




weirdcrap
Members
-
Joined
-
Last visited
Everything posted by weirdcrap
-
I saw plex in top and ps but I didn't know about loads, thanks.
-
4K content does have some other downsides besides the space it takes up apparently. I didn't even consider the prolonged CPU impact of scanning 4K content into the library vs 1080p content. The 1080p stuff scanned quick enough it couldn't drag down the array performance very far. Now that it's scanned in everything it seems to be back to normal. I've got all m dockers turned back on and it's checking at around 180MB/s. Is there a disk activity read out in there? is that just top? How did you find this out for my future reference?
-
Yeah it's definitely a docker. When the speed tanks stopping all dockers fixes it. I haven't added a new docker in months and this is the first time I'm aware of this ever happening so I'm at a bit of a loss. Is there a way to see disk activity on a per docker basis somehow? I'm having trouble narrowing it down by just starting and stopping containers. I guess I need to wait longer before each container start to better identify my culprit. EDIT: It appears to be Plex, its in the maintenance window and doing library tasks. I've never in my life seen a plex library scan cripple unraid's performance so much. It's like any disk activity during the parity check just completely cripples it's speed. This was not the case in previous versions (at least not that I've ever noticed). I've had parity checks running in the past with every single docker running and multiple streams going and it's never been like this. What gives? EDIT2: Could the performance hit invoked by plex be 4k related? Just last night I added my first few pieces of 4k content to my server. This morning would have been when they got scanned into the library and the shows would have had intro detection run on them. Maybe I've just never noticed the performance impact from non-UHD content before because plex chews through them much quicker? It took 20 minutes to run intro detection on 6 episodes of Planet Earth II node-diagnostics-20220927-0839.zip
-
I thought I grabbed them after I noticed the speed dropped in the parity check. I'm running Jbartlett's DiskSpeed docker right now to make sure none of my drives are the culprit then I'll start another parity check and grab new logs.
-
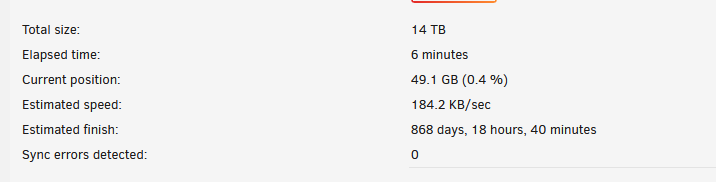
Not sure if this related or not but I just upgrade from 6.11 RC5 to 6.11 stable. Upon rebooting the server never came back up so I had to perform a hard reboot which obviously initiated a parity check. Well the server got .4% into the check and the speed dropped like a rock from 160MB/s~ (which is normal) down to 2.1MB/s and it has stayed there ever since. I've never had a speed issue like this before. Stopping and starting the array didn't change anything. Rebooting didn't change anything. Upon starting another check it starts out fine, hits 0.4% and just drops. It doesn't seem to recover once the speed drops, it just stays there until I cancel it. What gives? node-diagnostics-20220927-0718.zip
-
So this continues to get stranger. I got home and ran a short smart test on the disk and it passed. I transferred it to another PC to do a long smart test because I had issues with it not spinning down in UD. It passed that as well. Despite it passing I opted to replace the disk anyway. I precleared the new disk and started the parity rebuild. Different slot than the previous disk and everything. Not even an hour later it has also failed throwing a ton of errors. What gives? If it was a cabling issue it shouldn't have followed me to another slot... void-diagnostics-20220925-2144.zip EDIT: CA AppData backup apparently got real pissed that I didn't have the array started for a few days (it may have tried to run a backup) and wouldn't let me stop the array. I ended up having to force the system down so I could move the drive to another slot and try again. EDIT2: so there's something really strange going on here. Now every time I try to stop the array it hangs on unmounting the disk shares. last time it was the CA user share, this time it's the cache drive. syslog.txt EDIT3: I'm giving a rebuild one more go in another slot on an entirely different RAID controller this time. If it fails again hopefully someone here has a better idea on what's going on than I do.
-
threw a deprecated error in the logs but seems to have worked. Thanks. I've gone ahead and ordered a new drive which should hopefully be waiting for me when I get home. I'll update this post once I can get my hands on the server and see whats what.
-
I'm actually remote, probably won't be able to get to it for about a week. I was hoping I could give it a reboot in the meantime to atleast fix the webui so I can run a Smart test and see if the disk has failed or something happened with the connections. Or if someone like johnny had any insight into what the controller errors pointed to. I guess to play it safe I should just try to shut it down until I can get home. How do I initiate a clean power down from the terminal since the webui seems to be borked?
-
v6.11-RC5 This is a follow up to this post. I had repaired the errors and was running a final non-correcting check. was running a non-correcting parity check when one of my disks decided to sh*t the bed? or Maybe the sas controller lost contact? Now UnRAID is stuck on a paused "Read Check". This was the last thing before a flood of read and write failures: Sep 21 16:47:26 VOID kernel: mpt2sas_cm1: log_info(0x31110d01): originator(PL), code(0x11), sub_code(0x0d01) Sep 21 16:47:26 VOID kernel: sd 12:0:2:0: [sdo] tag#1652 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Sep 21 16:47:26 VOID kernel: sd 12:0:2:0: [sdo] tag#1652 Sense Key : 0x2 [current] Sep 21 16:47:26 VOID kernel: sd 12:0:2:0: [sdo] tag#1652 ASC=0x4 ASCQ=0x0 Sep 21 16:47:26 VOID kernel: sd 12:0:2:0: [sdo] tag#1652 CDB: opcode=0x88 88 00 00 00 00 00 04 29 0f 48 00 00 04 00 00 00 Sep 21 16:47:26 VOID kernel: I/O error, dev sdo, sector 69799752 op 0x0:(READ) flags 0x0 phys_seg 128 prio class 0 Now it's like the webui is half broken? Neither button to resume or cancel the check works. Firefox acts like it's loading (refresh symbol changes to stop) but nothing ever happens. I tried to change the spin down delay on the failed disk to run an extended smart test and the apply button doesn't work. I tried to run a short smart test and the button for it doesn't work either. I guess at this point I just restart the server to try to restore some semblance of functionality? void-diagnostics-20220921-1650.zip
-
I suppose that's fair though I'd still like the ability to decide when enough logging is enough. With a fair amount of RAM even millions of parity errors shouldn't fill up the log if I bump up the mount point for /var/log. Yes I always have intermittent connection issues during parity checks. I think it's the Norco bays I'm using. I plan on getting this moved into a new case soon and direct connecting disks instead of having a shared power backplane like they do now. After that I plan on going dual parity.
-
UnRAID 6.11-RC4 I ran a parity check after replacing a failing disk and now I've got a bunch of parity errors. Last month's parity check had zero errors. My general process when I get parity errors is to let the current check finish, noting the reported incorrect sectors. I then run a second non-correcting check to verify the reported sectors are the same before I run a correcting check to fix them. If they aren't the same I assume its a memory problem and start checking my RAM rather than re-write my parity. Looking over my logs today I noticed this line: "recovery thread: stopped logging" and as indicated it doesn't appear to be reporting sectors anymore despite the parity error count continuing to increase? Why was this done and how is it helpful to the end user? I do not like having errors suppressed for no good reason. Now when I run my second check I'll only be able to compare the errors up to whatever point the logging stops. I mean sure having a few hundred sectors report the same is probably a good indication its not RAM flipping bits or anything but still I'd like to know every sector that generates an error not just some of them. Can I force UnRAID to log all reported sectors? How else can I go about ensuring my parity errors aren't caused by bad RAM before I overwrite my parity data with a correcting check? void-diagnostics-20220918-1342.zip
-
How do we go about requesting package inclusions? Could we get screen included? It has no extra dependencies and its really useful for big data transfers in the console. EDIT: It has been pointed out to me that tmux will do everything screen does and is already included if you run unassigned devices Plus. I'd still argue screen should be included in the base OS for those who may not use unassigned devices though.
-
This is a minor annoyance/feature request, could we find a way to preserve the settings from the Dynamix TRIM plugin and transition them over to the built in support? The update disabled TRIM on both my servers and cleared the schedule. I know its a one time inconvenience but I imagine it would save some grumbling from users about losing their schedules/not realizing TRIM got turned off.
-
You can grab it from the 3rd party Slackers repository: https://slackware.pkgs.org/current/slackers/iperf3-3.11-x86_64-1cf.txz.html Direct Download: https://slack.conraid.net/repository/slackware64-current/iperf3/iperf3-3.11-x86_64-1cf.txz
-
No I occasionally use it to unpack archives I have stored on the command line. Thanks for the link
-
I think MOSH would probably fit the bill for SSH: https://mosh.org/ It's been a while since I played with it but I recall being able to pick up sessions from other devices. But this would have to be installed via /boot/extra and has some dependencies.
-
Oh, I guess I missed this comment, the last reply I saw from you seemed to imply dmacias would come through and update this closer to stable because he was good about staying on top of it.... So NerdPack is no longer being kept up to date? Dmacias is just no longer working on it? Would someone be able to adopt the plugin? As others have stated above me I'm not trying to turn UnRAID into a linux workstation. However there are a number of extremely useful benchmarking, troubleshooting, usability, etc packages provided by NerdPack that people in the community utilize to make their UnRAID experience better. Other plugins also rely on things provided by NerdPack, like bergware's system temp plugin needs PERL initially to detect sensors and autofan speed requires PERL as well. So what's our option moving forward, to use /boot/extra and keep our own extra packages updated? Will the warning to use NerdPack be removed from FCP? Going back over the thread that lead to this plugin LimeTech makes it pretty clear they have zero interest in adding additional command line tools as "most users never drop to the shell" & "everything should be available from the GUI" so I guess we're on our own for additional packages. Guess I'm going to be learning about how to choose slackware packages for UnRAID. Does UnRAID track a specific slackware release? EDIT: For anyone else wondering you can check the slackware version with: v cat /etc/slackware-version
-
I went ahead and threw PERL in there anyway. I only have PERL, Screen, SSHFS, and UnRAR and no issues so far. I did a test install of the UnRAR package I linked above and it seems to be working so if anyone is concerned about that CVE I posted you should be able to safely replace the NerdPack version with the one I linked above. ***EDIT: See my edit in my previous reply. Really the only reason I'm gunghoe to get on the RC is to try and resolve my DNS Issues.
-
@dmaciasThe latest version of unRAR supplied is subject to a directory traversal vulnerability: https://nvd.nist.gov/vuln/detail/CVE-2022-30333#vulnCurrentDescriptionTitle I found a slackware package for 6.1.7 (needs to be >= 6.1.2) so assuming this is usable in UnRAID it should be a simple swap? *SEE EDIT BELOW https://slackware.pkgs.org/current/slackers/unrar-6.1.7-x86_64-1cf.txz.html For those of you who don't want to wait for the plugin to be updated can place your packages in /boot/extra for install. This is unsupported, not recommended by FCP (it will produce a warning on scan), and may break your system but in my testing with the few packages I use it works fine for the time being. EDIT: I totally misread the CVE version #. It's 6.12 or later not 6.1.2 . So the version I linked above, while newer than what's in NerdPack, still doesn't address that CVE. I can't seem to find a 6.12 version for slackware anywhere? Can anyone else?
-
It looks like way back in May python invoked the out of memory killer and it killed QEMU. May 7 21:05:54 Tower kernel: python3 invoked oom-killer: gfp_mask=0x100cca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=0 .... May 7 21:05:54 Tower kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=3ea9e18112ed2dd06031f35c6351a2de56ee7b8fb2ce9631019b9f7ca51e3881,mems_allowed=0,global_oom,task_memcg=/machine/qemu-1-V-DLC.libvirt-qemu,task=qemu-system-x86,pid=15497,uid=0 May 7 21:05:54 Tower kernel: Out of memory: Killed process 15497 (qemu-system-x86) total-vm:17946876kB, anon-rss:17028860kB, file-rss:72kB, shmem-rss:23104kB, UID:0 pgtables:35208kB oom_score_adj:0 May 7 21:05:54 Tower kernel: oom_reaper: reaped process 15497 (qemu-system-x86), now anon-rss:16kB, file-rss:68kB, shmem-rss:4kB I only see the one OOM kill so it hasn't happened again in several months so it is probably safe to simply ignore it unless it happens again. You appear to have some VMs running, assigned about 24GB of RAM if I'm reading your XMLs correctly. That plus the dockers listed in your sig you may be pushing it a little to close on your RAM usage sometimes as the underlying OS needs some RAM for itself. You could try setting artificial limits for the dockers (using --memory=xG in the extra parameters for each docker where X is the limit in GB) and reducing the assigned RAM on the VMs a gigabyte or two at a time until the errors stop for good. But again if this only happened the one time and things seemed to be running OK otherwise I'd probably just leave it be.
-
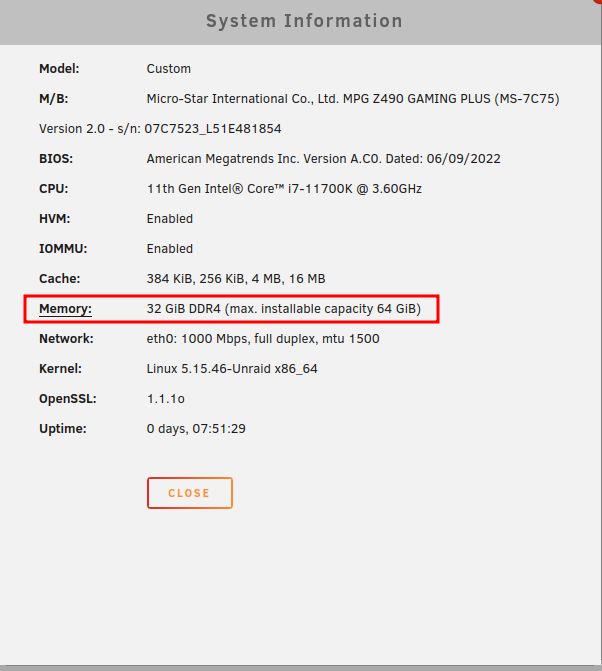
Built a new system with this board and UnRAID reports a max install-able RAM capacity of 64GB. But everything I can find (MSI website, newegg, etc) suggests it should support up to 128GB. I don't plan on installing more than 64GB of RAM in this anytime soon if ever, but I'm still curious if UnRAID is detecting this incorrectly or if the advertised RAM capacity is wrong... Anyone got this board and actually have it maxed out with RAM? node-diagnostics-20220731-2129.zip
-
I may have to go the VM route as well. The new hardware made no difference in the file transfer speeds. Not that I honestly expected it to.😥
-
Yeah this appears to be broken and any previously installed tools from it are missing... My whole *arr setup relies on SSHFS and it appears to be missing now. Interestingly I have no errors in my logs but trying to load the NerdPack interface just loads infinitely and as I mentioned above my previously installed packages are missing.
-
@Quick_FOXmy resolv.conf is intact with docker running. @SquidI can give the RC a try. It's difficult for me to diagnose as it seems to happen randomly. Maybe once a month or so. I will also disable NETBIOS as suggested. EDIT: Waiting on trying the RC until NerdPack gets updated as I need several of the tools it offers.
-
Unfortunately no, I'm at a loss with my own issue already lol. I'd take a look at what has already been suggested in this thread to see if you can narrow your issue down further. So when you lose connectivity your still able to resolve hostnames via ping? I'm not able to resolve any hostnames at all EXCEPT with NSLookup. It seems to be the only thing still capable of resolving domain names when I run into whatever is causing this issue... This doesn't seem to be a common problem, I've only found a few threads on it that sound similar enough to my issue and unfortunately none of them have yielded any further clues as to what's wrong. This server is getting rebuilt with all new hardware next month so I'm trying to just keep it coasting until then, see if the new hardware magically resolves any of the issues I've been having.


