
(Small).png.20e01e54adf9a0993af949e43e312763.png)
CorneliousJD
-
Posts
691 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by CorneliousJD
-
Rgr that, I agree it's a VERY strange issue. I download tons of data via Transmission and qBT as well and have never had issue. Only thing TA is doing differently is it downloads to my cache drive first and then it gets procsesed/moved to the array. I have NOT tried changing that config yet to put the /appdata/tubearchivist/downloads folder onto the array directly, but I have other friends using this to have over 10k videos as well already and have not run into this issue. Something very odd is going on, just can't pin down what! I've copied the majority of my two posts into a GitHub issue Here's the link if anyone wants to chime in w/ anything https://github.com/tubearchivist/tubearchivist/issues/402
-
Upon investigating a little more - I did try pinning to just 2 cores, but no luck there, things still get wonky fast. It does seem to be when it's finalizing/processing the video after it's finished downloading -- the download itself goes fine, and then if I monitor the Downloads page it will hit 100% completion then when it goes to processing the box showing the progress disappears and I lose all visibility on what TA is doing. -- this is also when things start to lock up on the whole server, other dockers become inaccessible, web UI and command line for unraid are terribly slow to respond. TA doesn't seem to log TOO much in the docker logs but here's the logs I get... download pending 6a80476e-9d66-4ba5-b673-e55367adc07f: set task id [2023-01-07 19:00:47,564: INFO/MainProcess] Task download_pending[6a80476e-9d66-4ba5-b673-e55367adc07f] received [2023-01-07 19:00:47,574: WARNING/ForkPoolWorker-1] Did not acquire download lock. [2023-01-07 19:00:47,575: INFO/ForkPoolWorker-1] Task download_pending[6a80476e-9d66-4ba5-b673-e55367adc07f] succeeded in 0.006124248000560328s: None download pending 0a949b28-3747-428b-9b05-729d0d8e24df: set task id [2023-01-07 19:00:49,529: INFO/MainProcess] Task download_pending[0a949b28-3747-428b-9b05-729d0d8e24df] received [2023-01-07 19:00:49,534: WARNING/ForkPoolWorker-1] Did not acquire download lock. [2023-01-07 19:00:49,535: INFO/ForkPoolWorker-1] Task download_pending[0a949b28-3747-428b-9b05-729d0d8e24df] succeeded in 0.0038173840002855286s: None {"error":{"root_cause":[{"type":"resource_not_found_exception","reason":"snapshot lifecycle policy or policies [ta_daily] not found, no policies are configured"}],"type":"resource_not_found_exception","reason":"snapshot lifecycle policy or policies [ta_daily] not found, no policies are configured"},"status":404} Filter download view ignored only: False Filter download view ignored only: True Filter download view ignored only: True Filter download view ignored only: False Filter download view ignored only: True zB-BRBmv34k: add single vid to download queue Filter download view ignored only: False Filter download view ignored only: True Filter download view ignored only: False [2023-01-07 19:08:12,452: WARNING/ForkPoolWorker-33] 6q6SXzmcqPY: get metadata from youtube [2023-01-07 19:08:16,634: WARNING/ForkPoolWorker-33] UCXnNibvR_YIdyPs8PZIBoEw: get metadata from es [2023-01-07 19:08:17,008: WARNING/ForkPoolWorker-33] 6q6SXzmcqPY: get ryd stats
-
Hi all, I have been running TubeArchivist now for a few weeks without issue, just subscribed to one channel or and downloading one video here or there. I added a few channels recently with ~500 videos or so ending up in my download queue. Now all of a sudden every time I start the download process after a while my entire unraid server starts to become unresponsive, which is VERY weird considering this is just a container... I have tried limiting the download speed to 5000kbps (I have 500Mbps download connection) but the same thing still happens. It's so bad that I can't even stop the container, unraid just says "server error" when I try and I can't get things like Plex to work, my NPM reverse proxy goes in/out (external monitoring on my public facing site will cite tons of up/down errors over night when the downloads run) and the only fix is to reboot my server because I can't even just stop the Tube Archivist container. My specs are pretty great, so it's not like it's killing the CPU or RAM or anything. I'm just not sure what's going on, or what I can even do to try and fix it. Any advice or suggestions are appreciated! I should also note that while the issues were present and I was able to sometimes get the unraid webUI to load, it didn't show any spiked or pegged usages, CPU was at 20% at the time, RAM wasn't full, nothing seemed to be getting used excessively, but pages would fail to load, containers would fail to stop, etc, only recourse was to reboot from command line or web UI if I got lucky. Specs Processor: Dual Intel® Xeon® CPU E5-2650 v2 @ 2.60GHz RAM: 128GB RAM All docker containers run thru a single NIC interface eth1 - no VALNs on it, no bonding, they're just all using that single NIC (due to some previous issues I had with crashing on macvlan -- a known bug in unraid)
-
(Small).thumb.png.b884b0484e848c502a315fc27b995f59.png)
[SUPPORT] Photoview - CorneliousJD Repo
CorneliousJD replied to CorneliousJD's topic in Docker Containers
You can't add it like that, you need to use a path that's relative to the container itself. A container path of /photos pointing to /mnt/user/Bilder/Fotos/ is what you need Then in the app you'd add your share as /photos -
There are still issues with IPVLAN - I've had different issues on two different unraid servers. I've had to resort back to using macvlan on both servers, and on one server have a dedicated NIC to the docker containers with a static address set. Myself and many others have continued to share findings here
-
I ran into same issues with ipvlan, Ipvlan has been less drastic of issues but more sporadic and IMO, the worse of the two
-
[SUPPORT] Tandoor Recipes - CorneliousJD Repo
CorneliousJD replied to CorneliousJD's topic in Docker Containers
Looks like it's requiring HTTPS now. Try reverse proxying it. -
Ipvlan made more issues for me. Then I went back to macvlan with vlans on docker and it was fine, until I got a new gateway (UDM-SE) and then it started crashing again. I am now on a dedicated NIC for containers with their own IP. Things keep changing... but I'm hopeful that this keeps things stable long term.
-
[SUPPORT] Stash - CorneliousJD Repo
CorneliousJD replied to CorneliousJD's topic in Docker Containers
The appdata should be a share in unraid, this is where all your docker container presistent storage is designed to go, so you might have /mnt/user/appdata/strash /mnt/user/appdata/plex /mnt/user/appdata/sonarr etc, etc, etc. If you want to access it from your Windows system, you will need to toggle that share to be visible on the network, otherwise it will only be accessible from the unraid system. To do this, go into "Shares" in unraid, and click your appdata share. Set Export to on, and choose your desired security as well.
-
[SUPPORT] Tandoor Recipes - CorneliousJD Repo
CorneliousJD replied to CorneliousJD's topic in Docker Containers
Thanks for posting this - I don't use this container anymore so I didn't notice it needed this. Much appreciated. i've updated the XML for the template here: https://github.com/CorneliousJD/Docker-Templates/blob/master/recipes.xml It should push live in a few hours to CA. If there's any outstanding issues after this let me know. -
[6.10.X] - New ipvlan causing network issues after backups.
CorneliousJD commented on CorneliousJD's report in Stable Releases
Forgot I made this post, but this issue still exists in 6.10.3 currently. Is there any acknowledgement of this issue? The thread linked above seems to show some other users with the same problem. -
I changed from a UniFi USG to a UDM now and my old macvlan setup with a VLAN ID of 10 for docker networks to give my pihole a static IP while still using macvlan and avoiding crashes has now stopped working for some reason... and this ipvlan issue still exists. This leaves me in a bad spot now Has this been properly reported as a bug yet?
-
[SUPPORT] JoplinApp - CorneliousJD Repo
CorneliousJD replied to CorneliousJD's topic in Docker Containers
Easiest option here is to just chmod your /mnt/user/appdata/joplinapp to 0777 that way it should have whatever permission it needs. This seems to be a recent issue with unraid's newer versions where permissions get wonky with containers, LOTS of of them need this type of permission change on new installs, which frankly kind of sucks, but this is the easiest solution to quickly fix yourself. -
[SUPPORT] Stash - CorneliousJD Repo
CorneliousJD replied to CorneliousJD's topic in Docker Containers
I'm mobile, but you probably need to chmod the database file to be writable. Try 0777 to see if it allows it to work after that. -
[SUPPORT] Uptime Kuma - CorneliousJD Repo
CorneliousJD replied to CorneliousJD's topic in Docker Containers
This would appear to be unrelated to the container and is a Cloudflare tunnel issue so not something I can really offer any support on. I reverse proxy 3 uptime kuma's with Nginx reverse proxy without any issues at all. Cloudflare is my dynamic DNS provider and I have a letsencrypt wildcard cert on my domain, makes reverse proxy setups dead-simple for me, have never dealt with their tunnels. -
Yes the nextcloud performance isn't great by today's standards, but that's nextcloud as a whole to my understanding, but my setup is VASTLY faster than my old LSIO container setup. I had to add my own variable to the Collabora environment. Variable of aliasgroup1 Value of https://cloud.mydomain:443 This is what gives it an allow list of what URL to allow it to load from, working fine for me w/out any issues in nextcloud after that. I also had to reverse proxy my collabora to collabora.mydomain.com and put that in my settings, otherwise it wasn't working. But it's working now and so does co-authoring/guest authoring, etc.
-
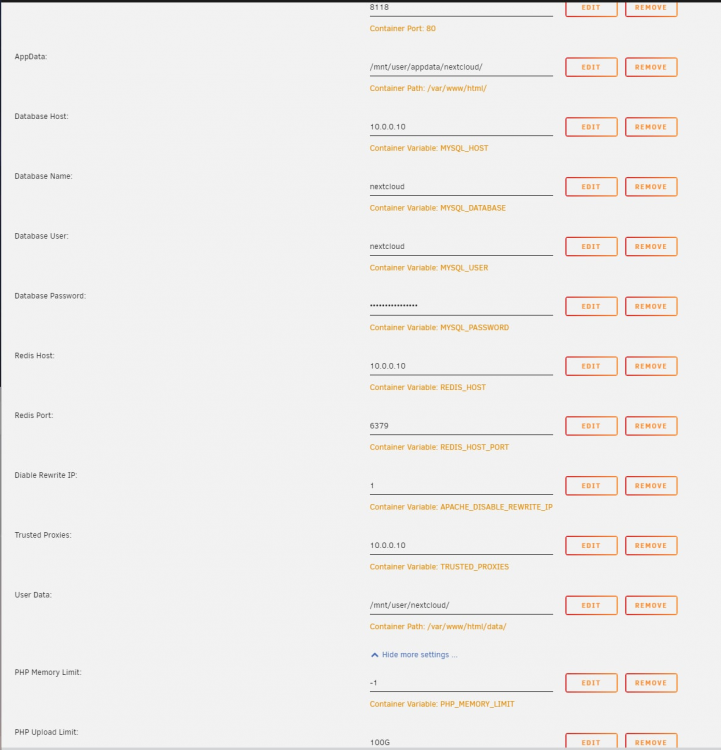
I had started completely over, however I'm sure you could get it to work with your existing data but I had given up on nextcloud for months and started using Filerun instead, but Filerun had it's own problems sadly. This got me motivated to figure out what the heck was going on with Nextcloud again and I started with the official image. My docker config for it is attached, and here's relevant config.php info as well. I even setup Collabra server as a seprate docker and have all that working as well. Passing with A+ security rating and no issues/warnings found in the instance at all, so far so good! It's been a long process to tweak to this point but hopefully this gives you a good starting point! Note that I also setup system cron via unraid userscripts running at */5 * * * * #!/bin/bash docker exec -u www-data Nextcloud php cron.php Sanitized config.php <?php $CONFIG = array ( 'htaccess.RewriteBase' => '/', 'memcache.local' => '\\OC\\Memcache\\APCu', 'apps_paths' => array ( 0 => array ( 'path' => '/var/www/html/apps', 'url' => '/apps', 'writable' => false, ), 1 => array ( 'path' => '/var/www/html/custom_apps', 'url' => '/custom_apps', 'writable' => true, ), ), 'memcache.distributed' => '\\OC\\Memcache\\Redis', 'memcache.locking' => '\\OC\\Memcache\\Redis', 'redis' => array ( 'host' => '10.0.0.10', 'password' => '', 'port' => 6379, ), 'trusted_proxies' => array ( 0 => '10.0.0.10', ), 'instanceid' => 'xxx', 'passwordsalt' => 'xxx', 'secret' => 'xxx', 'trusted_domains' => array ( 0 => '10.0.0.10:8118', 2 => 'cloud.domain.com', ), 'datadirectory' => '/var/www/html/data', 'dbtype' => 'mysql', 'version' => '24.0.3.2', 'overwrite.cli.url' => 'https://cloud.domain.com', 'overwriteprotocol' => 'https', 'trashbin_retention_obligation' => '30, 30', 'default_phone_region' => 'US', 'dbname' => 'nextcloud', 'dbhost' => '10.0.0.10', 'dbport' => '', 'dbtableprefix' => 'oc_', 'mysql.utf8mb4' => true, 'dbuser' => 'nextcloud', 'dbpassword' => 'xxx, 'installed' => true, 'twofactor_enforced' => 'true', 'twofactor_enforced_groups' => array ( 0 => 'admin', ), 'twofactor_enforced_excluded_groups' => array ( ), ***EMAIL CONFIG REDACTED*** 'enable_previews' => true, 'enabledPreviewProviders' => array ( 0 => 'OC\\Preview\\TXT', 1 => 'OC\\Preview\\MarkDown', 2 => 'OC\\Preview\\OpenDocument', 3 => 'OC\\Preview\\PDF', 4 => 'OC\\Preview\\MSOffice2003', 5 => 'OC\\Preview\\MSOfficeDoc', 6 => 'OC\\Preview\\Image', 7 => 'OC\\Preview\\Photoshop', 8 => 'OC\\Preview\\TIFF', 9 => 'OC\\Preview\\SVG', 10 => 'OC\\Preview\\Font', 11 => 'OC\\Preview\\MP3', 12 => 'OC\\Preview\\Movie', 13 => 'OC\\Preview\\MKV', 14 => 'OC\\Preview\\MP4', 15 => 'OC\\Preview\\AVI', ), 'loglevel' => 2, 'maintenance' => false, );
-
Thanks for the info! My appdata was already on my cache, but I ended up fixing nextcloud performance finally (actually just last week!) The long version here is I abandoned the LSIO container and went with the official apache-based container, spun it up on MariaDB w/ Redis caching, no memory limits (defaults to only 512MB), actually running system cron as recommended, etc, and it's night and day difference in speed, it's amazing, plus the container itself updates the nextcloud instance, no more web-based updater.
-
[SUPPORT] Photoview - CorneliousJD Repo
CorneliousJD replied to CorneliousJD's topic in Docker Containers
IIRC there was an open issue on their github and it has to do w/ the format the videos are in, the browsers cannot play them (major licensing issue) and photoview doesn't do trascoding like emby/plex would, so it just can't play them. I fixed my videos working by disabling HEVC format on my phone, so they record in regular mp4's instead of the hevc-codec and they all work since then - just takes up a bit more storage space per video. -
[6.10.X] - New ipvlan causing network issues after backups.
CorneliousJD commented on CorneliousJD's report in Stable Releases
This seems to be the same or a very similar issue, they are experiencing problems much faster than I am, but they seem to have it narrowed down to the same ipvlan issues, and the shim interface where the host access to custom networks being enabled is what causes the problem. Linking here as it may be helpful. -
I assume this is a very similar issue that I am facing, my network is fine for a week of uptime but when running a CA Appdata backup where all containers are stopped then restarted my network goes kaput and everything goes down, I cannot reach github, I cannot ping out from the server itself, etc. Just adding my experience to the mix!
-
This certainly looks like it could be related, for me my network is fine up until I run a CA Appdata backup and then it stops working, very weird. It certainly seems to be ipvlan related for me too!
-
[6.10.X] - New ipvlan causing network issues after backups.
CorneliousJD commented on CorneliousJD's report in Stable Releases
So this only affects this server. All other devices are ok, and it also *only* happens when doing a CA appdata backup. If I turn off the schedule for backups it doesn't happen at all. Also changing back to macvlan prevents the issue. If it's something network related outside of the server, then it makes no sense to me haha -
[6.10.X] - New ipvlan causing network issues after backups.
CorneliousJD commented on CorneliousJD's report in Stable Releases
Hi Squid, it shouldn't, because the only thing that *would* matter is my pihole container, but my server itself is set to use other public DNS servers, plus I run a secondary pihole on a raspberry pi totally external to my server that acts as my backup DNS on my LAN. Since my server itself fails to ping out to 8.8.8.8 when this happens, it would seem to not have anything to do with container order. If I can be of any more help let me know. -
[6.10.X] - New ipvlan causing network issues after backups.
CorneliousJD commented on CorneliousJD's report in Stable Releases
Forgot to attach my diags in last reply, sorry!server-diagnostics-20220703-1714.zip
(Small).thumb.png.b884b0484e848c502a315fc27b995f59.png)





