




jbuszkie
Members
-
Joined
-
Last visited
Everything posted by jbuszkie
-
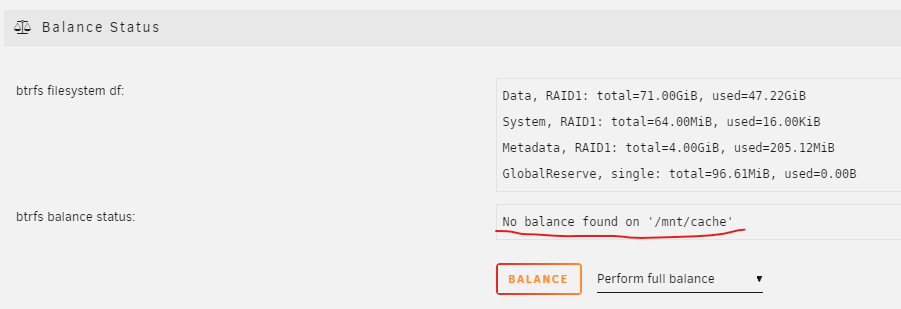
I added a second drive to my cache pool as per the manual. I can't tell if it's automatically in RAID1? I got a warning when I first added the disk Event: Unraid Cache disk message Subject: Warning [TOWER] - pool BTRFS too many profiles (You can ignore this warning when a pool balance operation is in progress) Description: Samsung_SSD_980_1TB_S64ANJ0R676360X (nvme0n1) Importance: warning Do I have to do a manual balance? Am I protected? or do I need to do that full balance? Thanks, Jim

-
So I wanted to upgrade my cache and eventually make it raid 1. I have two nvme slots but if I used the other slot on the MB I'd have to give up two sata connectors. I didn't want to do that. So I bought a PCIe 3.0 x4 card to NVME. My MB has 3.0 PCIe so great I thought. So I plug it into one of my non x16 slots and powered up. I ran the disk speed benchmark and I was unimpressed. Less than 1G/s I ran the onboard existing NVME drive and it was 3x faster! I'm like crap! Are my slots not really 3.0? Was there some limitation in the slot I used? So I pull up the MB manual and it looks like I have 3x x16 slots (of which only one can be x16 other wise 2x 8x) the last x16 is only x4. And I have 3x PCIe 1x slots. Guess what I plugged my 4x card into... Yes a 1x slot!! So I opened up the case again and move the card over to the real x4 slot... And BOOM! 3x-ish. the speed! I have no idea why I though the little 1x slots were 4x??? I'm an idiot sometimes!! 🙂
-
Has anyone moved away from crash plan to something else? I heard versioning is on 90 days now! CP is getting worse and worse about what they back up and now how long they keep revisions! Is there something better/ cheaper out there now?
-
I am not.. I'm more diligent now about closing any web terminals I try to keep the browser on the setting page. I did notice I got this once when I had a grafana webpage auto refreshing. Not sure if that was related at all.. Even if we do have the dash board open all the time, it shouldn't matter??
-
The manual never used to be useful for stuff like this. I've always relied on the knowledge here! It seems like the manual has improved!
-
This is what I did from Squid's post I found It seems to be rebuilding. I'm getting more memory tomorrow so I'll try to replace that sata cable tomorrow or switch the cable to my last free slot and mark that slot as bad! 😞
-
1) I want to rebuild on top of the old disk How do I do that? Unraid has it redballed
-
Ugh... I hate to bring up an old thread... But I'm having issues again. It looks like it's the same slot as above. I just rebooted my server and upon restart drive 8 became red balled! Nov 12 09:46:52 Tower kernel: ata8.00: exception Emask 0x10 SAct 0x0 SErr 0x400000 action 0x6 frozen Nov 12 09:46:52 Tower kernel: ata8.00: irq_stat 0x08000000, interface fatal error Nov 12 09:46:52 Tower kernel: ata8: SError: { Handshk } Nov 12 09:46:52 Tower kernel: ata8.00: failed command: WRITE DMA EXT Nov 12 09:46:52 Tower kernel: ata8.00: cmd 35/00:08:30:14:01/00:01:00:02:00/e0 tag 19 dma 135168 out Nov 12 09:46:52 Tower kernel: res 50/00:00:37:15:01/00:00:00:02:00/e0 Emask 0x10 (ATA bus error) Nov 12 09:46:52 Tower kernel: ata8.00: status: { DRDY } Nov 12 09:46:52 Tower kernel: ata8: hard resetting link Nov 12 09:47:02 Tower kernel: ata8: softreset failed (1st FIS failed) Nov 12 09:47:02 Tower kernel: ata8: hard resetting link Nov 12 09:47:12 Tower kernel: ata8: softreset failed (1st FIS failed) Nov 12 09:47:12 Tower kernel: ata8: hard resetting link Nov 12 09:47:47 Tower kernel: ata8: softreset failed (1st FIS failed) Nov 12 09:47:47 Tower kernel: ata8: limiting SATA link speed to 1.5 Gbps Nov 12 09:47:47 Tower kernel: ata8: hard resetting link Nov 12 09:47:52 Tower kernel: ata8: softreset failed (1st FIS failed) Nov 12 09:47:52 Tower kernel: ata8: reset failed, giving up Nov 12 09:47:52 Tower kernel: ata8.00: disabled Nov 12 09:47:52 Tower kernel: ata8: EH complete Nov 12 09:47:52 Tower kernel: sd 8:0:0:0: [sdg] tag#20 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=0x00 cmd_age=60s Nov 12 09:47:52 Tower kernel: sd 8:0:0:0: [sdg] tag#20 CDB: opcode=0x8a 8a 00 00 00 00 02 00 01 14 30 00 00 01 08 00 00 Nov 12 09:47:52 Tower kernel: blk_update_request: I/O error, dev sdg, sector 8590005296 op 0x1:(WRITE) flags 0x800 phys_seg 33 prio class 0 Nov 12 09:47:52 Tower kernel: md: disk8 write error, sector=8590005232 Nov 12 09:47:52 Tower kernel: md: disk8 write error, sector=8590005240 Nov 12 09:47:52 Tower kernel: md: disk8 write error, sector=8590005248 Now I really believe that the disk is still good. How do I get unraid to try to rebuild onto that disk? As in how do I get it to believe that the disk is not redballed and try to rebuild to that disk? The other drive from the above post that had "errors" in this slot has been behaving fine in a different slot for over a year now. So I really think it's an issue with that slot. grr... I can't remember if I replaced that ata8 cable or not last time. Thanks, Jim
-
When I had this (I believe) I stopped my dockers one by one until it stopped coming.. And for me it was just the first one... Reboot will work as well...
-
Sorry.. But then It's beyond my help.. I'm nowhere near the expert here!
-
I don't remember the details of the problem or the fix... And might be useless.. But might you try a full reboot? Not just restarting the dockers?
-
Did you undo any "fixes" you implemented before the upgrade?
-
@limetech Is there any way you guys can start looking at this? There are more and more folks that are seeing this. For the rest of us... Maybe we should start listing our active dockers to see if one of them is triggering the bug. Maybe there is one common to us that's the cause. If we can give limetech a place to start so to more frequently trigger this condition, it would probably help them.. For me I have Home_assist bunch ESPHome stuckless-sagetv-server-java16 CrashPlanPRO crazifuzzy-opendct Gafana Influxdb MQTT I have no running VMs My last two fails did not have any web terms open at all. I may have had a putty terminal, but I don't think that would cause it? I do have the dashboard open on several machines (randomly powered on) at the same time.. Jim
-
You posted the space available for your cache and others.. But how much space do you have left in /var? Was it full? The first thing I do is delete the syslog.1 to make some space so it can write the log, then I restart nginx. Then I tail the syslog to see if the writes stop. My syslog.1 is usually huge and frees up a lot of space so it can write to the syslog The time before last time, I still had some of those errors in the syslog after the restart.. So I was going to stop my dockers one by one and see if it stopped. And well it did with my first one. Two days ago when then happened to me.. I didn't have to do that. the restart was all I needed...
-
strange that /etc/rc.d/rc.nginx restart didn't fix it. I assume you made room in /var/log for more messages to come through? After the restart did you still have stuff spewing in the log file? I do recall a time where I had to do a restart to fix it completely. Jim
-
No.. I never did...
-
This happened again to me last night. I've been really good about not leaving web terminal windows open. Well.. I didn't have any last night open or for a while. What I did have different was I had set my grafana window to auto refresh every 10s. I wonder if that had anything to do with this problem? Also.. The restart command didn't completely fix it this time. I was still getting a bunch of these... Aug 23 09:09:49 Tower nginx: 2021/08/23 09:09:49 [alert] 25382#25382: worker process 1014 exited on signal 6 Aug 23 09:09:50 Tower nginx: 2021/08/23 09:09:50 [alert] 25382#25382: worker process 1044 exited on signal 6 Aug 23 09:09:51 Tower nginx: 2021/08/23 09:09:51 [alert] 25382#25382: worker process 1202 exited on signal 6 Aug 23 09:09:53 Tower nginx: 2021/08/23 09:09:53 [alert] 25382#25382: worker process 1243 exited on signal 6 Aug 23 09:09:54 Tower nginx: 2021/08/23 09:09:54 [alert] 25382#25382: worker process 1275 exited on signal 6 Aug 23 09:09:55 Tower nginx: 2021/08/23 09:09:55 [alert] 25382#25382: worker process 1311 exited on signal 6 Aug 23 09:09:56 Tower nginx: 2021/08/23 09:09:56 [alert] 25382#25382: worker process 1342 exited on signal 6 Aug 23 09:09:57 Tower nginx: 2021/08/23 09:09:57 [alert] 25382#25382: worker process 1390 exited on signal 6 Aug 23 09:09:58 Tower nginx: 2021/08/23 09:09:58 [alert] 25382#25382: worker process 1424 exited on signal 6 Aug 23 09:09:59 Tower nginx: 2021/08/23 09:09:59 [alert] 25382#25382: worker process 1455 exited on signal 6 I started to kill my dockers and after I stopped the HASSIO group, That message stopped. I restarted the docker group and it hasn't comeback. I really wish we could get to the bottom of this!! FYI.. I'm now on 6.9.2
-
Yeah.. It works fine now! Can't wait for it to be able to send encrypted flash images! I have to upgrade my flash drive though! It's only one Gig.... And maybe 11 years old! Might be time anyway!! lol
-
Yup.. That works fine.

-
Chrome I tried that with the same result. Sure.. I looked in the logs and saw nothing. This is the only spot were I get this. If I change the "Use SSL/TLS" to No.. That change happens just fine.. It's only if I muck with the "My servers" section. Not sure what the update DNS is supposed to do? (generate a new certificate?) But that seems to not come back either. tower-diagnostics-20210810-1401.zip
-
Yeah.. I figured that out. I was able to setup a DNSMASQ setting to allow unraid.net in my tomato config Thanks!
-
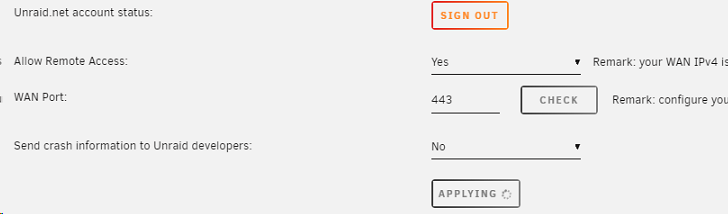
Update.. I do get the spinning circle every time I try to apply when I change something in my servers area. If I disable remote access... I get the spinning circle. But when I go back to something else or refresh, I see the new setting. Same thing if I enable .. I get the spinning applying that never goes away.. But if I refresh, it sticks. However... If I try to change the port, it never sticks. I always see the 443 port. Double however... if I actually try the remote access, I see the new port being used and it works fine even though the webpage settings still says port 443. I do have the flash backup disabled if that has anything to do with this... Bug? Something with my setup?
-
Trying to updated the WAN port on myservers and I just get the spinning circle on "applying" button. If I go to another page and then come back.. I still see the default port of 443. Second question.. Do I have to keep "prevent DNS rebind attacks" unchecked on my router once I provisioned?
-
I had the same thing yesterday.. But when I checked it this AM.. It was now working... So it just took some time for me.. I don't know why.. Maybe someone with more knowledge can explain it or show how to get the fix to work immediately ..
-
I tried the manual fix... But it isn't working. I still get the "not available".. Is there some sort of service I have to restart? preg_match('@Docker-Content-Digest:\s*(.*)@i', $reply, $matches); That's what's in my file...




