




weirdcrap
Members
-
Joined
-
Last visited
Everything posted by weirdcrap
-
I had no problems with the commands above that I can recollect. Just be sure to run FIND before you run FIND & DELETE to make sure you aren't getting anything included you don't want.
-
Alright, was hoping something more conclusive would be in the log. I'll move it to the back ports outside of the case if i have problems with the other internal header. if it still drops out I'll buy a new flash.
-
zero issues other than human error and your typical disk problems. This is the first flash related issue or error I believe I've ever had in my entire time using UnRAID. I buy quality flash drives and limit writes to them to avoid this exact type of situation. EDIT: Well this is not entirely true, I had a roof leak in my rental house 3 years ago that got into my server and blew my mobo and flash. This is that replacement flash drive so its only about ~3 years old.
-
Have you modified the plugin with custom rsync flags (under the settings)? the -m flag would prune empty directories but doesn't appear to be part of the default flags. I've never used the gather before, only scatter and I've never seen this behavior. You could turn up the logging verbosity to full and perform a dry run to look and see what rsync's doing without actually affecting your shares or folder structure.
-
Yeah sorry should have been clear, its an internal USB 2.0 header and USB 2.0 flash drive.
-
went to pull something from my array and discovered my shares are missing....it appears my flash drive has died or had some sort of problem? UnRAID reports its offline. void-diagnostics-20221029-0806.zip The flash drive is only a few years old. Its a sandisk Cruzer Fit 16GB. I don't believe the USB drive model is the problem, I've used this same model for nearly a decade between my two systems and this is the first time I've ever had an issue. I do use a startech internal USB adapter that I've had for quite some time (since unraid 4.7 lol). Oct 29 05:04:44 VOID kernel: mdcmd (69): set md_write_method 1 Oct 29 05:04:44 VOID kernel: Oct 29 06:48:03 VOID webGUI: Successful login user root from 192.168.1.208 Oct 29 06:48:34 VOID kernel: usb 3-6: reset high-speed USB device number 3 using xhci_hcd Oct 29 06:48:39 VOID kernel: usb 3-6: device descriptor read/64, error -110 Oct 29 06:48:53 VOID webGUI: Successful login user root from 192.168.1.208 Oct 29 06:48:55 VOID kernel: usb 3-6: device descriptor read/64, error -110 Oct 29 06:48:55 VOID kernel: usb 3-6: reset high-speed USB device number 3 using xhci_hcd Oct 29 06:49:01 VOID kernel: usb 3-6: device descriptor read/64, error -110 ### [PREVIOUS LINE REPEATED 1 TIMES] ### Oct 29 06:49:17 VOID kernel: usb 3-6: reset high-speed USB device number 3 using xhci_hcd Oct 29 06:49:22 VOID kernel: usb 3-6: device descriptor read/8, error -110 ### [PREVIOUS LINE REPEATED 1 TIMES] ### Oct 29 06:49:27 VOID kernel: usb 3-6: reset high-speed USB device number 3 using xhci_hcd Oct 29 06:49:33 VOID kernel: usb 3-6: device descriptor read/8, error -110 ### [PREVIOUS LINE REPEATED 1 TIMES] ### Oct 29 06:49:38 VOID kernel: usb 3-6: USB disconnect, device number 3 Oct 29 06:49:38 VOID kernel: scsi_io_completion_action: 9 callbacks suppressed Oct 29 06:49:38 VOID kernel: sd 0:0:0:0: [sda] tag#0 UNKNOWN(0x2003) Result: hostbyte=0x03 driverbyte=DRIVER_OK cmd_age=94s Oct 29 06:49:38 VOID kernel: sd 0:0:0:0: [sda] tag#0 CDB: opcode=0x28 28 00 00 00 8f a0 00 00 01 00 Oct 29 06:49:38 VOID kernel: blk_print_req_error: 9 callbacks suppressed Oct 29 06:49:38 VOID kernel: I/O error, dev sda, sector 36768 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 0 Oct 29 06:49:38 VOID kernel: device offline error, dev sda, sector 36768 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 ### [PREVIOUS LINE REPEATED 1 TIMES] ### Oct 29 06:49:38 VOID kernel: device offline error, dev sda, sector 20241952 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 0 Oct 29 06:49:38 VOID kernel: device offline error, dev sda, sector 20241952 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 ### [PREVIOUS LINE REPEATED 1 TIMES] ### Oct 29 06:49:38 VOID kernel: device offline error, dev sda, sector 36768 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 ### [PREVIOUS LINE REPEATED 1 TIMES] ### Oct 29 06:49:38 VOID kernel: device offline error, dev sda, sector 18112 op 0x0:(READ) flags 0x80700 phys_seg 2 prio class 0 Oct 29 06:49:38 VOID kernel: device offline error, dev sda, sector 18114 op 0x0:(READ) flags 0x80700 phys_seg 6 prio class 0 Oct 29 06:49:38 VOID kernel: FAT-fs (sda1): Directory bread(block 18080) failed Oct 29 06:49:38 VOID kernel: FAT-fs (sda1): Directory bread(block 18081) failed Oct 29 06:49:38 VOID kernel: FAT-fs (sda1): Directory bread(block 18082) failed Oct 29 06:49:38 VOID kernel: FAT-fs (sda1): Directory bread(block 18083) failed Oct 29 06:49:38 VOID kernel: FAT-fs (sda1): Directory bread(block 18084) failed Oct 29 06:49:38 VOID kernel: FAT-fs (sda1): Directory bread(block 18085) failed Oct 29 06:49:38 VOID kernel: FAT-fs (sda1): Directory bread(block 18086) failed Oct 29 06:49:38 VOID kernel: FAT-fs (sda1): Directory bread(block 18087) failed Oct 29 06:49:38 VOID kernel: FAT-fs (sda1): Directory bread(block 18088) failed Oct 29 06:49:38 VOID kernel: FAT-fs (sda1): Directory bread(block 18089) failed Oct 29 06:49:38 VOID emhttpd: Unregistered - flash device blacklisted (EBLACKLISTED2) EDIT: Shut down system, Windows can see the drive and all of its contents. Copying the flash contents to a folder on my PC as a backup went smoothly, no files threw errrors. Windows claims it found issues on the drive but when I ran the repair it reported no issues... I moved the starttech usb adapter to another header on the board and the system came back up just fine, albeit running a parity check. Does this look more like a flash problem or a header/adapter problem?
-
No, when this issue occurs everything loses DNS resolution. Webui, Dockers, SSH, everything. I haven't tried spinning up a VM yet but that's next on my list. The router is a Zyxel USG110 (not my choice but it's not my network). I'm talking to the business owner about putting in my own router in front of my gear. No openWRT. UnRAID doesn't pull DHCP, all of it's network settings are statically configured and DNS is set to go straight to cloudflare and google for lookups.
-
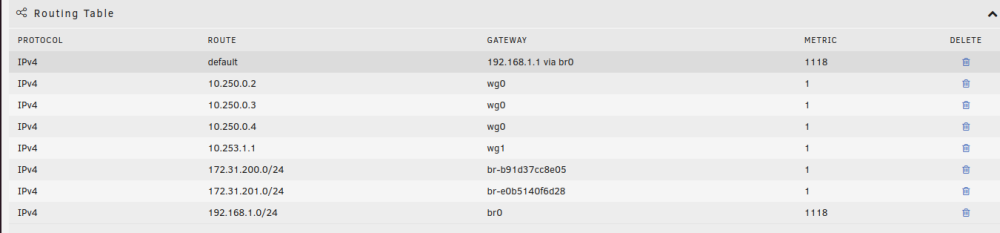
UnRAID v6.11.1 void-diagnostics-20221023-0851.zip It's been a long time since I've messed with my network config on VOID and I noticed my gateway metric was statically set at 209 and I honestly can't remember why. If I clear out 209 and let UnRAID determine its metric it sets it too a whopping 1118? I've read that the metric is the calculated "cost" of using the route so why is mine so high? there are no other hops between the server and router. On my other server letting UnRAID determine the metric just sets it at 1, which is what I would expect here since I don't have any other gateways or static routes set, right? Should I just statically set VOID's metric at 1? Are there any adverse affects if its calculated high? EDIT: Statically setting it to 1 doesn't seem to change anything so I guess it's fine but I'd still like to know why it auto determines the metric to be so high? It's behind a pfsense router if that's a clue...
-
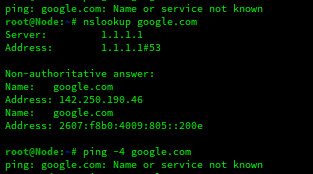
Even with the router on the latest firmware I have yet again lost DNS but nslookup continues to work. I'm going to have to install my own router apparently as I don't know what else to do to troubleshoot this. I'm sick and tired of my server just randomly losing the ability to resolve ANY DNS names via normal means.
-
The USG110 is a few versions behind on firmware, I've asked them to update it if possible (assuming it isn't held back for a reason). If that doesn't fix it I'll move forward with getting my own router installed (if possible) unless anyone has any other ideas.
-
This is incorrect, NODE has never been on 192.168.1.x. I just double checked the first diagnostic file I posted to be sure. From Network.cfg: IPADDR[0]="192.168.20.249" NETMASK[0]="255.255.255.0" GATEWAY[0]="192.168.20.254" DNS_SERVER1="8.8.8.8" DNS_SERVER2="1.1.1.1" DNS_SERVER3="9.9.9.9" Unfortunately this is not possible. NODE is hosted at a friend's IT business 4 hours away (they've got fiber, I don't). I can't ask them to tear down their business network just for me to troubleshoot my plex server. Completely swapping out their router is out of the question. I can see about procuring my own router to send over there and splitting the fiber demarc between their router and my own. But that will take some time to get set up if they'll allow it. In the meantime I can share what I know about the network: The router is a Zyxel USG110. None of the USG services (IDS, AV, Content FIlter, etc) are enabled so they shouldn't be causing me any grief here. I'm in the business's internal VLAN and have my own public static IP. The router doesn't handle DHCP/DNS directly for this VLAN, that's done by a Windows AD server. I don't pull DHCP or DNS from their AD server anyway since I've got my IP and DNS servers statically set in UnRAID. I've asked everyone who works there on multiple occasions and no one else has DNS resolution issues, just me. I am the only linux user in their network though.
-
That destination host unreachable line is a new symptom, it was never there before I upgraded to 6.11 NODE is on 192.168.20.x, it's router is at 192.168.20.254 VOID is on 192.168.1.x I do not have any issues with DNS on VOID. It's an entirely separate network with its own ISP, router, switches, etc.
-
When DNS goes out ping -4 google.com does NOT work. I've still got no clue what's causing this. root@Node:~# nslookup google.com Server: 8.8.8.8 Address: 8.8.8.8#53 Non-authoritative answer: Name: google.com Address: 142.251.32.14 Name: google.com Address: 2607:f8b0:4009:80a::200e root@Node:~# ping -4 google.com ping: google.com: Name or service not known root@Node:~# ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. From 192.168.20.254 icmp_seq=1 Destination Host Unreachable 64 bytes from 8.8.8.8: icmp_seq=1 ttl=59 time=12.7 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=59 time=12.5 ms ^C --- 8.8.8.8 ping statistics --- 2 packets transmitted, 2 received, +1 errors, 0% packet loss, time 1002ms rtt min/avg/max/mdev = 12.488/12.617/12.746/0.129 ms root@Node:~# ping -4 google.com ping: google.com: Name or service not known root@Node:~# ping -4 google.com ping: google.com: Name or service not known
-
Passed both a short and long SMART test. Moved it to a different slot in a different norco and it's rebuilding now. Glad I'm moving out of these Norcos to direct connected disks, they've been getting more and more finicky.
-
Thanks. I'm pretty sure its the connectors in this particular slot in one of my norco 5 bays. This same slot dropped another disk just a few weeks ago.
-
void-diagnostics-20221008-1651.zip Unraid v6.11.1 Just added a 2nd parity drive and started the parity sync and now one of my disks has been disabled. I've never had a disk drop during a parity rebuild before, let alone when I'm adding a second drive. Can the rebuild finish with an emulated disk? I guess so as it's still chugging along. Should I cancel the parity rebuild and try to use the new disk to replace the "failed" disk? Should I just let it finish? Anecdotally I've been having a lot of disk issues with this server lately. I think this is the third disabled disk in six months. The disks always seem to pass SMART but I don't want to risk it so I always put new ones in then another one drops. Very strange.
-
I would also be curious if ich777 plans on continuing to maintain un-get or if I should switch to this. Can we get a brief breakdown of what improvements are in this new plugin? Does it just pull stuff from the slackware repo like ich's plugin or does it also include things that require compiling? In the meantime you can always just place the package file in /boot/extra so you can stay on 6.11
-
I'm still having issues with this. Netbios is off and I'm on the latest 6.11.0 ping -4 google.com worked but so did ping google.com immediately after so I assume it's just the issue fixed itself again. It doesn't seem to be as permanent as it used to be. If I just wait 5 minutes DNS will just start working again.
-
I think they were suggesting that simply unassigning the disk and reassigning it would just magically make the array whole again. I've started a rebuild on the data drive. Thanks for your help.
-
@trurl I wasn't trying to do the act of "hot swapping" a drive. I'm simply referring to the physical type of bay where you can easily open it, remove a disk, and insert another without having to unscrew anything. Sleds or trays I guess would be a better word. All I was trying to do was remove a disk that isn't part of my array from the machine. I accidentally popped open the wrong tray.
-
Unraid knows its the same disk, that won't change anything.
-
I already restarted, it didn't help.
-
I'm an idiot. I wasn't looking closely enough at which hot swap bay I opened and pulled an active array drive while the array was running. The disk is now disabled. I literally just finished a parity check an hour ago, so the parity should be 100% correct and up to date. Can I just run new config-retain current, and check the box for parity being valid before I start the array? Or am I better off treating the now disabled disk as a new disk and adding it back into the array to be rebuilt from parity?
-
Excellent, glad I was right on the money. Thanks for the info about parity 2, I do plan on adding a second parity drive given how many disks I have in the array. I don't often shuffle drive orderings but its good to know I'll need to be extra careful once I add the second disk.
-
I'm wanting to both upgrade my parity drive as well as remove two data drives that I've emptied. The end goal being transplanting my array to a 4u rack case instead of the tower its in now. Can I simply use new config (retain current config) and assign the new parity drive, remove the old one, and remove the two disks I no longer need in one fell swoop? Can I also reorder the drives to fill in the empty slots by the removed drives? It shouldn't matter right since I've already invalidated parity?


