




iilied
Members
-
Joined
-
Last visited
Everything posted by iilied
-
hello everyone, so after an abrupt shutdown caused power outage, the server became unavailable after starting the docker. and after uninstalling/reinstalling now it created a new server that is empty (as shown in the middle in screenshot below). how can i delete this newly created one (middle), and get the old one (top with lists of libraries) running again?
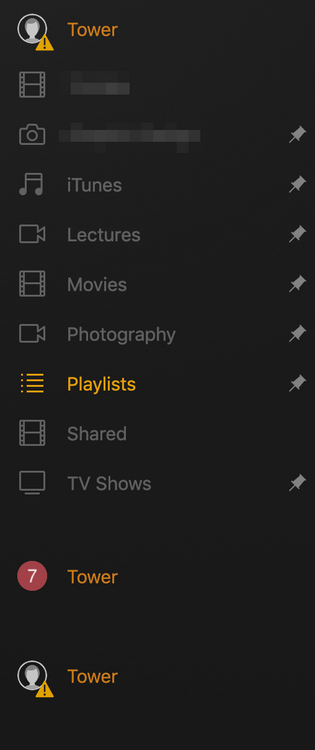
-
the server is unable to add any docker correctly. however i try to add any docker app, the name of the docker changes to VNCWebBrowser! i have no idea how to fix it.
-
still the same, and even after updating os, docker apps started to disappear after updating them. tower-diagnostics-20240220-1743.zip
-
Hello, Recently, and I’m not sure if it’s related to the main issue, I have noticed the docker utilization percentage has been higher than usual. After powering up the system, it lasts for few hours then the connection drops and the WebUI stops working and unable to ssh into. Though the server remains powered up! Unsure about to tackle this issue or where to start. Would appreciate any leads. Thanks tower-diagnostics-20240213-2336.zip
-
i'm having the same issue, but i'm on version 6.8.3 and getting use_ssl: command not found. is there another way around it?
-
hello, was rebuilding a disk and cache 1 dropped offline then went online again, and since the log is listing errors: Jul 24 06:24:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 0 off 1031746809856 (dev /dev/sdc1 sector 6058872) Jul 24 06:24:00 Tower kernel: BTRFS error (device sdc1): parent transid verify failed on 1031702478848 wanted 24394769 found 24380501 Jul 24 06:24:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 0 off 1031702478848 (dev /dev/sdc1 sector 5972288) Jul 24 06:24:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 0 off 1031702482944 (dev /dev/sdc1 sector 5972296) Jul 24 06:24:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 0 off 1031702487040 (dev /dev/sdc1 sector 5972304) Jul 24 06:24:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 0 off 1031702491136 (dev /dev/sdc1 sector 5972312) Jul 24 06:24:00 Tower kernel: BTRFS error (device sdc1): parent transid verify failed on 1031746781184 wanted 24394898 found 24380677 Jul 24 06:24:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 0 off 1031746781184 (dev /dev/sdc1 sector 6058816) Jul 24 06:24:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 0 off 1031746785280 (dev /dev/sdc1 sector 6058824) Jul 24 06:24:00 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 29528623 off 70361088 csum 0x06a1d7ca expected csum 0x71a37def mirror 2 Jul 24 06:24:00 Tower kernel: BTRFS error (device sdc1): parent transid verify failed on 1031236435968 wanted 24393467 found 24378723 Jul 24 06:25:00 Tower kernel: BTRFS error (device sdc1): parent transid verify failed on 1031702462464 wanted 24394769 found 24380501 Jul 24 06:25:00 Tower kernel: repair_io_failure: 7 callbacks suppressed Jul 24 06:25:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 0 off 1031702462464 (dev /dev/sdc1 sector 5972256) Jul 24 06:25:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 0 off 1031702466560 (dev /dev/sdc1 sector 5972264) Jul 24 06:25:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 0 off 1031702470656 (dev /dev/sdc1 sector 5972272) Jul 24 06:25:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 0 off 1031702474752 (dev /dev/sdc1 sector 5972280) Jul 24 06:25:03 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 33750182 off 8265728 csum 0x98f94189 expected csum 0x7ca57398 mirror 2 Jul 24 06:25:03 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 33750182 off 8265728 (dev /dev/sdc1 sector 132894080) Jul 24 06:25:03 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 33750182 off 8503296 csum 0x98f94189 expected csum 0x78909ff8 mirror 2 Jul 24 06:25:03 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 33750182 off 8503296 (dev /dev/sdc1 sector 132894544) Jul 24 06:25:18 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 33750182 off 8282112 csum 0x98f94189 expected csum 0x190b460d mirror 2 Jul 24 06:25:18 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 33750182 off 8282112 (dev /dev/sdc1 sector 132894112) Jul 24 06:26:00 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 29528623 off 39731200 csum 0xb74044e9 expected csum 0xae6e14c9 mirror 2 Jul 24 06:26:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 29528623 off 39731200 (dev /dev/sdc1 sector 92317816) Jul 24 06:28:00 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 29528623 off 26374144 csum 0x98f94189 expected csum 0x42f382f4 mirror 2 Jul 24 06:28:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 29528623 off 26374144 (dev /dev/sdc1 sector 175102552) Jul 24 06:28:00 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 29528623 off 1466368 csum 0x31453955 expected csum 0x0a8d7f8c mirror 2 Jul 24 06:28:00 Tower kernel: BTRFS info (device sdc1): read error corrected: ino 29528623 off 1466368 (dev /dev/sdc1 sector 174960776) how to go about this? thanks tower-diagnostics-20220724-0626.zip
-
sata cable change and went through rebuilding process smoothly. thanks
-
no, but turning the privilege on fixed it for me.
-
Hello, Disk 2 was disabled for 2 errors, went with the rebuilding process per this wiki, but step no. 6 is not working, as when the same drive is selected it disappears from the option list and does not show up to be selected again nor it gets reassigned to the slot. I hope this explanation make sense. Unsure about the next step. I have shutdown the server, and I will be rechecking the sata cables. Attached is diagnostics prior shutdown. Appreciated tower-diagnostics-20220604-1135.zip
-
@realies after the last docker update, docker doesn’t fire up anymore. 2022-05-26 13:07:47,706 INFO Set uid to user 1000 succeeded 2022-05-26 13:07:47,711 INFO supervisord started with pid 25 2022-05-26 13:07:48,714 INFO spawned: 'tigervnc' with pid 26 2022-05-26 13:07:48,719 INFO spawned: 'openbox' with pid 27 2022-05-26 13:07:48,724 INFO spawned: 'novnc' with pid 28 2022-05-26 13:07:48,728 INFO spawned: 'soulseek' with pid 29 2022-05-26 13:07:49,078 INFO exited: novnc (exit status 1; not expected) 2022-05-26 13:07:50,526 INFO success: tigervnc entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-05-26 13:07:50,526 INFO success: openbox entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-05-26 13:07:50,535 INFO spawned: 'novnc' with pid 37 2022-05-26 13:07:50,536 INFO success: soulseek entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-05-26 13:07:50,648 INFO exited: novnc (exit status 1; not expected) 2022-05-26 13:07:51,764 INFO exited: openbox (terminated by SIGABRT; not expected) 2022-05-26 13:07:52,767 INFO spawned: 'openbox' with pid 47 2022-05-26 13:07:52,769 INFO spawned: 'novnc' with pid 48 2022-05-26 13:07:52,790 INFO exited: novnc (exit status 1; not expected) 2022-05-26 13:07:52,823 INFO exited: openbox (terminated by SIGABRT; not expected) 2022-05-26 13:07:53,826 INFO spawned: 'openbox' with pid 56 2022-05-26 13:07:53,867 INFO exited: openbox (terminated by SIGABRT; not expected) 2022-05-26 13:07:55,871 INFO spawned: 'openbox' with pid 57 2022-05-26 13:07:55,873 INFO spawned: 'novnc' with pid 58 2022-05-26 13:07:55,926 INFO exited: novnc (exit status 1; not expected) 2022-05-26 13:07:55,926 INFO gave up: novnc entered FATAL state, too many start retries too quickly 2022-05-26 13:07:56,943 INFO success: openbox entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-05-26 13:07:56,944 INFO exited: openbox (terminated by SIGABRT; not expected) 2022-05-26 13:07:57,947 INFO spawned: 'openbox' with pid 66 2022-05-26 13:07:57,984 INFO exited: openbox (terminated by SIGABRT; not expected) 2022-05-26 13:07:58,987 INFO spawned: 'openbox' with pid 67 2022-05-26 13:07:59,024 INFO exited: openbox (terminated by SIGABRT; not expected) 2022-05-26 13:08:01,028 INFO spawned: 'openbox' with pid 68 2022-05-26 13:08:01,066 INFO exited: openbox (terminated by SIGABRT; not expected) 2022-05-26 13:08:04,071 INFO spawned: 'openbox' with pid 69 2022-05-26 13:08:04,108 INFO exited: openbox (terminated by SIGABRT; not expected) 2022-05-26 13:08:05,109 INFO gave up: openbox entered FATAL state, too many start retries too quickly
-
been getting these errors since the last update. not exactly sure what is causing.
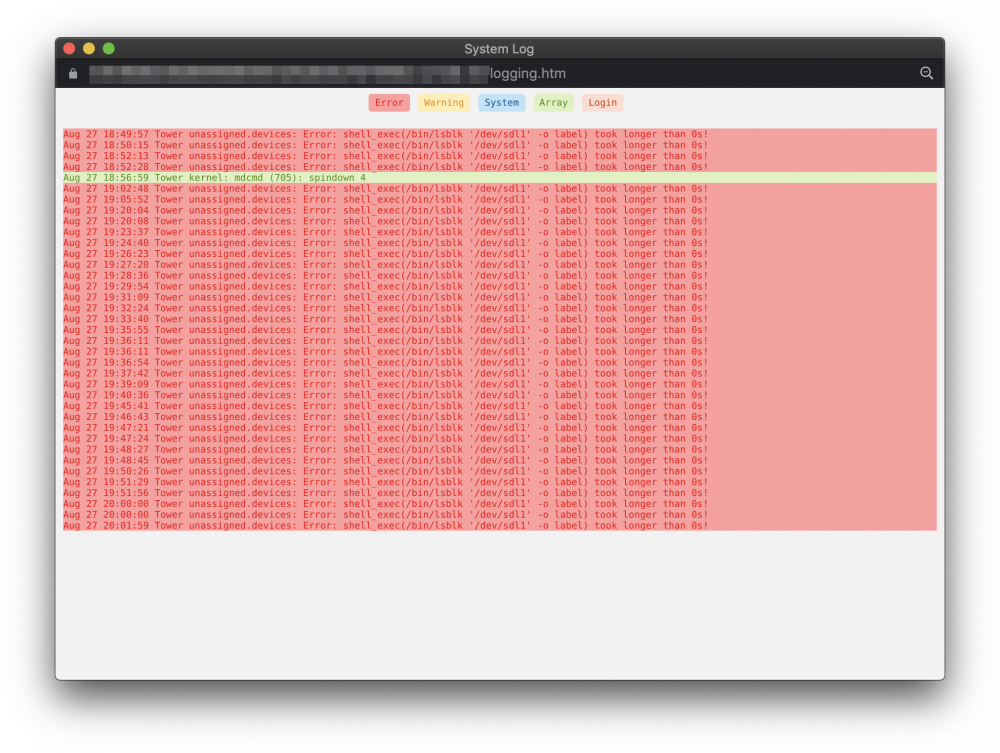
-
cheers @HyperV
-
server has been running for 88 days w/o issues (version 6.8.3), but all of a sudden now it lists “not available” in the docker containers tap. tried forcing update on multiple containers, and stoping and starting the array, to no avail. first time facing this issue and not quite sure a restart would fix this, or where to start. tower-diagnostics-20210514-0713.zip

-
tried this, unfortunately didn’t work. don’t know where to start to solve this.
-
I am not getting a handshake from WireGuard client on macOS. Used to be able to connect no problem, is there a common issue occurring atm after the latest client update? Edit: Regenerated keys and tried to reconnect, still same issue. Able to connect, no data, no handshake. No idea what to do next. Used to work smoothly, unfortunately, not anymore.
-
it’s an external drive connected through the back-port usb directly. used as time machine backup, using spaceoneinvader method. i rarely disconnect it, so usually is it connected all the time.
-
it happened again. disconnected and reconnected, and another letter assigned is assigned, that’s very strange. Jul 28 03:20:46 Tower unassigned.devices: Adding disk '/dev/sdm1'... Jul 28 03:20:46 Tower unassigned.devices: Mount drive command: /sbin/mount -t xfs -o rw,noatime,nodiratime '/dev/sdm1' '/mnt/disks/ST9500325AS_6VE5Z84R' Jul 28 03:20:46 Tower kernel: XFS (sdm1): Filesystem has duplicate UUID c0baa833-15ad-41c1-b008-93d89164b138 - can't mount Jul 28 03:20:46 Tower unassigned.devices: Mount of '/dev/sdm1' failed. Error message: mount: /mnt/disks/ST9500325AS_6VE5Z84R: wrong fs type, bad option, bad superblock on /dev/sdm1, missing codepage or helper program, or other error. and it doesn’t unmount. Jul 28 03:36:53 Tower unassigned.devices: Issue spin down timer for device '/dev/sdm'. Jul 28 03:36:53 Tower unassigned.devices: Unmounting '/dev/sdm1'... Jul 28 03:36:53 Tower unassigned.devices: Unmount cmd: /sbin/umount '/dev/sdm1' 2>&1 Jul 28 03:36:53 Tower unassigned.devices: Unmount of '/dev/sdm1' failed. Error message: umount: /mnt/disks/ST9500325AS_6VE5Z84R: target is busy. now this too. Jul 28 10:54:58 Tower unassigned.devices: Adding disk '/dev/sdn1'... Jul 28 10:54:58 Tower unassigned.devices: Mount drive command: /sbin/mount -t xfs -o rw,noatime,nodiratime '/dev/sdn1' '/mnt/disks/ST9500325AS_6VE5Z84R' Jul 28 10:54:58 Tower kernel: XFS (sdn1): Filesystem has duplicate UUID 82f7e126-d6cb-4146-a545-0c51fbe8f1fa - can't mount Jul 28 10:54:58 Tower unassigned.devices: Mount of '/dev/sdn1' failed. Error message: mount: /mnt/disks/ST9500325AS_6VE5Z84R: wrong fs type, bad option, bad superblock on /dev/sdn1, missing codepage or helper program, or other error.
-
I’m having the same issue, Jul 27 09:46:19 Tower unassigned.devices: Adding disk '/dev/sdl1'... Jul 27 09:46:19 Tower unassigned.devices: Mount drive command: /sbin/mount -t xfs -o rw,noatime,nodiratime '/dev/sdl1' '/mnt/disks/ST9500325AS_6VE5Z84R' Jul 27 09:46:19 Tower kernel: XFS (sdl1): Filesystem has duplicate UUID 20345907-1be5-47e5-9722-00ca8c644885 - can't mount Jul 27 09:46:20 Tower unassigned.devices: Mount of '/dev/sdl1' failed. Error message: mount: /mnt/disks/ST9500325AS_6VE5Z84R: wrong fs type, bad option, bad superblock on /dev/sdl1, missing codepage or helper program, or other error. Jul 27 09:46:20 Tower unassigned.devices: Partition 'ST9500325AS_6VE5Z84R' could not be mounted. Jul 27 09:47:36 Tower unassigned.devices: Changing disk '/dev/sdl1' UUID. Result: ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_admin. If you are unable to mount the filesystem, then use the xfs_repair -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. drive was working perfectly before. no idea what to do next. could anyone offer their help, please? edit: ran xfs_repair -L then xfs_admin -U generate and all is good.
-
somehow, i slept on this, thinking it’s been done already. cheers for reminding me.
-
anyone here can please point me to how to set up the server to be accessed remotely?
-
you can start with the following: dockers > add container > (see below) and then hit apply. you‘ll see it with other containers on the main page. keep in mind there are some issues in regards to folder privilege and other aforementioned problems. but this is a good place to start.
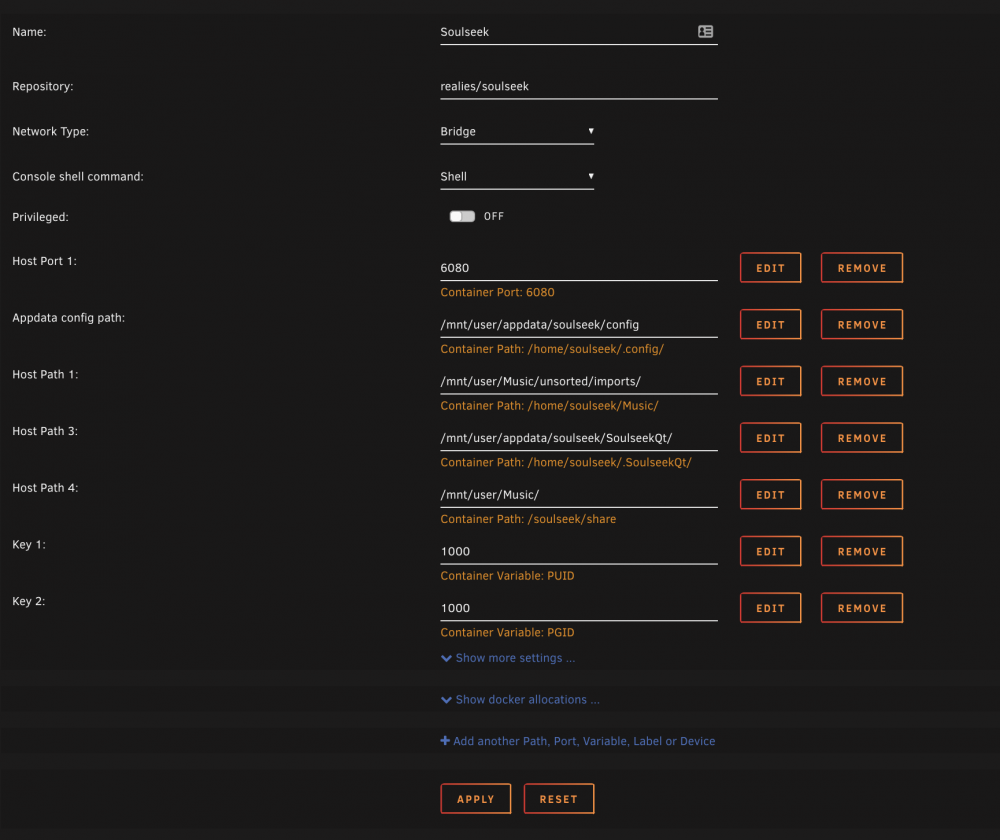
-
cheers for pushing the new update, but i don't see any changes regarding the ownership of the files even after adding key variables. also, soulseek settings are maintained as long as i don't edit the docker‘s template. any edit on the template, soulseek loses all configurations and have to resort to importing last saved config data and re-login. like mentioned before, the appdata config path appears to be empty.
-
whenever changing the dockers template soulseek loses its configurations, any idea why is that happening and how to go about fixing it? it doesn't seem to save anything on /appdata folder either.
-
system temp does not detect motherboard's (prime x470-pro) sensors when pressed, and yes perl is installed via nerd pack. any idea why?
-
fantastic, gonna give it a try. btw, read that using displayport instead gives you sound! any luck with that? don't have dp cable myself to try it atm. edit: also, if you have any idea about this, could you mirror screen using airplay and get sound with roccat juke and gpu?




