





frakman1
Community Developer
-
Joined
-
Last visited
Everything posted by frakman1
-
@ZappyZap Does this app support SSH logins using a signed certificate? In addition to the usual SSH public and private keys, I need to present a signed public key to my target. private key: id_ed25519 public key: id_ed25519.pub signed certificate: id_ed25519-cert.pub This uses ssh's "-o CertificateFile=id_ed25519-cert.pub" syntax.
-
Currently, appdata is primarily stored on the cache drive but gets moved to the array by the Mover once a day at 3:40 AM. So, files are still initially written to the cache. If your app, rradio, requires writing to the temp directory on the cache for stability, that's already in place. However, keeping everything in appdata exclusively on the cache isn't ideal. It wouldn’t benefit from the redundancy and backup features of the Unraid array, which is a key advantage of using Unraid for storage. It looks like our setups differ too much for this to be a workable solution for me. I appreciate your assistance, but I'll explore other options. Thank you again for your help!
-
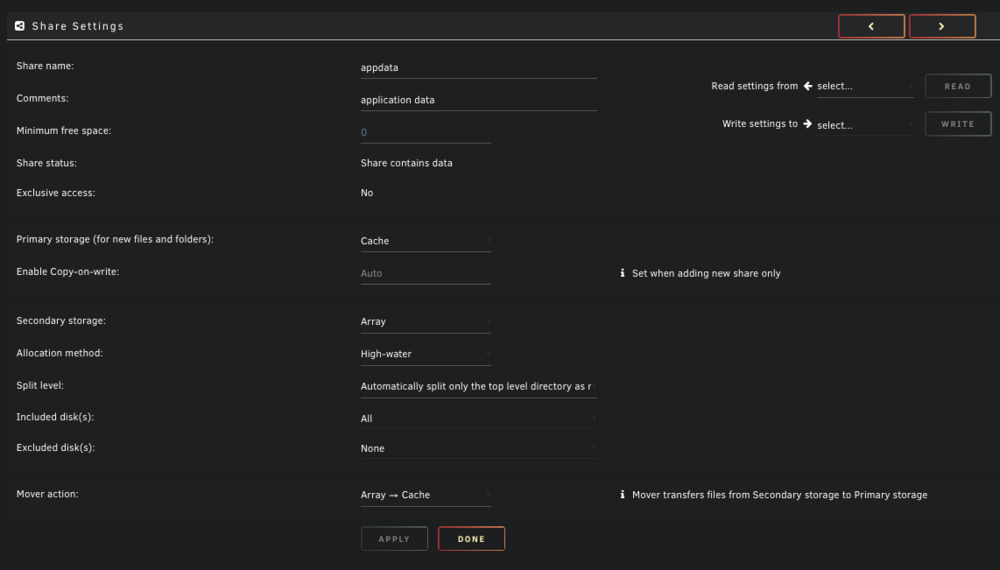
i just checked again and it looks like it's already using Cache as the primary storage despite residing in /mnt/user/appdata
-
It seems that the rradio app currently expects appdata to be on the cache drive for it to function properly, but since this isn't the default for Unraid, it may not align with everyone's setup. Many users, including myself, have various apps like Plex, working smoothly with appdata in its current location. Would it be possible to adjust the app so that we can map the temp folder to a different location, such as the cache drive? I attempted to volume mount the container's temp folder, but it seems to be tied to the appdata folder, which caused the change to fail.
-
It looks like my logs didn't paste correctly. I just put it back in my previous post. I can see all 3 recordings attempted. I don't know what this error means: 2024-10-04 06:00:30 [ERROR] (Object reference not set to an instance of an object.-) app data is in: /mnt/user/appdata/rradio
-
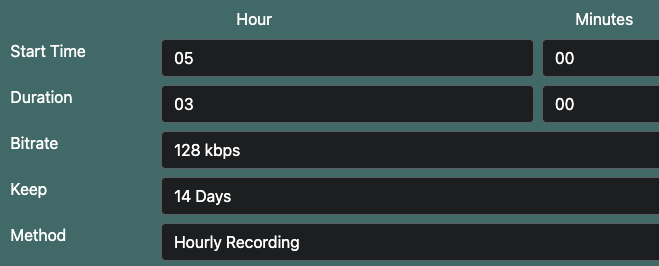
Thank you for the feedback and tips. I deleted everything and started over using the MP3 stream URL that had worked perfectly for me when using the vlc command line to capture recordings in the past. It's also low bandwidth so should be less taxing or demanding on the system and less likely to fail. I created a new recording schedule every day for 3 hours starting at 5AM and used the Hourly instead of Continuous option The logs indicated that two of the three 1 hour recordings completed successfully. The middle hour is missing. 2024-10-04 05:00:10 [INFO] (Executing job 1-1) 2024-10-04 05:00:10 [INFO] (Job registered: False.) 2024-10-04 05:00:10 [INFO] (Setting up recording LBC - James O'Brien) 2024-10-04 05:00:10 [INFO] (Creating recording task) 2024-10-04 05:00:10 [INFO] (Recording stream) 2024-10-04 05:00:10 [INFO] (Job sent to ffmpeg recording engine) 2024-10-04 05:00:10 [INFO] (Arguments: -i "http://media-ice.musicradio.com/LBCLondonMP3Low" -c copy -t 3600 -metadata Title="LBC - James O'Brien (10.04.24 Fri. 05:00)" -metadata Album="James O'Brien" -metadata Artist="LBC" -metadata Track="1004" -metadata Album_Artist="LBC" -metadata Year="2024" -metadata Genre="Radio" -metadata Comments="LBC_James_O_Brien_(2024-10-04_05.00.10_Friday)" -c:a libmp3lame -ab 128k -y "/app/config/temp/LBC_James_O_Brien_(2024-10-04_05.00.10_Friday).mp3".) 2024-10-04 05:30:10 [INFO] (Executing job 1-1) 2024-10-04 05:30:10 [INFO] (Job registered: True.) 2024-10-04 05:30:10 [INFO] (Aborting) 2024-10-04 05:59:56 [INFO] (Parsing metadata) 2024-10-04 05:59:56 [INFO] (ffmpeg exit code 0) 2024-10-04 05:59:56 [INFO] (File recorded LBC_James_O_Brien_(2024-10-04_05.00.10_Friday).mp3) 2024-10-04 05:59:56 [INFO] (Updating job register) 2024-10-04 05:59:56 [INFO] (Moving recorded file from temp folder to media folder) 2024-10-04 05:59:56 [INFO] (Generating audio feed) 2024-10-04 05:59:56 [INFO] (Job 1-1 completed) 2024-10-04 06:00:10 [INFO] (Executing job 1-2) 2024-10-04 06:00:10 [INFO] (Job registered: False.) 2024-10-04 06:00:10 [INFO] (Setting up recording LBC - James O'Brien) 2024-10-04 06:00:10 [INFO] (Creating recording task) 2024-10-04 06:00:10 [INFO] (Recording stream) 2024-10-04 06:00:10 [INFO] (Job sent to ffmpeg recording engine) 2024-10-04 06:00:10 [INFO] (Arguments: -i "http://media-ice.musicradio.com/LBCLondonMP3Low" -c copy -t 3600 -metadata Title="LBC - James O'Brien (10.04.24 Fri. 06:00)" -metadata Album="James O'Brien" -metadata Artist="LBC" -metadata Track="1004" -metadata Album_Artist="LBC" -metadata Year="2024" -metadata Genre="Radio" -metadata Comments="LBC_James_O_Brien_(2024-10-04_06.00.10_Friday)" -c:a libmp3lame -ab 128k -y "/app/config/temp/LBC_James_O_Brien_(2024-10-04_06.00.10_Friday).mp3".) 2024-10-04 06:00:30 [INFO] (Parsing metadata) 2024-10-04 06:00:30 [ERROR] (Object reference not set to an instance of an object.-) 2024-10-04 07:00:10 [INFO] (Executing job 1-3) 2024-10-04 07:00:10 [INFO] (Job registered: False.) 2024-10-04 07:00:10 [INFO] (Setting up recording LBC - James O'Brien) 2024-10-04 07:00:10 [INFO] (Creating recording task) 2024-10-04 07:00:10 [INFO] (Recording stream) 2024-10-04 07:00:10 [INFO] (Job sent to ffmpeg recording engine) 2024-10-04 07:00:10 [INFO] (Arguments: -i "http://media-ice.musicradio.com/LBCLondonMP3Low" -c copy -t 3600 -metadata Title="LBC - James O'Brien (10.04.24 Fri. 07:00)" -metadata Album="James O'Brien" -metadata Artist="LBC" -metadata Track="1004" -metadata Album_Artist="LBC" -metadata Year="2024" -metadata Genre="Radio" -metadata Comments="LBC_James_O_Brien_(2024-10-04_07.00.10_Friday)" -c:a libmp3lame -ab 128k -y "/app/config/temp/LBC_James_O_Brien_(2024-10-04_07.00.10_Friday).mp3".) 2024-10-04 07:30:10 [INFO] (Executing job 1-3) 2024-10-04 07:30:10 [INFO] (Job registered: True.) 2024-10-04 07:30:10 [INFO] (Aborting) 2024-10-04 07:59:57 [INFO] (Parsing metadata) 2024-10-04 07:59:57 [INFO] (ffmpeg exit code 0) 2024-10-04 07:59:57 [INFO] (File recorded LBC_James_O_Brien_(2024-10-04_07.00.10_Friday).mp3) 2024-10-04 07:59:57 [INFO] (Updating job register) 2024-10-04 07:59:57 [INFO] (Moving recorded file from temp folder to media folder) 2024-10-04 07:59:57 [INFO] (Generating audio feed) 2024-10-04 07:59:57 [INFO] (Job 1-3 completed) When I checked the folders manually, I see only two recordings: root@bf4d254a14f5:/media# ls -lasth total 110M 0 drwxrwxrwx 1 99 users 200 Oct 4 07:59 . 55M -rw-r--r-- 1 root root 55M Oct 4 07:59 'LBC_James_O_Brien_(2024-10-04_07.00.10_Friday).mp3' 55M -rw-r--r-- 1 root root 55M Oct 4 05:59 'LBC_James_O_Brien_(2024-10-04_05.00.10_Friday).mp3' 0 drwxr-xr-x 1 root root 170 Oct 3 19:11 .. 0 lrwxrwxrwx 1 root root 6 Oct 1 17:16 media -> /media root@bf4d254a14f5:/media# ls -lasth /app/config/temp total 0 0 drwxr-xr-x 1 root root 0 Oct 4 13:27 . 0 drwxr-xr-x 1 99 users 192 Oct 1 17:16 .. root@bf4d254a14f5:/media#
-
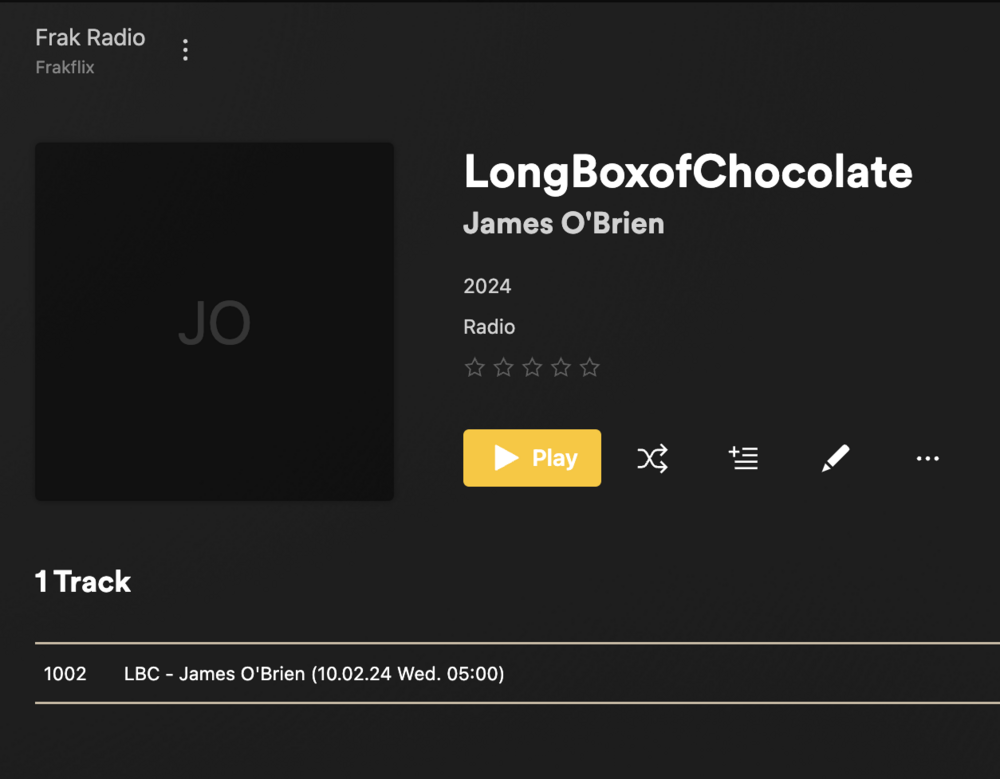
I tried to setup a scheduled recording and although it starts on time, it aborts and never completes. There is no log in the WebUI, but I found this in the container logs: 2024-10-03 05:00:07 [INFO] (Executing job 0-1) 2024-10-03 05:00:07 [INFO] (Job registered: False.) 2024-10-03 05:00:07 [INFO] (Setting up recording LBC - James O'Brien) 2024-10-03 05:00:07 [INFO] (Creating recording task) 2024-10-03 05:00:07 [INFO] (Recording stream) 2024-10-03 05:00:07 [INFO] (Job sent to ffmpeg recording engine) 2024-10-03 05:00:07 [INFO] (Arguments: -i "http://media-ice.musicradio.com/LBCUK" -c copy -t 10800 -metadata Title="LBC - James O'Brien (10.03.24 Thu. 05:00)" -metadata Album="James O'Brien" -metadata Artist="LBC" -metadata Track="1003" -metadata Album_Artist="LBC" -metadata Year="2024" -metadata Genre="Radio" -metadata Comments="LBC_James_O_Brien_(2024-10-03_05.00.07_Thursday)" -c:a libmp3lame -ab 128k -y "/app/config/temp/LBC_James_O_Brien_(2024-10-03_05.00.07_Thursday).mp3".) 2024-10-03 05:30:07 [INFO] (Executing job 0-1) 2024-10-03 05:30:07 [INFO] (Job registered: True.) 2024-10-03 05:30:07 [INFO] (Aborting) [] The container's temp folder appears to contain part of the file. root@ca8a057756f6:/app# ls -lasth /app/config/temp total 123M 55M -rw-r--r-- 1 root root 55M Oct 3 05:59 'LBC_James_O_Brien_(2024-10-03_05.00.07_Thursday).mp3' 0 drwxr-xr-x 1 root root 244 Oct 3 05:00 . I have it set to record for 3 hours. Could that be too long? Is there anyway to get more insight as to why it Aborted? More verbose logs? When I tried a short 2 minute test, that seemed to work. Strangely enough, when I move the mp3 from temp to media and into Plex (the rradio media folder is mapped into my Plex library folder), it always has the strange name "LongBoxofChocolate" Perhaps Plex is auto looking up LBC?
-
SSL/TLS is now supported in Unraid but is off by default. You can turn it on by going to Settings > Management Access and changing Use SSL/TLS to Yes. See screenshot for more details:
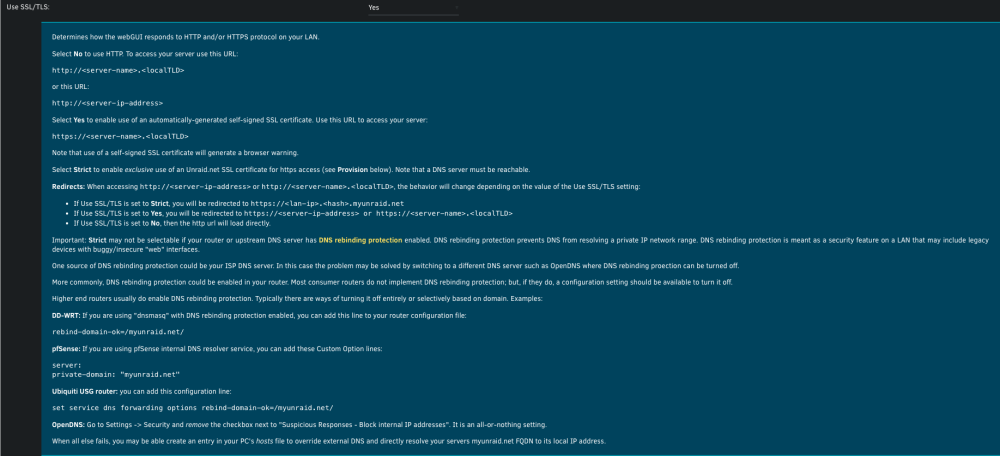
-
@thenhz @Tucubanito07 @Northwave Author of the frak-gvm template here (not the actual container). Sorry for pointing the support page to here. I think it was my first template and I didn't have a page on the forum to point it to, or perhaps I started with the nessus template and inherited by accident. Either way, sorry for the confusion. As I recall, the OpenVAS/GVM container takes a really long time to come up the first time as it downloads a ton of NVTs and other databases from the web. After it's done, it should come up. Just be patient and monitor the logs. It spends most of the time in the 'Updating xxx' lines then finally goes to: Your GVM 11 container is now ready to use! 9:C 14 Mar 2024 13:23:34.863 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 9:C 14 Mar 2024 13:23:34.863 # Redis version=5.0.7, bits=64, commit=00000000, modified=0, pid=9, just started 9:C 14 Mar 2024 13:23:34.863 # Configuration loaded Wait for redis socket to be created... Testing redis status... Redis ready. Starting PostgreSQL... waiting for server to start....2024-03-14 13:23:35.963 EDT [21] LOG: starting PostgreSQL 12.3 (Ubuntu 12.3-1.pgdg20.04+1) on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 9.3.0-10ubuntu2) 9.3.0, 64-bit 2024-03-14 13:23:35.964 EDT [21] LOG: listening on IPv4 address "127.0.0.1", port 5432 2024-03-14 13:23:35.964 EDT [21] LOG: could not bind IPv6 address "::1": Cannot assign requested address 2024-03-14 13:23:35.964 EDT [21] HINT: Is another postmaster already running on port 5432? If not, wait a few seconds and retry. 2024-03-14 13:23:35.983 EDT [21] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432" 2024-03-14 13:23:36.016 EDT [22] LOG: database system was interrupted; last known up at 2024-03-14 13:20:10 EDT ............2024-03-14 13:23:48.242 EDT [22] LOG: database system was not properly shut down; automatic recovery in progress 2024-03-14 13:23:48.249 EDT [22] LOG: redo starts at 6/AFF8A7C8 ...2024-03-14 13:23:51.958 EDT [22] LOG: invalid record length at 6/C435B610: wanted 24, got 0 2024-03-14 13:23:51.958 EDT [22] LOG: redo done at 6/C435AEA8 ....2024-03-14 13:23:55.066 EDT [21] LOG: database system is ready to accept connections done server started Updating NVTs... Updating CERT data... 2024-03-14 13:24:55.160 EDT [43] LOG: autovacuum: dropping orphan temp table "gvmd.pg_temp_5.current_credentials" rsync: failed to connect to feed.openvas.org (89.146.224.58): Connection timed out (110) rsync: failed to connect to feed.openvas.org (2a01:130:2000:127::d1): Cannot assign requested address (99) rsync error: error in socket IO (code 10) at clientserver.c(127) [Receiver=3.1.3] Updating SCAP data... rsync: failed to connect to feed.openvas.org (89.146.224.58): Connection timed out (110) rsync: failed to connect to feed.openvas.org (2a01:130:2000:127::d1): Cannot assign requested address (99) rsync error: error in socket IO (code 10) at clientserver.c(127) [Receiver=3.1.3] Starting Open Scanner Protocol daemon for OpenVAS... Starting Greenbone Vulnerability Manager... admin Starting Greenbone Security Assistant... Oops, secure memory pool already initialized Starting OpenSSH Server... ++++++++++++++++++++++++++++++++++++++++++++++ + Your GVM 11 container is now ready to use! + ++++++++++++++++++++++++++++++++++++++++++++++ I would also monitor the output of: netstat -tulpn | grep LISTEN and look for the 9392 port which corresponds to the Web UI port. When it finally completes, the output of that command should look like this: root@e2885647614f:/# netstat -tulpn | grep LISTEN tcp 0 0 0.0.0.0:9390 0.0.0.0:* LISTEN - tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 10/redis-server 0.0 tcp 0 0 127.0.0.11:32801 0.0.0.0:* LISTEN - tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 379/sshd: /usr/sbin tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN - tcp6 0 0 :::9392 :::* LISTEN - tcp6 0 0 :::22 :::* LISTEN 379/sshd: /usr/sbin Pointing the browser to <ip-address>:9392 should look like this:
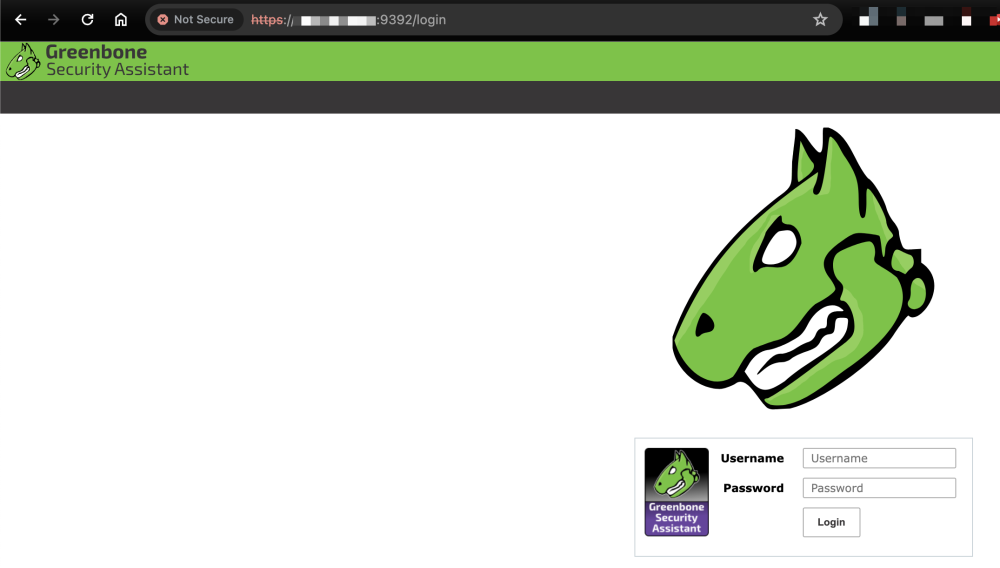
-
Thanks. I will try and get some logs but it's good to know which driver to use now.
-
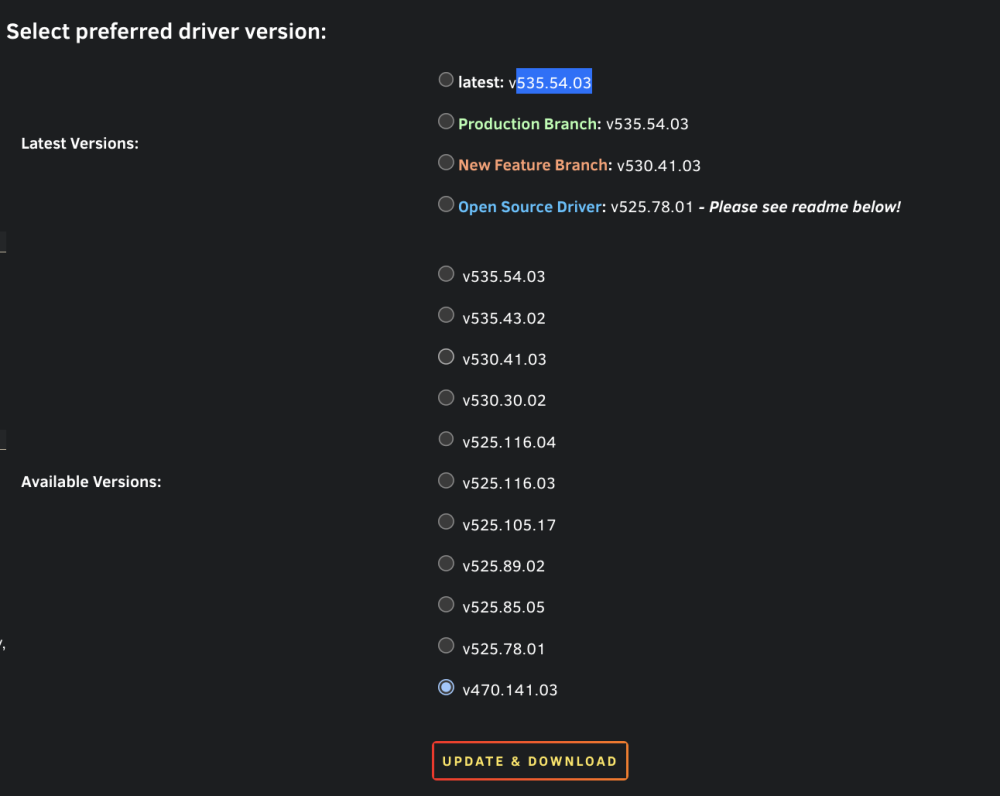
I have the Nvidia Quadro K4000 graphics card. When I try to install the latest from the plugin, I get this error: The Nvidia drivers page points me to this driver for Linux 64bit which is fairly recent (March 2023) However, when I use the plugin, the only 470.xxx one that it provides is the one at the bottom: v470.141.03 I want to be able to use this card with Docker for apps that use the "--runtime=nvidia" parameter like stable-diffusion etc. that detect the NVIDIA GPU and ask for its GPUID e.g. GPU-xxxxxxx-xxxx-xxxx-xxxx-xxxxxxx. Is this something that can be supported?
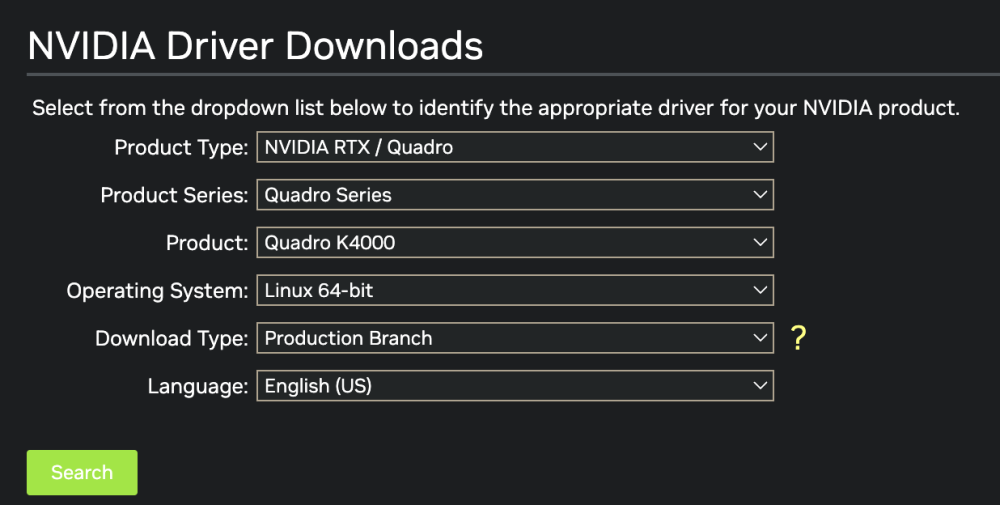
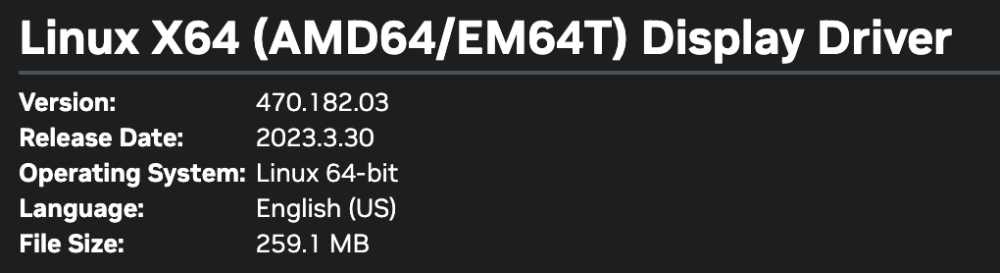

-
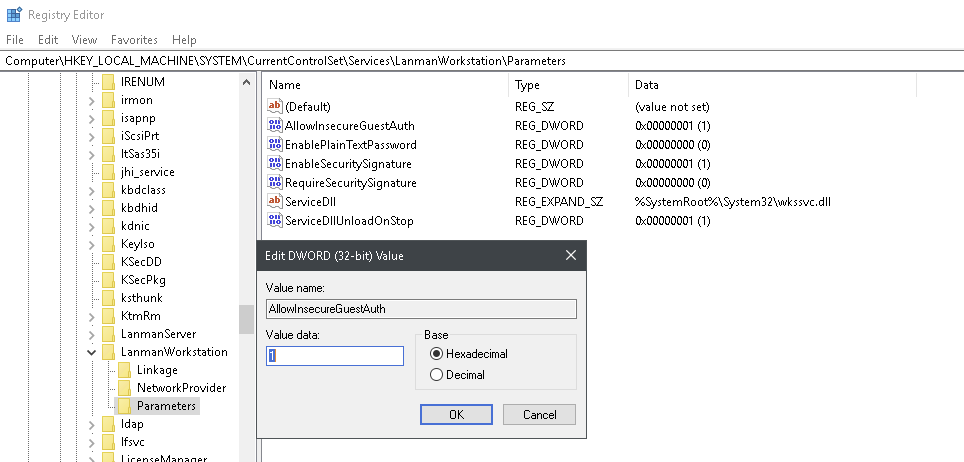
To get this to work on my Windows 10 (Enterprise) I had to set AllowInsecureGuestAuth to 1 in [HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\LanmanWorkstation\Parameters] in the Registry Editor. Then I had to login with username "\" and no password.
-
Can you please change the template to use br0 instead of eth0 by default? It doesn't work otherwise and that's the default interface for most Unraid users and I would never have known to change this without spending way too much time trying to figure out which interface (out of dozens) to use and if I had to change the network from host to bridge etc. This should work 'out-of-the-box' without any fuss.
-
Once you get your C prompt, did you try running the three commands in the comment above?
-
I don't know but a Google of the error message took me to this forum discussion: > Initializing to bash, running gitlab-ctl reconfigure (waiting for the db to fail, then start accepting connections, which took ~12 minutes for me) and then running reconfigure again allows it start.
-
You can limit log file sizes by changing the environment variable in your Edit docker template page. Mine looks like this. I disabled prometheus because it's a giant hog. --log-opt max-size=10m --log-opt max-file=1 --env GITLAB_OMNIBUS_CONFIG="external_url 'http://MY-UNRAID-IP:9080/'; postgresql['shared_buffers'] = '256MB'; sidekiq['concurrency'] = 15; prometheus_monitoring['enable'] = false;"
-
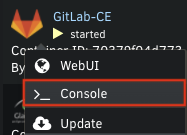
You right click on the GitLab-CE entry in the Docker tab of the UnRaid webpage, then select Console Hope that helps!
-
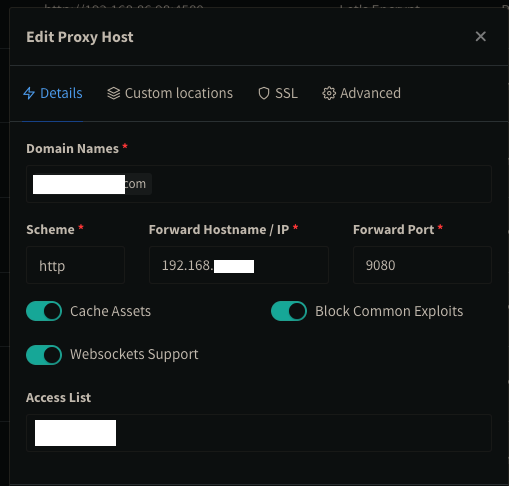
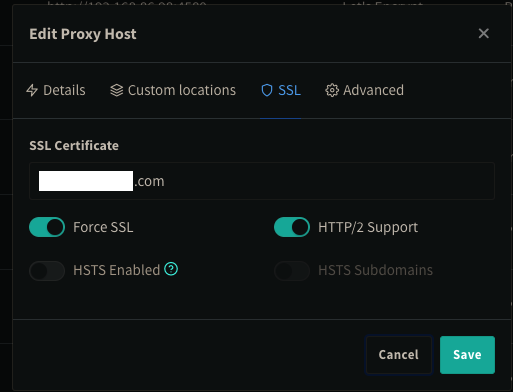
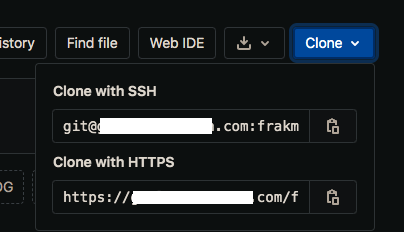
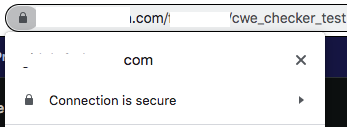
Unfortunately, I'm not sure I can help with your specific setup as I have it configured very differently. I use Cloudflare for my DNS and Let's Encrypt for the SSL certificate management within NginxProxyManager. You may need to map my logic to your specific setup. After some trial and error, I was able to get the external URL to work with SSL and have the Clone button in my repo point to the external URL instead of the local IP address: Browser Location bar: Gitlab Clone panel: How come you are setting env variables manually? I put them all as one string under Extra Parameters: I changed external_url to https://mysite.com/ I then made the following changes to gitlab.rb: external_url 'https://mysite.com' nginx['listen_port'] = 9080 nginx['listen_https'] = false and ran gitlab-ctl reconfigure In Nginx Proxy Manager: With the appropriate SSL certificate details for Let's Encrypt The problem I now have is that I am unable to do a git clone on either https or ssh without getting some authentication/SSL error. It used to work when I used the local server's IP address before I changed it to external URL.

-
I had a similar problem with localhost URL instead of my actual server when I clone. In the docker template page in Unraid, I had to add the external_url parameter to Extra Parameters and set it to my Gitlab WebUI IP:PORT. In your case, you may want to change it to your actual site URL. --log-opt max-size=10m --log-opt max-file=1 --env GITLAB_OMNIBUS_CONFIG="external_url 'http://MY-UNRAID-IP:9080/'; postgresql['shared_buffers'] = '256MB'; sidekiq['concurrency'] = 15; prometheus_monitoring['enable'] = false;" I use NginxProxyManager to manage the internet-facing URL.
-
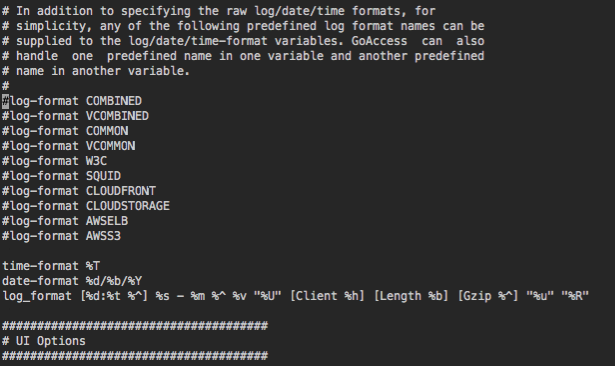
I put mine around line 116: I now notice that I use log_format while the file seems to be using log-format. Not sure if it makes a difference. You may want to try both if it isn't working like you expect.
-
The link to the script shows exactly how it's used. In any case, you don't have to use the script because I already did and provided the output. Those are the three lines you need to copy into the goaccess.conf file.
-
Thank you for the definitive answer and suggestion. I don't understand where the previous container's digest would be. Doesn't the old container get blown away after an upgrade? The only "inspect" I can run is on the new container. I also thought that an upgrade explicitly removed the orphan image that was the previous "latest" tagged image. I remember seeing that in the logs as the last step of the upgrade process. So after an upgrade, both the old container and the old image are gone and all I have is the new image and the new container created from it. Am I missing something? Maybe there's a misunderstanding. I'm not trying to figure out what version the current "latest" tag corresponds to. Yes, I can compare digests to published values. I am trying to determine the version of the previous version of the app just before the failed upgrade. It was also tagged as "latest".
-
Unfortunately there is no way of knowing what the version I had running before the upgrade was. Was it the previous version? Was the it the one before that? etc. I don't upgrade as soon as a new release is made so it could be anything in the last year. Is there a log of the docker upgrade operations and associated output anywhere? @Squid It just seems wrong that if I didn't happen to take a screenshot of the docker upgrade popup then it's gone forever.
-
I have a slightly different but related question. When I upgrade a docker app, there is a pop up with details about the upgrade. After the upgrade completes and I close that window and later find out that the upgrade failed, how do I know what the previous version of the docker image was? It's always set to xxx:latest in the template so there's no way of knowing after the operation completes what it was before. Is this information/log saved anywhere? When filing an issue/ticket against the app, I'd like to know what the source and destination versions where that caused the failure.
-
Sorry, I misunderstood earlier. I didn't know there was a second 'official' app on Community Applications. I'll have to try is out and get back to you later. UPDATE: Sorry, it's highly unlikely that I will revisit this on a different version of the app. It seems it was added after I started using the one from Grack's Repository. I updated my post to show which version I am using. You can use that one if you like.



















