




weirdcrap
Members
-
Joined
-
Last visited
Everything posted by weirdcrap
-
I think I found the problem, in addition to the LAN rules there was a NAT rule I had forgotten about. So I guess my setup at home breaks the container because it wants to reach the internet directly and it won't let my firewall play middleman in the DNS lookup? It's unfortunate that I have to disable them as I liked the peace of mind knowing that IOT devices and things with hard coded DNS can't just bypass my filtering.
-
Well I disabled the rules and reloaded the firewall and it still won't resolve... Will I be able to test DNS resolution from within the container if the initial resolution fails? EDIT: Ah wait I missed on, it appears to be working now... let me do some more checking
-
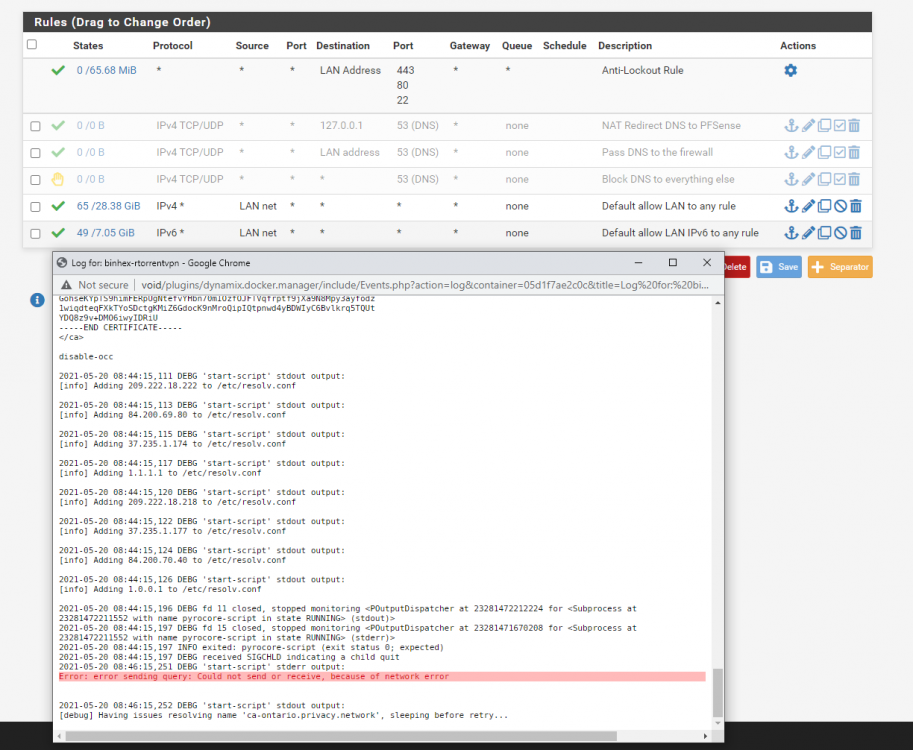
The defaults that come with the docker: 209.222.18.222,84.200.69.80,37.235.1.174,1.1.1.1,209.222.18.218,37.235.1.177,84.200.70.40,1.0.0.1 I do have some rules in PFSense to prevent DNS lookups from getting out directly to the internet (I want everything to go through unbound so it can be checked/filtered). I'm going to try turning those off and see if that fixes it.
-
So OpenVPN also appears to be broken? It seems like no matter what the docker can't resolve any endpoints.... Error: error sending query: Could not send or receive, because of network error 2021-05-20 08:29:47,603 DEBG 'start-script' stdout output: [debug] Having issues resolving name 'ca-montreal.privacy.network', sleeping before retry... 021-05-20 08:35:19,650 DEBG 'start-script' stdout output: [debug] Having issues resolving name 'ca-ontario.privacy.network', sleeping before retry... I have about half a dozen endpoints set up in my openVPN config: client dev tun proto udp remote sweden.privacy.network 1198 remote swiss.privacy.network 1198 remote ca-ontario.privacy.network 1198 remote ca-montreal.privacy.network 1198 remote ca-toronto.privacy.network 1198 remote ca-vancouver.privacy.network 1198 remote de-frankfurt.privacy.network 1198 remote ro.privacy.network 1198 resolv-retry infinite nobind persist-key cipher aes-128-cbc auth sha1 tls-client remote-cert-tls server What's even odder is I have the PIA windows client and it works fine with these endpoints on my network at home. I also have this same docker container on another server (different network) using these exact same OpenVPN settings and they work fine.
-
Ah of course, why didn't I think to check if the endpoint was down. I'm just glad it isn't me, I thought I was missing something super obvious in the setup of the container. I'll keep an eye out for your fix and/or see if the endpoint comes back up.
-
I can't for the life of me get any of the VPN containers to start with Wireguard support (I've tried rtorrent and qbittorrent). The only symptoms I can see are the wg0.conf file is never generated and the webui never starts. The logs always seem to just stop after adding DNS servers to resolv.conf... I'm not seeing anything in the FAQs and these threads are so unruly and hard to navigate through if you don't have a specific error to search for. These are freshly pulled containers, no previous appdata or template was available so these should have all the latest changes in them. EDIT: I'm seeing: 2021-05-18 08:32:52,689 DEBG 'start-script' stderr output: Error: error sending query: Could not send or receive, because of network error 2021-05-18 08:32:52,690 DEBG 'start-script' stdout output: [debug] Having issues resolving name 'nl-amsterdam.privacy.network', sleeping before retry... 2021-05-18 08:34:57,807 DEBG 'start-script' stderr output: Error: error sending query: Could not send or receive, because of network error 2021-05-18 08:34:57,808 DEBG 'start-script' stdout output: [debug] Having issues resolving name 'nl-amsterdam.privacy.network', sleeping before retry... 2021-05-18 08:37:02,930 DEBG 'start-script' stderr output: Error: error sending query: Could not send or receive, because of network error 2021-05-18 08:37:02,931 DEBG 'start-script' stdout output: [debug] Having issues resolving name 'nl-amsterdam.privacy.network', sleeping before retry... 2021-05-18 08:39:08,052 DEBG 'start-script' stderr output: Error: error sending query: Could not send or receive, because of network error 2021-05-18 08:39:08,053 DEBG 'start-script' stdout output: [debug] Having issues resolving name 'nl-amsterdam.privacy.network', sleeping before retry... 2021-05-18 08:41:13,168 DEBG 'start-script' stderr output: Error: error sending query: Could not send or receive, because of network error 2021-05-18 08:41:13,169 DEBG 'start-script' stdout output: [debug] Having issues resolving name 'nl-amsterdam.privacy.network', sleeping before retry... Trying to dig or ping anything returns no servers could be reached errors. I can see the name servers defined in /etc/resolv.conf though they just flat out don't work... DNS seems to be broken in the container? I can ping IP addresses but no hostnames at all... EDIT: Ok so my issues look very similar to: Which never got an answer or reply and I can't seem to find anyone else who's having this problem. @binhex Is there any further testing I can do?
-
I checked overall CPU usage on the stats page as well as individual core utilization on the WebUI dashboard. With nothing else running except a file transfer I don't see utilization over 5% on any single core. There may be an occasional spike but it always quickly drops back down to almost nothing. Yes we are referring to roughly the same speeds, I do the big B for bytes. I agree I have also noticed In the last few months it does seem to linger around 1MB/s more so than it used to. When this issue first started for me when the speed dropped it would drop down into the kilobytes and stay there until I cancelled it. 1MB/s is an improvement over the dial-up like speeds I was getting before.
-
In my testing hardware doesnt seem to make a difference. I have two i7 Haswells each with 32GB of RAM and they struggle just as badly as my old AMD FX-6300 did. I would be surprised if Hardlinks being one or off makes a difference. I have that setting on and never considered turning it off. If you think you see improvements with it off I'll give it a shot. Like right now I just started a transfer no more than a few minutes ago and the speed has already tanked to barely 1MB/s. My CPU usage on both servers is >5%.
-
Ah I didn't realize you weren't already using bwlimit. That might explain why I haven't seen the CPU spikes you have. My remote server shares bandwidth with a friend's business so I always make sure to only use roughly have of the available bandwidth. So with the bandwidth limit can your WireGuard transfer consistently maintain it's speed? I'm still seeing my speeds drop to 1MBps > at random points during my tests with my bwlimit of 5MBps
-
I feel your pain. Once a month when I sync my servers I get frustrated and do a day of furious research while I baby sit the transfer. So far I haven't found anything to resolve the issue but please do report back if you figure it out first
-
My LAN MTUs are all 1500 and running traceroute --mtu myendpoint shows my MTU is not incremented down at all before it reaches it's destination out on the internet so the default wireguard setting of 1420 should be correct for me and my network. I was simply saying I'd be willing to try tuning it lower just to see if it makes any difference if you had promising results. In my experience it doesn't seem to have any effect.
-
Yeah I've read that the default is 1420 but I figured it couldn't hurt to set it manually in case it wasn't auto detecting correctly. I had also tried going all the way down to 1380 and it didn't seem to make much of any improvement. I'm not sure if taking my MTU to far down could be making things worse so maybe 1380 was to far the other way and 1412 is the sweet spot? Let me know if you can get consistent results with several large transfers. It would be great to get some sort of debug output from wireguard like I mentioned a few posts back with the kernel debug options. I don't know if we'll ever nail this down without some logs or WG dev help.
-
I have not seen any correlation between CPU usage spikes and my wireguard performance woes. My processor can be entirely idle with nothing running and I'll still have a speed drop. Anecdotally I have had some marginal improvements in how long I can maintain a transfer at speed through the tunnel by adjusting the MTU for the tunnel down to 1420. However this is not fool proof and it will still lose speed at some point and require me to restart the transfer. At 1420 I was able to move about 300GB of data at speed over the course of 12-14 hours. In total this month I was able to move about 700GB and only had to restart the transfer 4-5 times.
-
Well after upgrading my existing gaming PC I decided to take the old Mobo and CPU and put it into VOID as a major upgrade. So now VOID has an i7-4790K and an ASUS ROG Maximus VII Hero with an Intel Killer NIC. A complete change of hardware has made no difference in this issue either. I made it about 30 minutes into copying a 50GB ISO file and the speed has tanked already.
-
Final update. I regret to report that I am now 100% positive this entire issue is caused by WireGuard itself as @claunia mentioned and no amount of setting changes is going to fix it. I re-enabled direct SSH access to NODE through the firewall and restricted it to my current comcast IP. When using the exact same setup and going entirely around the WG tunnel I get my full consistent speeds without any random drops or issues. I transferred roughly 300GB of data over the course of about 12 hours yesterday and NOT ONCE did the speed drop to an unacceptable level (only minor variances of +/-0.5MBps). This is the performance I have been seeking from the WireGuard tunnel and I am still no closer to figuring out why this simply doesn't work consistently. @ljm42 I assume WireGuard was not built with CONFIG_DYNAMIC_DEBUG enabled in the Kernel? I would really like to see this issue solved. However with nothing but anecdotal evidence and my personal testing I don't feel right just showing up on the WireGuard mailing list (or wherever the devs hang out) and saying there's a problem without some actionable proof. That and I have no flipping clue what about WireGuard causes this performance issue. EDIT: I guess I'll join #Wireguard on Freenode and see if any of the devs have a clue on what, if anything else, I can try to change to fix this or get some actionable proof and a fix made.
-
Some promising results with an MTU of 1380. I was able to complete a 60GB transfer from start to finish with zero drop in speed. I've started a much larger 250GB transfer, we shall see if I can maintain speed through the entire thing. EDIT: ANNNNDDDDD just like that there it goes. This is just ridiculous. EDIT2: I've re-opened SSH up to the world, restricted to my current comcast IP only. I'm running my 250GB transfer completely outside of the WireGuard tunnel and so far so good, but I've said that dozens of times up to this point so I won't hold my breath. For whatever reason, despite making the appropriate changes in sshd_config and rebooting for good measure, I cannot get UnRAID to completely disable password auth.
-
It's that time of the month again! Just upgraded both servers to 6.9.0 stable. I haven't done my test with iperf3 yet that I mentioned above, I figured I'd try to adjust my MTU first and see what happens. I have lowered MTU to 1400 on both ends of the tunnel and have started a data transfer. EDIT: 1400 didn't work, trying 1380 as recommended in that link I posted. I don't know what else to try.
-
I don't use this docker but hydra stores all its config in its data/nzbhydra.yml file afaik. I imagine your path would be something like /appdata/nzbhydra2-binhex/data/nzbhydra.yml
-
I've been playing with iPerf3 to see if I can saturate my wireguard tunnel with other programs/protocols. My hope is to determine if this is in fact an SSH/RSYNC issue or if this random speed issue is WireGuard itself. With NODE running "iperf3 -s" and VOID acting as the client with "iperf3 -c 10.253.1.1 -t 30 -P 8" I can only seem to get about 20-25Mbps.... Cranking parallels up to 30 made no difference, I still maxed out at a meager 25Mbps. Is this indicative of a bigger problem or am I just not using iperf correctly? This is my first time messing with it so I'm inclined to think I'm doing something wrong with my test. EDIT: Could my speed woes be an MTU issue? https://www.reddit.com/r/WireGuard/comments/jn7d7e/slow_file_transfer/ https://keremerkan.net/posts/wireguard-mtu-fixes/ https://superuser.com/questions/1537638/wireguard-tunnel-slow-and-intermittent running traceroute --mtu <endpoint> on both ends of the server to server tunnel show my first hop MTU of 1500 so I assume that means wireguards default of 1420 should be fine for me right? I may try to tune it lower like the second link suggests just to test during my monthly data transfer to see if it has any real affect on the issue or not. EDIT2: Well my iperf3 issues appear to be my home internet's limited upload. In my described setup above VOID as the client was uploading data to the server rather than downloading data from it. Using --reverse fixes it and I seem to be able to fully maximize my bandwidth both directions. I'll have to pick a time this evening to run an iperf3 test where I can saturate the server bandwidth for like 45 minutes and see if it is able to maintain it the entire time.
-
On UnRAID SSH is enabled by default. QNAP probably requires SSH to be enabled in the GUI somewhere. EDIT: https://wiki.qnap.com/wiki/How_to_SSH_into_your_QNAP_device I'm not aware of a QNAP and UnRAID specific guide, but there are hundreds of guides online about setting up server to server sync with SSH and RSYNC: https://www.digitalocean.com/community/tutorials/how-to-use-rsync-to-sync-local-and-remote-directories
-
Bump, still having the same issues with this. Transferred about 30GB before the transfer speed goes to shit. Finishing the transfer in Windows because I don't know what else to do about this issue.
-
Good morning itimpi, this may be related to the issue ScottinOkla is describing? I had a parity check running all day yesterday (manually started), went to bed, woke up and it was paused for no reason. I do have the parity check tuner plugin installed, and my only pause scenario is disks overheating. I see no indication in the logs that any disks were overheating (additionally my house has quite a cold ambient temperature). I did have "Send notification for temperature related pause" set to NO, but I assume it would have still logged the pause and reason in the logs? It stopped right at 3:30AM CST with no corresponding log entries around it as to why... Feb 12 13:44:24 VOID webGUI: Successful login user root from 192.168.1.8 Feb 12 13:45:00 VOID root: Fix Common Problems Version 2021.01.27 Feb 12 13:47:23 VOID kernel: mdcmd (38): check nocorrect Feb 12 13:47:23 VOID kernel: md: recovery thread: check P ... Feb 12 13:47:48 VOID kernel: mdcmd (39): set md_write_method 1 Feb 12 13:47:48 VOID kernel: Feb 12 13:49:04 VOID root: Stopping Auto Turbo Feb 12 13:49:04 VOID root: Setting write method to unRaid defined Feb 12 13:49:04 VOID kernel: mdcmd (40): set md_write_method auto Feb 12 17:04:35 VOID dhcpcd[1683]: br0: failed to renew DHCP, rebinding Feb 12 18:19:34 VOID emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/tail_log syslog Feb 12 23:00:01 VOID Plugin Auto Update: Checking for available plugin updates Feb 12 23:00:06 VOID Plugin Auto Update: Checking for language updates Feb 12 23:00:06 VOID Plugin Auto Update: Community Applications Plugin Auto Update finished Feb 13 00:00:07 VOID crond[1849]: exit status 1 from user root /usr/local/sbin/mover &> /dev/null Feb 13 00:10:37 VOID emhttpd: spinning down /dev/sdh Feb 13 00:10:37 VOID emhttpd: spinning down /dev/sdg Feb 13 00:10:37 VOID emhttpd: spinning down /dev/sdb Feb 13 00:10:37 VOID emhttpd: spinning down /dev/sdf Feb 13 00:10:37 VOID emhttpd: spinning down /dev/sdq Feb 13 00:10:37 VOID emhttpd: spinning down /dev/sdo Feb 13 02:00:01 VOID Docker Auto Update: Community Applications Docker Autoupdate running Feb 13 02:00:01 VOID Docker Auto Update: Checking for available updates Feb 13 02:00:07 VOID Docker Auto Update: No updates will be installed Feb 13 03:30:06 VOID kernel: mdcmd (49): nocheck PAUSE Feb 13 03:30:06 VOID kernel: Feb 13 03:30:06 VOID kernel: md: recovery thread: exit status: -4 Feb 13 05:02:21 VOID emhttpd: read SMART /dev/sdh Feb 13 05:02:29 VOID emhttpd: read SMART /dev/sdg Feb 13 05:02:35 VOID emhttpd: read SMART /dev/sdb Feb 13 05:02:42 VOID emhttpd: read SMART /dev/sdo Feb 13 05:02:49 VOID emhttpd: read SMART /dev/sdf Feb 13 05:02:54 VOID emhttpd: read SMART /dev/sdq void-diagnostics-20210213-0521.zip
-
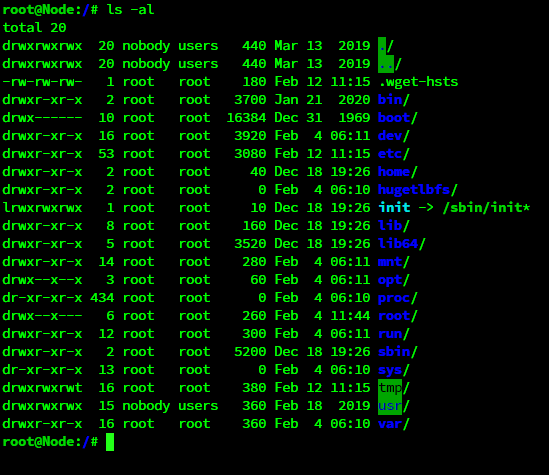
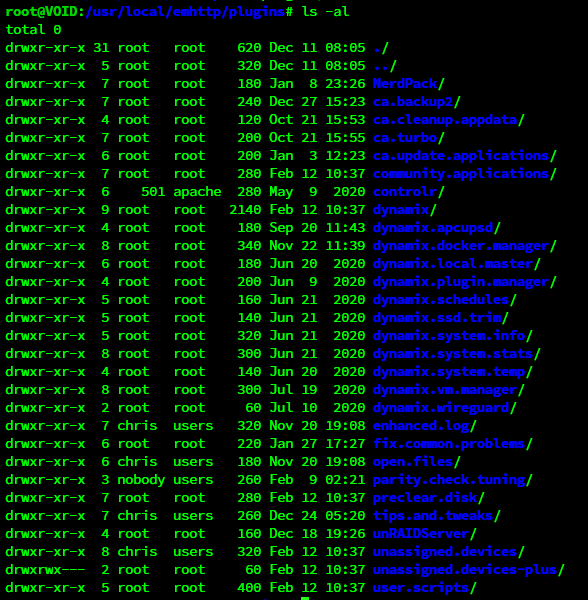
You were right @ken-ji My other server hadn't had the parity check tuning plugin updated yet so I installed. Sure enough I lost pub key access and my usr folder is owned by nobody:users now EDIT: So I went digging into the folders it seems to have touched and I ended up in the plugins folder and it looks like some of the other plugins ive installed over the years aren't owned by root either. Is it a rule of thumb that all of these files should be owned by root? Or is it different from plugin to plugin?
-
Interesting. The reboot actually fixed it for me so UnRAID must be correctly applying the default permissions and overriding anything the plugins may be messing with at boot. I don't have any more plugin updates currently but I will keep my eye out for an update and see if my ssh breaks after applying it. EDIT: Yeah it was almost certainly the "usr" folder that caused this as I recall seeing that it was the only folder in / that wasn't owned by root. I ignored it as I didn't think that folder would have anything to do with my issue since my key and ssh files weren't stored there.
-
Yeah I was able to get in with my password still but I could not find anything wrong with my / directory. Next time it happens ill be sure to get a screenshot and share it so I can get some more eyes on it. If it was a plugin though wouldn't it affect me from the moment I booted the system? This occurred after 6 days of uptime and multiple uses of the key up to that point. I haven't added or removed any plugins, I think I may have updated one, the parity check tuning plugin.


