




Dissones4U
Members
-
Joined
-
Last visited
-
Well, this explains a lot! I've had a similar issue but it was more of an annoyance and so I ignored it. Now that I understand this I've tweaked some settings and should be able to avoid any overflow onto the array moving forward. Thanks!
-
According to this bug report I know this may be too simple BUT I had a similar situation and realized that after a recent move I'd plugged everything into the surge side of the UPS and not the backup side (because I did it blind due to space). This resulted in the exact situation you show above, zero load on the UPS, I noticed it a few weeks later and plugged everything into the other side.
-
have you tried: ps l (try ps -x instead this gives a better list with the current state of the process and the pid) anything waiting should be in the (uninterruptible) D state I think... all of my processes are in the (interruptible) S sleep state.
-
Hello Djoss, thank you for the Filezilla docker! I've recently noticed a change in behavior and I can't seem to fix it. I have the remote path set to /mnt/mpathh/myusername/files/TV and it has always worked but recently it has stopped the connection at the top level directory of my user name (where the .trash and .ssh files are), until now I have simply browsed to the desired directory from there but now I'd like to try the sync function which would require it to connect to the TV folder directly (at least I think). if you have any thoughts on why it isn't following the defined remote path to the end I would appreciate your insight. BTW it does log the error "no such file or directory" but there definitely is and I can navigate to it within Filezilla once the connection is made to the top level directory. Thanks again!
-
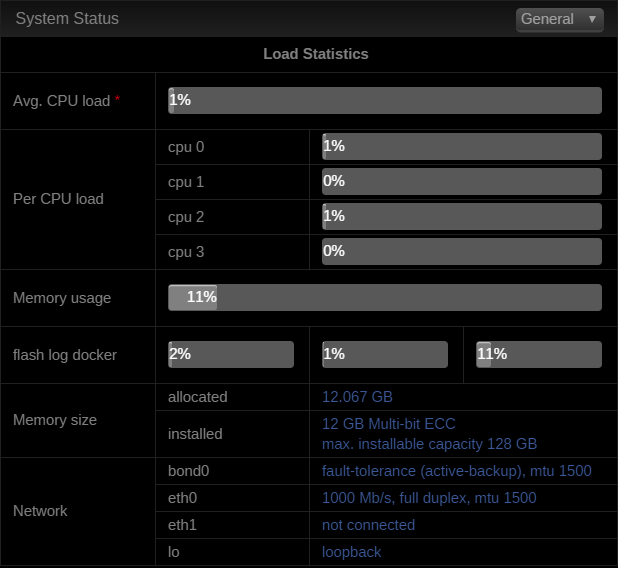
12 GB Multi-bit ECC it seems to run fine and can be upgraded to 128 GB but I haven't really had a reason to...
-
okay cool, I thought that I may not need to maintain empty space because it's not like I defrag it or anything but I always err on the side of caution when I'm not sure. So fill'er up it is, thanks guys!
-
So how full is too full, two of my four disks are over 93% full? I was considering moving files to my new empty disk and making the disks around 85% full. Is that a waste of time?
-
What am I missing, based on the first post in this thread it sounds like unbalance can do exactly what Arandomdood is describing. In fact, I was about to install it myself for the same purpose but I wanted to read the support page first. The first post says:
-
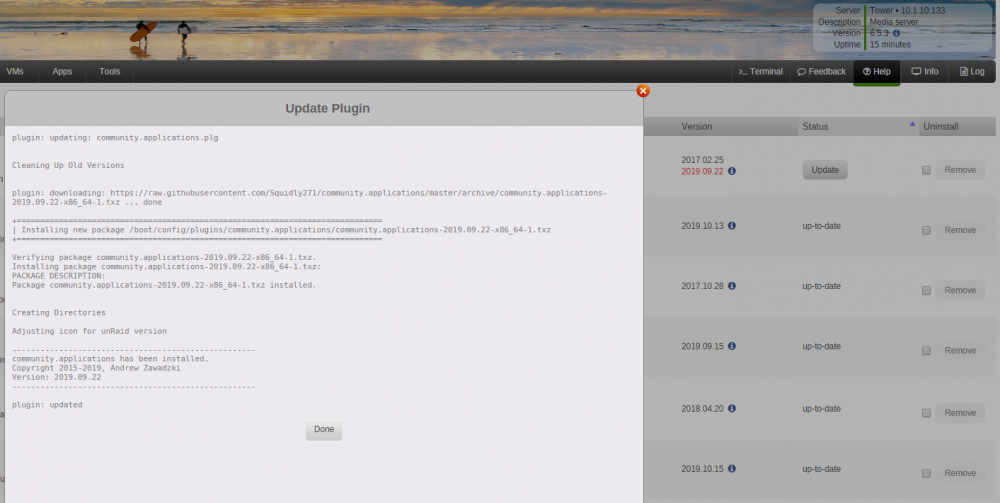
Just a heads up squid, I decided to update incrementally so I'm currently at OS v6.5.3 from 6.3.2 and CA did in fact just update to version 9.22.19 hopefully this is not a problem, I've attached an image just in case you want to see. I'll run the array for a day or two and then update the OS further. BTW I've read through your change-log on the old version, it was very thorough and easy to follow, I especially liked the OCD change regarding the spinner! Anyway, thank you for all of your hard work brother, you are an invaluable asset to this community. 😎
-
Hey guys, I'm trying to update from 6.3.2 and admin's post (here) refers me to @ljm42's excellent 6.4 Update Notes. These notes say to run the Fix Common Problems plugin, specifically the update assistant. The problem is I can't seem to find the Fix Common Problems plugin in the apps tab so I can't install it. Thanks in advance! **EDIT** So I tried to update CA to see if that was the issue, unfortunately I can't update it because apparently 6.3.2 is too old, rather than jumping to the latest release maybe I should update incrementally? On the plugin tab it is telling me that 6.5.3 is available...
-
I've got a quick question, my sonarr is working as it should but when I go to the log there is a recurring error message and I'd like to know if it indicates a permissions error that may be a problem for me later, it says: Thanks in advance... Couldn't get total space for /UNRAID/var/lib/docker/btrfs/subvolumes/5be4b4d0c230dc13296a55f9b4a81589d9fc8cdc33fffb0b99b7df23a4fd7bb0: Permission denied The exception block says: System.InvalidOperationException: Permission denied ---> Mono.Unix.UnixIOException: Permission denied [EACCES]. --- End of inner exception stack trace --- at Mono.Unix.UnixDriveInfo.Refresh (Boolean throwException) <0x41fbdec0 + 0x000e3> in <filename unknown>:0 at Mono.Unix.UnixDriveInfo.Refresh () <0x41fbde90 + 0x00013> in <filename unknown>:0 at Mono.Unix.UnixDriveInfo.get_TotalSize () <0x42016a30 + 0x0000f> in <filename unknown>:0 at NzbDrone.Mono.Disk.ProcMount.get_TotalSize () [0x00000] in M:\BuildAgent\work\b69c1fe19bfc2c38\src\NzbDrone.Mono\Disk\ProcMount.cs:37 at NzbDrone.Mono.Disk.DiskProvider.GetTotalSize (System.String path) [0x00064] in M:\BuildAgent\work\b69c1fe19bfc2c38\src\NzbDrone.Mono\Disk\DiskProvider.cs:106
-
I've read in the forums that running preclear from screen is recommended due to potential loss of connection which may abort the process. I couldn't figure out nerd tools so I tested this premise by closing the browser after starting preclear. I came back to the gui about 20 minutes later and it was still running as expected. I will leave my remote computer on tonight just in case I'm missing something but it seems to me that I can start preclear then turn off my remote computer and the script will continue to run. Can anyone confirm that this is the case or is nerd tools working in the background somehow? I did install it and start screen, I just couldn't figure out how to initialize a terminal from the gui.

