be meshed from one of mine but my question is can I just provide them with internet? I do not want them to have access to my network. I am running OPNsense on unraid as well if that helps? Many thanks!
-
Just started having the same problem, did you find a fix?
-
Just wondering if anyone here has managed this? VERY little info on google for unraid users and although I have installed it, I cannot get past this screen.
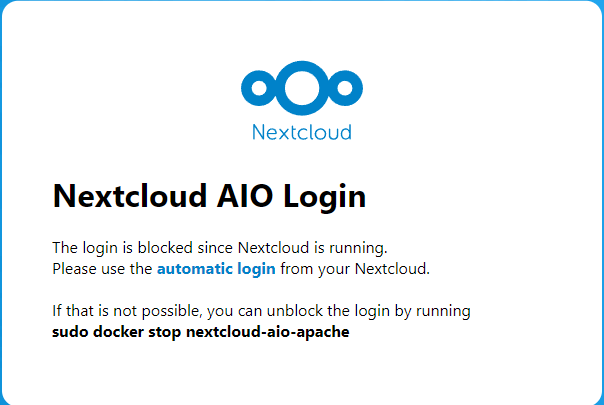
-
fantastic, thank you! It looks like I am up & running then 🙂 I thought generating thumbnails would have been an NVIDIA task but apparently not!
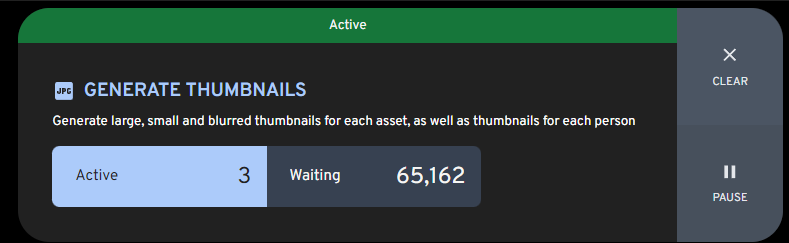
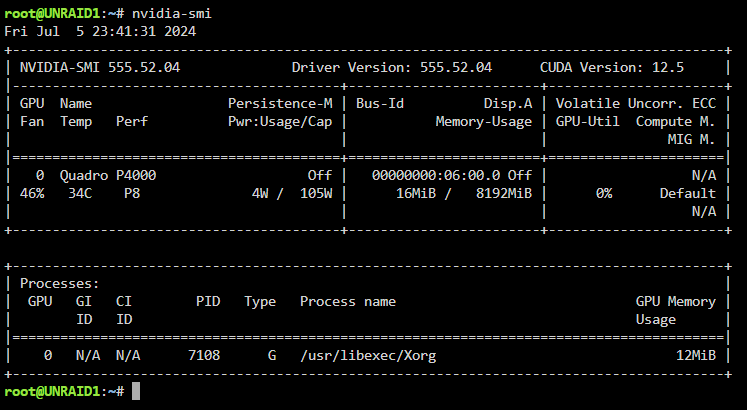
-
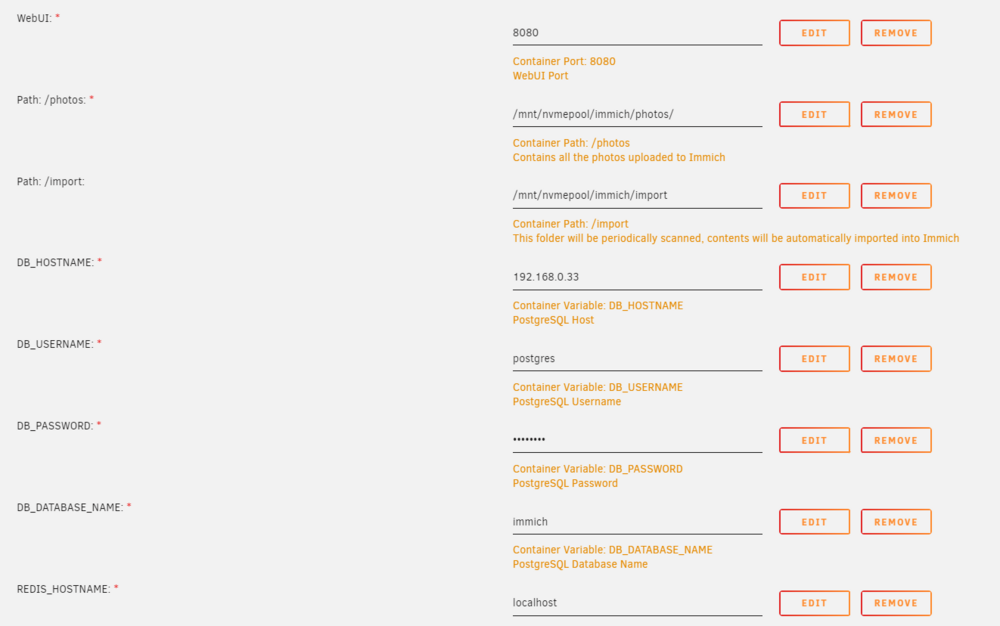
Hi! Glad you have it working 🙂 Thanks for the info @Mattaton Can I ask what command you are typing to show the NVIDIA info? I still don't seem to be getting my NVIDIA to work? Many thanks!
-
I have the same problem unfortunately, I have not invested too much time trying to resolve as too busy, will look forward to responses on here.
-
That's great! Thank you 🙂
-
Hi, I have seen this question answered with conflicting results, I would like to install an NVME drive to store my photo's on for Immich for response times (waiting for drive to spin up) I don't want a drive spinning 24/7 I have 20 or so HDD's currently 4XNVME's as 2 cache pools and would like to add an NVME drive into the array for protection, has anyone here done this for a good amount of time to give any advice? Many thanks
-
Hi, I have just walked through the installation video made by spaceinvader one and the only thing different I did was use a sub-folder instead of a dedicated share which has done the trick, thank you 🙂
-
Thank you, I will recheck again, I was sure all was ok but will have another look!
-
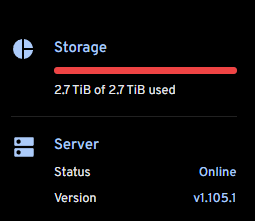
Hi, I see that my storage is always full? Is there a way to correct this information on the dashboard? As you can see here, I have 720GB available


-
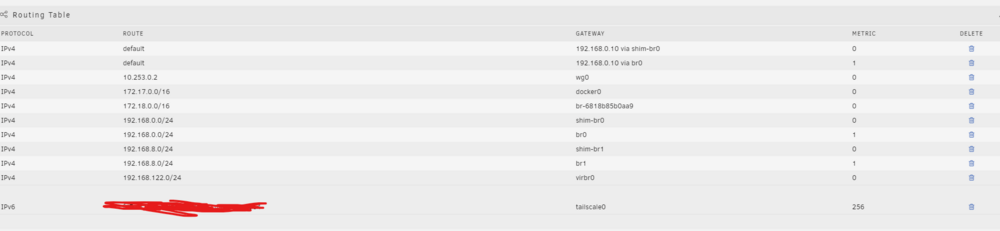
ok! Update, despite hours of googling before posting, I found a discussion on metrics straight after! This is my new routing table and it appears to now be working as intended! All except being able to communicate with 192.168.0/24 from 192.168.8/24 (eth1 to eth0) can anyone help with this please? I am able to do the reverse no problems. Many thanks 🙂
-
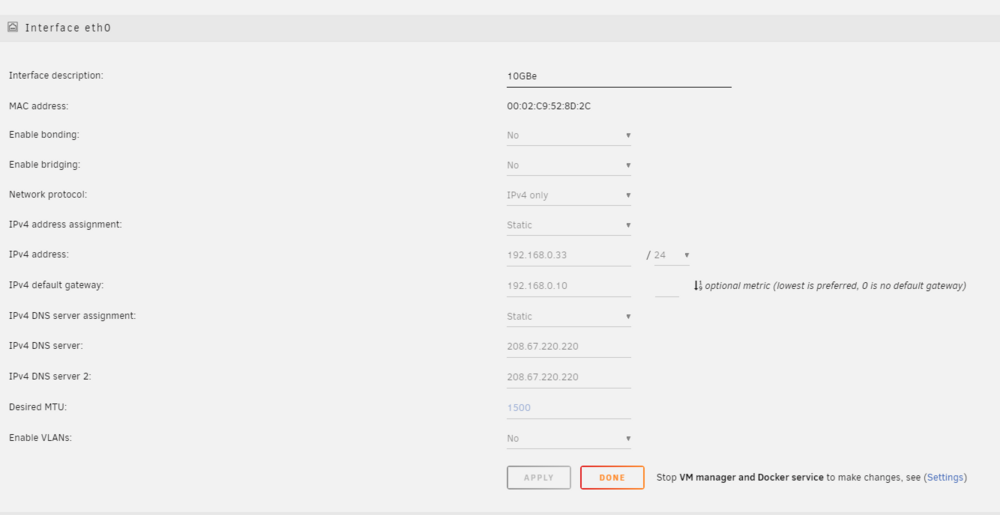
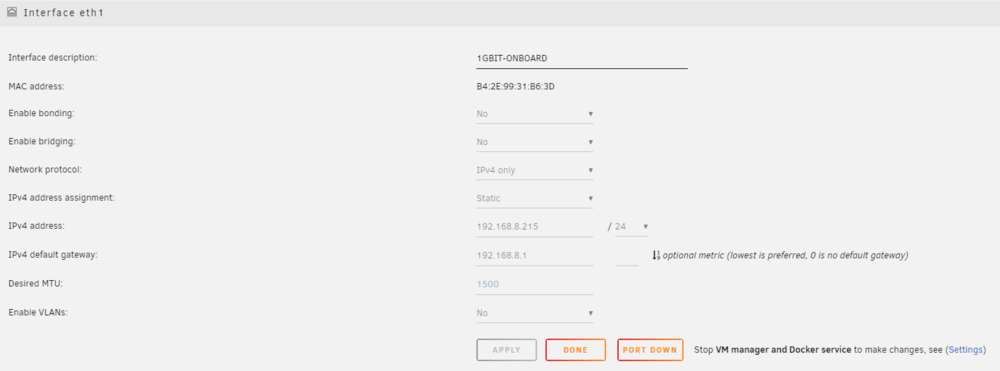
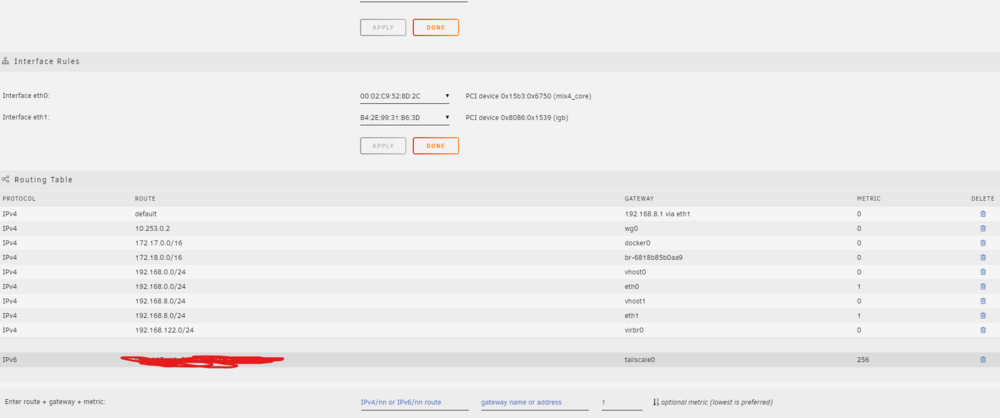
Hi! ***NOTE If I was able to assign a mac address to each docker none of this would be an issue as I am able to use Sophos to route traffic to either my DSL or 5G router but I am currently on ipvlan as macvlan caused me major issues a year or so ago, even though I have tried swapping back to macvlan out of desperation I could not see a way to assign a mac address, even with the extra parameter.***** Due to being behind a GNAT I have introduced a new 5G router that I would like to use on certain dockers and keep my DSL for unraid and everything else. I have 2 network cards in my unraid server 1, 10GBe for unraid and everything else on 192.168.0/24 (eth0) Gateway 192.168.0.10 (Sophos) 2, 1GBIT-ONBOARD for the 5G router (192.168.8.0/24 (eth1) Gateway 192.168.8.1 I need to be able to access both ip ranges for lan access to the dockers (although I can currently only access 192.168.8.0/24 from 192.168.0/24 it doesn't work the other way around, it would be great if they could access each other!) The problem I have is that although the dockers are working great using the new 5G router but for some reason the whole unraid server and all dockers are using the 5G router gateway? As you can see, the 10GBe interface is set to use the DSL on eth0 but for some reason it is using 5G router on eth1? Can anyone please see where I am going wrong? thank you! unraid1-diagnostics-20240503-0049.zip
-
Thanks Both, I never scanned any QR codes (Been away for months) I will contact support now.
-
Hi, I have 2 unraid servers that I cannot connect to, I have seen the posts on how to enable MFA but cannot get into any account settings until I enter a code? where is this code?
-
Hi, Can anyone point me in the right direction as to if it is possible to mount an unraid share on my vps server at all please? I do not have sudo so cannot install sshfs. TIA!
-
Just to update, deleting the network.cfg file and rebooting has resolved my issues
-
Hi, The 4port NIC is in my other unraid server (HP Microserver) which basically just runs Sophos XG Firewall, Home Assistand, etc very on resources, but that is why the routing table is not showing that. I have disabled the on-board NIC, re-installed the 10gbe card deleted the network.cfg file and let unraid recreate it on reboot and now everything "seems" to be working as expected! I have stopped/started the docker service 10+ times and all seems stable so will se how it goes for a few days, I hope this is the end of it!
-
When I start my docker service, this is what the routing table changes to

-
OK, another update! I have disabled all the containers, disabled the docker service and rebooted unraid, on reboot the network is working as expected but as soon as I enabled the docker service with no containers running at all the network problem above re-occured. I stopped the docker service again and everything is again working as expected so at least I now know the docker service is causing the issue, how would I go about resolving this? it there a problem with my routing table? (I really don't understand it)

















