Leaderboard




Popular Content
Showing content with the highest reputation on 06/16/20 in all areas
-
Either I'm a glutton for punishment or just cheap, but I've purchased another Mikrotik switch, the 4 10gbe port (+1 1gig port) little guy. For a refresher, my previous. less than stellar mikrotik experience is detailed here: You don't have to read this reasoning of why I bought this: OK, so the reason I bought this little switch is because my main, old, Cisco/linksys 24 port switch died a pathetic death. I was using the mikrotik CSS326-24G-2S+RM 24 port switch by my servers to bridge 2 10gbe connections between them (one for the main server, the other for a video editing vm on another.) And yes, I know I could do direct cabling (which I've done), but then the other devices on the network trying to access the server would be bottlenecked by a single gigabit connection. When my house switch died, I decided to move the CSS326-24G-2S+RM 24 gig/2 10gbe switch into it's place. I thought about getting Mikrotik's new 8 ports sfp+ switch, but really I didn't need that many ports in that configuration by my servers. So I ended up with the smaller 4 port 10gbe switch which made more sense. Actual review/experience: There isn't a lot of info about this switch out there aside a couple videos, including one review with a guy drinking beer, one with guy with a dry erase board, and some cell phone video of someone else rambling. So I felt like I was winging it a bit but understood what it should be capable of doing. I had the same issues with just getting into the switch as I described in the other review. Rather, I figured I'd have the same issues, so it was basically straightforward this time by following the steps I eventually figured out. Again, the documentation is lacking with the switch and even the website link they give you to get the full documentation doesn't work. The switch comes with dual boot software: RouterOs and SwitchOs, the former being the more powerful/configurable. After changing the IP to a static one on my network and rebooting, everything else was pretty straight forward: plug in the main server, plug in the video editing vm, add a gigabit cable for network access and done. Completely different experience than last time. Important to note: it only comes with 1 power adapter, but they promote the hell out of "dual power inputs for redundancy!" which makes you think you're getting two. You're not. I didn't. So, a bit disappointed about the Latvians having a better grasp on English and implied advertising tactics than me. I talked about the thinness of the metal chassis for the last switch. This one also has a metal chassis, and while it doesn't feel thin, it does feel "less expensive." What I mean is, that I have a Netgear Prosafe GS105 5 port gigabit switch, which feels more rugged, durable, and also weighs more (go figure) than the mikrotik switch. It's not that the mikrotik switch feels cheap, I just thought it would feel, "more." Don't get me wrong, the fit/finish is more than acceptable, as everything seems to be aligned how it should be. I ran some speed tests and found that RouterOS was ever so slightly faster than SwitchOs by maybe 5%... who knows. I don't use or plan to use all the functionality with Router Os (also, I'm glad there is a safe mode), but I may in the future so I'll just let it run. On SMB file share from the ssd cache on the server to the ssd in the video editing vm I was getting 3-400MB/s throughput each way. iPerf3 also showed some nice numbers once I pushed up the thread count (as I had to do with the previous switch to get it's max bandwidth.) This is with no network tuning, right out the box, main server running a mellanox connectx2 into the switch via dac, then out via dac to a solarflare card. Additionally, monitoring the flow in the web gui of the switch showed peaks up to 9.7, but really, anything over 9gbps is just fine with me, and would be fine with you too. SO, I've had this switch for about 4 hours at this point. It seems to do the job nicely. In the next few months, I'll get two sfp+ rj45 10gbe transceivers and make a 10gbe trunk to the main house switch (I put in cat6a about a year ago.) The remaining sfp+ port will be connected to my server that hosts the video ending vm because.... why not, it's there. If my experience changes with this switch, I'll update accordingly. Also, if mikrotik is reading this, and you want to send me a 24 port sfp+ switch with all rj45 10gbe transceivers (or 3 of those 8 port sfp+ switches with transceivers), I'll make it my main house switch and review it for you! ------- March 28, 2020 update So I've been using this constantly for about 11 months. I've dropped it, I've pushed it, I've switched back and forth between the operating systems. It just does what it needs to do. It runs very warm, always has. But it hasn't slowed down. Earlier today I made the decision based on it's location to add a heatsink to the top to help dissipate cooling a little more (ordered one off amazon.) Wasn't my idea as I saw it somewhere else. Does it need it, probably not, but it won't hurt especially since the device has a single heatsink inside that sort of touches the chassis, and then using that to help dissipate heat. I currently use all 4 of the sfp+ ports: 1 to my main server via, 1 to my backup server via dac, 1 to my workstation vm via dac, and one using an rj45 transceiver from fs.com running over cat6a to the 24-gigabit/2-sfp+ switch server as a trunk. That transceiver runs really hot, hotter than the chassis of the switch. But both are always within spec. Regardless, I order a mixed mini-heat sink kit as well for 7 bucks and will add one or two to that transceiver just for fun. Still no world from mikrotik on review sample 24 port sfp+ switch filled with rj45 10gbe transceivers..... but at the rate they are moving products, I doubt it will ever come at this point..


 1 point
1 point -
To allow grouping of VMs and thus better organization. Say school, networking, current projects, and backburner projects as categorizations that someone might have. Go to VM tab and can expand only the folder you need like networking to troubleshoot a problem instead of scrolling up and down all your VMs to go to the different networking related ones. For simplicity I would assume a VM would default to uncategorized (or unlabeled or whatever). Ideally this property of the VM could be changed with it running, like maybe one goes from projects to processing data to signify the functional state of the VM (big data application so runs for long time). Farther down the road it would be nice to apply actions to the whole group. Start/stop/pause, and vnc to open a vnc window for each VM so you can quickly look at the whole group (tiling the windows would be cool but probably be too far). Apply settings to the group like autostart toggle. Can think of other actions, but not ones that make sense for unRAID VMs.1 point
-
That means the partition is gone, it was either deleted or it could be an SSD problem, despite still appearing healthy on SMART.1 point
-
Rebooting shouldn't be needed for this, but glad it's working now.1 point
-
Not seeing any USB device being connected, but since the log is kind of long, reboot, start the array, wait a minute and then plugin the USB device and post new diags.1 point
-
You, sir, are a gentleman and a scholar. Thank you.1 point
-
Just had the same issue with asrock x399 and the intel 3186 passed to win 10 VM. Changed the alias bus to 0x06 in xml and it work a treat. Many thanks guys!1 point
-
That seem to have fixed it! Now I observe one other quirk. When I set the password in `ark-se\ShooterGame\Saved\Config\LinuxServer\GameUserSettings.ini` the server ignores the password and resets it to blank. The file itself seems to be read, since it actually sets the server name as specified...1 point
-
I assume you currently have no SSD cache drive? Although, at 30GB it is rather small, the SSD could be added as a cache drive with the sole use (no user share write caching) being to house the docker.img file and the appdata share which you would set to cache prefer. Other shares commonly stored on the cache drive are isos and system although these have to do with VMs. If you have no VMs, these would be empty so they are not taking up much space. You might want to check the current size of your appdata share to make sure that 30GB is sufficient. It should be if you only have the docker containers mentioned. Having the appdata share on an SSD cache drive allows the array drives to spin down when not in use for user share data access or writing.1 point
-
Hyper-V recently added support for nested AMD virtualization. Requesting Unraid build feature parity. https://techcommunity.microsoft.com/t5/virtualization/amd-nested-virtualization-support/ba-p/14348411 point
-
@teh0wner i did end up fixing it! What i did was putting the passphrase in a text file on my dns server and make my unraid server retrieve it at every boot meaning that if it ever was taken away from here it wouldn't decrypt the disks. I did this using some scripts for adding a ssh key to my server at every boot and another script that uses said key to retrieve the passphrase file with passwordless rsync. DM me if you want a more in depth guide1 point
-
Unmanic 0.0.1-beta4 is now available. This fixes the issue that you all were having regarding files that were already processed being re-added to the queue. The major change with this release is the following: Improved job pipeline. Prior to this, the workers handled everything including the file copies and post-processing after a conversion. This was not ideal. The new pipeline works as follows: File added to job queue as a "task" object Worker picks up task object Worker configures ffmpeg Worker inits ffmpeg (monitor output) On conversion complete task object is updated by the worker Worker places update task object into a new "processed" queue New "PostProcessor" class picks up task object from "processed" queue PostProcessor tests all files and carries out the file move PostProcessor adds task object data to history This now opens doors for things like modular post-processing configurations and improved logging on historical tasks (needed for upcoming "See all records" screen). Further in the background this also enables the automated build CI server that I've setup. This build server will automatically execute regression tests which should help with my development. The next milestone on my task list is 0.0.1-beta5 (https://github.com/Josh5/unmanic/milestone/3). This will include some more bugfixes and a new "See all records" screen. I set a release date for this for next Monday, but that my end up pushing out to the following week. We'll see how things go. If you have opened issues on github, please check if I have closed them. If they are now closed, could you please test that your reported bug/enhancement now works as expected. Ta1 point
-
Hey team. I'm finally coming off my 350 hour project at work. Will finally start to see more free time to work on unmanic. I appreciate the patience. Since January I've been working overtime and have not had a chance to do any of my personal projects. I have not even logged into steam for months. But finally that's coming to an end. Over the next fortnight I'll take a look at everyone's suggestions and start coming up with a plan of attack for getting unmanic to a point where its useful for everyone. Thanks again. Sent from my ONE E1003 using Tapatalk1 point
-
So this is a very simple breakdown of what unmanic currently does. I'm in no way an expert with ffmpeg, so I welcome anyone to come forward and tell me this is wrong and it's not working this way.... for each video stream: re-encode: bitrate: source resolution: source codec: hevc (can be configured in settings) encoder: libx265 (locked to codec at the moment) for each audio stream: (if audio channel has more than 2 channels (not stereo):) clone source audio channel (does not re-encode) copy source audio channel re-encode to stereo (with same title where possible. Eg. English -> English Stereo): bitrate: 128k codec: aac encoder: aac (if audio channel is stereo:) re-encode stereo audio channel: bitrate: 128k codec: aac encoder: aac for each subtitle stream: (if setting for stripping subtitle streams out of mux is set) do nothing (subtitles will not be cloned to destination) (else) clone source subtitle stream (does not re-encode)1 point
-
Actually I got halfway through the CPU slamming and logging issues on Wednesday (it was a public holiday over here). There should be a build sitting on :latest that fixes the CPU slamming while idle. I have not been able to finish the other issue yet Sent from my ONE E1003 using Tapatalk1 point
-
There should be a new update available. This has quite a number of changes to how ffmpeg is executed. It should resolve some issues with inotify and library scanning. For those people who created issues on github you will see the ones that "should" be now fixed marked as closed. If I get time tomorrow I will make a push for adding some features. Perhaps some additional settings for file conversions.1 point
-
@Josh.5 What @BomB191 said ^^^. This work is brilliant and no rush. Don't worry at all.1 point
-
Don't stress @Josh.5 You just managed to think of and start writing something everyone's been looking for, For a dam long time. So the "I wanted this 2 years ago" factor is extremely strong.1 point
-
@Ashe @trekkiedj @itimpi Please see update first post also for an example of how I have it setup. I have also added a temporary solution to adding multiple library locations if anyone needs that. I will add a feature to the WebUI to separate it in the future. Thanks tho to you three for sorting the Docker configs out for everyone. I should have posted better details here initially. @trekkiedj - Thanks for the reports regarding the ascii issues, I'm looking into that one asap. Possible ETA for a fix is by the weekend.1 point
-
I'm currently testing the version on GitHub on my TV library. Going really well, however I'm finding the output too heavily compressed which is compromising the quality. I know you want to keep the interface simple but I for one would welcome some ability to set the quality of the output.1 point
-
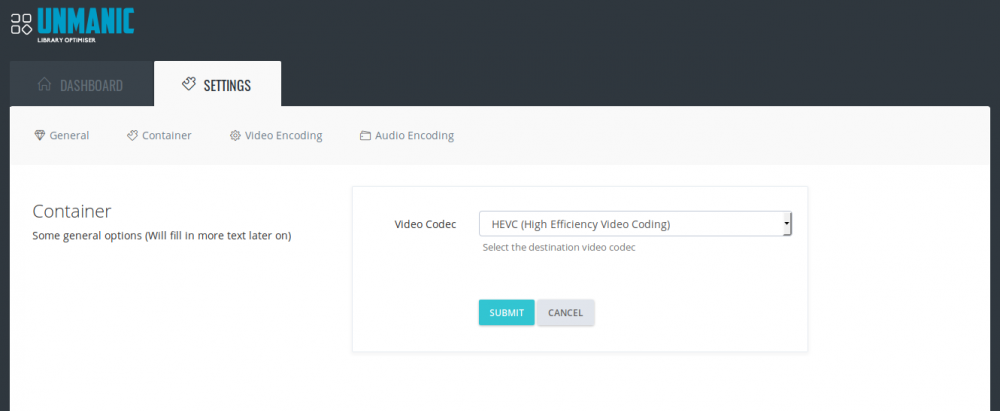
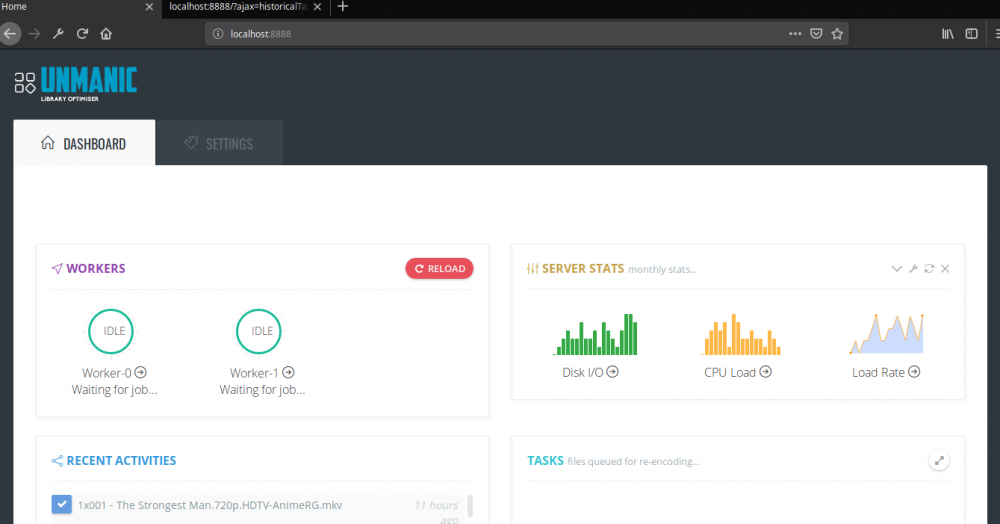
I've put in quite a few hours to creating a tidy UI for the application. Once this is complete we should be able to start adding much better control over the settings. UI and code tidy up should be complete with 5 or so more hours of coding (probably tomorrow if time permits). See the attached screenshots for an idea of what it will look like. You can see that I have implemented the "worker" approach. In the screenshot I have too workers that are passed files to re encode. Once complete they are logged in the "recent activities" list. Currently unsure about the server stats. That may not be complete by the time I push this to dockerhub. But I think it will be a nice idea to see what sort of load you are putting on the server.
 1 point
1 point













