




weirdcrap
Members
-
Joined
-
Last visited
Everything posted by weirdcrap
-
Ok, so you would recommend my next step be memtest with a few passes?
-
An update on this. The 3rd non-correcting check (92% completed) has flagged the exact same sector that the second correcting check supposedly already repaired??? 2nd (correcting): Sep 2 02:39:36 Node kernel: md: recovery thread: P corrected, sector=8096460000 3rd (non-correcting) Sep 2 21:08:17 Node kernel: md: recovery thread: P incorrect, sector=8096460000 So the sector is staying consistent now, which I assume makes RAM less likely. Is this a disk issue? I've never seen a correcting check not actually correct the parity mismatch before. Or it did correct it and that sector has changed again? node-diagnostics-20210903-0552.zip Update: Completed, just the one incorrect sector again. Should I run another parity check? Do something else?
-
I may be out of date on my info here but I recall that setting not persisting between reboots (at least in older versions of unraid). Which is why I thought tips and tricks had a disable telnet & ftp option in it. Yeah, it is still listed in the OP so it was there at one point:
-
Did the disable FTP server option get removed? I noticed today that the built in FTP server was running when I explicitly had it disabled....
-
Good morning. On my latest non-correcting parity check on NODE I received 2 reported parity errors. Sep 1 01:04:47 Node kernel: md: recovery thread: P incorrect, sector=682504056 Sep 1 03:37:49 Node kernel: md: recovery thread: P incorrect, sector=3443896592 There were none reported during last month's check and there have been no unclean shutdowns or power outages (server is on a UPS of adequate size). When the check finished I started another (what I thought was) non-correcting parity check to see if it hit the same sectors again. Well, I screwed up and started a correcting check instead🥴 The correcting check is at about 75% and has gone way past the previously reported sectors. Interestingly the second run has found and corrected only one error in an entirely different sector: Sep 2 02:39:36 Node kernel: md: recovery thread: P corrected, sector=8096460000 I'm gonna let the check finish and run a 3rd non-correcting check to see if any new (or the same) sectors are reported. If everything comes back clean on the 3rd check should I just consider them legitimate corrected errors and move on? If it isn't clean (with the reported sectors seemingly changing at random so far) should I assume there is a disk reporting bad data? How would I go about identifying the culprit? What other causes should I look at? node-diagnostics-20210902-0816.zip
-
Yes you would need a single good backup of all 12TBs of your QNAP data as UnRAID will need to wipe and format all of your existing data disks.
-
An update on this, moving the drive to a new port (SATAII Since that is all that was left open) seems to have resolved the issue so far. I have a parity check scheduled in 2 days so that will give it a bit of an extra stress test but it SEEMS to be solved... I'll have to put another drive on that SATAIII port next and see if the issue continues on a different drive.
-
Yeah I'm going trying to take a step by step approach to identify the issue. I changed SATA ports today, if it is still acting up we'll swap power connections. I had my tech confirm this is the one drive on a MOLEX to SATA adapter due to the last SATA plug not being long enough. So that may be the culprit and I'll try replacing it next.
-
5.0.2 fixed my inability to add any servers to the app with the Object Object error.
-
Didn't last long, back at with just some read errors now. it was only a few days after and the disk dropped last time so I imagine its going out again soon. Jul 17 18:13:53 Node kernel: sd 1:0:0:0: [sdb] tag#26 ASC=0x11 ASCQ=0x4 Jul 17 18:13:53 Node kernel: sd 1:0:0:0: [sdb] tag#26 CDB: opcode=0x88 88 00 00 00 00 02 47 d0 00 d0 00 00 00 08 00 00 Jul 17 18:13:53 Node kernel: blk_update_request: I/O error, dev sdb, sector 9794748624 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Jul 17 18:13:53 Node kernel: md: disk5 read error, sector=9794748560 Jul 17 18:13:53 Node kernel: ata1: EH complete Jul 17 18:14:01 Node sSMTP[7263]: Creating SSL connection to host Jul 17 18:14:01 Node sSMTP[7263]: SSL connection using TLS_AES_256_GCM_SHA384 Jul 17 18:14:03 Node sSMTP[7263]: Sent mail for snip (221 2.0.0 closing connection b25sm7843287ios.36 - gsmtp) uid=0 username=root outbytes=819 Jul 17 18:14:34 Node kernel: ata1.00: exception Emask 0x0 SAct 0x10000 SErr 0x0 action 0x0 Jul 17 18:14:34 Node kernel: ata1.00: irq_stat 0x40000008 Jul 17 18:14:34 Node kernel: ata1.00: failed command: READ FPDMA QUEUED Jul 17 18:14:34 Node kernel: ata1.00: cmd 60/08:80:a8:89:2a/00:00:e9:00:00/40 tag 16 ncq dma 4096 in Jul 17 18:14:34 Node kernel: res 41/40:00:a8:89:2a/00:00:e9:00:00/00 Emask 0x409 (media error) <F> Jul 17 18:14:34 Node kernel: ata1.00: status: { DRDY ERR } Jul 17 18:14:34 Node kernel: ata1.00: error: { UNC } Jul 17 18:14:34 Node kernel: ata1.00: configured for UDMA/133 Jul 17 18:14:34 Node kernel: sd 1:0:0:0: [sdb] tag#16 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=7s Jul 17 18:14:34 Node kernel: sd 1:0:0:0: [sdb] tag#16 Sense Key : 0x3 [current] Jul 17 18:14:34 Node kernel: sd 1:0:0:0: [sdb] tag#16 ASC=0x11 ASCQ=0x4 Jul 17 18:14:34 Node kernel: sd 1:0:0:0: [sdb] tag#16 CDB: opcode=0x88 88 00 00 00 00 00 e9 2a 89 a8 00 00 00 08 00 00 Jul 17 18:14:34 Node kernel: blk_update_request: I/O error, dev sdb, sector 3911879080 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Jul 17 18:14:34 Node kernel: md: disk5 read error, sector=3911879016 Jul 17 18:14:34 Node kernel: ata1: EH complete Jul 17 18:14:59 Node kernel: ata1.00: exception Emask 0x0 SAct 0x2000 SErr 0x0 action 0x0 Jul 17 18:14:59 Node kernel: ata1.00: irq_stat 0x40000008 Jul 17 18:14:59 Node kernel: ata1.00: failed command: READ FPDMA QUEUED Jul 17 18:14:59 Node kernel: ata1.00: cmd 60/08:68:e0:75:cb/00:00:47:02:00/40 tag 13 ncq dma 4096 in Jul 17 18:14:59 Node kernel: res 41/40:00:e0:75:cb/00:00:47:02:00/00 Emask 0x409 (media error) <F> Jul 17 18:14:59 Node kernel: ata1.00: status: { DRDY ERR } Jul 17 18:14:59 Node kernel: ata1.00: error: { UNC } Jul 17 18:14:59 Node kernel: ata1.00: configured for UDMA/133 Jul 17 18:14:59 Node kernel: sd 1:0:0:0: [sdb] tag#13 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=7s Jul 17 18:14:59 Node kernel: sd 1:0:0:0: [sdb] tag#13 Sense Key : 0x3 [current] Jul 17 18:14:59 Node kernel: sd 1:0:0:0: [sdb] tag#13 ASC=0x11 ASCQ=0x4 Jul 17 18:14:59 Node kernel: sd 1:0:0:0: [sdb] tag#13 CDB: opcode=0x88 88 00 00 00 00 02 47 cb 75 e0 00 00 00 08 00 00 Jul 17 18:14:59 Node kernel: blk_update_request: I/O error, dev sdb, sector 9794450912 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Jul 17 18:14:59 Node kernel: md: disk5 read error, sector=9794450848 Jul 17 18:14:59 Node kernel: ata1: EH complete I'll try moving it to a different SATA port on the mobo next and see if that makes any difference... node-diagnostics-20210717-1829.zip
-
Cables replaced, power cable seating checked, rebuilding to the same disk now. So far so good, fingers crossed that was it. EDIT: Rebuild completed successfully. I will monitor and report back if this becomes a problem again.
-
It passed SMART. I believe this disk runs directly off the PSU power so no splitters or anything. I can try having someone replace the SATA cable but I am honestly terrified that if this is a cabling/power issue swapping cables with another drive is going to drop a different disk from the array, breaking parity all together. If I try to rebuild to the same disk and it drops off again will UnRAID just re-disable the disk? Or will it break parity? This is a remote server so infuriatingly I cannot troubleshoot this problem myself without a 6 hour round trip that i just made last weekend.
-
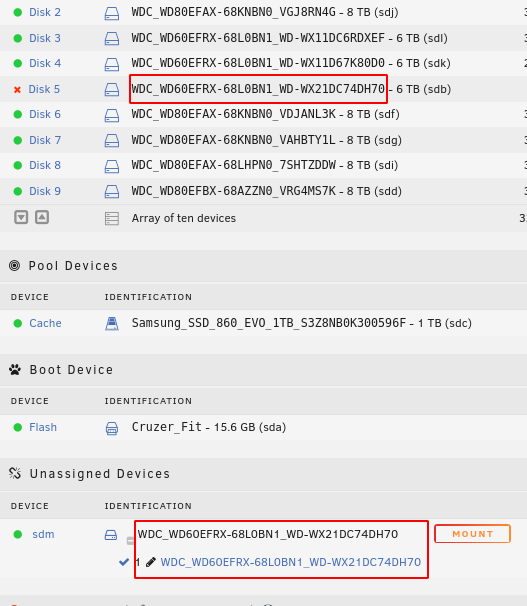
I had disk5 in my array throw a random smattering of read errors earlier this week and wrote it off as nothing significant after the disk passed a long and short smart test. Well it just magically dropped off out of the blue and it almost looks like the controller took the link down rather than the drive died? Jul 15 13:18:47 Node kernel: Jul 15 13:19:21 Node kernel: ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Jul 15 13:19:21 Node kernel: ata1.00: configured for UDMA/133 Jul 15 14:13:09 Node kernel: ata1: COMRESET failed (errno=-32) Jul 15 14:13:09 Node kernel: ata1: reset failed (errno=-32), retrying in 8 secs Jul 15 14:13:17 Node kernel: ata1: limiting SATA link speed to 3.0 Gbps Jul 15 14:13:19 Node kernel: ata1: SATA link up 3.0 Gbps (SStatus 123 SControl 320) Jul 15 14:13:19 Node kernel: ata1.00: configured for UDMA/133 Jul 15 17:20:11 Node emhttpd: spinning down /dev/sdg Jul 15 17:20:53 Node kernel: mdcmd (60): set md_write_method 0 Jul 15 17:20:53 Node kernel: Jul 15 17:33:31 Node kernel: ata1: SATA link down (SStatus 0 SControl 320) Jul 15 17:33:31 Node kernel: ata1: SATA link down (SStatus 0 SControl 320) Jul 15 17:33:31 Node kernel: ata1.00: link offline, clearing class 1 to NONE Jul 15 17:33:32 Node kernel: ata1: SATA link down (SStatus 0 SControl 320) Jul 15 17:33:32 Node kernel: ata1.00: link offline, clearing class 1 to NONE Jul 15 17:33:32 Node kernel: ata1.00: disabled Jul 15 17:33:32 Node kernel: ata1.00: detaching (SCSI 1:0:0:0) Jul 15 17:33:32 Node kernel: sd 1:0:0:0: [sdb] Synchronizing SCSI cache Jul 15 17:33:32 Node kernel: sd 1:0:0:0: [sdb] Synchronize Cache(10) failed: Result: hostbyte=0x04 driverbyte=0x00 Jul 15 17:33:32 Node kernel: sd 1:0:0:0: [sdb] Stopping disk Jul 15 17:33:32 Node kernel: sd 1:0:0:0: [sdb] Start/Stop Unit failed: Result: hostbyte=0x04 driverbyte=0x00 Jul 15 17:33:32 Node rc.diskinfo[12031]: SIGHUP received, forcing refresh of disks info. Jul 15 17:33:38 Node kernel: ata1: link is slow to respond, please be patient (ready=0) Jul 15 17:33:41 Node kernel: ata1: SATA link up 3.0 Gbps (SStatus 123 SControl 300) Jul 15 17:33:41 Node kernel: ata1.00: ATA-9: WDC WD60EFRX-68L0BN1, WD-WX21DC74DH70, 82.00A82, max UDMA/133 Jul 15 17:33:41 Node kernel: ata1.00: 11721045168 sectors, multi 0: LBA48 NCQ (depth 32), AA Jul 15 17:33:41 Node kernel: ata1.00: configured for UDMA/133 Jul 15 17:33:41 Node kernel: scsi 1:0:0:0: Direct-Access ATA WDC WD60EFRX-68L 0A82 PQ: 0 ANSI: 5 Jul 15 17:33:41 Node kernel: sd 1:0:0:0: Attached scsi generic sg1 type 0 Jul 15 17:33:41 Node kernel: sd 1:0:0:0: [sdm] 11721045168 512-byte logical blocks: (6.00 TB/5.46 TiB) Jul 15 17:33:41 Node kernel: sd 1:0:0:0: [sdm] 4096-byte physical blocks Jul 15 17:33:41 Node kernel: sd 1:0:0:0: [sdm] Write Protect is off Jul 15 17:33:41 Node kernel: sd 1:0:0:0: [sdm] Mode Sense: 00 3a 00 00 Jul 15 17:33:41 Node kernel: sd 1:0:0:0: [sdm] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Jul 15 17:33:41 Node kernel: sdm: sdm1 Jul 15 17:33:41 Node kernel: sd 1:0:0:0: [sdm] Attached SCSI disk Jul 15 17:33:41 Node rc.diskinfo[12031]: SIGHUP received, forcing refresh of disks info. Jul 15 17:33:47 Node emhttpd: read SMART /dev/sdg Jul 15 17:33:49 Node kernel: md: disk5 read error, sector=1743040 Jul 15 17:33:49 Node kernel: md: disk5 read error, sector=1743048 Jul 15 17:33:49 Node kernel: md: disk5 read error, sector=1743056 Jul 15 17:33:49 Node kernel: md: disk5 write error, sector=1743040 Jul 15 17:33:49 Node kernel: md: disk5 write error, sector=1743048 Jul 15 17:33:49 Node kernel: md: disk5 write error, sector=1743056 node-diagnostics-20210715-1742.zip Is this a disk or controller/cabling problem? It appears to be the onboard intel SATA controller. I had one other disk (disk9) on the same controller throw some read errors recently but I went ahead and replaced it and I haven't seen any more. What are my options at this point? Since it failed a write test I'm going to have to rebuild on the same disk or a new one. EDIT: Ok so taking another look at this it looks like UnRAID now sees the same disk as /dev/sdm? So maybe this is a controller or cabling issue after all since it "lost" and "found" the disk again? I'm probably going to get a new disk on order anyway but it might be worth having someone check and re-seat the cables tomorrow. If cabling seems good should I try a rebuild on top of the old disk? The emulated content is present and accounted for and I have another long smart test of the drive running.
-
So because I'm an idiot I started a run of the unbalance plugin to move files off a drive so i can drop it from the array, then had to stop it because I included a disk I didn't mean to. rsync created empty directories on the destination disks first so I now have a bunch of empty folders on the /mnt/disk* shares that don't correspond to the actual location of the data. I would like to delete the empties but am looking for a sanity check to make sure my methodology is sound and I'm not going to break things. https://www.reddit.com/r/unRAID/comments/9chbca/user_share_splitting_and_clean_up/ FIND: for i in {1..6}; do find /mnt/disk$i/ShareName -type d -empty -print; done FIND & DELETE: for i in {1..6}; do find /mnt/disk$i/ShareName -type d -empty -delete; done This seems promising, works on the share level, and can be scaled across all the disks in the array. Can anyone foresee any problems with running one of the above commands and clearing out the empty folders on a share by share basis? I figure by working at the share level I avoid accidentally deleting a top level share that may be empty for whatever reason. EDIT: Well I gave it 48 hours and I couldn't come up with any negative effects so I went for it. It doesn't seem to have had any ill effects, no missing data, etc. Consider this solved.
-
This is still very much broken for me. Right now no matter how many times I restart the transfer or the servers I can't even top 100KB/s. My current file is running at 1.5KB/s, it's disgusting how badly this runs. If I find time this weekend I'm going to go bother the wireguard devs on IRC and see if they have any ideas. I really really want this to work but in its current state it is unusable.
-
Well since you're not having the overwrite issue that tells me there must be something wrong with my container. I'll probably scrub the container and it's appdata directory and try again from scratch. EDIT: Well even after starting over with the container from scratch it is still overwriting my wg0.conf file... I don't get how the exact same container can perform so differently on two different servers. EDIT2: The only remaining difference I have yet to test is the iptables mangle support. NODE has it enabled as rtorrent is externally accessible while VOID does not have mangle support turned on. I don't think that will affect my wg0.conf overwrite issue but maybe mangle is what is preventing me from accessing the local web interface.
-
Did you have any luck editing your AllowedIPs in the wg0.conf file like Binhex suggested? I'm curious if there is something wrong with my container that's causing that line to be overwritten every time I restart the container.
-
I stopped the container and edited the AllowedIPs as indicated. It looks like your wireguard startup script is overwriting the allowed line I set as I go back into the file after starting the container and it has been changed back to 0.0.0.0/0. Seems quite odd to me that this affects only NODE and not VOID despite them both using WireGuard....Could it be my "non-standard" LAN IP? Not that I can do anything to change the .20. network as it isn't mine, it just seems odd that the issue isn't consistent across multiple servers...
-
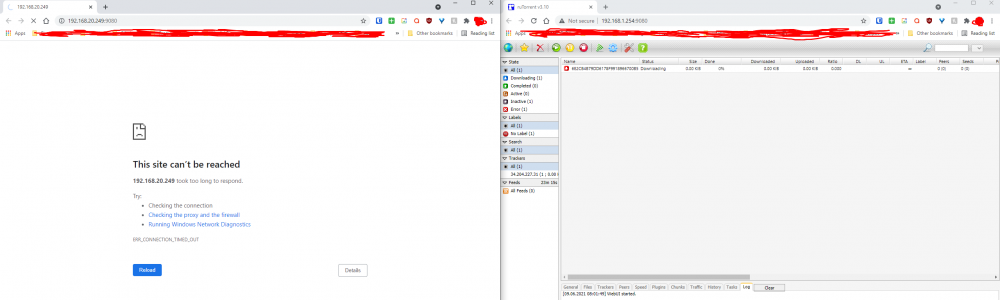
So I'm having an odd issue with only one of my two rtorrentvpn containers. When using WireGuard as the connection type on my server NODE, I cannot access the rutorrent web interface using the local unraid server IP (it just spins and times out). I can however access it externally through my reverse proxy via HTTP / RPC without any issues. What's even stranger is if I switch back to using OpenVPN as my connection method I can access the web interface locally again. I don't see anything error wise in the logs that would suggest what is wrong... My server IP for NODE is 192.168.20.249 and my LAN_NETWORK variable is set correctly: 192.168.20.0/24 Finally, on an entirely separate server and network (VOID at my home) I have your container running using WireGuard and I have no issues accessing the webui via the unraid server IP address. I went line by line through the environmental variables and they are configured exactly the same besides a different network address (192.168.1.0/24). My only thought is maybe the iptables rules are bad on the one container, but then why does it work for OVPN vs WG?
-
I think you can just copy your \\tower\cache\appdata\CONTAINER_NAME\rtorrent\session folder contents into the session folder of the new container. There may be differences in your config and file structure so you may have to resolve those manually or make sure your paths and config are identical between the new and old containers before you copy the session data.
-
What I was trying to point out earlier is that rutorrent is part of the rtorrent docker I mentioned. rtorrent on its own is a command line torrent client, binhex's container includes both the main command line rtorrent client AND the rutorrent web frontend. From binhex's github: "...this Docker image includes the popular ruTorrent web frontend to rTorrent for ease of use." Crazymax's stuff is on docker hub, which can be searched through CA. However he/she does not appear to publish an rtorrent container of any kind, I only see qbittorrent: https://hub.docker.com/u/crazymax
-
are you running an up to date version of UnRAID? It shows up for me on both of my servers:
-
You need to search for "rtorrent" or "binhex" as that's part of the application name. rutorrent is the web frontend.
-
Ah OK. For now I'll leave the rules disabled. When I've got some time I'll play around with PFSense and see if I can modify the rules to exclude VOID from my DNS redirecting. Thanks for your help with this! EDIT: I was able to make an alias group for my entire subnet excluding my server and set that as the source for all my firewall rules. Now the container can get straight out to the internet while all other devices must go through pfsense.
-
I'm not quite sure I understand the caveat you are stating after the however. So if I set my router IP in the name server variable it should allow me to use my firewall rules as I had them. The firewall would take in the DNS query, say I don't know where that is and pass it on up to one of the public servers it is setup to reference, then pass that lookup response back to the docker. Shouldn't it not matter that resolution would fail since resolution is blocked after the initial endpoint lookup as part of the IPTable rules anyway? Or am I grossly misunderstanding how this works?




