




tjb_altf4
Members
-
Joined
-
Last visited
Everything posted by tjb_altf4
-
Switch to bridge network and right port settings will reappear. You can't port map on custom networks like the docker br0, so either you can have pihole on its own IP with no mapping (ports are 1:1), or you can use the port mapping like the pihole devs suggest. The error is likely the dhcp pool from docker network clashing with your dhcp set by your router. Its also possible you need to restart the server as Unraid may not have cleaned up its network artifacts correctly.
-
the way your describing used to work, but was broken a few releases ago to lockdown the UI for tailscale users. typical way to solve is to host icons on a github repo, or one way I solved this in the past was to spinup an nginx container with a configuration that supports directory browsing (you then grab that url).
-
I think those weird variables come from Unraid itself doing some jiggery to save port settings when you change to a network type that doesn't support port mapping... its not part of the binhex template. The variables aren't really a problem, but it is a symptom that you might not be using the correct network type.
-
Its official because it uses the docker container image from the author of the application i.e. pihole/pihole Unraid templates are a wrapper which hold the docker configuration, equivalent of docker run command. There templates are nearly all community author supported, and typically have a support thread... this one doesn't seem to, so post in their general thread: https://forums.unraid.net/topic/44108-support-binhex-general/page/8/
-
I'm going to be real here, if you can't even help yourself by searching for unknown terms on google etc, are you really ready to do advanced tasks like working with your encrypted array data from the CLI ?
-
This looks like you are only changing the properties for Unraid WebUI link, not the container's port settings.
-
Prowlarr doesn't have a vpn component, that read me is for containers with the vpn suffix e.g. delugevpn, qbittorrentvpn, sabnzbdvpn etc Typical use case is downloaders (e.g. delugevpn) have the vpn setup, and you use container networking to use that containers vpn connection.
-
you'll need to update your container templates manually, but here's a cli one-liner to give you a table of info you need (container name, ip and mac address): docker ps -q | xargs docker inspect \ --format '{{.Name}} {{range .NetworkSettings.Networks}}{{.IPAddress}} {{.MacAddress}}{{end}}' \ | column -t
-
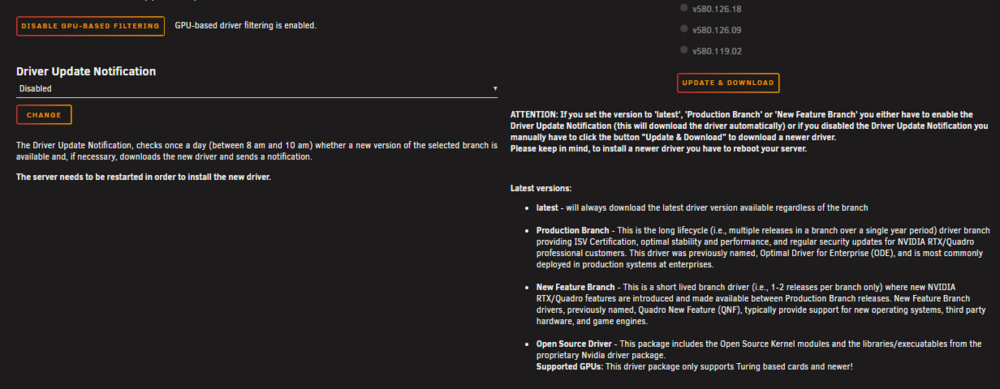
setting is still there for me 🤷♂️
-
--gpus=all is the modern, supported method for gpu passthrough as per Dockers documentation (linked). It does work on Unraid, I use it currently in 7.2, but there are regressions in 7.3.x, which look likely to be issues with nvidia-container-toolkit. https://docs.docker.com/engine/containers/gpu/
-
This is an Unraid templating limitation, its a known issue. Assuming the IP is static, change the WebUI entry, replacing the dynamic [IP] portion with the actual IP. WebUI link should work if done correctly.
-
I've got a few sets of rj45/transceivers from fs.com which I've been happy with, there's a few different specs available, including coding for your NIC and switch (if it happens to be one that has compatibility issues).
-
it would be talking from a raw speed perspective, and as an acceleration device. 2 reasons this doesn't matter, optane is lower latency so is better for real world use, and the raw speed of slower gen3 pcie is still multiples faster than what Unraid users are coming from with USB drives
-
I agree with the premise, but not the solution. IMO, better to introduce reputation/reviews for developers in CA, and promote these devs and their work above others. Devs producing crap, AI assisted or otherwise will develop poor/negative reputation, new devs can be labelled as such while building rep, while LT can promote "trusted devs" including it own team. This should mean the community can regulate and thus promote quality developers. Similar system could be brought in for containers, but obviously there are a few more factors to take into consideration there.
-
If I remember right, you need to boot into live mode so you can actually modify and extend the partition with fdisk. You won't be able to modify the system partition if its in use.
-
Unraid File Manager uses rsync in the background, not sure what options it uses but I'd imagine its been built to preserve metadata
-
Good option for unlimited users then, maybe not so much 6 device users... thanks!
-
which is why I left it open for correction from someone who knows the answer rather than leaving it unsaid
-
You can now either have dedicated boot drive(s), or boot drive(s) where you can also use extra space in a separate partition as a pool. So if you have a 2TB SSD, you would want to used the original implementation which allowed you to use both boot and pool data on one drive. But if you picked up for example a small optane drive e.g. 16GB, you can dedicate it completely to being a boot drive... I'm assuming this also means it won't count as a disk device for licencing purposes also.
-
Should work out of the box without additional configuration on the Unraid side. I'd be looking at the mikrotik's port configuration... noting that you are running tagged and untagged traffic on br2 which likely needs additional configuration.
-
Short answer, try 8095:80 Long answer, taken from docker docs: Publishing ports Publishing a port provides the ability to break through a little bit of networking isolation by setting up a forwarding rule. As an example, you can indicate that requests on your host’s port 8080 should be forwarded to the container’s port 80. Publishing ports happens during container creation using the -p (or --publish) flag with docker run. The syntax is: docker run -d -p HOST_PORT:CONTAINER_PORT nginx HOST_PORT: The port number on your host machine where you want to receive traffic CONTAINER_PORT: The port number within the container that's listening for connections For example, to publish the container's port 80 to host port 8080: docker run -d -p 8080:80 nginx Now, any traffic sent to port 8080 on your host machine will be forwarded to port 80 within the container. https://docs.docker.com/get-started/docker-concepts/running-containers/publishing-ports/
-
I'm not sure what other users failure modes were on USB, but mine were always linked to boot partition corruptions (and were recoverable with a reformat). I always wondered if simply moving to a more resilient filesystem would improve failure rates. Would formatting usb with a different filesystem be possible under new internal boot?
-
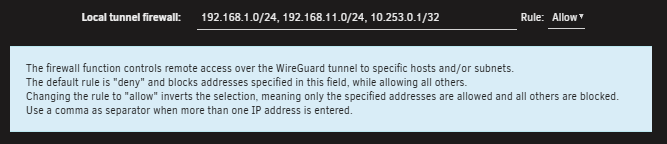
For others that don't have the luxury of a wireguard enabled router, this is the setting you need to look at in Unraid VPN manager (toggle basic to advanced mode). These are the list of networks you are allowing to be accessible from your wireguard tunnel. In my example I have 2x networks I wish to access, the last is the wireguard network itself which should be there already (may be a slightly different subnet).
-
Just use wireguard on your Unifi router.
-
Try turning off "Enhanced macOS interoperability" in SMB settings




