




danktankk
Members
-
Joined
-
Last visited
Everything posted by danktankk
-
It isnt doing it for all my drives, but its a heck of a lot closer than i was! thank you brother
-
thanks. ill give that a go now
-
that just led to the first page, first post. ill look through this. thanks anyway.
-
i cant find the post where you show how to update JSON for a single panel. its late and im getting crosseyed. I would like to get this right tonight.. but it can wait obviously... The way that the post argument for me is done is valid (minus lm_sensors) - that didnt work out well. It does not have to have apk in it as my :latest repo does not like that.
-
I have the post arguments in place, however it required some tweaking (ty @HalienElf) since telegraf would not start at all without it: I use telegraf:latest repo and this is probably why. See below for a different way to implement. bash -c 'apt update && apt install -y smartmontools && lm_sensors && telegraf' lm_sensors is the latest effort for fans and CPU and is not integral to making S.M.A.R.T. work and doesnt appear to be working right now anyway. BTW, drive life now makes much more sense and I do like that stat! lol
-
I will see what i have missed. Thank you very much for the hasty reply! Will report back asap
-
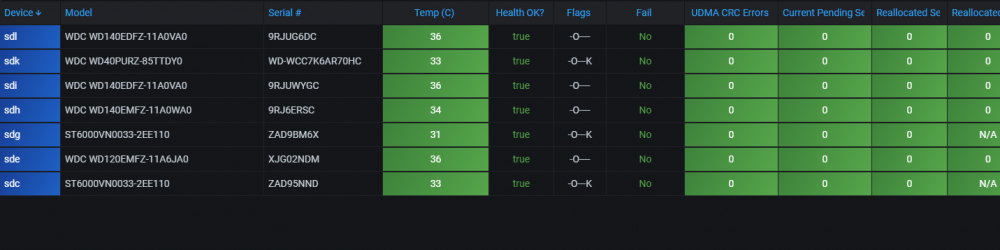
Great work on this dashboard! The only thing I cant seem to get to display properly - aside from ipmi (which will be corrected/modified for non-server boards in 1.4) - is the Drive S.M.A.R.T. Health Overview. NOTHING shows up in this panel. Bah! And believe me, I have tried to correct. The other smart panel does display as shown below. Also, "Drive Life" doesn't really separate anything. Is this intentional? How is this useful? so back to the smart health overview... Any ideas to help get this panel working? Again, great effort on this dashboard!



-
Ive been on this for about a week off and on between work & sleep. This worked! Thank you very much!
-
I was finally able to get my logo to appear. I just needed to clear my stubborn cache. Works great now. Thank you for the effort!
-
yes, the folder is mounted and the container wasnt made with a shell it looks like. I was able to get the custom.css to work, but still no go for the image. It looks like it has to be svg and has to be named logo, correct?
-
Im trying to add a custom image for filebrowser and use a custom css file but filebrowser doesnt appear to accept them. I used the documentation provided for this: https://filebrowser.org/configuration/custom-branding I created a directory in /mnt/user/appdata/filebrowser/ named 'config' and within that, I created a directory named 'img' that holds the logo.svg file for the custom logo. The custom.css I would like to use is in the config folder. In global settings, I changed the instance name successfully and disabled external links per the documentation I read to get this all set up properly. I have tried an absolute path: /mnt/user/appdata/filebrowser/config and regular path: /config but neither work. Any ideas as to where I have gone wrong? Many thanks for any help! Im sure I missed something simple.
-
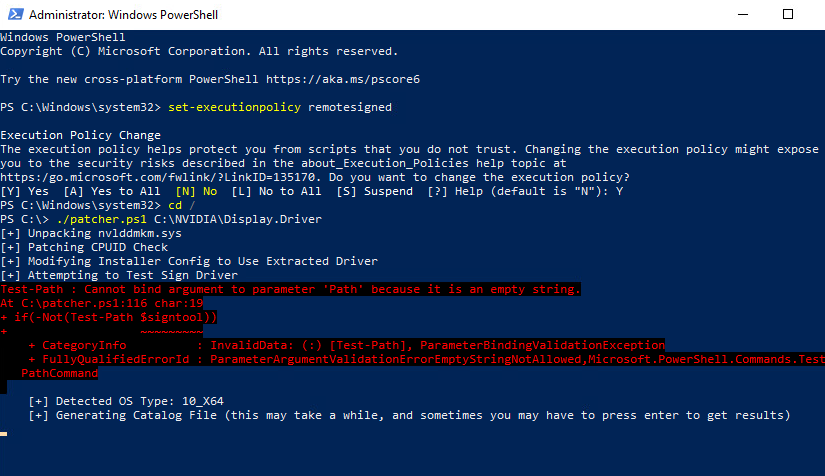
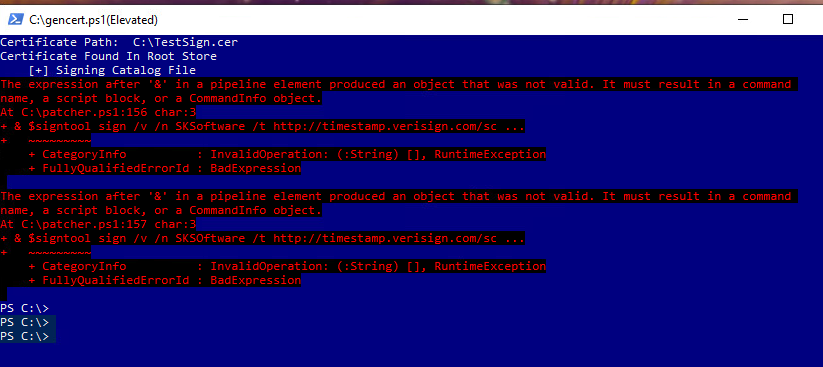
Works fine up until this point: PS C:\> ./patcher.ps1 C:\NVIDIA\Display.Driver [!] Failure: Unable to find nvlddmkm.sy_ in C:\NVIDIA\Display.Driver Any ideas? Many thanks! [EDIT] It appears that Display.Driver is now in a folder called 'universal' This is what I get now after moving the Display.Driver folder into the NVIDIA folder: After a few minutes, it does this: It does the same thing if I try using the patch with it in the universal folder as well. Any way we could get an updated version of these instructions? Any help would be greatly appreciated.
-
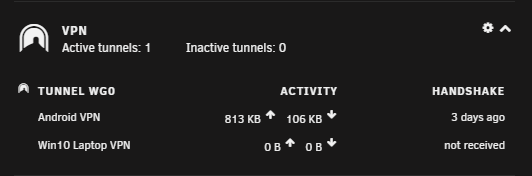
Another strange issue I am having is when I disconnect wireguard VPN, the unraid interface doesnt seem to get the memo: [image didnt copy over, but its in my original post In the picture above i test connected for about 20 seconds. After disconnect, it just keeps adding connected time. What made me notice this issue was that I had not logged into my unraid server for about 4 days (small vacation), and there was 4 days of wireguard uptime when I hadnt been connected but for a few minutes and then shut it off. Any advice would be appreciated on these 2 small issues. Thanks in advance! this is from the original post i made a few posts up....
-
Do you have any insights as to why UNRAID is hanging when I close a tunnel in the second half of my issue with wireguard? I hope it is as easy as the first solution. this is still open days later after closing the connection.
-
You are absolutely correct. I did not realize that advanced mode for each tunnel needed to be turned on. My oversight completely. Thank you very much for pointing out my error. This effectively solved the issue.
-
This does not happen in my case as shown by the pictures submitted above in my original post. The delete option is indeed there for WG0, but not for the other two that i would like to remove. Thank you for the reply.
-
No, I have not. I will look into that in the morning. Thank you for the suggestion.
-
-
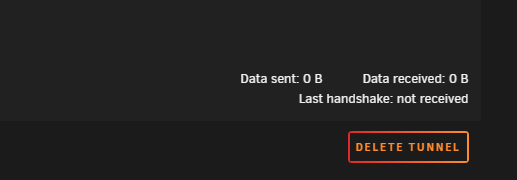
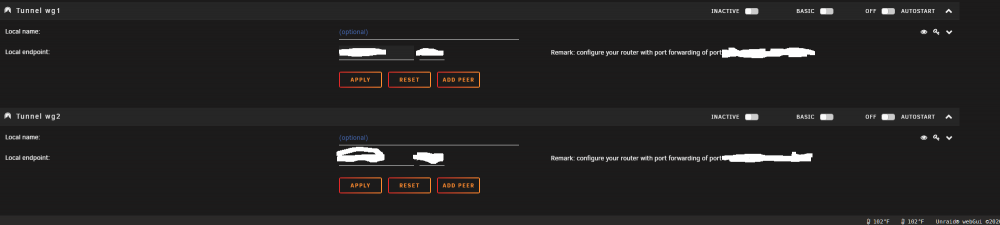
I seem to have accidentally added some extra tunnels in the wireguard config and do not have a way to delete them that I can see. WG0 is deletedable as shown below but is not the issue: There is no delete button for the other two tunnels that were created accidentally that I want to remove: I have looked in network settings and WG1 and WG2 are not there to delete either. **Another strange issue I am having is when I disconnect wireguard VPN, the unraid interface doesnt seem to get the memo: In the picture above i test connected for about 20 seconds. After disconnect, it just keeps adding connected time. What made me notice this issue was that I had not logged into my unraid server for about 4 days (small vacation), and there was 4 days of wireguard uptime when I hadnt been connected but for a few minutes and then shut it off. Any advice would be appreciated on these 2 small issues. Thanks in advance!
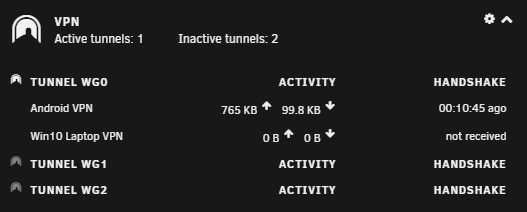
-
Nextcloud updates pretty regularly, but they could absolutely care less about this.... Its pretty obvious.
-
onlyoffice integration appears to still not work in nextcloud 18.04 either. updated today.. 😕 same error as always. ONLYOFFICE cannot be reached. Please contact admin. Not asking why, just posting it still doesn't work. At this point I'm not holding out any hope that it ever will without installing yet another container which defeats the purpose of OnlyOffice integration...
-
I've never used the alpine version, but i am considering it since it also works in unraid. You mentioned that it is slower, so that does make me hesitant. In addition, if I have to install an apache container as well, then there isnt much point in not installing the onlyoffice container
-
They have a backup folder they cram your old files in when they update. Glad it worked. Sent from my SM-G950U using Tapatalk
-
I was able to update mine without much trouble at all. Onlyoffice still isn't fixed, but other than that it went pretty well. I can't believe they have had 2 updates and it still doesn't have this corrected to run onlyoffice internally lol. I had to reload nextcloud a few times when it timed out doing the backup and in one other spot I can't recall atm. But it did complete it's tasks in the background. Could you possibly revert to 18.02? Sent from my SM-G950U using Tapatalk
-
If its a matter of a WebServer... I'd much rather install that than another container that is otherwise useless. At least the WebServer can do something for me besides doll up text...













