




JustinChase
Members
-
Joined
-
Last visited
Everything posted by JustinChase
-
Just upgraded and was poking around. Noticed a red warning after scrolling down the dashboard that the parity drive is missing. Looked, and yeah, seems to be. I wasn't presented any errors, and don't seem to be having any issues using the server, but i suspect I'm now unprotected, and that seems bad. Diagnostics attached. media-diagnostics-20180505-1549.zip
-
this worked 2 versions ago, many times. Now, after upgrading twice, the USB controller I've passed thru to my Windows VM no longer recognized when a device is plugged in 9 out of 10 times, and if I leave it plugged in, then restart the VM, it finds the device, but it's regularly disconnecting and reconnecting, making it useless, as any file operations are killed when it disconnects momentarily. I've tried with 2 cables, and 2 drives, and it's acted this way with all combinations. Not sure what might have caused this, or if it's 'just me' somehow. I'll try to revert back a couple versions and see if functionality returns this evening. media-diagnostics-20180427-0953.zip
-
thanks again Binhex for all the support you provide, i certainly do appreciate it. I figured i was probably working from an old template, which is why I just nuked the whole thing, including the previously installed apps in community applications, and tried to start as 'from scratch' as I could. When i first did this, there was a variable in the template where I could just enter the server I wanted and that just worked. I don't remember ever needing to download the openvpn file, but it's very possible I just don't remember doing it. I understand you can only make it so foolproof, but us fools will get you, no matter what you try. I wasn't trying to imply that you don't or aren't, sorry if it seemed that way. I deleted all but the montreat ovpn file and 3 other not-ovpn files and its working now. thanks for your help
-
I suspect it's mis-configuration in this case, but I also blame the setup for not offering what's needed. I put the PIA server i the VPN_OPTIONS box, because I didn't (and still don't) see any place to put the PIA server. I'll re-read this entire thread when I get back later, and figure out what variable I need to add to get it working. (it would be nice if that variable was there by default, and the options variable wasn't) Thanks again. PS, I wasn't trying to say you should have it just magically work for any/all providers, and options, but maybe a 'just works' with PIA, since it's the easiest to configure, and offers port forwarding out of the box (with a pre-selected known working forwarding endpoint server) and/or pop up a warning if all required fields aren't filled out, or if the options is filled, but likely not necessary). Again, not your job to make it too easy, just some ideas I have after fighting what seems like a very unnecessary fight against my server.
-
yes, it does, but what is " auth-user-pass (2.4.5) " referring to? What do I need to change? I don't have any weird characters in my user name or password for PIA, and like I said, it was all working fine for years until a couple days ago. I've installed with the default settings, only adding my endpoint, user name and password; but that doesn't work. If it set vpn enabled to no, it works, so it's to do with that, but I have the correct user name, correct password, and I believe, the correct endpoint. (i've tried montreal and toronto, both fail). This feels like an setup/installation problem. I've kept pretty much all defaults, so I would expect it to pretty much work right out of the box. Please let me know if you want me to run a debug for you, but it seems the error code above ought to point to something without all that.
-
That didn't quite work, I ended up deleting all SAB containers, and any templates CA had saved, and then installed from scratch. This created a new folder structure, and this new structure had a folder called openvpn located at /mnt/cache/appdata/binhex-sabnzbdvpn/openvpn (not /config/openvpn/ and it was blank. I downloaded the file you linked and unzipped everything into this new folder. Now, SAB will start. I've lost all my settings, obviously, but at least it seems to be working. Perhaps in the future, if one selects pia as the provider, you can download the necessary files and put them in place automatically? Also, I have absolutely NO IDEA why my setup just died one day for no apparent reason, I certainly did not delete any openvpn files, oh well. It seems it's fixed now/again. Thanks PS Sadly, it's not actually working. It seems to start now (green arrow, not red square icon), but it doesn't actually let me get to the GUI, so I can't actually use it. It's a fresh, brand new install. Is it supposed to just work, or do I need to re-read the OP and re-learn how to do this? I don't remember it being this complicated before. log shows this error... Options error: Unrecognized option or missing or extra parameter(s) in [CMD-LINE]:1: auth-user-pass (2.4.5) that doesn't seem to be the vpn password; I just confirmed it's right. so, I'm not sure what's going on. thanks again for the help, and sorry to be a pita
-
I'll do all that now, and I'm sure it will work. the question becomes, how did it go away? it's worked fine for years, and I don't recall making any changes related to Dockers in a long time. was it done differently long ago and now things have changed, or is this just one of those weird things that happen in life. Sent from my HTC6545LVW using Tapatalk
-
I removed the docker and container and re-installed it, same error. Nothing related to openvpn under the /config folder on the flash drive.
-
I can't find a /config/openvpn/openvpn.ovpn anywhere, but I found /mnt/cache/appdata/sabnabdvpn/openvpn.ovpn It is a blank file. will a log of any sort help?
-
SABnzbd has been running fine for years. Today, I noticed an error in Sonarr that SAB wasn't responsive (or something), and unRAID notified me of many updates, so I just updated all dockers (Deluge, SABnzbd, mariadb, Nextcloud) and once finished, i tried to start SAB, but it just will not start. here is the log from the 3 times I tried after updating. Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2018-04-17 10:36:05.187484 [info] Host is running unRAID 2018-04-17 10:36:05.214652 [info] System information Linux 7452edd79e01 4.14.33-unRAID #1 SMP PREEMPT Sun Apr 8 09:14:46 PDT 2018 x86_64 GNU/Linux 2018-04-17 10:36:05.245612 [warn] PUID not defined (via -e PUID), defaulting to '99' 2018-04-17 10:36:05.292649 [warn] PGID not defined (via -e PGID), defaulting to '100' 2018-04-17 10:36:05.333527 [warn] UMASK not defined (via -e UMASK), defaulting to '000' 2018-04-17 10:36:05.363287 [info] Permissions already set for volume mappings 2018-04-17 10:36:05.402040 [info] VPN_ENABLED defined as 'yes' 2018-04-17 10:36:05.437123 [info] OpenVPN config file (ovpn extension) is located at /config/openvpn/openvpn.ovpn dos2unix: converting file /config/openvpn/openvpn.ovpn to Unix format... Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2018-04-17 10:36:23.369998 [info] Host is running unRAID 2018-04-17 10:36:23.394661 [info] System information Linux 7452edd79e01 4.14.33-unRAID #1 SMP PREEMPT Sun Apr 8 09:14:46 PDT 2018 x86_64 GNU/Linux 2018-04-17 10:36:23.420571 [warn] PUID not defined (via -e PUID), defaulting to '99' 2018-04-17 10:36:23.448664 [warn] PGID not defined (via -e PGID), defaulting to '100' 2018-04-17 10:36:23.483373 [warn] UMASK not defined (via -e UMASK), defaulting to '000' 2018-04-17 10:36:23.509744 [info] Permissions already set for volume mappings 2018-04-17 10:36:23.543138 [info] VPN_ENABLED defined as 'yes' 2018-04-17 10:36:23.575686 [info] OpenVPN config file (ovpn extension) is located at /config/openvpn/openvpn.ovpn dos2unix: converting file /config/openvpn/openvpn.ovpn to Unix format... Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2018-04-17 10:37:34.220132 [info] Host is running unRAID 2018-04-17 10:37:34.248672 [info] System information Linux 7452edd79e01 4.14.33-unRAID #1 SMP PREEMPT Sun Apr 8 09:14:46 PDT 2018 x86_64 GNU/Linux 2018-04-17 10:37:34.277363 [warn] PUID not defined (via -e PUID), defaulting to '99' 2018-04-17 10:37:34.307355 [warn] PGID not defined (via -e PGID), defaulting to '100' 2018-04-17 10:37:34.338576 [warn] UMASK not defined (via -e UMASK), defaulting to '000' 2018-04-17 10:37:34.364294 [info] Permissions already set for volume mappings 2018-04-17 10:37:34.400206 [info] VPN_ENABLED defined as 'yes' 2018-04-17 10:37:34.433560 [info] OpenVPN config file (ovpn extension) is located at /config/openvpn/openvpn.ovpn dos2unix: converting file /config/openvpn/openvpn.ovpn to Unix format... I guess i can uninstall and reinstall, but thought I should report what I experienced.
-
I looked at the dashboard today and saw only one drive had a temperature listed. But all the drives were spun up, so I was surprised. I spun down a drive and spun it back up and its temp was then reported. Not sure why they only show for a recently spun up drive, but it seems to be a bug.
-
I spoke too soon. video seems just fine, audio is a no-show. I originally had Intel Display Audio and HD Audio (or similar) as sound devices in windows > settings > sound. However, neither actually worked to give sound thru HDMI. I then figured it'd be wise to 'start fresh' and uninstalled the audio drivers and confirmed they were gone in device manager. I then reinstalled the intel Graphics drivers (which install the audio). Now, I can see Intel Display Audio in Device Manager, but settings > sounds says no audio devices are installed. restarting didn't fix this obvious discrepancy. I guess, I'll try removing the sound driver from the VM setup, boot, then add it and see if that gets windows to see it. Am I missing something, or is Audio still sketchy with iGPU?
-
fresh install won out on time over 'fixing' another. I'm not finished, but it's finalizing updates now. I'm so happy this is working so easily now. I can remove another power hungry card from the server. Core i5 HD4600 iGPU in server i440fx-2.7 SeaBios Hyper-V - yes USB - 3.0 (qemu XHCI) and passing thru a PCI USB controller (now, to figure out which ports these are giving to windows...)
-
I'm trying to get a Windows10 VM running with the iGPU today, and I'm making progress, but have some questions. Is it possible to 'convert' a non iGPU Windows VM to use the iGPU instead? I'd rather 'update' a working install i have than reinstall fresh. I have tried to use a working VM, but couldn't get it to work, so I tried to just install fresh, and that's working, so i know now that the setup is good, it's just trying to stick an existing VM into the process. I don't want to spend 2 hours fighting to get this working, since I can finish the fresh install almost that fast. Has anyone gotten this to work?
-
Great, thanks! I think it was uBlock causing it. Have a great day!
-
I always get this message when I open FCP... Ad blocker detected. Ad blockers can interfere with the GUI of unRaid, and it is recommended to whitelist your server in the ad-blocker settings I thought I've whitelisted it everywhere, but I still get the message. Can you tell me what/how you test this, so i can figure out what's triggering it and whitelist it there? Thanks!
-
I guess I never considered that. I guess it is just what it is. Thanks for the input.
-
My normal ping is 600ms, so latency is a big issue. I kinda figured once the connection is handled, the latency is absorbed (it's all delayed, but stays steady). Maybe not. I have no cell service here, not for miles, satellite is the only option for me; sadly.
-
do you mean this entry? Key 6: Container Variable: VPN_PORT 1198 I don't remember adding that, i thought it was part of the template. Perhaps I need to just kill this container altogether and restart from scratch. Although, it seems I have it set right, that seems drastic.
-
I have them set to go to my SSD Cache drive. I guess I could send them to the unassigned SSD I use for my VM's as a test. Hopefully someone else sees something else I'm not doing right. I looked at the supervisord.log and it keeps saying "random port = False" which someone said is bad, but I've enabled/checked random incoming ports in the deluge interface settings several times, and it always looks like it's accepted the check, but when i restart the docker, it's back to not being checked. Not sure how that's happening.
-
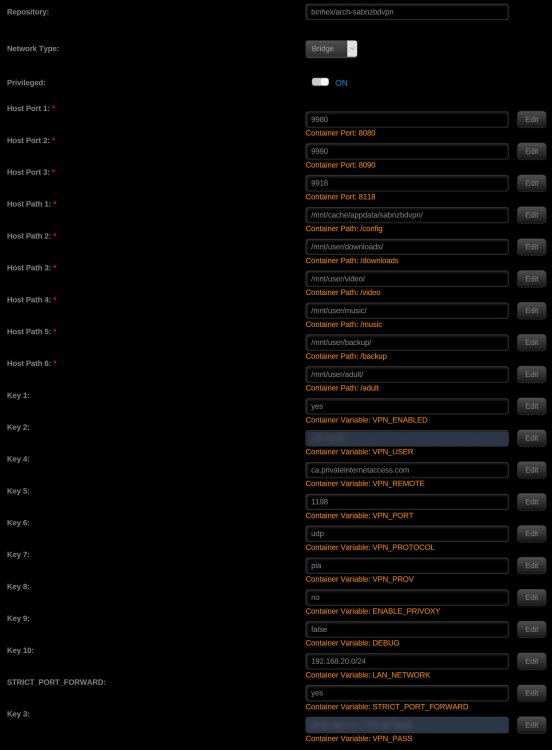
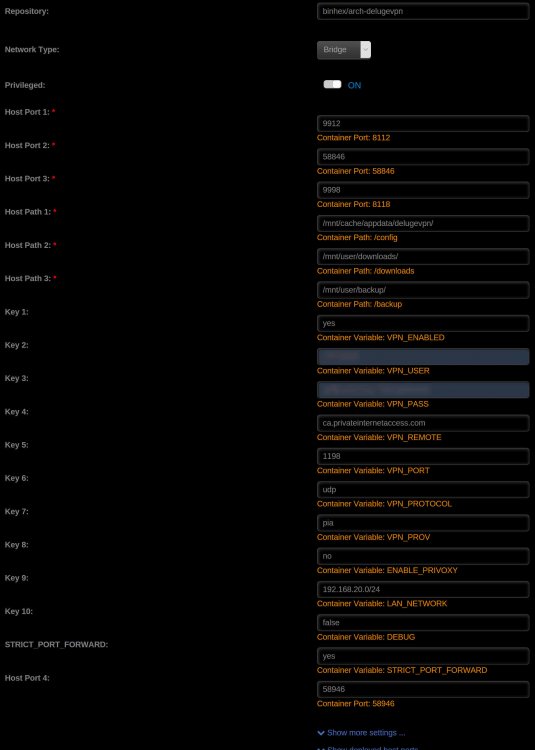
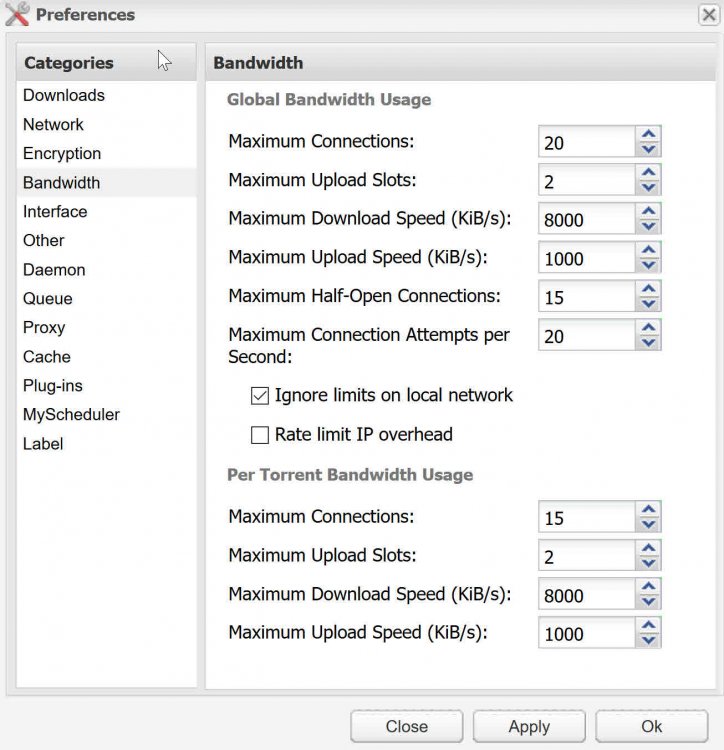
this forum search function isn't great, so a search for slow speeds and slow downloads wasn't very helpful. So, I've got terrible satellite internet, and go over my data every month. But, they do allow me my 'normal' speeds during the day, when the network isn't busy. My download speed is 12 Mbps, and 1 Mbps upload. I just ran a test and got 9 Mbps down and 1 Mbps upload, which is typical during the day here. I have felt my download speeds were very slow with Deluge for some time, but just kinda ignored it, but now it's annoyed me enough to try to 'fix' it. I know part of the issue will be available seeds, so I went to a torrent site and just grabbed something with over 3000 seeds, so it should be about as fast as it will get. I watched it climb to about 400 KiB/s, then settle into a more normal for me 125 KiB/s. I assume this isn't normal and I should be able to get better speeds than this. With SABnzbdVPN docker I get 1.2MB/s regularly. I just added something as a test and SAB has leveled off at about 700-800 KB/s. both are using the same VPN settings. I included screenshots of the SAB and deluge docker setups and also the deluge bandwidth settings. I think I have it setup right from what I've read here, but it seems something isn't right. any advice appreciated.
-
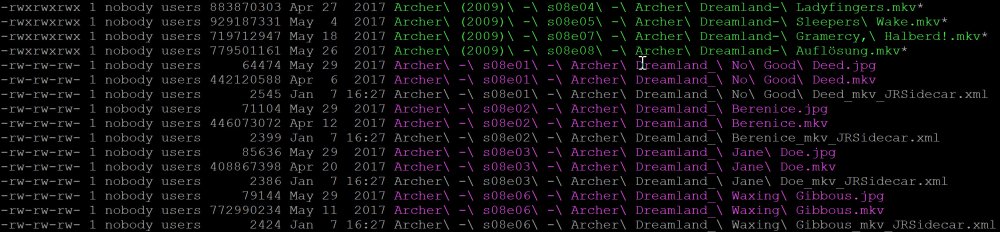
A question about permissions: I used to have the setting at 770, which mostly worked, but Fix Common Problems complained that the files didn't have the right permissions, and I had to run the Docker Safe new Permissions script in tools to 'correct' them. So, I changed Sonarr to use 777 instead, and now FCP doesn't complain, but my (JRiver) media player doesn't like the new permissions. I used to be able to "Update Library (from tags)" to get the program to see the new dimensions (1080 from 720) because Sonarr found the better file. But after changing to 777 JRiver fails when I try to update; which tells me it doesn't like the new permissions for some reason. Below is a screenshot of a few files (in green) that Sonarr just replaced and you can see their permissions are not the same as the rest of the files. tl;dr: how do I set the permissions in Sonarr to match what Docker Safe New Permissions sets them to?
-
I got a warning this morning that said unRAID file corruption: 1-22-2018 11:27AM Notice [Media] - bunker verify command Found 6 files with SHA256 hash key mismatch I'm not sure it's this plugin throwing the warning, nor am I sure how to find these 6 files. The Fix Common Problems tool isn't showing any errors, and I'm not sure what else might notice such a thing. Suggestions on how to proceed?
-
Upon entering the page to re-run the extended test, I was greeted with the scanning window. it's been scanning for almost 10 minutes now. I understand this is not normal. how do I help troubleshoot why it's taking so long scanning, and/or how can I just stop it? I opened a new window and quickly hit run extended test, and it started. I was then able to see this error... Unable to communicate with GitHub.com Reset your modem / router or try again later, or set your to 8.8.8.8 and 8.8.4.4 Also make sure that you have a Gateway address set up (Your Router's IP address) I assume that's the cause of the extended hanging of the scan. Problem is I have shitty satellite internet and it's pretty intermittent, so there's not much I can do to fix this, other than try again. I can't do that while the popup window is displayed though.
-
Squid posted in another thread that FCP will scan for duplicates, which I did not know. I've just done it, and it did find many on my system; which is great. however, the only way to see the results was in the popup window, and the formatting made it quite hard to follow and get to the problem files. Is there/could there be a report/log I could grab to pull into some other program to help format to make it easier to act upon? Also, some of the errors referred to illegal characters, and 3 of my files had ... as the 'character' it seems to have had issue with. I checked in my media program, and it seems I have it entered as 3 dots, not one ellipsis character, so I'm not sure if it's not saving that way, or if the test is flawed. I'm not sure how to 'fix' the issue either way. Otherwise; great job on this test, it helped me clean up a lot of stuff. I'm running again to see what I may have missed on the first pass.




