



CS01-HS
Members
-
Joined
-
Last visited
Everything posted by CS01-HS
-
I've only seen OOM errors while running a 4GB VM (in addition to my standard apps.) I haven't booted that VM since installing the plugin. But now that swap's available unRAID is using it. Interesting.
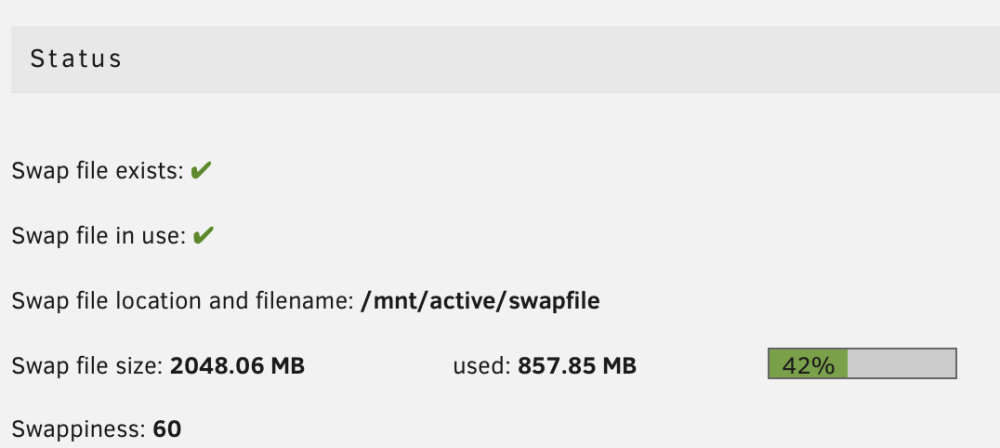
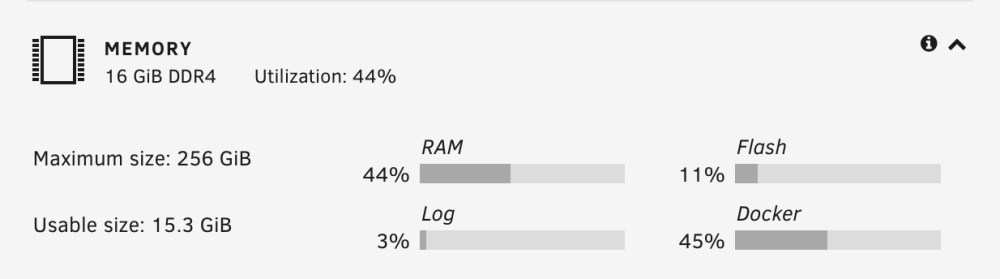
-
It's about a once-a-month thing. Apparently I had a very superficial understanding of linux memory allocation. I've installed the plugin, fingers crossed.
-
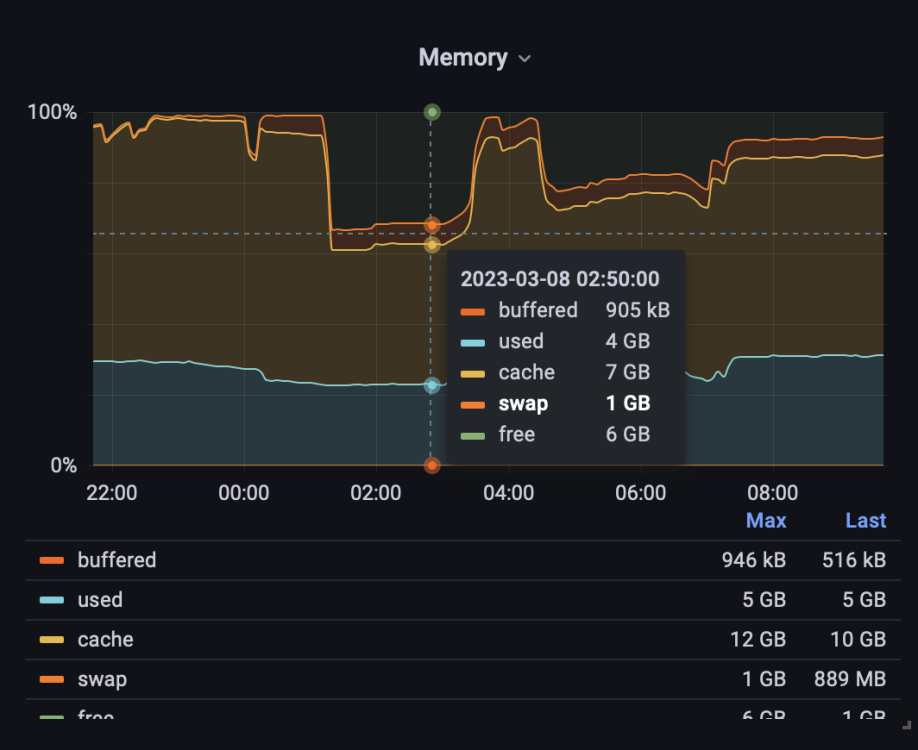
I got another out of memory error warning (killed a VM): Mar 6 02:48:28 NAS kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/machine/qemu-4-macOS.libvirt-qemu,task=qemu-system-x86,pid=15774,uid=0 Mar 6 02:48:28 NAS kernel: Out of memory: Killed process 15774 (qemu-system-x86) total-vm:4771316kB, anon-rss:4437356kB, file-rss:0kB, shmem-rss:26488kB, UID:0 pgtables:9400kB oom_score_adj:0 Seems like I just ran out of memory. But reporting (just prior to the error) showed 9GB used and 7GB in cache out of 16GB total: Shouldn't the OS clear the cache before killing processes? I wonder if the Folder Caching plugin I run has something to do with it.
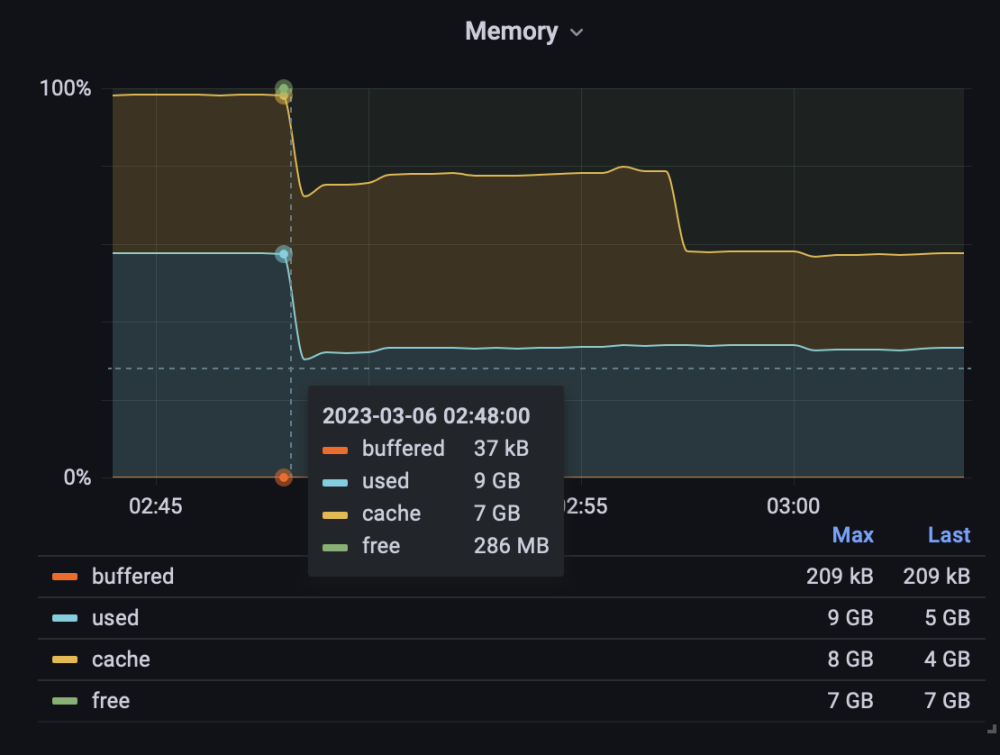
-
I got this last night. I suspect the macOS VM (which I usually don't run) pushed me over the edge. Diagnostics attached. If you spot anything out of the ordinary I'd appreciate the assistance. nas-diagnostics-20230206-0732.zip
-
At some point in the last couple/few months my backups started taking longer e.g. it takes about 40 minutes to copy this 50GB disk image: I remember fixing this a year or two ago by disabling rsync to the extent possible. It's still disabled: But the log entry above and grafana, which shows mostly reads on both the source (as expected) AND destination (Active -> Array) during the backup period, suggests it's using rsync. Any ideas? I have reconstruct write enabled but even if reporting tracks that as reads I doubt the above shows a copy operation. 12MB/s write is well below my array's capacity.

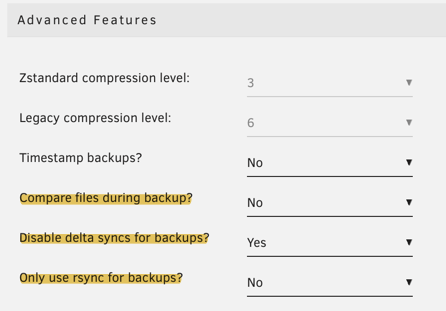
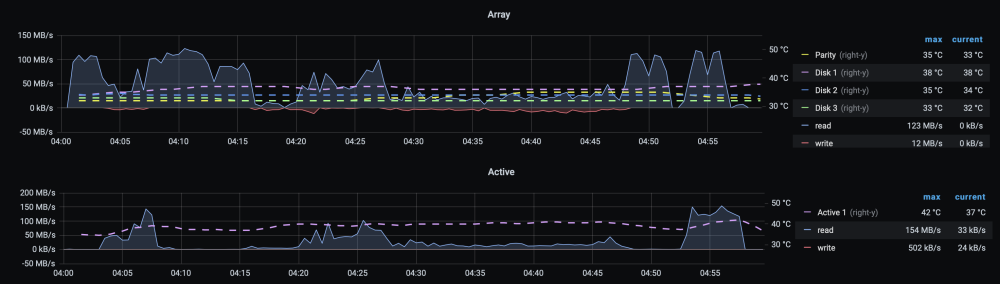
-
Not to get too far off the main topic but isn't the solution there a secondary DNS like Google or OpenDNS, unless the concern is custom local resolution.
-
The simpler and IMHO more robust solution would be to imitate unraid's start process: stop all containers backup the first container start the first container backup the second container start the second container etc. Avoid the headache of debugging user- or container-specific dependencies - if boot works, backup works. And shorter downtime for primary containers (relative to the current version) should reduce the need to exclude, reducing errors.
-
My fix was to move the spinning disks from the integrated ASM controller to the integrated intel. I've had no problems running autotune with only SSDs on the ASM. Before that, with mgutt's explicit config/go commands as a basis, I excluded the ASM's host3 and host4 from power-saving - intel are 1 and 2. linkpm_count=1 for i in /sys/class/scsi_host/host*/link_power_management_policy; do echo 'med_power_with_dipm' > $i if [ $linkpm_count -eq 2 ]; then break fi ((linkpm_count++)) done
-
Awesome update. One big advantage (maybe for a future version :) is with separate archives there's no need to wait until all backups are complete to restart individual containers, which will minimize downtime.
-
Is persistent load from the unmanic-service process expected? Pausing workers (which were already inactive) and disabling file monitors didn't affect it, and there are no entries in the log (even with debug enabled) indicating activity. top within the container: top in unraid:
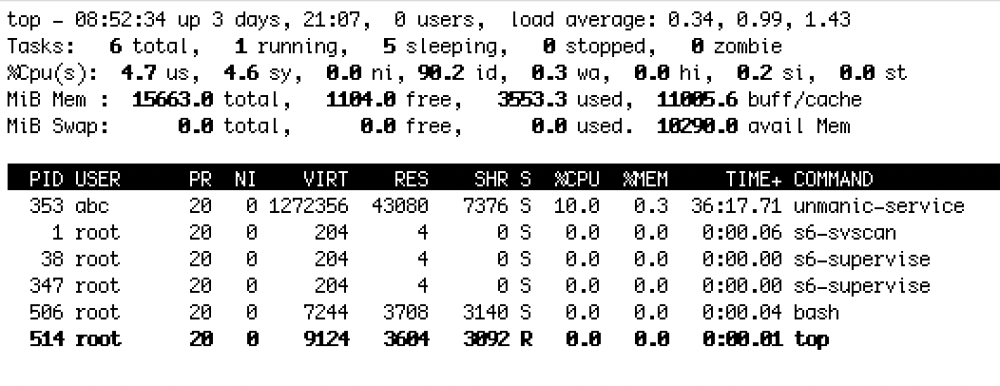
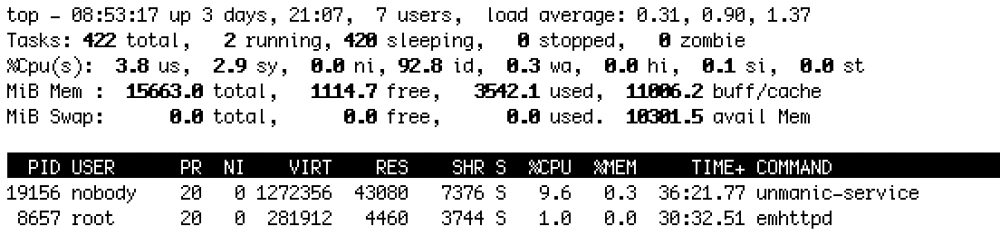
-
Also consider a transcoding path outside the docker image. I have mine use RAM (to minimize SSD writes) but a path to a cached share works as well. NOTE 1: Emby will create the subdirectory transcoding-temp under your specified path. (In my case that's /dev/shm/transcoding-temp) NOTE 2: As an alternative to the nightly restart I've written a monitoring script: SCRIPT TO KEEP EMBY'S TRANSCODING DIRECTORY FROM FILLING UP


-
Had an issue with 4.5 where memory ballooned to about 4GB, best I can tell. My system should have been able to handle it but I couldn't investigate – GUI was non-responsive and even simple bash commands would throw "resource fork" errors (maybe nproc limits?) I managed to restart the server and downgrade cleanly, no problems since.
-
Nope - hasn't happened since. Either a fluke or whatever caused it was fixed.
-
Running ffmpeg on (I believe) a corrupted video file mapped via 9p caused a fuse error rendering shares inaccessible. Any idea how I can prevent that? The error's fine but I'd prefer if it didn't take down the array. Is there anything obviously wrong with my setup? It's been running stably for a couple of years now. Error in script running in Debian VM. The next line after ffmpeg is a move which fails: frame=200798 fps=531 q=-1.0 Lsize= 2492607kB time=00:55:49.97 bitrate=6095.4kbits/s speed=8.86x mv: failed to access '/mnt/unraid/scratch//test.mp4': Transport endpoint is not connected /etc/fstab: unraid /mnt/unraid 9p trans=virtio,9p2000.L,_netdev,nofail 0 0 VM share config: Error in unraid syslog (I was tailing the syslog server's output when it failed) Nov 17 12:04:14 NAS shfs: shfs: ../lib/fuse.c:1450: unlink_node: Assertion `node->nlookup > 1' failed. Nov 17 12:04:14 NAS rsyslogd: file '/mnt/user/system/logs/syslog-nas.log'[9] write error - see https://www.rsyslog.com/solving-rsyslog-write-errors/ for help OS error: Transport endpoint is not connected [v8.2102.0 try https://www.rsyslog.com/e/2027 ] Nov 17 12:04:14 NAS rsyslogd: file '/mnt/user/system/logs/syslog-nas.log': open error: Transport endpoint is not connected [v8.2102.0 try https://www.rsyslog.com/e/2433 ] Nov 17 12:04:30 NAS kernel: ------------[ cut here ]------------ Nov 17 12:04:30 NAS kernel: nfsd: non-standard errno: -107 Nov 17 12:04:30 NAS kernel: WARNING: CPU: 2 PID: 8911 at fs/nfsd/nfsproc.c:889 nfserrno+0x45/0x51 [nfsd] Nov 17 12:04:30 NAS kernel: Modules linked in: xt_connmark xt_comment iptable_raw xt_mark cmac cifs asn1_decoder cifs_arc4 cifs_md4 dns_resolver xt_CHECKSUM xt_nat veth ipt_REJECT nf_reject_ipv4 xt_tcpudp ip6table_mangle ip6table_nat iptable_mangle vhost_net tun vhost vhost_iotlb tap xt_conntrack nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo xt_addrtype br_netfilter xfs nfsd auth_rpcgss oid_registry lockd grace sunrpc bluetooth ecdh_generic ecc md_mod nct6775 nct6775_core hwmon_vid wmi efivarfs iptable_nat xt_MASQUERADE nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 wireguard curve25519_x86_64 libcurve25519_generic libchacha20poly1305 chacha_x86_64 poly1305_x86_64 ip6_udp_tunnel udp_tunnel libchacha ip6table_filter ip6_tables iptable_filter ip_tables x_tables af_packet 8021q garp mrp bridge stp llc bonding tls i915 drm_buddy i2c_algo_bit ttm drm_display_helper x86_pkg_temp_thermal intel_powerclamp coretemp kvm_intel drm_kms_helper drm kvm processor_thermal_device_pci_legacy Nov 17 12:04:30 NAS kernel: processor_thermal_device processor_thermal_rfim processor_thermal_mbox intel_gtt crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel mpt3sas i2c_i801 aesni_intel agpgart intel_soc_dts_iosf crypto_simd i2c_smbus cryptd rapl r8169 syscopyarea intel_cstate ahci sysfillrect raid_class i2c_core scsi_transport_sas sysimgblt realtek libahci iosf_mbi fb_sys_fops thermal button int3406_thermal video backlight fan dptf_power int3400_thermal acpi_thermal_rel int3403_thermal int340x_thermal_zone unix Nov 17 12:04:30 NAS kernel: CPU: 2 PID: 8911 Comm: nfsd Not tainted 5.19.17-Unraid #2 Nov 17 12:04:30 NAS kernel: Hardware name: To Be Filled By O.E.M. To Be Filled By O.E.M./J5005-ITX, BIOS P1.40 08/06/2018 Nov 17 12:04:30 NAS kernel: RIP: 0010:nfserrno+0x45/0x51 [nfsd] Nov 17 12:04:30 NAS kernel: Code: c3 cc cc cc cc 48 ff c0 48 83 f8 26 75 e0 80 3d bb 47 05 00 00 75 15 48 c7 c7 17 a4 99 a0 c6 05 ab 47 05 00 01 e8 42 07 eb e0 <0f> 0b b8 00 00 00 05 c3 cc cc cc cc 48 83 ec 18 31 c9 ba ff 07 00 Nov 17 12:04:30 NAS kernel: RSP: 0018:ffffc900005ffb58 EFLAGS: 00010282 Nov 17 12:04:30 NAS kernel: RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000000000000027 Nov 17 12:04:30 NAS kernel: RDX: 0000000000000001 RSI: ffffffff820d7be1 RDI: 00000000ffffffff Nov 17 12:04:30 NAS kernel: RBP: ffffc900005ffdb0 R08: 0000000000000000 R09: ffffffff82244bd0 Nov 17 12:04:30 NAS kernel: R10: 00007fffffffffff R11: ffffffff82876e76 R12: 0000000000000011 Nov 17 12:04:30 NAS kernel: R13: 0000000000e00000 R14: ffff88815a2591a0 R15: ffffffff82909480 Nov 17 12:04:30 NAS kernel: FS: 0000000000000000(0000) GS:ffff888470100000(0000) knlGS:0000000000000000 Nov 17 12:04:30 NAS kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Nov 17 12:04:30 NAS kernel: CR2: 000055d456171350 CR3: 00000003229b0000 CR4: 0000000000352ee0 Nov 17 12:04:30 NAS kernel: Call Trace: Nov 17 12:04:30 NAS kernel: <TASK> Nov 17 12:04:30 NAS kernel: nfsd4_encode_fattr+0x1372/0x13d9 [nfsd] Nov 17 12:04:30 NAS kernel: ? getboottime64+0x20/0x2e Nov 17 12:04:30 NAS kernel: ? kvmalloc_node+0x44/0xbc Nov 17 12:04:30 NAS kernel: ? __kmalloc_node+0x1b4/0x1df Nov 17 12:04:30 NAS kernel: ? kvmalloc_node+0x44/0xbc Nov 17 12:04:30 NAS kernel: ? override_creds+0x21/0x34 Nov 17 12:04:30 NAS kernel: ? nfsd_setuser+0x185/0x1a5 [nfsd] Nov 17 12:04:30 NAS kernel: ? nfsd_setuser_and_check_port+0x76/0xb4 [nfsd] Nov 17 12:04:30 NAS kernel: ? nfsd_setuser_and_check_port+0x76/0xb4 [nfsd] Nov 17 12:04:30 NAS kernel: nfsd4_encode_getattr+0x28/0x2e [nfsd] Nov 17 12:04:30 NAS kernel: nfsd4_encode_operation+0xad/0x201 [nfsd] Nov 17 12:04:30 NAS kernel: nfsd4_proc_compound+0x2a7/0x56c [nfsd] Nov 17 12:04:30 NAS kernel: nfsd_dispatch+0x1a6/0x262 [nfsd] Nov 17 12:04:30 NAS kernel: svc_process+0x3ee/0x5d6 [sunrpc] Nov 17 12:04:30 NAS kernel: ? nfsd_svc+0x2b6/0x2b6 [nfsd] Nov 17 12:04:30 NAS kernel: ? nfsd_shutdown_threads+0x5b/0x5b [nfsd] Nov 17 12:04:30 NAS kernel: nfsd+0xd5/0x155 [nfsd] Nov 17 12:04:30 NAS kernel: kthread+0xe4/0xef Nov 17 12:04:30 NAS kernel: ? kthread_complete_and_exit+0x1b/0x1b Nov 17 12:04:30 NAS kernel: ret_from_fork+0x1f/0x30 Nov 17 12:04:30 NAS kernel: </TASK> Nov 17 12:04:30 NAS kernel: ---[ end trace 0000000000000000 ]---Nov 17 12:04:14 NAS shfs: shfs: ../lib/fuse.c:1450:
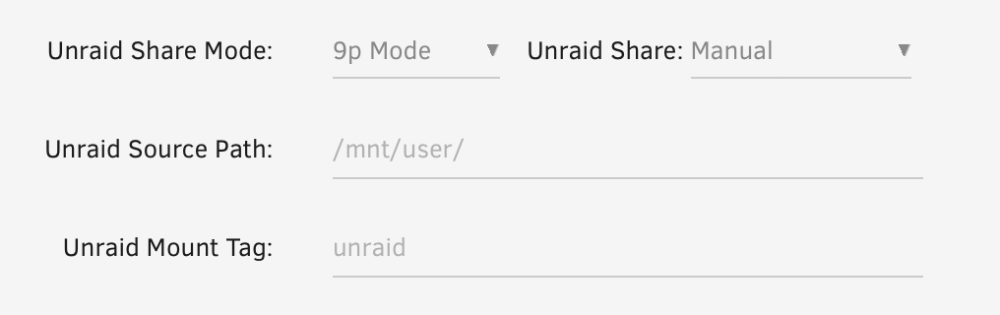
-
Yes I've done all of that. My only aim with smb-custom was to define the path explicitly - bypass shfs to avoid SMB-related fuse errors which have broken my shares/necessitated restarts. The rest of those settings I took as-is from testparm.
-
Got it. Shame there's no simple way to confirm, makes me wonder about my own customizations. Huh, so is it better to put the smb-custom include at the top of smb-extras so scope is [global] when it returns? e.g. #Custom include = /boot/config/smb-custom.conf [global] # Fix for 6.9.0-rc2 Mac client search spotlight backend = tracker # tweaks from https://wiki.samba.org/index.php/Configure_Samba_to_Work_Better_with_Mac_OS_X min protocol = SMB2 I have a dedicated pool that serves docker, VM and scratch called active (single-disk, XFS), cache is separate. Here's my full smb-custom.conf if you're curious:
-
That's strange because I don't think spotlight indexing enters into it. If I had to guess maybe some time within those few hours you disconnected/reconnected automatically or explicitly and that's what did it. Either way, glad it worked.
-
Installed and rebooted - mixed results: The smb-shares include line is still present in the share: [system] case sensitive = Yes comment = system data include = /etc/samba/smb-shares.conf The smb-unassigned include line is gone from the share but it's not present anywhere (according to testparm) Should I add it manually to smb-extras and if so where? [global] # Fix for 6.9.0-rc2 Mac client search spotlight backend = tracker # tweaks from https://wiki.samba.org/index.php/Configure_Samba_to_Work_Better_with_Mac_OS_X min protocol = SMB2 #Custom include = /boot/config/smb-custom.conf
-
Only WARNINGS before hitting enter but I think those were always there: root@NAS:/boot/config# testparm -v Load smb config files from /etc/samba/smb.conf lpcfg_do_global_parameter: WARNING: The "null passwords" option is deprecated lpcfg_do_global_parameter: WARNING: The "syslog" option is deprecated Loaded services file OK. Weak crypto is allowed by GnuTLS (e.g. NTLM as a compatibility fallback) Server role: ROLE_STANDALONE Press enter to see a dump of your service definitions
-
Add the following line to the [global] section of SMB Extras (which you can do via the GUI): spotlight backend = tracker And the following line to /boot/config/smb-fruit.conf (which will add it to each share) spotlight = yes You can use this post as a reference but I wrote it before the advent of smb-fruit, so this new way is better.
-
I did a quick test on a share with only a dozen files and no subdirs: With my setup search returned the matching result instantly. Then I added spotlight backend = noindex (the default) to smb-custom, restarted samba and searched again. No results after 30 seconds. So I want to say the fix is an improvement except when I removed the newly-added backend line from smb-custom and restarted, nothing changed - still no results. Maybe a proper test requires stopping and starting the array, which I can't do at the moment.
-
Oh! Well that's useful information. I've had the fix in place since 6.9 broke it. I must have missed a fix in the release notes. I'll test without it, thanks.
-
Partially - with the fix I can (once again) search my shares in Finder. That backend override to a nonexistent tracker fails gracefully (the default does not.) Proper "spotlight" is more comprehensive, some solutions on this forum but I haven't investigated.
-
AFAIK the fix still requires a global setting (which you're seeing in extras) and a per-share setting (which I have in fruit)
-
Right, I have my per-share customizations in smb-fruit. Why does something look off? (Ignore the commented lines, they're leftover from earlier experimentation)














