



CS01-HS
Members
-
Joined
-
Last visited
Everything posted by CS01-HS
-
I have an iTunes share I export to a MacOS VM via NFS. It's also exported via Samba. When I try to access it over Samba my syslog fills with error messages, like the following, until /var/log is full. Jun 21 21:29:29 NAS smbd[53700]: fruit_freaddir_attr: ad_convert("MobileSync/Backup/befb940834f22f2a08a0c0798743a276bd743d26/b4/b433d7e80ae776e6d7e5b0b72aa94cfc9f34746b") failed Jun 21 21:29:29 NAS smbd[53700]: [2025/06/21 21:29:29.304654, 0] ../../source3/lib/adouble.c:1254(ad_convert_xattr) Jun 21 21:29:29 NAS smbd[53700]: ad_convert_xattr: SMB_VFS_CREATE_FILE failed Jun 21 21:29:29 NAS smbd[53700]: [2025/06/21 21:29:29.304777, 0] ../../source3/modules/vfs_fruit.c:4441(fruit_freaddir_attr) Jun 21 21:29:29 NAS smbd[53700]: fruit_freaddir_attr: ad_convert("MobileSync/Backup/befb940834f22f2a08a0c0798743a276bd743d26/b4/b47b8135fe78124b07d197f347e8f83eb43e304b") failed Jun 21 21:29:29 NAS smbd[53700]: [2025/06/21 21:29:29.318523, 0] ../../source3/lib/adouble.c:1254(ad_convert_xattr) Jun 21 21:29:29 NAS smbd[53700]: ad_convert_xattr: SMB_VFS_CREATE_FILE failed Jun 21 21:29:29 NAS smbd[53700]: [2025/06/21 21:29:29.318655, 0] ../../source3/modules/vfs_fruit.c:4441(fruit_freaddir_attr) Note the MobileSync directory is for iPhone backups and Apple's format has maybe thousands of directories with thousands of files in each. I mention that because I don't get the error when accessing other shares. I do however get the following error whenever I mount a share from macOS but it doesn't seem to cause any problems: Jun 21 21:35:56 NAS rpcd_mdssvc[72992]: [2025/06/21 21:35:56.682698, 0] ../../source3/rpc_server/mdssvc/mdssvc.c:1693(mds_init_ctx) Jun 21 21:35:56 NAS rpcd_mdssvc[72992]: mds_init_ctx: Unknown backend 1 Jun 21 21:35:56 NAS rpcd_mdssvc[72992]: [2025/06/21 21:35:56.682758, 0] ../../source3/rpc_server/mdssvc/srv_mdssvc_nt.c:129(_mdssvc_open) Jun 21 21:35:56 NAS rpcd_mdssvc[72992]: mdssvcopen: Couldn't create policy handle for Public My setup hasn't really changed since 6.9 and this is the first I'm seeing the error, which suggests it's a consequence of changes in recent versions. It happened first with 7.1.3 so I started this report then noticed 7.1.4 was available, upgraded and reconfirmed (still a problem.) Other than Enhanced macOS interoperability enabled I've had these custom settings since 6.9 to make search work in macOS clients because it wouldn't work otherwise: Diagnostics attached. nas-diagnostics-20250621-2130.zip
-
Just checking back in to confirm it was a docker pathing issue. Thanks!
-
The plugin creates a swap file on the disk to act as extra "memory." I set mine to 25% of total RAM. Nothing more to add really - just works. There's more detail in the support thread.
-
I resolved sporadic OOM errors with the swapfile plugin. My swap location is a simple single-drive XFS mount so I can't say how well it works with more complex setups but for me it's worked perfectly. Set-and-forget.
-
Sporadically an empty directory cache (owned by root) appears in the root of one of my shares. I'll delete it then a week or weeks later it reappears. I'm trying to figure out why. Maybe mover-related (I use mover-tuning) or a misbehaving user-script (I have many) but so far no clear cause. Any ideas?

-
I have mine set to 1. I believe if you go to Danger Zone and set Disable restrictive validation to Yes it allows it.
-
It looks like Limetech only solved this in 2018 by replacing rsync with a custom "move", so I don't think it's solvable with rsync. I see the previous mover-tuning plugin also used unraid's "move": https://github.com/hugenbd/ca.mover.tuning/blob/master/source/ca.mover.tuning/usr/local/emhttp/plugins/ca.mover.tuning/age_mover I wonder if there are other (maybe more significant) differences between rsync and move.
-
I see an option to moves files based on atime - if that's it, my issue's different: preserving the atime of files and directories when they're moved (which standard mover does but mover-turning doesn't.) Edit: AFAIK unraid doesn't update atime when files are accessed so I don't think this will work as intended.
-
After testing a patch to mover I can confirm adding the --atimes option does not solve the problem. Must be some magic in Unraid's /usr/libexec/unraid/move that rsync doesn't replicate.
-
Sure, no rush, I was more trying to determine if the problem was general or specific to me. I've poked around and (this is only a first pass but) from what I can tell: unRAID's mover calls the executable /usr/libexec/unraid/move where age_mover uses rsync, with this call: rsync --archive --xattrs --relative --hard-links which does not preserve atime. Test: root@NAS:~# touch /mnt/cache/Download/x root@NAS:~# stat /mnt/user/Download/x File: /mnt/user/Download/x Size: 0 Blocks: 0 IO Block: 4096 regular empty file Device: 0,46 Inode: 2744525 Links: 1 Access: (0666/-rw-rw-rw-) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2025-02-16 11:48:25.081690303 -0500 Modify: 2025-02-16 11:48:25.081690303 -0500 Change: 2025-02-16 11:48:25.081690303 -0500 Birth: - root@NAS:~# rsync -v --archive --xattrs --hard-links --remove-source-files /mnt/cache/Download/x /mnt/user0/Download/x sending incremental file list x sent 95 bytes received 59 bytes 308.00 bytes/sec total size is 0 speedup is 0.00 root@NAS:~# stat /mnt/user/Download/x File: /mnt/user/Download/x Size: 0 Blocks: 0 IO Block: 4096 regular empty file Device: 0,46 Inode: 2744525 Links: 1 Access: (0666/-rw-rw-rw-) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2025-02-16 11:49:07.322278620 -0500 Modify: 2025-02-16 11:48:25.081690303 -0500 Change: 2025-02-16 11:49:07.323278611 -0500 Birth: - root@NAS:~# But by adding the --atimes option it will: root@NAS:~# rm /mnt/user/Download/x root@NAS:~# touch /mnt/cache/Download/x root@NAS:~# stat /mnt/user/Download/x File: /mnt/user/Download/x Size: 0 Blocks: 0 IO Block: 4096 regular empty file Device: 0,46 Inode: 2744526 Links: 1 Access: (0666/-rw-rw-rw-) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2025-02-16 11:51:47.631716978 -0500 Modify: 2025-02-16 11:51:47.631716978 -0500 Change: 2025-02-16 11:51:47.631716978 -0500 Birth: - root@NAS:~# rsync -v --archive --xattrs --hard-links --remove-source-files --atimes /mnt/cache/Download/x /mnt/user0/Download/x sending incremental file list x sent 100 bytes received 59 bytes 318.00 bytes/sec total size is 0 speedup is 0.00 root@NAS:~# stat /mnt/user/Download/x File: /mnt/user/Download/x Size: 0 Blocks: 0 IO Block: 4096 regular empty file Device: 0,46 Inode: 2744526 Links: 1 Access: (0666/-rw-rw-rw-) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2025-02-16 11:51:47.000000000 -0500 Modify: 2025-02-16 11:51:47.631716978 -0500 Change: 2025-02-16 11:52:11.122488244 -0500 Birth: - root@NAS:~# But really, given all of mover's complexity (and my relative ignorance) that "mistake" seems too basic to be an oversight.
-
Seems stat's Access is what macOS uses for Date Created and I don't see anything better so I assume it apples generally. Here's an example: Directory Where Eagles Dare (1968) was created on cache on 1/14 Mover runs on 2/13 at 02:24 and creates the directory on the array with a new Access time. Files exist in both directories because I exclude specific file-types. For reference: cache is BTRFS and the array is standard Unraid.
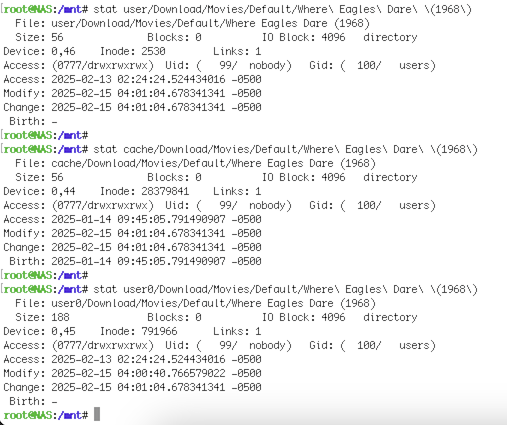
-
I can rule this out because I set it to Yes, reran, and the behavior persisted.
-
Upgraded to 7 and the new plugin - works well, except I noticed only with directories (not files) Date Created (macOS over SMB) is reset to the time it was moved. Is that expected? Maybe because I have Clean empty folders: No ? Otherwise I'll investigate further.
-
I'm running the latest bios (v1.70) here: https://www.asrock.com/mb/Intel/J5005-ITX/index.asp#BIOS so I think these are totally different lines. Yours gets stuck while Unraid is booting (not in the earlier bios stage) ? I've never had that problem. I'd start with the on-screen messages at the point it gets stuck - what's it trying to do?
-
I run an old (Mojave) MacOS VM, created with Spaceinvader's mac-in-a-box, that's survived several years of Unraid upgrades unchanged. No problems with 7.0 except the VM lost iTunes WiFi sync - the icon present when a phone's detected doesn't appear. USB sync still works and the VM can see the iPhone in Bonjour/Discovery but no option to sync. It's the strangest thing. Any ideas on where to start? Information on implementation/requirements on the Mac end is scant so I'm hoping I can probe outside it. (VM runs qemu 4.2 and e1000-82545em)
-
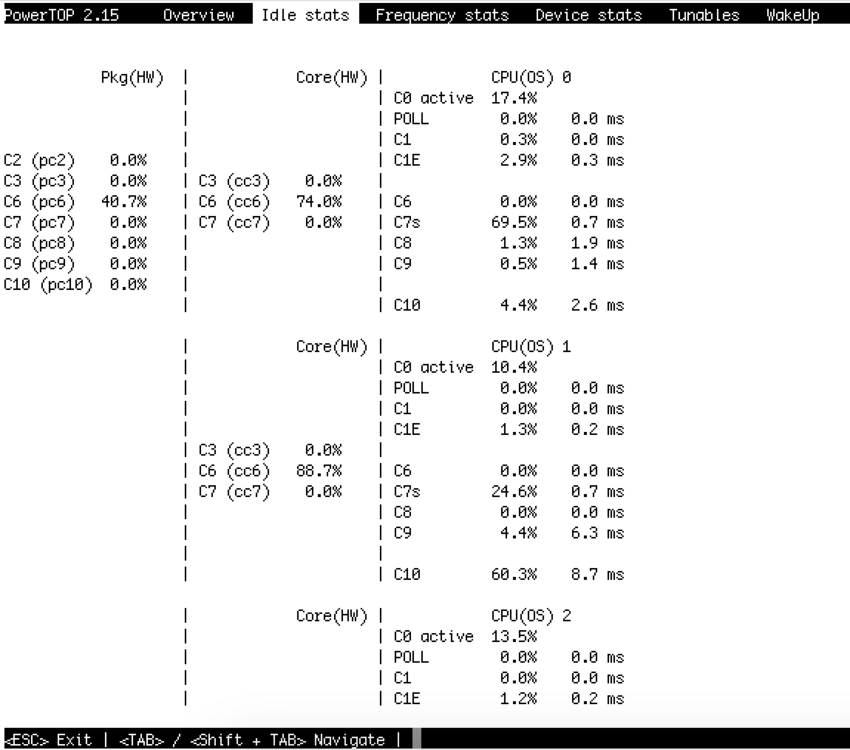
That's a useful reference point, thanks. I tested with a watt meter - with 3 SSDs and 5 2.5" HDDs spun down I see it fluctuate between ~13w and ~20w at idle. Not bad. I have a decent PSU (Corsair SF450 Gold) I'll experiment some more.
-
With drives asleep save one SSD I estimate it's around 17W at idle but I haven't tested properly. Seems high considering the low-power CPU.
-
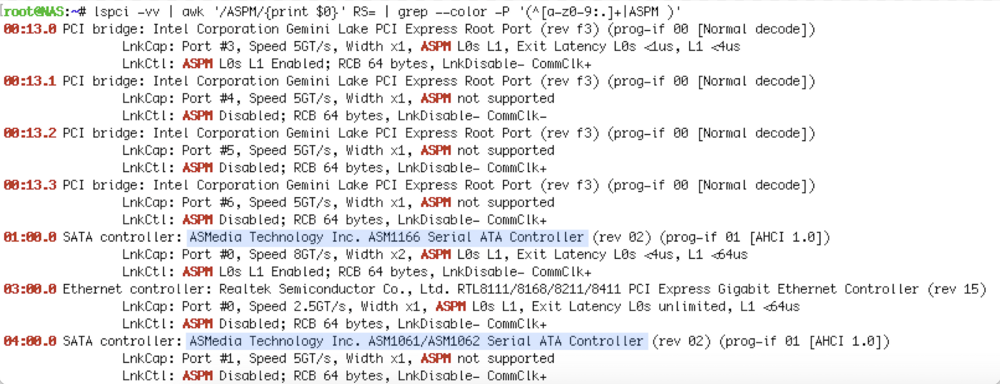
Since swapping my HBA for an ASM1166 card I can reach C6 but no lower: The relevant bios settings are C1/C6, C1E, and L0sL1, all of which I've enabled. Curiously while the ASM1166 PCI card shows ASPM Enabled, the onboard ASM1061/ASM1062 shows ASPM Disabled. I'm wondering if it's worth it to probe further.
-
Right - only one of the two ports will work when used with the MB's 4 pin connection. (That's the setup I have now.) But forget the dual port because I only need one. Does anyone sell a 4-pin single-port header with no cable? I've scoured the usual sites, google images - nothing. Worst case I'll mount the cabled version somewhere but it's not as clean.
-
I'm trying to find a USB header for my boot drive. I see plenty of 9 pin headers without cables: and 4 pin with cables: but no 4 pin without. Strange! (What prompted this was intermittent boot problems which I traced to my 9-pin header sagging on the 4-pin motherboard connection.)


-
No, my appdata's on a single XFS drive. Maybe I'll look into ZFS when I upgrade to 7.
-
It occurs to me the following (for "start, backup, start for each container") would reduce downtime significantly: Untar container's latest backup into temp directory Stop container rsync container's appdata directory to temp directory Start container Tar temp directory as new backup Verify Clear temp directory No downsides I can think of besides the extra space required.
-
Huh, clear differences between your file view and mine. Not sure why - best to ask in another thread.
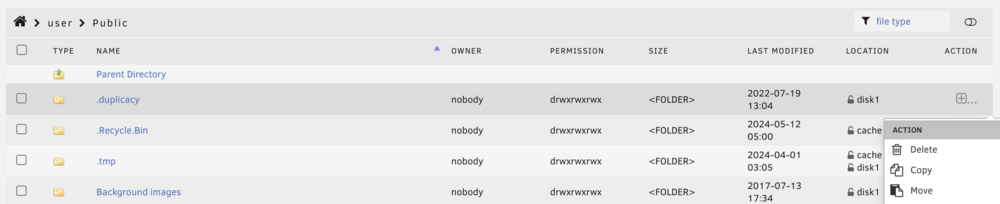
-
A file browser's built it. Go to shares in the top menu and navigate to the file then use the file menu to delete or change permissions.
-
The plugin's working great but I don't understand the rationale for a warning for "no internal mappings." In theory if I set the container to skip the only difference is the warning! But in practice that's not the only difference: I have a container with no internal mapping as part of a group (because its start order is important.) If I set it to skip it's not restarted so it loses communication with the container it depends on, which is. If I don't, I get the warning. Is there an approved way to handle that? I come back to the warning though - plenty of containers with no "appdata" so why warn about a normal condition? Maybe something I'm missing.









