




Altheran
Members
-
Joined
-
Last visited
Everything posted by Altheran
-
You loose your GPU X time after starting your server, and it comes back after a reboot ? If you have the same symptoms as me, I edited my solution as I had to tweak my go file also. Also, export your diagnostics zip file into ChatGPT, see if it think you have the same issue as me.
-
For anyone loosing access to their GPU randomly, here is what I did : Losing my GTX1660 GPU randomly X days/weeks ? after a reboot. - General Support - Unraid
-
So, I updated my BIOS and disabled any and all power management settings ... Rock solid for the last week. Note that I did nothing past my "Here is where I might pratice caution with what it is suggesting :" comment in the middle of the instructions. Edit : BIOS "only" finally didn't fix it for good (made last longer tho), I had to edit my /boot/config/go file and added these lines at the end (or in the order it makes most sense for you) # Ensure NVIDIA driver is initialized & kept warm between clients modprobe nvidia /usr/bin/nvidia-smi -pm 1 # Optional warm-up query (fails fast if device absent) /usr/bin/nvidia-smi -L || true
-
Hi, I want to report an issue with either Unraid 7.2 and/or Nvidia drivers plugin when updating to 580.105.05. Starting a --runtime=nvidia enabled container (linuxserver/emby:beta and ghcr.io/haveagitgat/tdarr) results in this error : docker: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running createContainer hook #4: exit status 1, stdout: , stderr: 2025/11/04 15:46:40 Error updating ldcache: error running pivot_root: pivot_root .: invalid argument Reverting back to 580.95.05 fixes the issue. Diagnostics analysis by ChatGPT return this explanation : 580.105.08 introduced a userspace/toolkit change that doesn’t play nicely with your current Docker/runc/overlayfs combo on Unraid 7.2. The failure happens in the NVIDIA Container Toolkit OCI prestart hook (the one that tries to run ldconfig inside the prepared rootfs); its internal pivot_root call returns EINVAL → container won’t start. Removing --runtime=nvidia sidesteps the hook entirely (so Emby starts, but loses NVENC). Rolling back to 580.95.05 downgrades that hook/tooling to a version that does work with your stack—hence everything comes back. Original diagnostics attached. I'd guess either an issue in the update process, incompatibility between the new driver and the packaged toolkit, or something in unraid betwwen the toolkit and the containers. untheran-diagnostics-20251104-1557.zip
-
Ok, so fun fact, ChatGPT (v5, thinking mode) is REALLY good at extracting and analyzing the diagnostics zip file. Prompt (+ upload of the diagnostics.zip in the same prompt): In Unraid OS, I have an Nvidia GTX 1660 GPU. All works fine for a good while, then randomly, my gpu is not found. When I reboot, everything comes back all right and working for a while. I rebooted this morning, and right now the GPU is not found. Analyze all the files and logs in this compressed zip archive. Extract the file's content, analyze all the logs and configurations, report back with an explanation of this behavior and provide a step by step solution. Here is what it reported : What’s happening (from your logs)Driver loads at boot: At boot the NVIDIA kernel modules load cleanly and bind to the 1660 at PCI 0000:01:00.0: nvidia: loading ... NVRM: loading NVIDIA UNIX x86_64 Kernel Module 580.95.05 DRM attaches: [drm] Initialized nvidia-drm ... for 0000:01:00.0 A few minutes later the GPU stops initializing Starting at 10:40:20 (same boot), the kernel begins spamming: NVRM: GPU 0000:01:00.0: RmInitAdapter failed! (0x25:0xffff:1623) repeated many times as RmInitAdapter failed! (0x62:0x40:2661) These lines continue for minutes. When this starts, nvidia-smi shows “No devices were found” (your system/nvidia-smi.txt). The gpustat JSON also reports vendor command errors and N/A for clocks/temps. You have three display adapters in this system ASPEED BMC (IPMI) — AST driver (BMC console) Intel iGPU — i915 driver, device 00:02.0 NVIDIA GTX 1660 (TU116) — device 01:00.0 Motherboard: Supermicro X11SSH-LN4F, BIOS 2.0b (2017-07-27). PCIe power-saving is enabled Your bridges show ASPM L1/L0s enabled (system/aspm-status.txt). ACPI reports AER unsupported (“platform does not support [AER]”), so the OS can’t log link-layer errors even if the link is flaking. Timing correlation Docker/containers (including Tdarr, which can use NVENC) start around 10:36–10:37. A few minutes later (~10:40) the NVIDIA driver begins failing to (re)initialize the adapter. This pattern is classic for a card that’s slipped into a bad PCIe power state or is being poked while the driver isn’t “persistent.” Diagnosis in one line:Your GTX 1660 is on an older Supermicro platform (2017 BIOS) with ASPM power-saving enabled and two other GPUs present (ASPEED + Intel iGPU). Under load/idle transitions the GPU drops into a PCIe power state the driver can’t recover from; when a container touches it, the driver tries to (re)initialize and you get RmInitAdapter failed storms. A reboot resets the link, so it “comes back” — until the next time it falls into that state. Why this causes the exact symptoms you seeASPM + older platform firmware: Aggressive PCIe link power management (L1/L0s) on some older C236/X11 boards is notorious for GPUs “falling into a ditch.” Without AER, the kernel can’t even record proper link errors — so all you see is NVIDIA’s RM failing. Multiple GPUs: With ASPEED + Intel iGPU + NVIDIA in the same machine, BAR allocation and power policies get more complex on old firmware. Even if initial BAR assignment is OK (it is in your log), subsequent power-state transitions can leave the device non-responsive to RM (NVIDIA’s resource manager), which matches your RmInitAdapter failed! loops. No persistence mode: If nothing keeps the device initialized between client uses, transitions in and out of low-power + module refcounts can amplify the chance of landing in that bad state. Containers hitting the GPU while it’s not “ready”: Tdarr/Plex/etc. may probe NVENC very early after boot; if the card hasn’t fully settled (or slipped into ASPM L1.2), that’s when the first RM failures typically appear. Fix plan (do in order)You don’t have to do every step — but the more of these you apply, the more bullet-proof it gets. I’ve split them into BIOS, Unraid boot parameters, and service ordering. None of these change your data or array. 1) BIOS / firmware settings (Supermicro X11SSH-LN4F)Update BIOS to the latest available for X11SSH-LN4F. You are on 2.0b (2017-07-27) — several later revs improve PCIe compatibility and resource handling. Disable ASPM in BIOS (PCIe power management). Set PCIe ASPM/Power Saving to Disabled (global and per-slot if offered). Force slot speed for the x16 slot hosting the 1660 to Gen3 (not Auto). (Your logs show 8.0 GT/s caps on bridges; forcing speed avoids training oddities.) Enable “Above 4G Decoding” (a.k.a. 64-bit BAR decoding). Even though initial BARs look fine, this reduces pressure with 3 GPUs + NVMe/SATA HBAs. Primary display: Set Onboard/BMC as primary; if you don’t need Intel QuickSync, disable the Intel iGPU entirely. If you do use QuickSync in containers, keep iGPU on — but still set BMC as primary. (If you can only do a couple things: update BIOS, disable ASPM, force Gen3.) Here is where I might pratice caution with what it is suggesting : 2) Unraid boot (Syslinux) kernel parametersEdit: Main → Flash → Syslinux Configuration (apply to the boot stanza you use). Add to the append line: pcie_aspm=offOptional but sometimes helpful on X11 when not using Intel iGPU: To keep the iGPU from binding at all (if you don’t need it): modprobe.blacklist=i915 If you see framebuffer clashes (rare here), you can also add: video=efifb:offApply and reboot. 3) Make the NVIDIA device “persistent” and start GPU containers after it’s readyEnable persistence mode at boot Add these lines near the bottom of /boot/config/go (before the last line is fine): # Ensure NVIDIA driver is initialized & kept warm between clients modprobe nvidia /usr/bin/nvidia-smi -pm 1 # Optional warm-up query (fails fast if device absent) /usr/bin/nvidia-smi -L || true Stagger GPU containers (Tdarr, Plex/Emby/Jellyfin, etc.) until the device node exists. If you use the User Scripts plugin, create one named “Start GPU containers” with: #!/bin/bash # Wait up to ~2 minutes for NVIDIA device to appear for i in {1..60}; do if [ -e /dev/nvidia0 ]; then break fi sleep 2 done # Start your GPU-using containers (edit list) docker start tdarr 2>/dev/null || true # docker start plex 2>/dev/null || true # docker start emby 2>/dev/null || trueSet it to At Startup of Array. Also set those containers’ own setting “Start when array starts” = No, so your script controls the timing. Double-check container GPU flags In each GPU container template: NVIDIA_VISIBLE_DEVICES = your GPU UUID or all NVIDIA_DRIVER_CAPABILITIES = compute,video,utility (for NVENC) Use the NVIDIA runtime (Unraid’s NVIDIA Driver plugin does this automatically when set). 4) (If not using QuickSync) keep Intel iGPU out of the wayIf you don’t need QuickSync: Either disable Intel iGPU in BIOS or Create /boot/config/modprobe.d/blacklist-i915.conf with: blacklist i915(This keeps i915 from binding, reducing multi-GPU interaction. Reboot to apply.) 5) Physical basics (worth a quick check)Ensure the GTX 1660 has all PCIe power plugs fully seated. If using a riser, test directly in the board slot. Try another slot if available (on X11 it may share lanes with other controllers). How we know this is the root causeKernel shows successful bind at boot and repeated RmInitAdapter failed a few minutes later (10:40:20+). That pattern is not a driver install issue — it’s a device/link power or initialization issue. nvidia-smi has “No devices were found” at the time your diagnostics were captured — exactly what RM-init failure yields. ASPM is enabled and AER is not available on this platform, which hides link-error breadcrumbs and is a well-known recipe for flaky GPU links on older server boards. Three GPUs present (BMC + Intel + NVIDIA) on an old BIOS (2017) increases the chance of a device getting power-gated or left in D3 during runtime. After you make the changesReboot. On the Unraid console or SSH: nvidia-smi watch -n1 nvidia-smiYou should see the 1660 listed and it should remain visible indefinitely. Start a GPU workload (Tdarr/Emby NVENC) and watch for any new NVRM lines in Tools → System Log. There shouldn’t be any RmInitAdapter failed after these fixes. If anything still misbehaves, the next most impactful single change is disabling the Intel iGPU (if you don’t use it) and ensuring ASPM is truly off (both BIOS and kernel pcie_aspm=off). TL;DRYour GTX 1660 is fine; it’s the platform power/PCIe policy. Update the X11SSH BIOS, disable ASPM, set the GPU slot to Gen3, enable Above-4G, keep the card “awake” with nvidia-smi -pm 1, and start GPU containers only after /dev/nvidia0 exists. This stops the RmInitAdapter failed loops and the random “GPU not found” episodes without needing to reboot. So, I'll try the BIOS fixes first, it should fix the PCIe power management issues. Any thoughts on the rest of the suggestions ?
-
Hi all, I looked around about why this might happen and possible fixes. Can't figure where to start with this ... I need the collective knowlege of you fine people. Got a GTX1660, using Nvidia Drivers and a certain patch applied at first array start only. (Setup worked flawlessly for years, issue appeared ~ 6-8 months ago) All works fine for a good while, then randomly, my gpu is not found. It disapears from my Transcode GPU choices in Emby. GPU Statistics throws a "Vendor command returned unparseable data." nvivia-smi returns "No devices were found" Tools > System devices I still got : IOMMU group 2: [8086:1901] 00:01.0 PCI bridge: Intel Corporation 6th-10th Gen Core Processor PCIe Controller (x16) (rev 07) [10de:2184] 01:00.0 VGA compatible controller: NVIDIA Corporation TU116 [GeForce GTX 1660] (rev a1) [10de:1aeb] 01:00.1 Audio device: NVIDIA Corporation TU116 High Definition Audio Controller (rev a1) [10de:1aec] 01:00.2 USB controller: NVIDIA Corporation TU116 USB 3.1 Host Controller (rev a1) Bus 003 Device 001 Port 3-0 ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 004 Device 001 Port 4-0 ID 1d6b:0003 Linux Foundation 3.0 root hub [10de:1aed] 01:00.3 Serial bus controller: NVIDIA Corporation TU116 USB Type-C UCSI Controller (rev a1) After a simple software reboot, everything comes back and work fine. I attached anonymized diagnostics untheran-diagnostics-20251101-2135.zip
-
+1 one on this. There doesn't even seem to be any premade images even ... quitte an issue with Unraid I'd say ....
-
It's what I did ! But still, there are some parameters that can't be in an ENV FILE, like Post Arguments that MIGHT contain sensitive data.
-
@bonienl Is this this an issue ? Do we still have to use virtio-net in VMs if we use Docker containers ?
-
Given that the flash drive can't be encrypted and that docker user-templates definitions often containing credentials and keys are stored in the clear, it would be nice to have an option to move /boot/config/plugins/dockerMan on a pool drive (cache). Could be as simple as storing data on an unpublished share and making a symlink to the original folder. I tried, but it won't let me do "ln -s /mnt/cache/dockerMan /boot/config/plugins/dockerMan". Might be a cool approach for any other "config" that doesn't need to be available before the array is started and available.
-
@SimonF you need this ? ipmifan.log
-
Ok, now we are getting somewhere. I tried this in "Extra parameters" in my containers with no success : --sysctl net.ipv6.conf.all.autoconf=0 --sysctl net.ipv6.conf.all.accept_ra=0 Soooo, what else is there for me to try ?
-
@SimonF Here, are you aware of such issue ?
-
I just tried to login into my WebGUI this morning, Error 500. Dockers still working. I logged into cli via IPMI, htop, no performance issues, RAM and CPU cruising. Tried restarting the webgui process via "/etc/rc.d/rc.php-fpm restart", didn't work. Found a thread saying GPU Statistics might be the culprit here So I tried "plugin remove gpustat.plg" and restarted php-fpm. Back online ! So there seems to be a serious issue with the plugin that makes php-fpm crash or something. @SimonF what do you need to check on that ? I didn't reboot, so I might still have some relevant logs.
-
The outgoing rule is planned, I want to block all other clients (Except my UNRAID server itself and my router) on my LAN from making DNS queries anywhere else but my Pi-Hole. And I DID enable RA in my router, I want my devices on my LAN to use SLAAC. I don't have issues with SLAAC by itself. It's just that when I configure a "STATIC" IPv6 on a device, I don't want it to go out of it's way and not use said Static IPv6 ;).
-
The issue was that my pi-hole container was making upstream dns queries using the automatic Address that I did not configure and did not allows trough my firewall (Because I had specifically configured a fixed IP !), so I had MASSIVE dns timeouts until I also allowed the surprise SLAAC IP. That behavior is gonna be a PAIN to manage in larger organizations .... some "quirks" of IPv6 are still to be polished ...
-
Hi, I am super late but for posterity. Yes, I just bought an X13SAE-F with a 14900k and 192GB of RAM. Using it with an LSI 9207-8i (pcie3.0 x inside a SC847 SuperMicro Case. MB shipped with the latest bios (3.3b) and BMC firmware. Worked right out of the box. All core accounted for and good performance. All RAM accounted for, running at 4000MT/s (As specified in the documentation) I'm using a Dynatron Q5 cooler with Thermal Grizzly KryoSheet thermal interface (So it wont ever degrade). In a room around 18-19C, CPU stays around 40C (no load) 60C light load, 70-75C High load on an "Optimal speed" setting selected. LSI card will work in the top pcie slot if alone. If both pcix16 slot are to be used, they will both only work at 8x BUT the top slot needs to be a 16x I think, not tested, only deducting from documentation.
-
I also have an issue, I installed "Intel GPU TOP" and "GPU Statistics". All I have in my dashboard is "No GPUs selected - Select GPU(s) in GPUStat settings page and apply." But I can select anything in the "Unit ID for Dashboard(Multiple):" Unraid 7.0.0-beta.4 i9 14900k -> UHD770
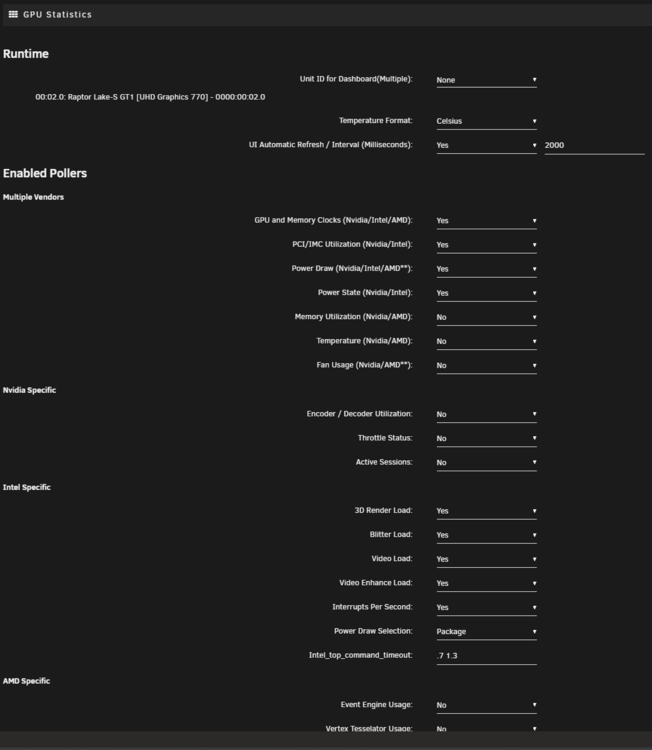
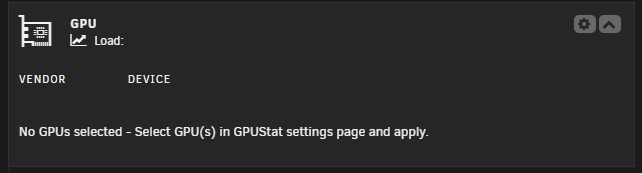
-
I don't have a problem with dynamic adresses per say, and my isp provides static Prefixes on demand, so i'm good there. I am just super annoyed that a device (container) I set with a static IPv6 adresse still gets a SLAAC one on the side
-
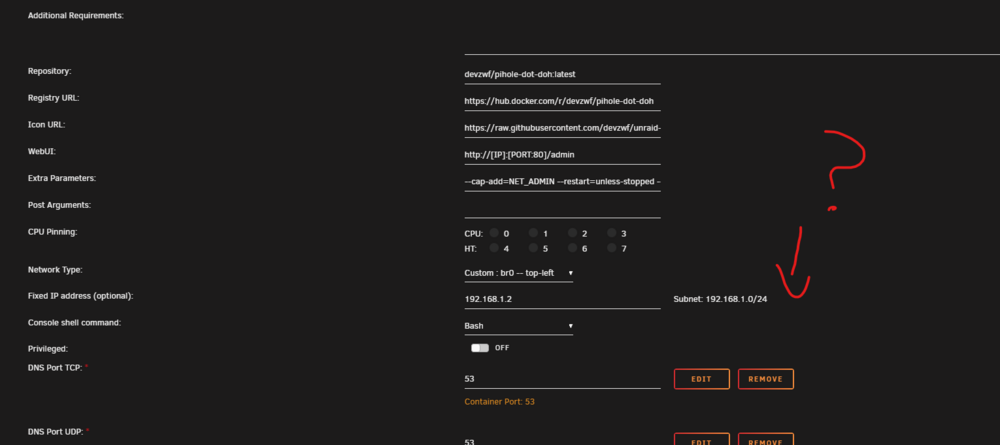
Following my previous post IPv6 is working, superb BUT I found an ... unwanted behavior. I've defined a static IPv6 on my PiHole DoT Doh container = Fixed IP address (optional): [192.168.1.2, 2606:6d00:xxxx:xxxx::1:2] Subnet: 192.168.1.0/24, 2606:6d00:xxxx:xxxx::/64 Now to be super sure that all my DNS queries goes to my PiHole to forward queries to Cloudflare via DoH, I made some Firewall Ingress LAN rules on my router. Essentially, Block all ports 53 and 853 from entering the routers from the LAN EXCEPT my PiHole (v4 and v6 defined up there), Unraid and my own gateway's interface Ip. Block all traffic destined to any of the IPs (v4 or v6) of known public DNS supporting DoH (Ain't nothing bypassing my own DNS server trying to use DoH themselves) So following that ... I had a lot of instability for my dns requests, timeouts and such. I went inside my PiHole container's Shell and did some tests. IPv4 was working fine, IPv6, not so much, could not reach cloudflare with a ping ... I did an ip addr : Oh there is the culprit, the container had assigned himself a routable v6 IP trough SLAAC beside the link local and the static IP defined in the GUI. Added the IP to my allow list on my firewall, Problem fixed ! Now ... I don't want my containers configured with a Fixed IP to go and get another One trough SLAAC (or even generating a link local?). I tried this in "Extra parameters" with no success : --sysctl net.ipv6.conf.all.autoconf=0 --sysctl net.ipv6.conf.all.accept_ra=0 Even after adding that, and restarting the container, when i shell into the container and do an ip addr, the damn SLAAC IPv6 address is still there ... any idea on what I could do ? fun fact, I added --sysctl net.ipv6.conf.all.disable_ipv6=1 to 2 of my containers that were not playing nice with cookies exchange, and it effectively disabled IPv6 on those containers.
-
Well, I got it ! Updated to 7.0.0 beta4 as there was a few IPv6 fix listed for docker, didn't want to take chances. Didn't work. Then I removed the bridge as I don't really use it and also enabled host access to custom networks. (Edit: host access created a duplicate of my Unraid IP under a new MAC, triggering some annoying notifications in UniFi. I reverted back this setting to Disabled, and everything keeps working fine, so no need for host access for IPv6 to work, it was just the bridge ! ) Then the subnet appeared in my container settings ! Now to define the IPs, all I had to do is setting the Fixed IP field properly (adding the IPv6 following a coma after the IPv4. Instead of : [ 192.168.1.2 ], do this : [ 192.168.1.2, 2606:6d00:zzzz:zzzz::1:2 ] Thanks for pointing me in the right direction
-
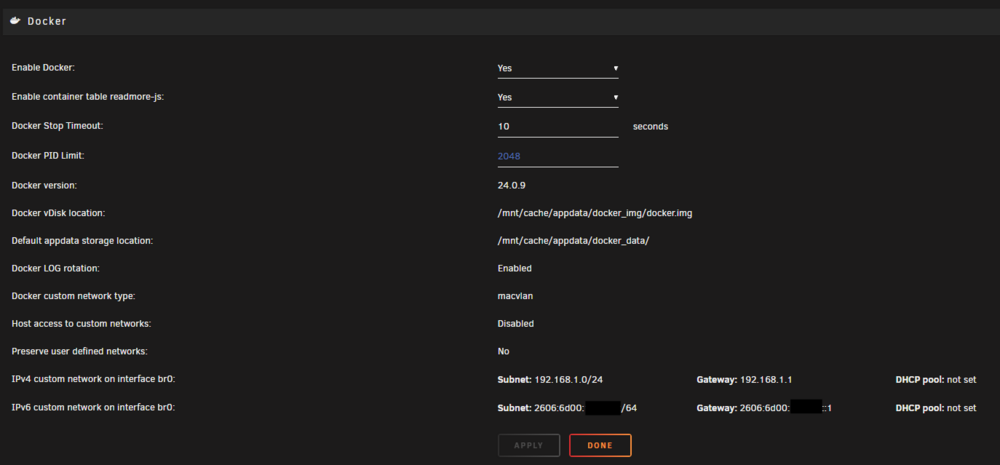
Hi, thanks for taking the time. My UnRaid version is 6.12.13. Here is the requested diagnostics untheran-diagnostics-20241112-2258.zip Before going deep in the routing stuff and systemctl etc ... I just don't see the configured subnet here (and I am not sure where i would specify the desired Static IPv6 IP address) Unraid has a properly configured IPv6 and is pingable, and the subnet is visible in the docker configuration page.
-
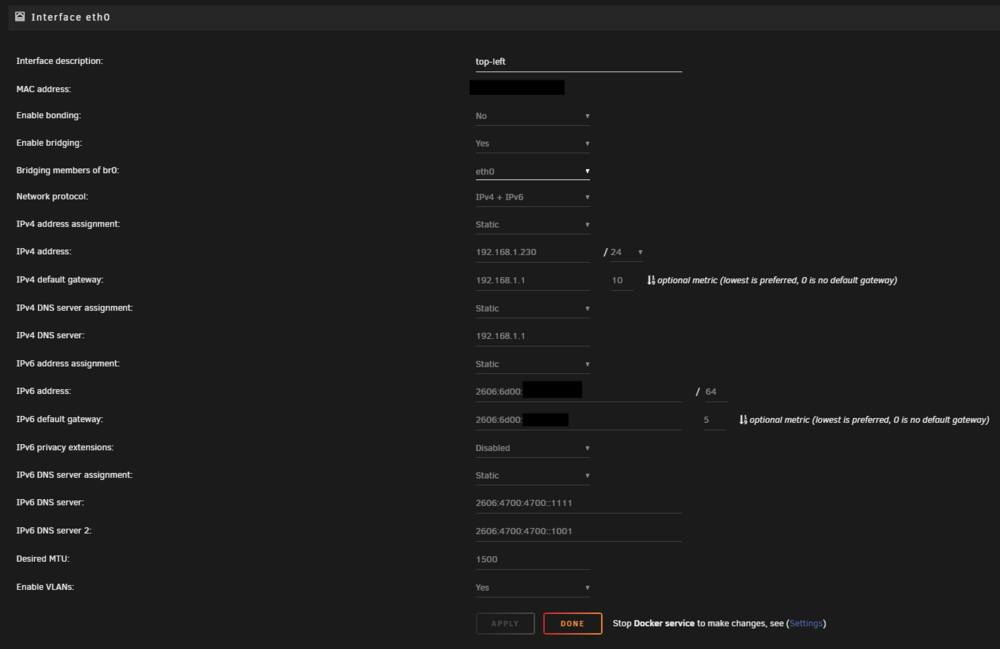
Hi all, I've search far and large for some insight on what is happening to me but I can't find quite the same issue as I have. IPv6 still being in it's infancy I suppose. That and having a few foreign concepts to IPv4. So here is my setup : I managed to obtain a routable IPv6 from my ISP configuring my UDM Pro with a SLAAC Connection and /56 Prefix Delegation. On the wan interface, I got an IP looking like : 2606:6d00:xxxx:xx23:zzzz:zzzz:zzzz:9197 Then, on my LAN interface, I got a subnet looking like : 2606:6d00:xxxx:xx24::/64 In Unraid, I configured my eth0 Interface (Interface description = top-left) with bridging with both network protocol (IPv4+IPv6), Static IPv4 (192.168.1.230/24) and automatic IPv6. It got an IPv6 adress looking like : 2606:6d00:xxxx:xx24:zzzz:zzzz:zzzz:a410 and the link local adresse of my gateway (fe80::yyyy:yyyy:yyyy:4180) as a gateway adress, which is per protocol, all right, even if unsightly. To make sure it was all routable from the internet, I tested an IPv6 only traceroute to 2606:6d00:xxxx:xx24:zzzz:zzzz:zzzz:a410 from an online tool, it got to my router's WAN interface alright. And i can login to my Unraid WebUI using [2606:6d00:xxxx:xx24:zzzz:zzzz:zzzz:a410]. In my docker settings, i got my IPv4 and IPv6 custom networks selected : IPv4 custom network on interface br0: Subnet: 192.168.1.0/24 Gateway: 192.168.1.1 DHCP pool: not set IPv6 custom network on interface br0: Subnet: 2606:6d00:xxxx:xx24::/64 Gateway: fe80::yyyy:yyyy:yyyy:4180 DHCP pool: not set (in case that's important) Docker custom network type: macvlan Host access to custom networks: Disabled Preserve user defined networks: No So now, the meat and potatoes. All my docker containers are configured with the UI (No fancy docker compose) with "Custom : br0 -- top-left" Network Type and fixed "IPv4" addresses. At the right of the "Fixed IP address (optional):" field, i got "Subnet: 192.168.1.0/24". For the life of me, I can't get my IPv6 subnet to show up AND then i'm not sure how I would even specify the IPv6 adress or tell it to use SLAAC to get one. HELP ? :)
-
I just saw that the docker file was not found. Then my appdata share was not there anymore ... But My cache drive is still in my main tab, no errors ... Strying to stop the array to start it back and it takes forever. Forces a reboot. The cache drive wasn'T there anymore .... lsblk, no 2TB Drive ... Went to bios, not there. Shutdown the server, shut off the PSU, reslotted the M.2 drive, And now it'S back ! Very strange, I'll keep an eye on it for the next days.
-
I just saw that the docker file was not found. Then my appdata share was not there anymore ... But My cache drive is still in my main tab, no erreors ... Strying to stop the array to start it back and it takes forever.






