




Reflexion
Members
-
Joined
-
Last visited
-
Wie gesagt, mir ist die Variante durchaus bekannt mit CoreELEC und auch mir wäre ein externer Player lieber, aber nicht jeder mag viel IT-Gedöns, es wären damit Kabel und ein Device mehr vorhanden. Wie muss ich mir das Vorstellen mit „nicht“ nativ? Ich habe es über verschiedene Wege der VM probiert, sobald die iGPU zum Tragen kommt war das mit dem HDMI/DP out und gerne mit freezer. Als App gibt es da nichts, ich könnte höchstes eine VM installieren, dort dann ein 'elec installieren und schauen, ob ich iGPU an HDMI/DP durchgereicht bekomme.
-
Meine Schwester hat einen „uralt“ Asustor AS3202T 2-Bay NAS, gibt sogar noch immer Updates Jellyfin support..usw. aber bei 2GB RAM wird das wenig lustig, wenn mal für Fotos ne Datenbank anlegen möchte nebenher.. und jellyfin.. usw.. Sie wollte gerne den HDMI nutzen, jetzt habe ich Ihr mein altes ASRock Rack C246 WSI vermacht sammt 2x16GB DDR4 uREG ECC RAM, schön mit DP/HDMI und bekomme weder LibreELEC noch OpenELEC mit durchgereichter iGPU zum Laufen. Ja ich kenne CoreELEC habe einige Boxen seit Jahren am Laufen (müssten auch mal nen Upgrade erfahren derzeit aktuellste ARM 905x3). Womöglich muss ich bei Ihr wieder mit mehr Kabelsalat, weiteren Devices herumhantieren, wollte ich eigentlich vermeiden. Ach so der PCIe Steckplatz ist für NVMe Bifurcation draufgegangen.
-
@alturismo Danke für den Hinweis, dann habe ich jetzt ja einiges an Zeit gespart, denn mehr als ein Schwarz werdender Monitor oder einfrierender NAS kam leider nicht dabei heraus die iGPU eines i3 9350k über HDMI/DP durchzujagen. Eigentlich schon schade, einige fertig NAS-Kisten bekommen dies umgesetzt.
-
Moin zusammen, da ich mein bestehende Windows 11 Szenario direkt auf Blech; (Intel Xeon E5-2630L V4Asus Z10PA-U8 C612) ersetzen möchte, u. a. frisst die Kiste zwar „nur“ ~42Watt Idle (4x M.2 SSD), dafür aber im ausgeschalteten Zustand um die 8Watt (Gigabyte Mainboard MC12-LE0 Re1.0 AMD B550 kommt da auf 4Watt mit dem Ryzen 7 5700x) und eh bald Win 11 nicht mehr auf den "alten" Xeons laufen wird, stellt sich mir die Frage, wie ich das am besten umsetzen „sollte“.. Gedanke ist 3x 2TB Mega Fastro MS200 M.2 PCIe 3.0 x4 3D-NAND TLC (MS200-2TB) zu einem ZFS (RAIDz1) zusammen zusetzen, als "pool" auf dem die VM sitzen, als cache und dachte ich, dass ich 2x rumliegende 1TB WD SN570 nutze. Was das Array betrifft, wird hier wohl erstmal nur ein Platzhalter dienen, ich weiß einfach noch zu wenig bei unRAID sich bei 4x 8TB HDD ZFS (RAIDz1) verhält, wie „einfach“ ich hier in gewohnter xfs Manier die Platten ersetzen kann usw. Persönlich finde ich auch die Anleitung; https://docs.unraid.net/unraid-os/manual/zfs/placeholder/ jetzt nicht bahnbrechend, vllt. wäre es einfacher und verständlicher mal Beispiel Videos reinzupacken, wie etwas aussieht, auch das Thema Plugins..kapiere ich zumindest hier nicht vor allem was man real benötigt, ZFS RAIDz kann auch ohne nach dem Formatieren erstellt werden.
-
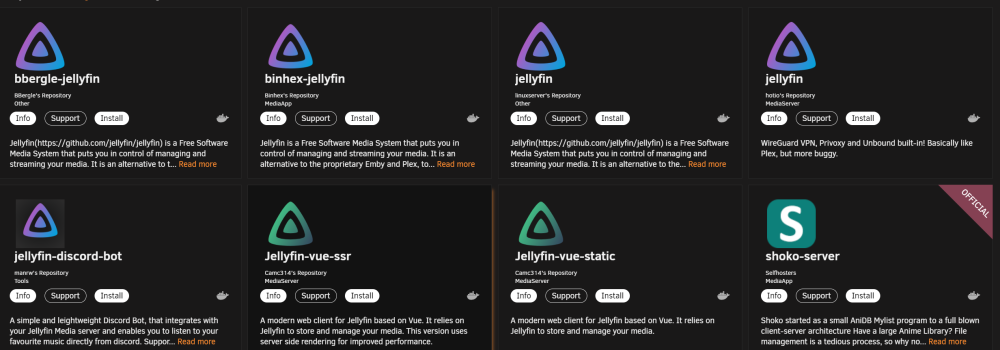
Danke, ich habe jetzt den „bbergle-jellyfin“ in Verwendung unter den Zusätzliche Parameter: --device=/dev/dri Wurde RAM transk. anbelangt so bin ich am ausprobieren; Schön ist aber, dass Vaapi transc. funktioniert. config dürfte etwas zugemüllt sein; " #!/bin/ # AMD iGPU modprobe amdgpu chmod 777 aktivieren /dev/dri # Verwaltungsdienstprogramm starten /usr/local/sbin/emhttp & " Wenn ich das richtig gelesen habe, soll das „Radeon TOP“ aber die Einstellungen von „modprobe“ ersetzt werden, auch gab es die Info, dass „Bei ‚Device‘ unten hier in der Vorlage ‚/dev/dri‘ hinzufügen“ anzugeben, Ich werde bei Problemen dann von „Extra Parameters“ auf „Device“ wechseln. EDIT; RAM Transkodierung klappt bei mir mit folgenden Anpassungen; In Jellyfin; Dann bleibt auch folgender Pfad schön leer; ..und folgender füllt sich; "ls -l /dev/shm/jellyfin"
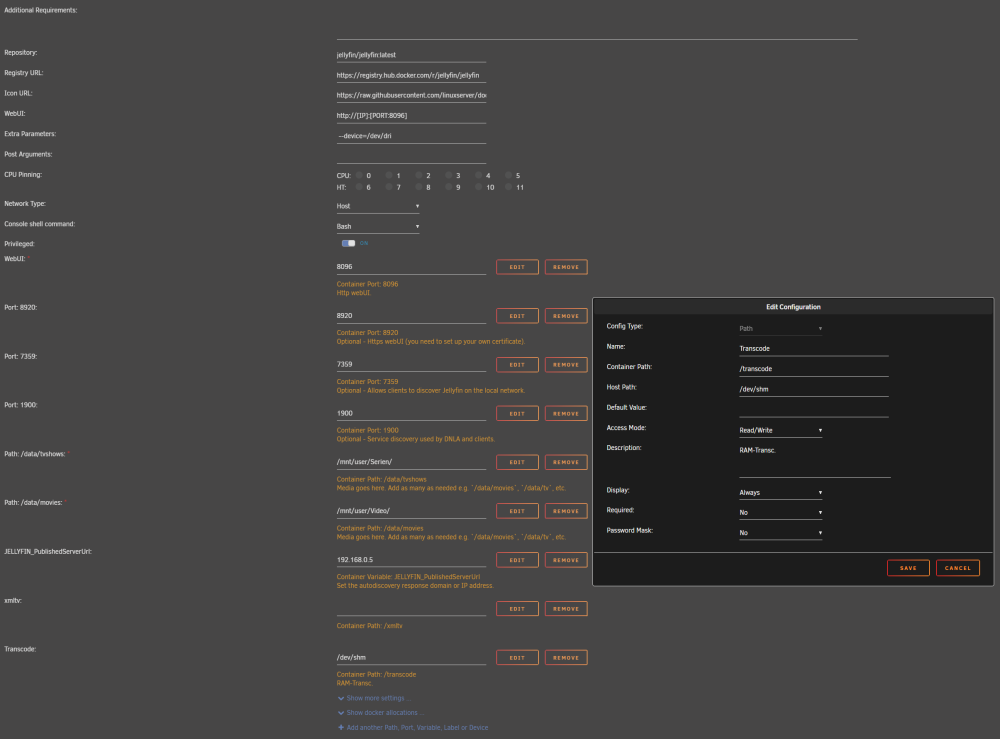
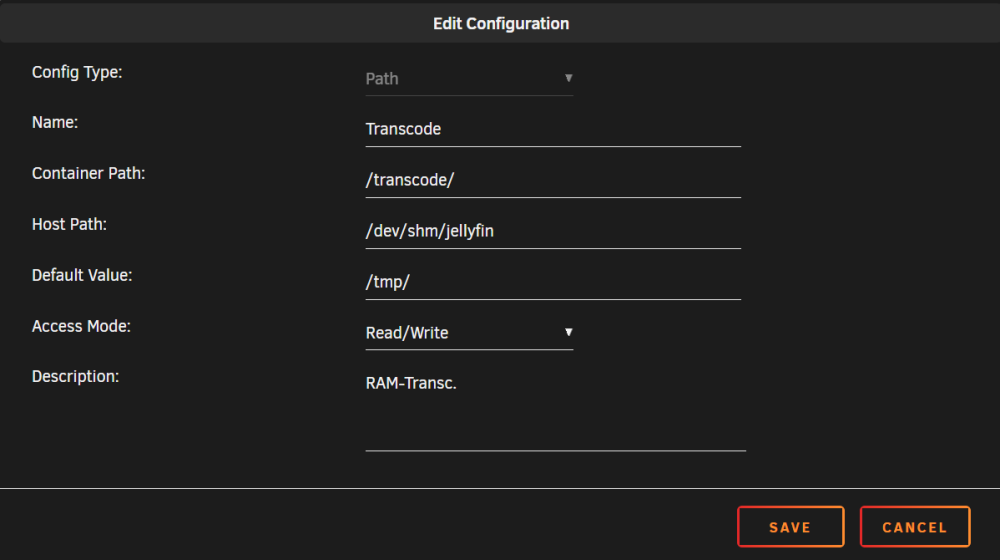

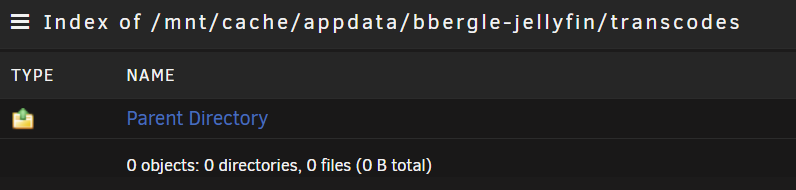
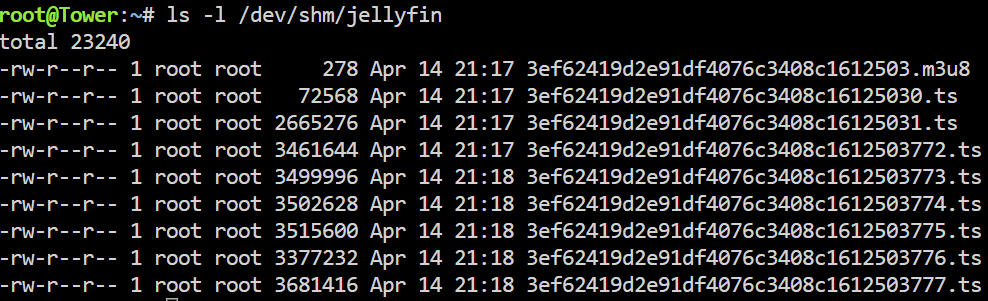
-
Naja, auf die Idee bin ich auch gekommen, genau wie Jellyfin Foren/Guide selbst aufzusuchen. Lediglich "bbergle-jellyfin" gibt HW Transc. in der Info an, im Kern ist das aber nicht meine Frage. Frage könnte auch sein, was bringt es so viel „Jellyfins“ zu haben, ohne die Merkmale was unter unRAID empfohlen wird u.a. für HW transcodierung. Ich wühle mich dann derzeit durch das geschlossene erwähnte Topic mal durch...
-
Hi zusammen, vor einigen Jahren hatte ich den Beitrag Dankenswerterweise umsetzen können; angepasste ich777/jellyfin' in Verwendung und auch meinen RAM als cache zur SSD vorgezogen, wie zu sehen, geht der Schwenk zu 'jellyfin/jellyfin" und ich und vllt. auch eine andere Nutzer sieht es dann so aus; und ich frage mich, was man denn hier eigentlich wählen sollte, optimalerweise, wenn es um die VEGA Einbindung für Transkodierung geht. Plugins wie; Radeon TOP und NVTOP und auch die Anpassung; # Enable AMD iGPU modprobe amdgpu wie auch; add '/dev/dri' Habe ich vorgenommen, keine Ahnung, ob das alles noch vonnöten ist. Danke für Vorschläge Optimierungen.
-
What is incomprehensible?
-
GT 7x0 can still be used in uEFI, but for xeons that don't have an iGPU, Gt 7x0 was also a good option for the VM. Too bad, even under Win11 you can still use the Kepler with driver.
-
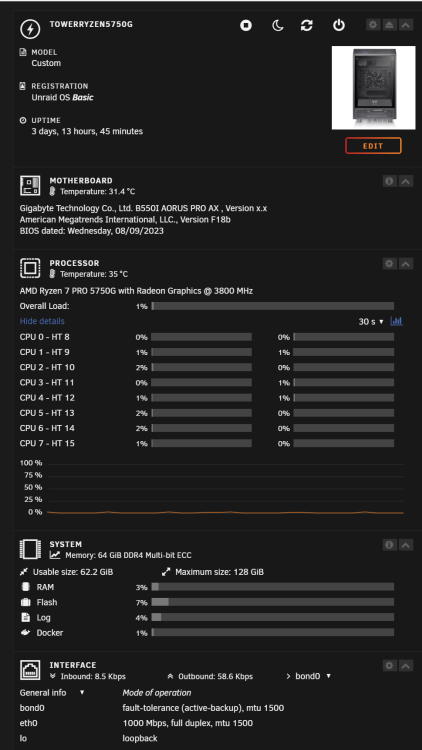
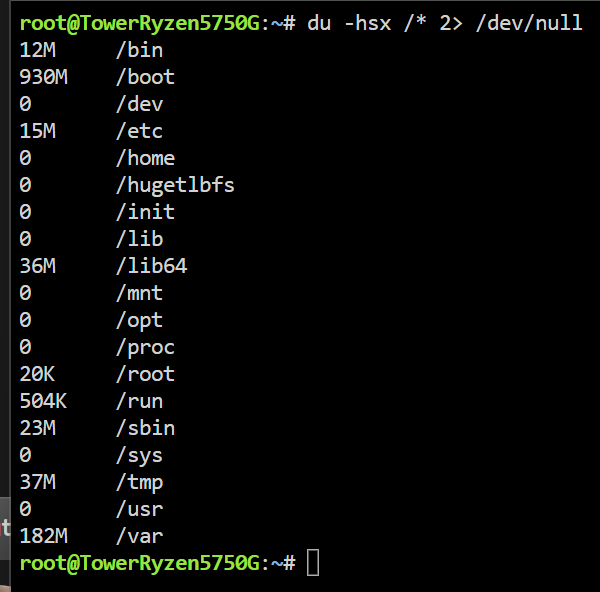
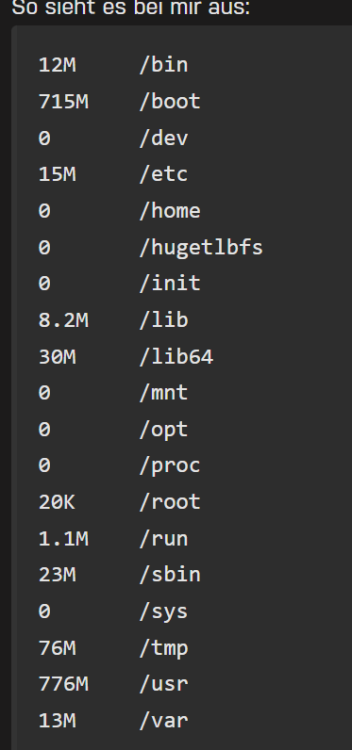
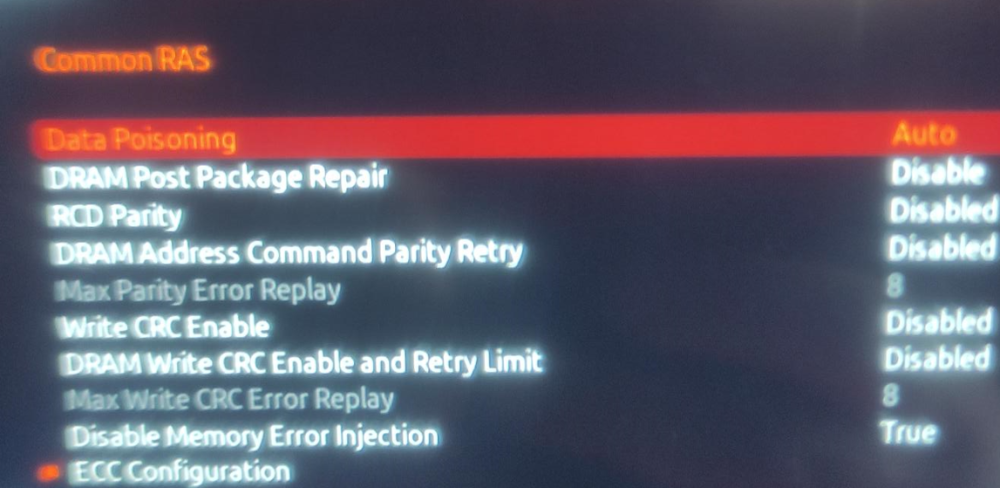
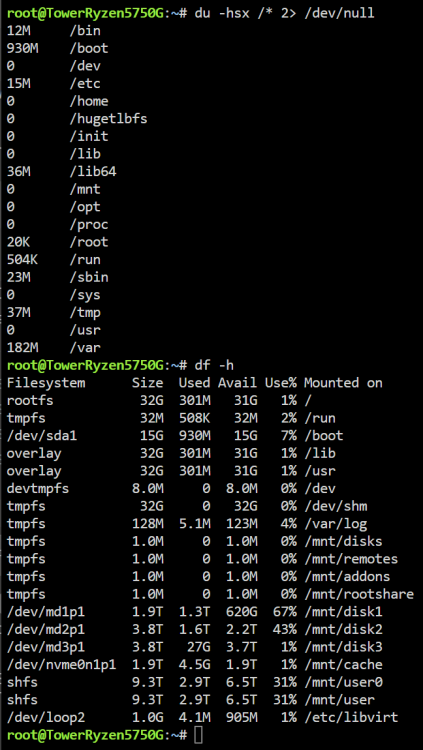
@mgutt Danke Dir erstmal für die Mühe, ich selbst hatte schon auf Verdacht, dass der RAM kaputt sei, diesen getauscht aber eben keine Besserung.. daher auch noch die Vermutung, dass seitens des uEFI's noch im Bereich ECC Anpassungen getätigt wären müssen. Seit zwei Tagen sieht es nun recht ruhig aus, lediglich das „log“ file hat sich um 1% erhöht.: „du -hsx /* 2> /dev/null“, Ergebnis, rechts @mgutt und links dann meine Ergebnisse, „/lib“, „/Usr“, „/var“, ist hier recht auffällig. Ich habe hier nochmal meine Docker Einstellungen, leider bekomme ich nicht mehr eingeblendet (MacVLAN vs IPvlan Thematik); Ansonsten laufen nur die beiden Container: Zu den ECC Einstellungen im uEFI;
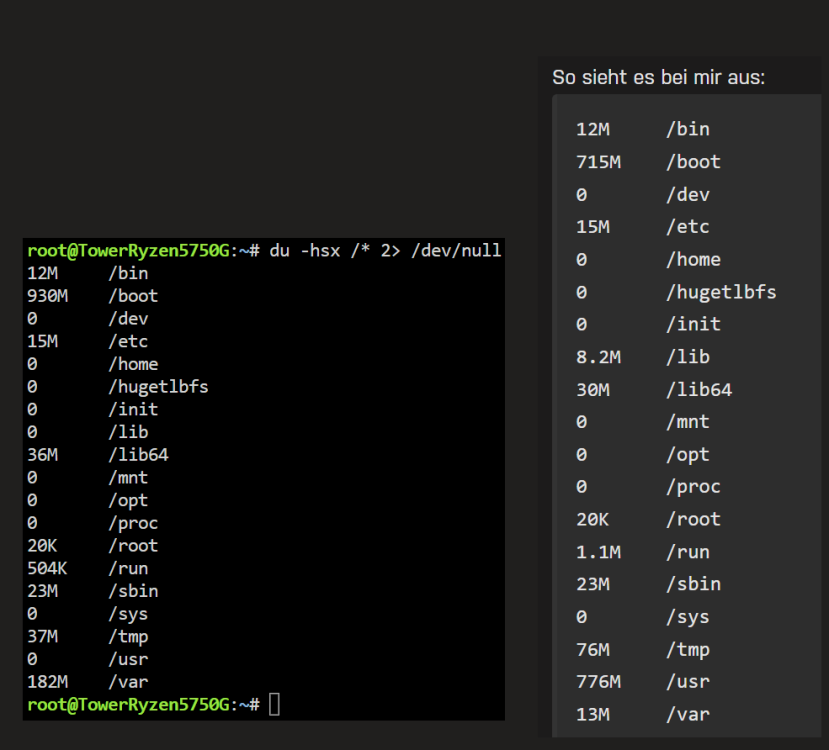
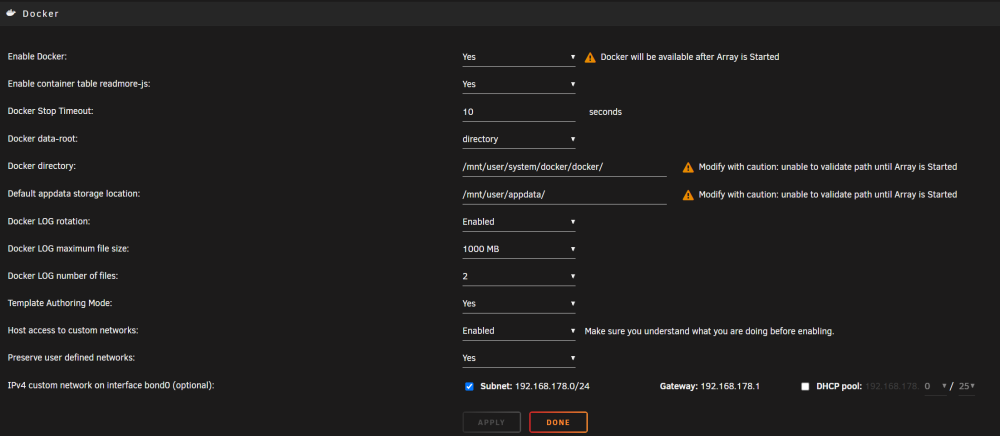
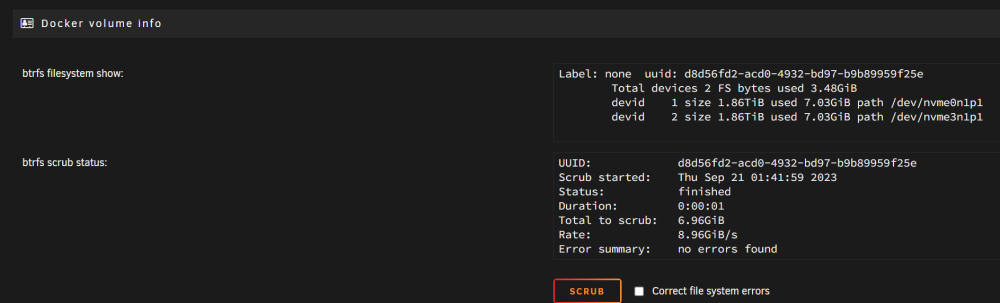
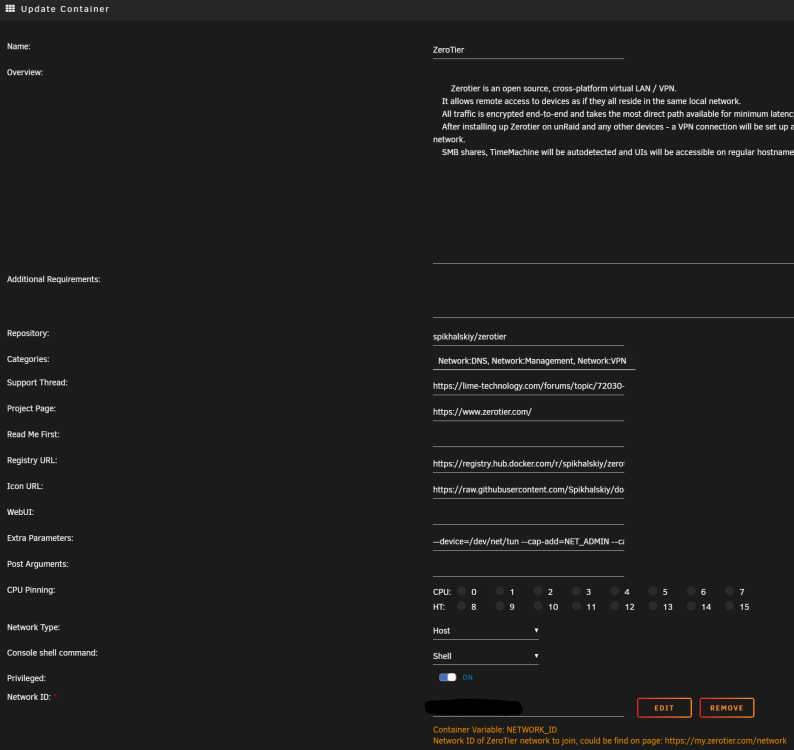

-
'n Abend zusammen, ich hänge mich mal hier mal mit dran, sollte ich damit stören, mache ich natürlich ein separaten Topic auf,... Ich habe schon länger Probleme auch nach dem Wechsel von Intel zu AMD mit regelmäßigen einfrieren (hatte ich auch schon hier in der Vergangenheit in anderen Topic's geschildert), nicht mehr erreichen des Servers. Reboot half dann meist für eine kurze Zeitspanne. Hellhörig wurde ich jetzt bei der These, und eben dem, was "LyDjane" beschrieb, denn auch mein Server dreht willkürlich mein Ryzen Server auf, nach einer halben Stunde war das noch immer der Fall. Es geht um folgendes Setup; Unraid Basic 6.12.4 Thermaltake The Tower 100 Mini Tower Schwarz SAMSUNG 32GB Flash Drive FIT Plus USB-Stick (Boot-Stick) AMD Ryzen 7 PRO 5750G Samsung DIMM 32GB, DDR4-3200, CL22, ECC (M391A4G43BB1-CWEQ) Samsung DIMM 32GB, DDR4-3200, CL22, ECC (M391A4G43BB1-CWEQ) GIGABYTE B550I AORUS Pro AX rev. 1.1 BIOS; F18b (aktuell) Pool: Asus Hyper M.2 X16 Card V2 (es werden leider max: x4x4x8 unterstützt) Lexar NM620 2TB, M.2 (cache) btrfs Lexar NM620 2TB, M.2 (cache2) btrfs Array: Lexar NM790 4TB, M.2 (parity) Western Digital WD Blue SN570 NVMe SSD 2TB, M.2 (Disk1) (xfs) Transcend SSD230S 4TB, SATA (Disk2) (xfs) Transcend SSD230S 4TB, SATA (Disk3) (xfs) Netzteil: Seasonic Focus 450Watt SFX Gemessen mit; denver smart home app; Idle ~28Watt Fritzbox 6690 cable (Vodafone, dual Stack, kein CGNAT) Einstellungen wurden wie oben bei "LyDjane" gesetzt; Einstellungen sind derzeit folgendermaßen: Settings > Network Settings > eth0 > Enable Bonding = Yes Settings > Network Settings > eth0 > Enable Bridging = No Settings > Docker > Host access to custom networks = Enabled Auffällig ist, dass vor allem ein Thread fast durchwegs auf 100% taktet.. ich habe dann die Kiste einmal neu gestartet und es war ruhe im Karton. ... ansonsten war erstmal alles wie gewohnt.. 1-2% Auslastung, smb Zugriff funktionierte.. WireGuard VPN ebenfalls, alles fein.. Dann am späten Abend wieder, die Kiste dreht voll auf nur diesmal habe ich mich dann pennen gelegt, auf den NVMe array/pool war auch nicht aktiv, kein R/W Datentransfer, zwei Container liefen (DuckDNS/Zerotier) lediglich und WireGuard eben über das System selbst. Ich dachte lass den Server mal arbeiten, womit auch immer... Heute Morgen dann direkt geschaut und gestaunt, die LOG Datei war voll, laut dem Webinterface, glücklicherweise kam ich überhaupt noch auf das WebUI und konnte bis auf das Starten des Docker Updaters (endlose Suche...) auch auf die Option ohne Einfrieren zugreifen.. habe schnellstmöglich die Option gesetzt für das LOG Schreiben auf dem Boot-Stick, via smb konnte ich darauf auch zugreifen und retten ... zumindest bis etwa ~35MB geschrieben waren.. danach kam ich dann auch nicht mehr auf der WebUI weiter... Die „wenigen“ LOG Datei Einträge wiederholen sich stetig, ich poste deshalb lieber nur einen kleinen der "syslog"; ".... Sep 20 08:26:44 TowerRyzen5750G rsyslogd: file '/var/log/syslog'[5] write error - see https://www.rsyslog.com/solving-rsyslog-write-errors/ for help OS error: No space left on device [v8.2102.0 try https://www.rsyslog.com/e/2027 ] Sep 20 08:26:44 TowerRyzen5750G rsyslogd: action 'action-0-builtin:omfile' (module 'builtin:omfile') message lost, could not be processed. Check for additional error messages before this one. [v8.2102.0 try https://www.rsyslog.com/e/2027 ] Sep 20 08:26:44 TowerRyzen5750G rsyslogd: file '/var/log/syslog'[5] write error - see https://www.rsyslog.com/solving-rsyslog-write-errors/ for help OS error: No space left on device [v8.2102.0 try https://www.rsyslog.com/e/2027 ] Sep 20 08:26:44 TowerRyzen5750G rsyslogd: action 'action-0-builtin:omfile' (module 'builtin:omfile') message lost, could not be processed. Check for additional error messages before this one. [v8.2102.0 try https://www.rsyslog.com/e/2027 ] Sep 20 08:26:44 TowerRyzen5750G rsyslogd: file '/var/log/syslog'[5] write error - see https://www.rsyslog.com/solving-rsyslog-write-errors/ for help OS error: No space left on device [v8.2102.0 try https://www.rsyslog.com/e/2027 ] Sep 20 08:26:44 TowerRyzen5750G kernel: BTRFS error (device nvme0n1p1): invalid free space control: bg start=30408704 len=1073741824 total_bitmaps=8394709 unit=4096 max_bitmaps=8 bytes_per_bg=134217728 Sep 20 08:26:44 TowerRyzen5750G kernel: BTRFS error (device nvme0n1p1): invalid free space control: bg start=30408704 len=1073741824 total_bitmaps=8394710 unit=4096 max_bitmaps=8 bytes_per_bg=134217728 Sep 20 08:26:44 TowerRyzen5750G kernel: BTRFS error (device nvme0n1p1): invalid free space control: bg start=30408704 len=1073741824 total_bitmaps=8394711 unit=4096 max_bitmaps=8 bytes_per_bg=134217728 Sep 20 08:26:44 TowerRyzen5750G kernel: BTRFS error (device nvme0n1p1): invalid free space control: bg start=30408704 len=1073741824 total_bitmaps=8394712 unit=4096 max_bitmaps=8 bytes_per_bg=134217728 Sep 20 08:26:44 TowerRyzen5750G kernel: BTRFS error (device nvme0n1p1): invalid free space control: bg start=30408704 len=1073741824 total_bitmaps=8394713 unit=4096 max_bitmaps=8 bytes_per_bg=134217728 Sep 20 08:26:44 TowerRyzen5750G kernel: BTRFS error (device nvme0n1p1): invalid free space control: bg start=30408704 len=1073741824 total_bitmaps=8394714 unit=4096 max_bitmaps=8 bytes_per_bg=134217728 Sep 20 08:26:44 TowerRyzen5750G kernel: BTRFS error (device nvme0n1p1): invalid free space control: bg start=30408704 len=1073741824 total_bitmaps=8394715 unit=4096 max_bitmaps=8 bytes_per_bg=134217728 Sep 20 08:26:48 TowerRyzen5750G kernel: _btrfs_printk: 846 callbacks suppressed ...." Ich habe mehrfach Parity checks, und unter Docker "Correct file system errors" mit Korrektur durchlaufen lassen. Auch den fix "Common Problems Befehl" und die beiden Tests unter; "Update Assistant Disk Utilities" . Auch habe ich versucht, mit dem Befehl: "append initrd=/bzroot nvme_core.default_ps_max_latency_us=0 pcie_aspm=off" in den Loader des USB-Sticks einzutragen. , ein Unterschied machte das nicht bezüglich der Stabilität, auf das array konte ich eh immer zugreifen, auch auf das pool selbst.. Aufgrund dessen strich ich denn ASPM Killer dann mal wieder. Im BIOS habe ich "C-States" deaktiviert, auch wenn das Problem mit Abstürzen/Einfrieren gefixt worden sein soll/te. Ach und den ECC uREG RAM habe ich auch ausgetauscht und betreibe ihn auf dem Default Status. ..habt Ihr noch eine Idee? Danke für evtl. Anregungen..
-
".... Wozu machst du das alles und lässt es nicht so wie es war? Das Ändern der Pfade in /mnt/cache ist nur für fortgeschrittene Nutzer empfohlen und ab unRAID 6.12 ist dieser Performance Tweak auch überflüssig, daher würde ich ihn nicht mehr verwenden. ".... Vielen Dank für den Hinweis bitte sei doch dann auch so lieb und merk das in der Anleitung an. Ich selbst werde mein System bald auch wieder neu aufsetzten, die monatlichen Verbindungsabbrüche nerven langsam wie auch beim vorherigen System. Derzeit habe ich es so umgesetzt;
-
... Admin-Aktivierung im Forum bei "https://forum.ts.fujitsu.com/ lässt auch mit unterschiedlichen E-Mails auf sich warten... Seitens des Supports zum Fehler Error-Code gibt es nur mit Rechnung, ansonsten kein weiterkommen.^^ Wie gewohnt 1x im Monat Absturz. Mal sehen was das aktuelle Beta Update so bringt, vllt. Beim nächsten Absturz werde ich da dann auf Ryzen wechseln., auch im Anbetracht dass ja in der aktuellen Unraid Beta; Linux kernel version 6.1.20 CONFIG_X86_AMD_PSTATE: AMD Processor P-State driver ....hinzugekommen ist. Hoffe dass es dazu vllt. noch eine Anleitung gibt, falls Anpassungen außerhalb des uEFI's nötig sein werden.
-
Btw; Das C246 WSI kann mit PCIe Erweiterungskarte (x8x4x4) 3* NVMe sowie eine weitere NVMe über den M.2 2242 Slot aktiv nutzen, außerdem über OCuLINK weitere 4* S-ATA + 4 weitere direkt übers Board anbinden, wenn man auf iGPU setzt, also recht gut vollzupacken das itx Board.
-
Danke, mal sehen ob die das auch ohne Ticket/Gold Status machen. Werde erstmal L0s beim PCIe herausnehmen, danach die C-States weiter zurückfahren.


















