Hoopster
Members
-
Joined
-
Last visited
Everything posted by Hoopster
-
This is due to the high incidence of counterfeit hardware from China. Stuff on Aliexpress could be genuine or it could be counterfeit junk that may or may not have problems. It's a roll of the dice. They don't advertise with "hey, our prices are so low because this is counterfeit junk" so you never know.
-
Preclear and wipe are not the same. They may both write 0s to every storage sector on the drive (some wipes do not do this) but preclear writes a special signature to the drive that tells Unraid it is precleared and can be added to the array without affecting parity and causing a parity rebuild. If you just wipe a drive, Unraid will preclear it anyway before adding it to the array.
-
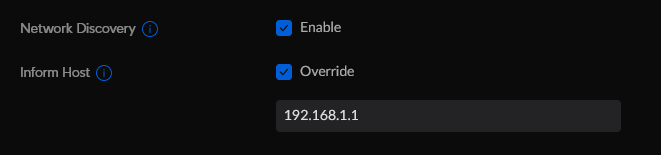
Under network --> System -->Advanced Override IP address is IP address of Unraid server on which Unifi controller container is running. In my case, iIn the example above, it is the IP address of the Unifi device running the network controller software.
-
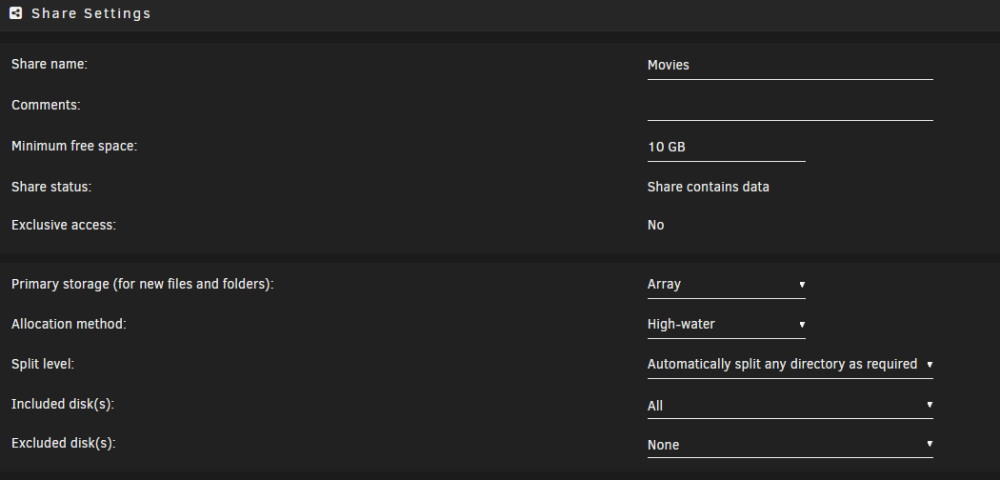
How storage is used is determined by a combination of a number of share settings such as allocation method, split level, minimum free space, included/excluded disks, etc. You should read up on these settings from User Shares section of the linked manual in the bottom right of the GUI.
-
Correct. Unraid supports dual parity (optional) which can protect against the simultaneous loss of two data drives. The USB flash drive holds Unraid files unpacked into RAM o boot, configuration files, and the license. If you setup Plex, it is common to have docker container appdata, VMs etc. on SSDs so no data disks need to be spinning for docker containers/VMs to access their needed configuration files. I actually take it one step further because I had an extra small SSD. I put Plex appdata on its own dedicated SSD. This is certainly not necessary but lets me isolate Plex database/config files for maintenance purposes.
-
Yes. You can add as many data drives as you wish up to 8TB in size since you have an 8TB parity drive. In fact, you are "wasting" space if you just keep adding 4TB drives. A parity rebuild is always going to have to rebuild the full 8TB even if your largest data drive is 4TB. There is no math to add up. The parity drive just has to be as large or larger than the single largest data drive. It does not have to be as large as all the data drives added up. I have one 8TB parity drive that protects five 8TB data drives (40 TB). Parity protects against data loss due to a disk failure but is not a data backup. The Parity drive contains no actual data, it has no filesystem. It is just a bucket of bits of calculated 1s and 0s that represent the data stored in the same location across all data drives. To rebuild a failed data drive, the parity drive plus all other data drives are needed so the rebuild process knows whether to write a 1 or 0 in a particular location on the new data disk. There is a plugin for that. I have never used it so I do not know how well it works.
-
I do this same thing with an NTFS (Windows) formatted drive with the Unassigned Devices plugin I have about 40 TB of Unraid Array storage but I sync the most important files (photos, family videos, some movies, etc.) to an 18TB external drive via unassigned devices. Since it is NTFS, it can be read directly and natively in Windows. APFS (Apple File System) is also supported with the Unassigned Devices Plus plugin. I also have a backup Unraid server and I back up the entire array (well, just the new or modified files) to the backup server once a week via a script in User Scripts
-
It has been mentioned in these forums. I have never used it. Some have it working and it has not worked for others. Can't hurt to see if it works for you, I suppose.
-
Good luck with that. Backblaze and some others will not back up a NAS. To back up a NAS, you have to use their much more expensive B2 service. Some of us use Crashplan Pro for $10 a month unlimited backup. They do not restrict NAS. Look in the Backup section of the Apps tab and see what the available options are for Unraid. Many are just client applications to front-end a cloud-based backup service. The client may be free but you can pay a lot for the cloud backup space.
-
This will not work with plugins but with docker containers (I believe there is one for Tailscale) in the Advanced View in the docker tab you can drag-and-drop containers to change their startup order (they start in order from top to bottom) Set a delay after starting a container before starting the next one in the order I am not sure when VMs start up compared to docker containers but Tailscale as a docker container could be set to be the last one to start with a delay after the container before it.
-
Your server can have a maximum of 64 GB RAM installed but it appears it has only 32 GB installed and it is using all that; 32 GB is the amount being reported to Unraid (system memory). If you believe this is wrong, how much RAM is reported in the BIOS? My server is capable of having 128 GB but has 64 GB installed as seen below.

-
On one of my Unraid servers I have had 4 different motherboards while using the same USB flash drive and configuration. Another server is on its third different motherboard so, yes, swapping the motherboard/CPU/RAM, etc does not impact your setup. The only way in which a motherboard swap could affect setup (assuming you keep the same array hard drives) is if you have virtual machines/docker containers setup with hardware pass through. If that hardware changes, you will need to make changes to your configuration.
-
Probably only if you have one of the following issues: Resolve issues mounting remote SMB shares via the Unassigned Devices plugin. Resolve issues with certain Asmedia controllers not seeing all the attached devices. nfs: (revert) NFSv4 mounts by default zfs: Detect if insufficient pools slots are defined for an imported pool with a missing device. Fix translations issue with SystemDrivers I had no issues with 6.12.9 either but there was some reason they rolled back to a prior kernel version. I updated just in case other issues were found with the kernel in 6.12.9.
-
Three servers updated to 6.12.10. No issues observed so far but I had none of the reported issues with 6.12.9.
-
Oh, she expects a lot more. I certainly have a long "honey-do" list. I am on the kitchen remodel item right now. Those are just the two things she figures she would never want to deal with (or pay someone else to do) if she had to. With me around she does not have to.
-
My wife has said more than once she married me for only two reasons: To kill bugs and spiders in the house To handle all AV equipment/technology in the house Both are still accurate 43 years later.
-
Glad to hear you found the issue and your parity rebuild is progressing normally. FYI, towards the end it will typically start to slow down quite a bit as it reaches the inner tracks of the drives. Still, roughly 2 hrs. a TB, perhaps just a a bit more, it typical with larger drives.
-
Yes, /mnt/user path uses the fuse system Yes, mnt/user/xxxx is just the contents of all top-level folders of a particular name across all disks
-
No, this is not what Turbo Write does. It is mainly useful to speed up parity writes, but since you have no parity, it will give you no increased speed. Here is a more detailed description of turbo write. Turbo write has no impact on writing data to the array disks, just parity.
-
I had the wrong link when I first posted the reply. It is corrected now in original post if you did not see direct link to manual method.
-
Often, flash devices that show as incompatible in the Flash Creator can be successfully used with the manual installation method.
-
Very nice build. I had never considered that case for a small build, I usually go with the Fractal Node 304, but it looks nice. Perhaps I will try a build in the Jonsbo N2 some day.
-
No, not normal. My 8TB parity takes a little over 16 hours to build. A reasonable rough estimate is about 2 hours per TB. Your 12TB parity should rebuild in approximately 24 hours if everythng with your server is as it should be. Clearly, there are some problems. You can use your server during rebuild altough that can slow down the rebuild depending on how heavy the use. You should minimize the use. Another option is to use the Parity Check Tuning plugin and spread a parity build over several low-use periods such as at night. I typically do my rebuild in two roughly 8-hour (midnight to 8am) sessions.
-
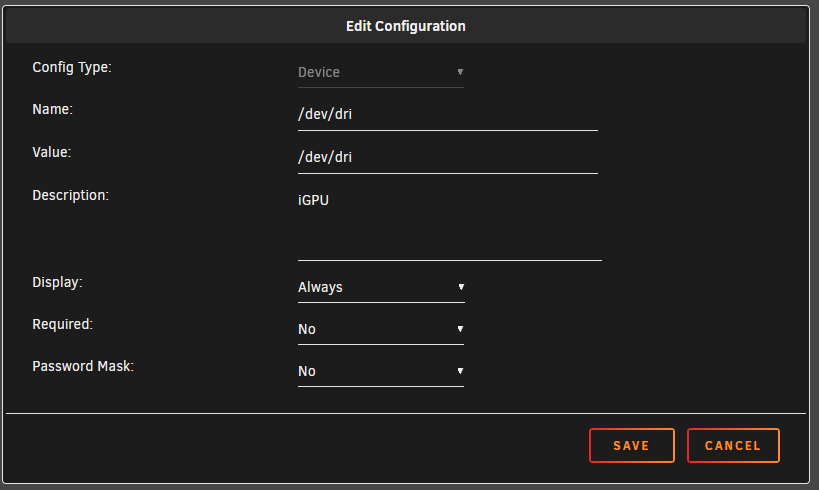
How are you passing /dev/dri to Plex container? It appears from what you are saying that /dev/dri exists but is not being used by your Plex docker container. Are you putting ---device /dev/dri:/dev/dri in the Extra Parameters line of the container config? (may depend on Plex container you are using) Or are you adding it as a device like this? I have used both methods but I am currently using the second (device configuration) method. I am using the Linuxserver version of the Plex docker so, perhaps whatever you are using may have slightly different configuration options. Do you see these checkboxes in the Plex Transcoder configuration? if you see these and can select them, that usually means you have an active Plex Pass.


-
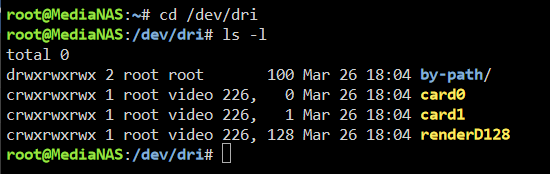
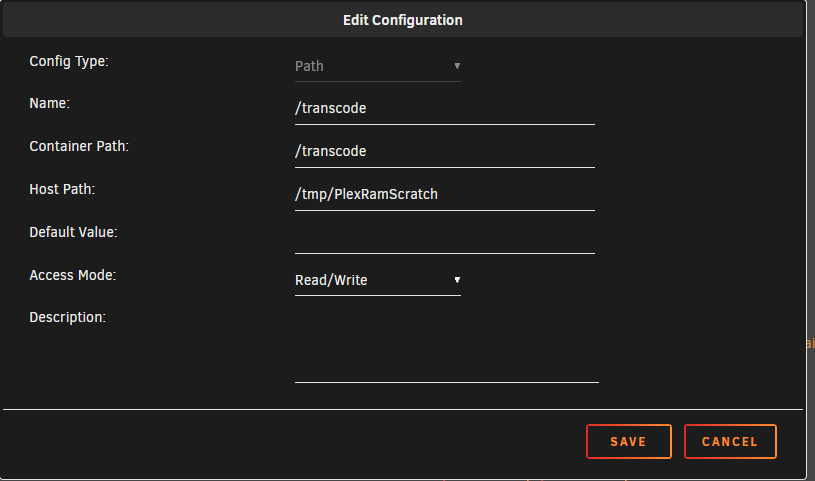
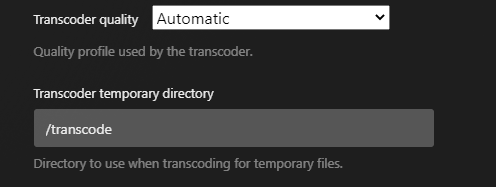
You make the assumption this has something to do with Unraid. The only thing Unraid has to do with Plex transcoding is loading the i915 drivers. On some motherboard BIOS (I am not familiar with yours), the primary graphics adapter must be set to the iGPU. If set to Auto, the i915 drivers will not load. Every once in a while Plex breaks transcoding. I just tested it with Unraid 6.12.9 and Plex and transcoding is working properly for me. - It is unclear exactly which Plex docker container you have installed. There are several in Apps. Which one are you using? I assume much of this is setup correctly or you would not get CPU transcoding. - Have you verified that i915 drivers are active and that /dev/dri is being created with the proper contents? Should look similar to image below (don't worry if card1 is missing). Passing /dev/dri as a device does nothing if no /dev/dri and its contents exist. - What does your docker run command look like? Any errors? - Have you set up a transcode path in Plex docker config and are you using it in Plex configuration? Mine looks like this as I am transcoding in RAM In Plex config: if all of this is setup properly, Plex should hardware (iGPU) transcode media that is not in a format that can direct play in the client.