




weirdcrap
Members
-
Joined
-
Last visited
Everything posted by weirdcrap
-
Just lost DNS again. Still no idea why NSLookup works but things like ping, checking for plugin/docker updates, etc all fail. Interestingly, i regained DNS functionality without having to restart or do anything other than wait this time. Very strange...
-
Still having the same problems with this. I'm going to rebuild the server from scratch with all new hardware and we'll see if that makes any difference. I'm not holding out any hope though.
-
When this happens I can reach the gateway and internet, but by IP only. I can SSH from the affected unraid server into the gateway by IP, and I can ping outside servers like 8.8.8.8. For all intents and purposes the internet is working, just not name resolution UnRAID was set to use only external DNS servers (8.8.8.8, 1.1.1.1, 9.9.9.9) when this started occurring. I've tried switching to my router's DNS server for troubleshooting but doing so made no difference. I looked at that link you've posted but I don't really know how UnRAID's DNS system works. Does nslookup use a different lookup method vs ping in UnRAID? That might explain why nslookup works while a simple ping to an external domain does not.
-
Bump. This continues to happen. Ping will tell me name or service not known but nslookup returns responses so I guess DNS is working but then what is happening to my ability to resolve names?
-
Alright so this finally happened again. Now on v6.10.1 I ran nslookup against google.com and it returned a proper answer from my LAN router as well as 8.8.8.8: root@Node:~# ping google.com ping: google.com: Name or service not known root@Node:~# nslookup google.com Server: 192.168.20.254 Address: 192.168.20.254#53 Non-authoritative answer: Name: google.com Address: 172.217.4.206 Name: google.com Address: 2607:f8b0:4009:806::200e root@Node:~# nslookup google.com 8.8.8.8 Server: 8.8.8.8 Address: 8.8.8.8#53 Non-authoritative answer: Name: google.com Address: 172.217.0.174 Name: google.com Address: 2607:f8b0:4009:808::200e root@Node:~# nslookup google.com 192.168.20.254 Server: 192.168.20.254 Address: 192.168.20.254#53 Non-authoritative answer: Name: google.com Address: 172.217.4.206 Name: google.com Address: 2607:f8b0:4009:806::200e root@Node:~# So then wtf is causing this? Sonarr/Radarr can't reach any of my external resources, I can't ping domain names from the terminal, nothing DNS related seems to work yet nslookup seems to suggest DNS is fine?
-
Duh why didn't I think of nslookup. I was wanting to use dig but the BIND package seems to have disappeared from NerdPack. I was also hoping for a way to check the literal status of the service, something equivalent to systemctl status ServiceName (I'm a debian guy mostly). I haven't lost DNS again so far. I also switched my first DNS server to my router rather than an external server. Saw some threads here about DNS issues being resolved doing that so I figured why not.
-
What happened to the bind package? Am I just not seeing it? Or is it because I'm on RC5?
-
Unraid v6.10-rc5 Diagnostics are from a fresh boot so my previous syslog is also attached: node-diagnostics-20220505-0737.zip syslog-20220505-073254.txt This issue is not new for me in RC5, it's happened before but its been years since it last occurred. It's now happened twice in the last week. DNS is statically configured to use Google, Cloudflare, & Quad9. Out of the blue my server will lose the ability to resolve any host names at all. I don't realize it's happened until I log into Radarr/sonarr and see errors about all my indexers, download clients, literally anything requiring a DNS lookup being unreachable. I console in and confirm that I can't ping any hostname with a "name or service unknown" error. Pinging internal and external IP addresses works fine. I don't see anything in the syslog to indicate what the issue might be. I can usually fix it with a restart but its annoying to have to reboot the entire server just to get DNS back up. I've tried just stopping the array, shuffling the DNS servers, and hitting apply in hopes of reviving DNS but it generally doesn't work. Is there a way to roll the UnRAID DNS service without having to reboot the entire machine? Or at least a way to verify that the DNS resolver is still running when this issue occurs? If the DNS service is up and running in UnRAID I may have to investigate issues on the LAN but no other client seems to experience this issue except for my server. Besides the loss of DNS networking seems entirely unaffected. My Wireguard VPN continues to work, sonarr and radarr are still available remotely, I can access shares and the webui.
-
That seems to have fixed it, thanks!
-
Having an issue with the New Apps page of CA. Every time I open it I get "An error occurred. Could not find any New Apps". The individual category pages work correctly, I can search for and install apps, I just can't get the new apps page to load. Not a huge deal since it otherwise works but I'm curious what's wrong. I've restarted the server and everything else (dockers, webui, etc) seems to work fine. My other server with the same config and CA version works fine. I enabled debug logging for CA and it is attached along with my server diagnostic. node-diagnostics-20220306-0614.zipCA-Logging-20220306-0608.zip
-
void-diagnostics-20220115-0802.zip I didn't see this reported anywhere when I searched but it's possible I missed it. When trying to view logs for dockers via the web UI I've noticed multiple characters are missing from the start of each line. When you run docker logs CONTAINERNAME via a terminal the logs are displayed correctly: So this seems to be an issue with the webui parsing the docker logs? It's been going on for some people for a while now it seems. There's this post from last year on reddit about it as well:
-
I'm on 6.10 RC2 and iotop is working fine for me.
-
So as a follow up to my post here: around the same time I started having those parity errors the server started having kernel panics that would lock up the server, producing no logs. I initially wrote this off as being related to the RAM issue, but its been two weeks of normal functionality since replacing the RAM and now the server again just dropped offline. I'm not seeing parity mismatches like before so I don't think this is the same issue. The monitor wasn't on when it went down so I have no clue what happened. I've had the external rsyslog server option turned on in UnRAID for months but every single time the server hard locks, it locks up so thoroughly nothing useful ever gets logged. It's just whatever the last normal log entry was then the server startup again. Is there any other way to better capture what's happening? I'd like to avoid mirroring logs to the flash drive and given how I never get anything to my log server on the LAN I doubt mirroring locally would be any more productive... 2021-10-10T13:27:50-05:00 Node sshd[28719]: pam_unix(sshd:session): session opened for user root(uid=0) by (uid=0) 2021-10-10T13:27:50-05:00 Node sshd[28719]: Starting session: command for root from xx.xx.xx.xx port 22016 id 0 2021-10-10T13:34:30-05:00 Node sshd[28719]: Close session: user root from xx.xx.xx.xx port 22016 id 0 2021-10-10T13:34:30-05:00 Node sshd[28719]: Received disconnect from xx.xx.xx.xx port 22016:11: disconnected by user 2021-10-10T13:34:30-05:00 Node sshd[28719]: Disconnected from user root xx.xx.xx.xx port 22016 2021-10-10T13:34:30-05:00 Node sshd[28719]: pam_unix(sshd:session): session closed for user root 2021-10-10T13:34:30-05:00 Node sshd[3724]: Connection from xx.xx.xx.xx port 9719 on xx.xx.xx.xx port 22 rdomain "" 2021-10-10T13:34:31-05:00 Node sshd[3724]: Accepted key RSA found at /etc/ssh/root.pubkeys:1 2021-10-10T13:34:31-05:00 Node sshd[3724]: Accepted publickey for root from xx.xx.xx.xx port 9719 ssh2: RSA SHA256 2021-10-10T13:34:31-05:00 Node sshd[3724]: pam_unix(sshd:session): session opened for user root(uid=0) by (uid=0) 2021-10-10T13:34:31-05:00 Node sshd[3724]: Starting session: command for root from xx.xx.xx.xx port 9719 id 0 2021-10-10T20:05:10-05:00 Node rsyslogd: [origin software="rsyslogd" swVersion="8.2002.0" x-pid="8183" x-info="https://www.rsyslog.com"] start 2021-10-10T20:05:10-05:00 Node root: plugin: skipping: /boot/config/plugins/enhanced.log/enhanced.log.cfg already exists 2021-10-10T20:05:10-05:00 Node root: plugin: skipping: /boot/config/plugins/enhanced.log/custom_syslog.conf already exists 2021-10-10T20:05:10-05:00 Node root: plugin: skipping: /boot/config/plugins/enhanced.log/syslog_filter.conf already exists 2021-10-10T20:05:10-05:00 Node root: plugin: running: anonymous 2021-10-10T20:05:10-05:00 Node root: 2021-10-10T20:05:10-05:00 Node root: ----------------------------------------------------------- 2021-10-10T20:05:10-05:00 Node root: Plugin enhanced.log is installed. 2021-10-10T20:05:10-05:00 Node root: Copyright 2015-2021, Dan Landon 2021-10-10T20:05:10-05:00 Node root: Version: 2021.08.21 2021-10-10T20:05:10-05:00 Node root: ----------------------------------------------------------- 2021-10-10T20:05:10-05:00 Node root: 2021-10-10T20:05:10-05:00 Node root: plugin: enhanced.log.plg installed 2021-10-10T20:05:10-05:00 Node root: plugin: installing: /boot/config/plugins/fix.common.problems.plg 2021-10-10T20:05:10-05:00 Node root: plugin: skipping: /boot/config/plugins/fix.common.problems/fix.common.problems-2021.08.05-x86_64-1.txz already exists 2021-10-10T20:05:10-05:00 Node root: plugin: running: /boot/config/plugins/fix.common.problems/fix.common.problems-2021.08.05-x86_64-1.txz 2021-10-10T20:05:10-05:00 Node root: 2021-10-10T20:05:10-05:00 Node root: +============================================================================== 2021-10-10T20:05:10-05:00 Node root: | Installing new package /boot/config/plugins/fix.common.problems/fix.common.problems-2021.08.05-x86_64-1.txz 2021-10-10T20:05:10-05:00 Node root: +============================================================================== 2021-10-10T20:05:10-05:00 Node root: I've asked that the monitor be left on so I can hopefully get some sort of a clue as to wtf is going on as I don't know what else to do besides just start replacing hardware. I guess I could upgrade to 6.10-RC1 but it was stable on 6.9.2 for months before this so I don't think it has anything to do with the OS version. node-diagnostics-20211010-2007.zip EDIT: I have this photo of a kernel panic from when I was still having the RAM issue, but its the only clue I've got right now.
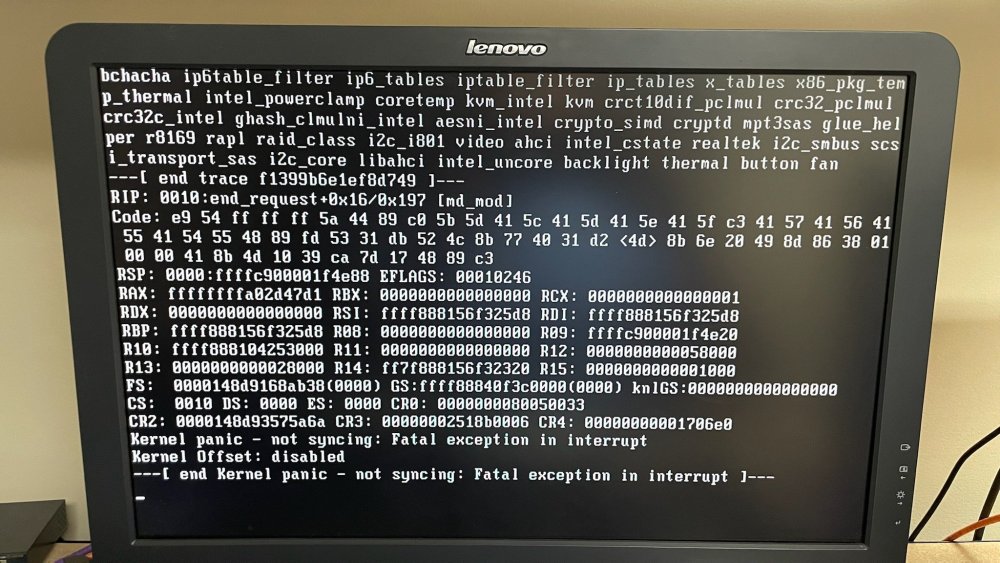
-
Apparently I'm just going to have to un-monitor that smart attribute. Disk1 just keeps randomly hitting me with notifications for the raw read error rate even though it isn't actually incrementing whatsoever.
-
I ran a short SMART yesterday but i'll turn off drive sleep and run an extended now that the parity check is finished. That's good to hear. I know it isn't one of the default monitored SMART attributes-I assume for reasons like this-but I had enabled it after coming across a recommendation in another thread when I was troubleshooting some disk issues that its useful for drives from certain vendors. I've never seen a WD drive with anything but zero for that attribute but I have seagate drives in my other server that all report a very high number for this attribute so I don't monitor it on VOID. EDIT: Oh and the correcting check completed with zero errors! Thanks Turl and JorgeB for helping me figure out it was the RAM.I think this is the first time I've ever had a computer issue and it was actually a bad stick of RAM.
-
It seems like the RAM has done the trick, its ~75% through a correcting check with no errors and it hasn't hard locked or crashed yet. However I just got a random notification from the server letting me know my RAW Read error rate on disk 1 is some ridiculous number 28-09-2021 05:27 PM Unraid Disk 1 SMART health [1] Warning [NODE] - raw read error rate is 65536 WDC_WD80EFAX-68KNBN0_VAJBBYUL (sdd) Which is odd because when I go to check the smart stats in the GUI it says my raw read error rate is zero???
-
I was able to find the same kit NIB on ebay so once it gets here I will replace and run a test with just the two new sticks to see if the panics stop.
-
@JorgeBIt finished the non-correcting check, 73 errors. within a few hours of starting a new correcting check with the second set of RAM it has again hard locked and the server is unresponsive. So at this point I've tried two correcting checks and it kernel panics each time with this RAM. Should I assume it's bad and replace? I find it interesting that it only happens during the correcting check. I had no problems with the first set of RAM.
-
Well it hard locked and crashed within a few hours of the second set being installed and a parrot check started. I've got someone going over today to power it off and back on. If it continues to be unstable with this set of DIMMS I wager a replacement is in order? EDIT: Unclean shutdown. I'm letting it run its non-correcting check, its already found 73 errors. It was in the middle of importing a bunch of stuff from sonarr, but it was all going to the cache drive (mover doesnt run till 3AM) so that wouldn't be the cause of these new parity errors right? After the non-correcting check is finished should I continue with the correcting checks?
-
The first run corrected the same sector and the second reported zero errors so that's a good sign. Correcting Check #1 Sep 15 07:19:12 Node kernel: mdcmd (37): check Sep 15 07:19:12 Node kernel: md: recovery thread: check P ... Sep 15 15:01:07 Node kernel: md: recovery thread: P corrected, sector=8096460000 Sep 16 01:05:00 Node kernel: md: sync done. time=63948sec Sep 16 01:05:00 Node kernel: md: recovery thread: exit status: 0 Sep 16 01:07:02 Node Parity Check Tuning: manual Correcting Parity Check finished (1 errors) Sep 16 01:07:02 Node Parity Check Tuning: Elapsed Time 17 hr, 45 min, 48 sec, Runtime 17 hr, 45 min, 48 sec, Increments 1, Average Speed 125.1MB/s Correcting check #2 Sep 16 05:13:29 Node kernel: mdcmd (38): check Sep 16 05:13:29 Node kernel: md: recovery thread: check P ... Sep 16 23:06:51 Node kernel: md: sync done. time=64402sec Sep 16 23:06:51 Node kernel: md: recovery thread: exit status: 0 Sep 16 23:07:01 Node Parity Check Tuning: manual Correcting Parity Check finished (0 errors) Sep 16 23:07:01 Node Parity Check Tuning: Elapsed Time 17 hr, 53 min, 22 sec, Runtime 17 hr, 53 min, 22 sec, Increments 1, Average Speed 124.2MB/s Swapped the set of DIMMs and testing again.
-
Two DIMMs removed and first correcting check is running.
-
Ah, its a change in the 6.10 series that led to those options being removed, that makes sense. I'll have to wait on the upgrade for a bit, having some server instability right now that I want to resolve before I move to an RC version.
-
My server was rebooted this evening and I went to check and sure enough the FTP service was re-enabled again. Is there somewhere besides Settings > FTP Server I should be disabling it so it persists between reboots?
-
The server hard locked tonight. I have no idea what happened, I sent someone over there to check on it and they could get no output on the console screen so I've got no logs or anything... No clue if its related or not. It's running a non-correcting parity check now after a forced reboot. EDIT: Same exact sector has the last two parity checks: md: recovery thread: P incorrect, sector=8096460000
-
Really? Well damn that makes diagnosing this significantly more inconvenient. I'll have to adjust docker memory allocations and shut some less essential dockers down if I'm going to have to cut my RAM in half. I wasn't aware memtest was so flawed when it comes to small intermittent errors, i thought that was the whole point of the software? I'll have to get someone to do this Tuesday when the office is open again.

