




hundsboog
Members
-
Joined
-
Last visited
Everything posted by hundsboog
-
If you follow this thread closely, people, me included have severe problems that VMs cannot reach eachother. This problem is not solved yet and if you net many vms, you should not update, Thats all.
-
Yes, and like we wrote, its buggy (network stack)
-
Same here, network stack is somehow broken, my VMs cant talk to eachother like other users mention it. Downgraded to .11 again.
-
Nobody know, why suddenly the deprecated Letsencrypt got a new update? Is it re-maintened?
-
Hey folks! Must confess, I've never switched to swag and let the deprecated letsencrypt docker just run (i know i know...). Today, I got an available update for it... why that? Can I safely run it? I had absolutely no issues the last time, so... Is it safe? Thanks!
-
Thank you guys, I appreciate you help! Never mind, I just thought, maybe it is a known issue and there is a simple and short trick to fix it. I will try to sort it out and let you know if I have success! I wish you a nice and happy pre-Christmas time, stay all healthy and well! - hundsboog
-
Hi guys, I experience a pretty strange increasing of the docker image size. I got a warning that my docker.img is taking up too much space, so i locked at all dockers I have and SearXNG eat up like about 8,5 GB. Is there any cache I could clean? Regards!
-
Yes, would need also this feature so badly!
-
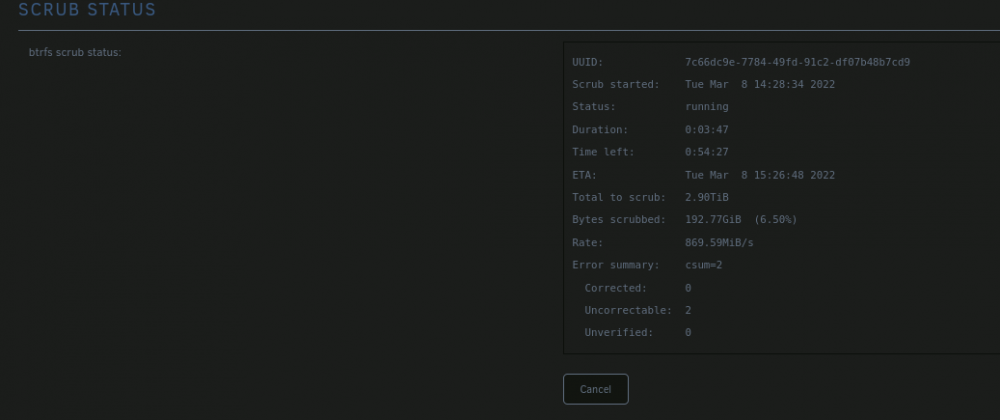
Ok, I deleted those two preview files and started scrub again, which was doing its thing. The error belonging to those were completely gone. This is now the final result, where I need still some assistance: Mar 8 16:41:31 Tower ool www[877]: /usr/local/emhttp/plugins/dynamix/scripts/btrfs_scrub 'start' '/mnt/cache' '' Mar 8 16:41:31 Tower kernel: BTRFS info (device sdi1): scrub: started on devid 1 Mar 8 16:41:31 Tower kernel: BTRFS info (device sdi1): scrub: started on devid 2 Mar 8 16:42:09 Tower kernel: BTRFS warning (device sdi1): checksum error at logical 35017768960 on dev /dev/sdh1, physical 18857115648: metadata leaf (level 0) in tree 5 Mar 8 16:42:09 Tower kernel: BTRFS warning (device sdi1): checksum error at logical 35017768960 on dev /dev/sdh1, physical 18857115648: metadata leaf (level 0) in tree 5 Mar 8 16:42:09 Tower kernel: BTRFS error (device sdi1): bdev /dev/sdh1 errs: wr 0, rd 0, flush 0, corrupt 3, gen 0 Mar 8 16:42:09 Tower kernel: BTRFS error (device sdi1): unable to fixup (regular) error at logical 35017768960 on dev /dev/sdh1 Mar 8 16:42:09 Tower kernel: BTRFS warning (device sdi1): checksum error at logical 35017768960 on dev /dev/sdi1, physical 18878087168: metadata leaf (level 0) in tree 5 Mar 8 16:42:09 Tower kernel: BTRFS warning (device sdi1): checksum error at logical 35017768960 on dev /dev/sdi1, physical 18878087168: metadata leaf (level 0) in tree 5 Mar 8 16:42:09 Tower kernel: BTRFS error (device sdi1): bdev /dev/sdi1 errs: wr 0, rd 0, flush 0, corrupt 3, gen 0 Mar 8 16:42:09 Tower kernel: BTRFS error (device sdi1): unable to fixup (regular) error at logical 35017768960 on dev /dev/sdi1
-
So this should be the culprits? Mar 8 14:54:28 Tower kernel: BTRFS warning (device sdi1): checksum error at logical 908941897728 on dev /dev/sdi1, physical 752108482560, root 5, inode 6129850, offset 3596288, length 4096, links 1 (path: Nextcloud/appdata_ocies0pc9lnb/preview/b/b/1/7/d/1/6/109600/3398-3398-max.png) Mar 8 14:54:28 Tower kernel: BTRFS error (device sdi1): bdev /dev/sdi1 errs: wr 0, rd 0, flush 0, corrupt 2, gen 0 Mar 8 14:54:28 Tower kernel: BTRFS error (device sdi1): unable to fixup (regular) error at logical 908941897728 on dev /dev/sdi1 Mar 8 14:54:28 Tower kernel: BTRFS warning (device sdi1): checksum error at logical 908941897728 on dev /dev/sdh1, physical 752087511040, root 5, inode 6129850, offset 3596288, length 4096, links 1 (path: Nextcloud/appdata_ocies0pc9lnb/preview/b/b/1/7/d/1/6/109600/3398-3398-max.png) Mar 8 14:54:28 Tower kernel: BTRFS error (device sdi1): bdev /dev/sdh1 errs: wr 0, rd 0, flush 0, corrupt 2, gen 0 Mar 8 14:54:28 Tower kernel: BTRFS error (device sdi1): unable to fixup (regular) error at logical 908941897728 on dev /dev/sdh1 @JorgeB thank you very much! It was a very awesome lesson to me and I learned a lot! Hopefully this thread will give other people also advice how to fix BTFRS errors!! Thank you so much! And I will report back, if the server runs now stabel with the config I did in the BIOS. Finger crossed, this was the the screw I had to fix to get the Mofo stable.... 😄
-
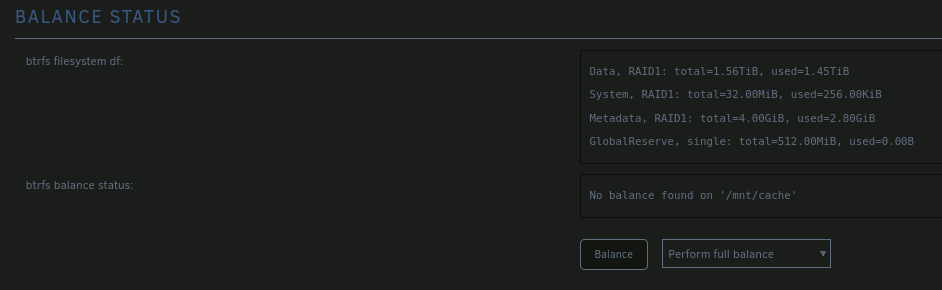
@JorgeB, the page you linked was my source for my light night work yesterday. I have some really sporadically lockups, maybe once a month. This is caused around the Threadripper/RAM/C6 State problem. I really couldnt figure out a pattern when it crashes but its always around little more than idle. Yesterday I did another approach to get rid of it. So, what I did was to bring the RAM manually back to the Mhz your table supposed, set the power to "typical" and *enabled" the deep sleep feature which could possibly lead to those crashes. I found this comment on reddit: The C6 states disabling should than be not necessary. By now, the server runs like expected but Im syslogging to the array anyways, because the lockup can happen anytime withing that month... So, I think like you supposed this is caused by some RAM error. All RAM stick are working, I memtested it without any errors. Is there a way to get rid of the BTFRS errors then? Move all data to the array, erase it and put it back? Do I have to do it, although it is a cache pool with two disks in Raid1? Would the corrupted data also be copied or is there a way to figure out which file is broke to delete it in advance? Thank you for you patience!!
-
Hey folks, recently I got an error on one device of my cache pool (2x2TB SSD). Mar 8 14:29:12 Tower kernel: BTRFS warning (device sdi1): checksum error at logical 35017768960 on dev /dev/sdi1, physical 18878087168: metadata leaf (level 0) in tree 5 So i startet a scrub and checked the box to correct errors when possible. The output in the logs is this: Mar 8 14:29:12 Tower kernel: BTRFS error (device sdi1): bdev /dev/sdi1 errs: wr 0, rd 0, flush 0, corrupt 1, gen 0 Mar 8 14:29:13 Tower kernel: BTRFS error (device sdi1): unable to fixup (regular) error at logical 35017768960 on dev /dev/sdh1 Mar 8 14:29:13 Tower kernel: BTRFS error (device sdi1): unable to fixup (regular) error at logical 35017768960 on dev /dev/sdi1 So, since I have a cache pool of two identical devices, why do I have a uncorrectable error? Is there any way to solve this? Thank you in advance! P.s. Dont know if its from importancy, but I deleted orphaned docker images the day before i noticed it... And second, since I have a Raid1 Cache Pool with two devices, why cant the error not repaired?
-
Hi Frank, Thank you so much. I searched the forum a bit and found a thread about call trace errors which lead to a kernel panic. Basically I upgraded to the new release candidate and so far, everything is ok. I will test it out and will write back. I looked at the logs and there is now another error, but some people upgraded like me, experienced the same. I will keep recording the syslogs and save the next time the server crashes the complete log, like you advised. But so far, everythings up and running! Have a great day Nov 1 19:08:00 Tower kernel: docker0: port 10(veth0351d9e) entered disabled state Nov 1 19:08:00 Tower kernel: veth29e74e4: renamed from eth0 Nov 1 19:08:00 Tower avahi-daemon[7541]: Interface veth0351d9e.IPv6 no longer relevant for mDNS. Nov 1 19:08:00 Tower avahi-daemon[7541]: Leaving mDNS multicast group on interface veth0351d9e.IPv6 with address fe80::e063:a1ff:fe3c:d18b. Nov 1 19:08:00 Tower kernel: docker0: port 10(veth0351d9e) entered disabled state Nov 1 19:08:00 Tower kernel: device veth0351d9e left promiscuous mode Nov 1 19:08:00 Tower kernel: docker0: port 10(veth0351d9e) entered disabled state Nov 1 19:08:00 Tower avahi-daemon[7541]: Withdrawing address record for fe80::e063:a1ff:fe3c:d18b on veth0351d9e. Nov 1 19:08:00 Tower wsdd2[7516]: error: wsdd-mcast-v6: wsd_send_soap_msg: send: Cannot assign requested address Nov 1 19:08:02 Tower kernel: docker0: port 10(veth51bbbe0) entered blocking state Nov 1 19:08:02 Tower kernel: docker0: port 10(veth51bbbe0) entered disabled state Nov 1 19:08:02 Tower kernel: device veth51bbbe0 entered promiscuous mode Nov 1 19:08:02 Tower kernel: docker0: port 10(veth51bbbe0) entered blocking state Nov 1 19:08:02 Tower kernel: docker0: port 10(veth51bbbe0) entered forwarding state Nov 1 19:08:02 Tower kernel: docker0: port 10(veth51bbbe0) entered disabled state Nov 1 19:08:05 Tower kernel: eth0: renamed from vethf3c118f Nov 1 19:08:05 Tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth51bbbe0: link becomes ready Nov 1 19:08:05 Tower kernel: docker0: port 10(veth51bbbe0) entered blocking state Nov 1 19:08:05 Tower kernel: docker0: port 10(veth51bbbe0) entered forwarding state Nov 1 19:08:06 Tower avahi-daemon[7541]: Joining mDNS multicast group on interface veth51bbbe0.IPv6 with address fe80::3485:ffff:feaf:3a45. Nov 1 19:08:06 Tower avahi-daemon[7541]: New relevant interface veth51bbbe0.IPv6 for mDNS. Nov 1 19:08:06 Tower avahi-daemon[7541]: Registering new address record for fe80::3485:ffff:feaf:3a45 on veth51bbbe0.*. Nov 1 19:08:06 Tower wsdd2[7516]: error: wsdd-mcast-v6: wsd_send_soap_msg: send: Cannot assign requested address
-
Same error here. Is it something we can safely ignore? What impact can this have? Nov 1 19:08:00 Tower kernel: docker0: port 10(veth0351d9e) entered disabled state Nov 1 19:08:00 Tower kernel: veth29e74e4: renamed from eth0 Nov 1 19:08:00 Tower avahi-daemon[7541]: Interface veth0351d9e.IPv6 no longer relevant for mDNS. Nov 1 19:08:00 Tower avahi-daemon[7541]: Leaving mDNS multicast group on interface veth0351d9e.IPv6 with address fe80::e063:a1ff:fe3c:d18b. Nov 1 19:08:00 Tower kernel: docker0: port 10(veth0351d9e) entered disabled state Nov 1 19:08:00 Tower kernel: device veth0351d9e left promiscuous mode Nov 1 19:08:00 Tower kernel: docker0: port 10(veth0351d9e) entered disabled state Nov 1 19:08:00 Tower avahi-daemon[7541]: Withdrawing address record for fe80::e063:a1ff:fe3c:d18b on veth0351d9e. Nov 1 19:08:00 Tower wsdd2[7516]: error: wsdd-mcast-v6: wsd_send_soap_msg: send: Cannot assign requested address Nov 1 19:08:02 Tower kernel: docker0: port 10(veth51bbbe0) entered blocking state Nov 1 19:08:02 Tower kernel: docker0: port 10(veth51bbbe0) entered disabled state Nov 1 19:08:02 Tower kernel: device veth51bbbe0 entered promiscuous mode Nov 1 19:08:02 Tower kernel: docker0: port 10(veth51bbbe0) entered blocking state Nov 1 19:08:02 Tower kernel: docker0: port 10(veth51bbbe0) entered forwarding state Nov 1 19:08:02 Tower kernel: docker0: port 10(veth51bbbe0) entered disabled state Nov 1 19:08:05 Tower kernel: eth0: renamed from vethf3c118f Nov 1 19:08:05 Tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth51bbbe0: link becomes ready Nov 1 19:08:05 Tower kernel: docker0: port 10(veth51bbbe0) entered blocking state Nov 1 19:08:05 Tower kernel: docker0: port 10(veth51bbbe0) entered forwarding state Nov 1 19:08:06 Tower avahi-daemon[7541]: Joining mDNS multicast group on interface veth51bbbe0.IPv6 with address fe80::3485:ffff:feaf:3a45. Nov 1 19:08:06 Tower avahi-daemon[7541]: New relevant interface veth51bbbe0.IPv6 for mDNS. Nov 1 19:08:06 Tower avahi-daemon[7541]: Registering new address record for fe80::3485:ffff:feaf:3a45 on veth51bbbe0.*. Nov 1 19:08:06 Tower wsdd2[7516]: error: wsdd-mcast-v6: wsd_send_soap_msg: send: Cannot assign requested address
-
Hello friendos, I deal a certain time with really strange shutdowns. They appeared like half a year ago and I really do hard to find the reason for it. here is the syslog, which my raspberry pi syslog server had saved shortly before the last crash: Oct 28 22:40:01 laborpi CRON[14203]: (root) CMD ( PATH="$PATH:/usr/sbin:/usr/local/bin/" pihole updatechecker local) Oct 28 22:45:36 Tower kernel: general protection fault, probably for non-canonical address 0xffff11207e99fe60: 0000 [#1] SMP NOPTI Oct 28 22:45:36 Tower kernel: CPU: 35 PID: 0 Comm: swapper/35 Tainted: G S W 5.10.28-Unraid #1 Oct 28 22:45:36 Tower kernel: Hardware name: To Be Filled By O.E.M. To Be Filled By O.E.M./X399 Taichi, BIOS P3.90 12/04/2019 Oct 28 22:45:36 Tower kernel: RIP: 0010:set_work_data+0x5/0x10 Oct 28 22:45:36 Tower kernel: Code: d0 21 c8 81 e6 c8 01 00 00 89 47 60 74 16 81 e1 c8 01 00 00 74 0e a9 c8 01 00 00 75 07 f0 ff 82 00 03 00 00 c3 48 8b 07 a8 01 <65> 02 0f 0b 48 09 d6 48 89 37 c3 53 89 fb 48 c7 c7 c0 58 03 82 e8 Oct 28 22:45:36 Tower kernel: RSP: 0018:ffffc90006f08eb8 EFLAGS: 00010002 Oct 28 22:45:36 Tower kernel: RAX: 00000000000008c1 RBX: ffff88903f4e8000 RCX: 0000000000000000 Oct 28 22:45:36 Tower kernel: RDX: 0000000000000005 RSI: ffff88903f4e8000 RDI: ffff88903f4dfe60 Oct 28 22:45:36 Tower kernel: RBP: ffff888100064400 R08: ffff88903f4e8000 R09: ffff88903f4e1d20 Oct 28 22:45:36 Tower kernel: R10: ffff88903f4e1d00 R11: ffff8881004004e8 R12: 0000000000000023 Oct 28 22:45:36 Tower kernel: R13: ffff88903f4dfe60 R14: 0000000000000023 R15: ffff88903f4e1d00 Oct 28 22:45:36 Tower kernel: FS: 0000000000000000(0000) GS:ffff88903f4c0000(0000) knlGS:0000000000000000 Oct 28 22:45:36 Tower kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Oct 28 22:45:36 Tower kernel: CR2: 0000006fcf6c725a CR3: 000000010936c000 CR4: 00000000003506e0 Oct 28 22:45:36 Tower kernel: Call Trace: Oct 28 22:45:36 Tower kernel: <IRQ> Oct 28 22:45:36 Tower kernel: insert_work+0x19/0x53 Oct 28 22:45:36 Tower kernel: __queue_work+0x235/0x24c Oct 28 22:45:36 Tower kernel: call_timer_fn.isra.0+0x12/0x6f Oct 28 22:45:36 Tower kernel: ? queue_work_node+0xbe/0xbe Oct 28 22:45:36 Tower kernel: __run_timers.part.0+0x120/0x185 Oct 28 22:45:36 Tower kernel: ? update_process_times+0x68/0x6e Oct 28 22:45:36 Tower kernel: ? hrtimer_forward+0x73/0x7b Oct 28 22:45:36 Tower kernel: ? tick_sched_timer+0x5a/0x64 Oct 28 22:45:36 Tower kernel: ? timerqueue_add+0x62/0x68 Oct 28 22:45:36 Tower kernel: ? timekeeping_get_ns+0x19/0x2f Oct 28 22:45:36 Tower kernel: __do_softirq+0xc4/0x1c2 Oct 28 22:45:36 Tower kernel: asm_call_irq_on_stack+0x12/0x20 Oct 28 22:45:36 Tower kernel: </IRQ> Oct 28 22:45:36 Tower kernel: do_softirq_own_stack+0x2c/0x39 Oct 28 22:45:36 Tower kernel: __irq_exit_rcu+0x45/0x80 Oct 28 22:45:36 Tower kernel: sysvec_apic_timer_interrupt+0x87/0x95 Oct 28 22:45:36 Tower kernel: asm_sysvec_apic_timer_interrupt+0x12/0x20 Oct 28 22:45:36 Tower kernel: RIP: 0010:arch_local_irq_enable+0x7/0x8 Oct 28 22:45:36 Tower kernel: Code: 00 48 83 c4 28 4c 89 e0 5b 5d 41 5c 41 5d 41 5e 41 5f c3 9c 58 0f 1f 44 00 00 c3 fa 66 0f 1f 44 00 00 c3 fb 66 0f 1f 44 00 00 <c3> 55 8b af 28 04 00 00 b8 01 00 00 00 45 31 c9 53 45 31 d2 39 c5 Oct 28 22:45:36 Tower kernel: RSP: 0018:ffffc90006613ea0 EFLAGS: 00000246 Oct 28 22:45:36 Tower kernel: RAX: ffff88903f4e2380 RBX: 0000000000000001 RCX: 000000000000001f Oct 28 22:45:36 Tower kernel: RDX: 0000000000000000 RSI: 00000000238e364d RDI: 0000000000000000 Oct 28 22:45:36 Tower kernel: RBP: ffff8890a33ea400 R08: 000342ed73233146 R09: 000000000000025c Oct 28 22:45:36 Tower kernel: R10: 000000000000026b R11: 071c71c71c71c71c R12: 000342ed73233146 Oct 28 22:45:36 Tower kernel: R13: ffffffff820c8c40 R14: 0000000000000001 R15: 0000000000000000 Oct 28 22:45:36 Tower kernel: cpuidle_enter_state+0x101/0x1c4 Oct 28 22:45:36 Tower kernel: cpuidle_enter+0x25/0x31 Oct 28 22:45:36 Tower kernel: do_idle+0x1a6/0x214 Oct 28 22:45:36 Tower kernel: cpu_startup_entry+0x18/0x1a Oct 28 22:45:36 Tower kernel: secondary_startup_64_no_verify+0xb0/0xbb Oct 28 22:45:36 Tower kernel: Modules linked in: macvlan xt_mark xt_CHECKSUM ipt_REJECT nf_reject_ipv4 ip6table_mangle ip6table_nat iptable_mangle nf_tables vhost_net tun vhost vhost_iotlb tap veth xt_nat xt_tcpudp xt_conntrack nf_conntrack_netlink nfnetlink xt_addrtype $ Could somebody help me dig into the right direction? Im not an expert in analyze error logs. It also happens always in the night without any certain load.... Things I did so far: Disabled the SSD trimming feature (I have a 2TB two Disk SSD Cache on btrfs) Checked the memory with memtest Disabled some dockers known to be not reliable. Any help is highly appreciated! Thanks!! hundsboog
-
Besides the upcoming security issues (if there are any): Is it by security means accaptable just to stay on that working version the next time till the docker gets a new maintainer?
-
... or you just setup another docker container and use two additional connections But is it true that it is really depricated? I really cant believe it! I mean this container has a huge community, can somebody clearify this?
-
Hey hey, meinst Du Du kannst mir nochmal erklären, wie du das eingestellt hast? Docker ist noch ein wenig neu für mich und würde gerne es Dir in der Hinsicht nachmachen, dass er beim neustart tessaract sofort auf Vorhandenensein prüft oder eben installiert! Lieben Dank 🙂
-
Hello folks, like the title said, I need some help with my UnRaid Box. Once in a while my server crashes and to be honest, I really don't know why. So I setup a syslog server on my second UnRaid machine to bring some light in that situation. If someone could help me, whats causing this hickup would be fine. Thanks alot and enjoy your sunday! May 2 02:26:48 Tower emhttpd: read SMART /dev/sdj May 2 02:58:12 Tower emhttpd: spinning down /dev/sdj May 2 03:00:18 Tower emhttpd: read SMART /dev/sdj May 2 03:32:45 Tower kernel: kernel tried to execute NX-protected page - exploit attempt? (uid: 0) May 2 03:32:45 Tower kernel: BUG: unable to handle page fault for address: ffffffff81a01640 May 2 03:32:45 Tower kernel: #PF: supervisor instruction fetch in kernel mode May 2 03:32:45 Tower kernel: #PF: error_code(0x0011) - permissions violation May 2 03:32:45 Tower kernel: PGD 200e067 P4D 200e067 PUD 200f063 PMD 10a2a75063 PTE 8000000001a01163 May 2 03:32:45 Tower kernel: Oops: 0011 [#1] SMP NOPTI May 2 03:32:45 Tower kernel: CPU: 9 PID: 53622 Comm: CPU 0/KVM Not tainted 5.10.28-Unraid #1 May 2 03:32:45 Tower kernel: Hardware name: To Be Filled By O.E.M. To Be Filled By O.E.M./X399 Taichi, BIOS P3.90 12/04/2019 May 2 03:32:45 Tower kernel: RIP: 0010:0xffffffff81a01640 May 2 03:32:45 Tower kernel: Code: 6f 00 67 00 00 00 00 00 00 00 58 00 00 00 02 00 00 00 b6 40 00 00 00 00 32 01 89 0b 03 00 00 00 0b 00 20 a6 d5 1d 02 00 00 00 <68> 4d e1 70 89 31 d7 01 01 20 00 00 00 00 00 00 00 00 00 00 20 00 May 2 03:32:45 Tower kernel: RSP: 0018:ffffc90006a80ea8 EFLAGS: 00010202 May 2 03:32:45 Tower kernel: RAX: ffffffff81436103 RBX: ffff889084f0a008 RCX: 0000000000000240 May 2 03:32:45 Tower kernel: RDX: ffffc90006a80f10 RSI: ffffffff814382b9 RDI: ffff889084f0a008 May 2 03:32:45 Tower kernel: RBP: ffff88a03e45cb40 R08: ffff889084f0a728 R09: 0000000000000004 May 2 03:32:45 Tower kernel: R10: 0000000000000214 R11: ffff88a03e462400 R12: 00000000ffffffff May 2 03:32:45 Tower kernel: R13: ffff889084f0a008 R14: ffffc90006a80f10 R15: ffffffff820060c8 May 2 03:32:45 Tower kernel: FS: 0000000000386000(0053) GS:ffff88a03e440000(002b) knlGS:0000000000384000 May 2 03:32:45 Tower kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 May 2 03:32:45 Tower kernel: CR2: ffffffff81a01640 CR3: 0000001afcf3c000 CR4: 00000000003506e0 May 2 03:32:45 Tower kernel: Call Trace: May 2 03:32:45 Tower kernel: <IRQ> May 2 03:32:45 Tower kernel: ? iova_domain_flush+0x15/0x1c May 2 03:32:45 Tower kernel: ? fq_flush_timeout+0x27/0x8b May 2 03:32:45 Tower kernel: ? call_timer_fn.isra.0+0x12/0x6f May 2 03:32:45 Tower kernel: ? fq_ring_free+0x92/0x92 May 2 03:32:45 Tower kernel: ? __run_timers.part.0+0x144/0x185 May 2 03:32:45 Tower kernel: ? update_process_times+0x68/0x6e May 2 03:32:45 Tower kernel: ? hrtimer_forward+0x73/0x7b May 2 03:32:45 Tower kernel: ? tick_sched_timer+0x5a/0x64 May 2 03:32:45 Tower kernel: ? timerqueue_add+0x62/0x68 May 2 03:32:45 Tower kernel: ? run_timer_softirq+0x21/0x43 May 2 03:32:45 Tower kernel: ? __do_softirq+0xc4/0x1c2 May 2 03:32:45 Tower kernel: ? asm_call_irq_on_stack+0x12/0x20 May 2 03:32:45 Tower kernel: </IRQ> May 2 03:32:45 Tower kernel: ? do_softirq_own_stack+0x2c/0x39 May 2 03:32:45 Tower kernel: ? __irq_exit_rcu+0x45/0x80 May 2 03:32:45 Tower kernel: ? sysvec_apic_timer_interrupt+0x87/0x95 May 2 03:32:45 Tower kernel: ? asm_sysvec_apic_timer_interrupt+0x12/0x20 May 2 03:32:45 Tower kernel: ? kvm_vcpu_running+0x7/0x38 [kvm] May 2 03:32:45 Tower kernel: ? apic_has_pending_timer+0xf/0x2c [kvm] May 2 03:32:45 Tower kernel: ? kvm_arch_vcpu_ioctl_run+0x21b/0x1363 [kvm] May 2 03:32:45 Tower kernel: ? __bpf_prog_run32+0x35/0x51 May 2 03:32:45 Tower kernel: ? __wake_up_common+0xa7/0x12f May 2 03:32:45 Tower kernel: ? kvm_vcpu_ioctl+0x176/0x4ac [kvm] May 2 03:32:45 Tower kernel: ? vfs_ioctl+0x19/0x26 May 2 03:32:45 Tower kernel: ? __do_sys_ioctl+0x51/0x74 May 2 03:32:45 Tower kernel: ? do_syscall_64+0x5d/0x6a May 2 03:32:45 Tower kernel: ? entry_SYSCALL_64_after_hwframe+0x44/0xa9 May 2 03:32:45 Tower kernel: Modules linked in: xt_connmark xt_comment iptable_raw xt_mark xt_CHECKSUM ipt_REJECT nf_reject_ipv4 ip6table_mangle ip6table_nat iptable_mangle nf_tables vhost_net tun vhost vhost_iotlb tap veth xt_nat xt_tcpudp xt_conntrack nf_conntrack_netlink nfnetlink xt_addrtype br_netfilter xfs nfsd lockd grace sunrpc md_mod nct6775 hwmon_vid iptable_nat xt_MASQUERADE nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 wireguard curve25519_x86_64 libcurve25519_generic libchacha20poly1305 chacha_x86_64 poly1305_x86_64 ip6_udp_tunnel udp_tunnel libblake2s blake2s_x86_64 libblake2s_generic libchacha ip6table_filter ip6_tables iptable_filter ip_tables x_tables bonding igb i2c_algo_bit edac_mce_amd kvm_amd kvm btusb btrtl btbcm btintel bluetooth crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel aesni_intel crypto_simd ecdh_generic wmi_bmof mxm_wmi i2c_piix4 ecc cryptd i2c_core ahci glue_helper ccp rapl wmi k10temp libahci button acpi_cpufreq [last unloaded: i2c_algo_bit] May 2 03:32:45 Tower kernel: CR2: ffffffff81a01640 Regards, hundsboog
-
Sure! I only thought, it common sense, that only some dedicated versions work. I did a fresh re-install, also with prior deleting the docker template and pulled a complete new one. This is what the docker log shows: [2021-04-23 08:29:48,113: DEBUG/ForkPoolWorker-2] document_log username=admin doc_id=694 page_num=18 text_len=351 [2021-04-23 08:29:48,114: DEBUG/ForkPoolWorker-2] document_log username=admin doc_id=694 page_num=19 text_len=130 [2021-04-23 08:29:48,115: DEBUG/ForkPoolWorker-2] document_log username=admin doc_id=694 page_num=20 text_len=239 [2021-04-23 08:29:48,118: DEBUG/ForkPoolWorker-2] Missing page txt /data/media/results/user_1/document_756/v2/pages/page_1.txt. [2021-04-23 08:29:48,120: DEBUG/ForkPoolWorker-2] Missing page txt /data/media/results/user_1/document_757/pages/page_1.txt. [2021-04-23 08:29:48,123: INFO/ForkPoolWorker-2] Task papermerge.core.management.commands.worker.txt2db[17445f37-9715-41ac-8f92-5b5bbe237bdc] succeeded in 1.6826063899789006s: None Basically it was the same with docker mods mentioned in the posts before, no effort in doing OCR'ring and use my automates like it did before. When you tell me what more details you need, let me know, I really appreciate your time and help! Update: New release update and it works like expected!!! Perfect and back in the Game! 😄
-
No updates yet? Its not working anymore... Did a complete reinstall, but unfortunately when it starts OCR'ing, nothing further happens. 😕 I really liked it
-
Bump this up! This feature is highly important for some guys (like me!) who want to get notified early in the morning if all servers at work are up and running to prevent (mostly female 😄 ) staff to cry in the phone that PC's arent working! Thanks 🙂
-
Hi and thank you for your fast answer, @bonienl Update: the german open source dyndns provider "ddnss.de" is down. Well that happened in the last 8 year only one time and felt accidentally together when i updated the plug in. My bad, I just checked their homepage where nothing is claiming about that their service is down so I checked by pinging in the console of my linux machine my dyndns adress.
-
I updated today to the version 2021.04.12 and I dont get any handshake at all with all my peers i created. Anybody experiences the same problem as me? Update: I asked a friend of mine and he has the same problem. Must be some kind of bug. Is there a way to get back to the previous version?
-
Bei mir leider das gleiche, nach dem Update geht leider gar nicht mehr. Nach Hochladen eines pdf vrebleibt dieses einfach in der inbox... File "./manage.py", line 24, in <module> execute_from_command_line(sys.argv) File "/usr/local/lib/python3.8/dist-packages/django/core/management/__init__.py", line 401, in execute_from_command_line utility.execute() File "/usr/local/lib/python3.8/dist-packages/django/core/management/__init__.py", line 395, in execute self.fetch_command(subcommand).run_from_argv(self.argv) File "/usr/local/lib/python3.8/dist-packages/django/core/management/base.py", line 330, in run_from_argv self.execute(*args, **cmd_options) File "/usr/local/lib/python3.8/dist-packages/django/core/management/base.py", line 368, in execute self.check() File "/usr/local/lib/python3.8/dist-packages/django/core/management/base.py", line 392, in check all_issues = checks.run_checks( File "/usr/local/lib/python3.8/dist-packages/django/core/checks/registry.py", line 70, in run_checks new_errors = check(app_configs=app_configs, databases=databases) File "/usr/local/lib/python3.8/dist-packages/papermerge/core/checks.py", line 113, in binaries_check subprocess.run( File "/usr/lib/python3.8/subprocess.py", line 489, in run with Popen(*popenargs, **kwargs) as process: File "/usr/lib/python3.8/subprocess.py", line 854, in __init__ self._execute_child(args, executable, preexec_fn, close_fds, File "/usr/lib/python3.8/subprocess.py", line 1702, in _execute_child raise child_exception_type(errno_num, err_msg, err_filename) PermissionError: [Errno 13] Permission denied: '/root/.local/bin/stapler' [uwsgi-daemons] throttling "/usr/bin/python3 ./manage.py worker" for 300 seconds Er beklagt sich über einen permission error? Weiß jemand, was da los ist? Frohe Osterfeiertage!!

