




weirdcrap
Members
-
Joined
-
Last visited
Everything posted by weirdcrap
-
Yes that is essentially the PIA linux script checking what port you have been assigned every five minutes to make sure it hasn't changed. If it has the Deluge port is updated accordingly (from what I understand of how this works). I upgraded my PIA client on the Windows machine I am trying to do some tests on and am still not having any luck with the client being able to tell me what port number I was assigned. If it eventually decides to tell me what port I have I will do some testing and see if my ports show open or closed. Maybe Binhex or some of the other users with some more experience with VPNs and bittorrent can shed some light on this (I just started using a VPN a month ago). EDIT: My Docker is seeding now and you are correct the port shows closed even when actively uploading data. EDIT2: Interestingly enough even though port utilities like the one you linked to above show my deluge port as being closed the tracker I am on is listing me as connectable.
-
Yes it is. According to a discussion on PIA's forums the port is only ever opened when you are actually sending data through it: https://www.privateinternetaccess.com/forum/discussion/4558/tcp-port-forwarding-not-working Do you have any torrents actively seeding (uploading data) when you are checking for connectivity? I just checked mine and it shows closed and I have no active uploads currently so AFAIK this is the expected behavior. EDIT: I am testing with a debian distro torrent on my home Windows machine and I am having issues getting the client to report what port number I have been assigned. Once I get that figured out I will do some more testing and report back whether my port shows open when I am seeding.
-
Did you verify that you are using a pia server that supports port forwarding? Specifically these endpoints (all outside of the US) : CA Toronto CA North York Netherlands Sweden Switzerland France Germany Russia Romania Israel Sent from my XT1096 using Tapatalk
-
The port that is being forwarded is randomly picked by the deluge startup script from what I can tell. It should show up in your container log when it starts and it can also be found in the Deluge preferences under Network > Incoming Ports. You also have to be sure you are using one of the PIA servers that supports port forwarding, the default one that Binhex has defined in the container (nl.privateinternetaccess.com) supports port forwarding and will work just fine.
-
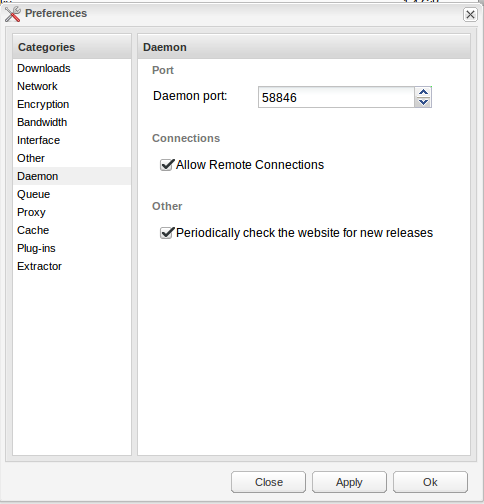
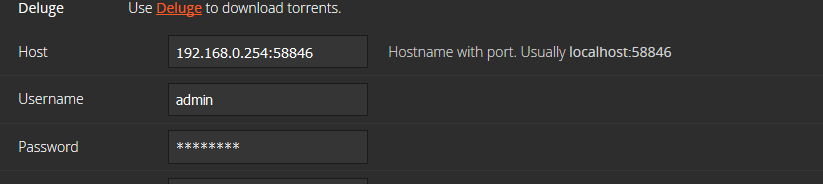
It should already be started, you simply need to check allow remote connections under preferences in the webui (see attachment). Then in CouchPotato this is what I have setup for deluge (see attachment). I use the IP address of UnRAID plus the port of the daemon and the user I defined in the auth file according to Q6 in the OP.
-
Looks like the pull request was merged in Sonarr and this container autoupdates on restart so, yes it will have made it into the container as soon as you restarted after the PR was merged. Just tested it again, still the same issue. The meta file is added with the proper download directory and label, but it is not passed on to the torrent file itself. Is this something I should bring up on the sonarr forums then? The links I posted previously were the only thing I could find that sounded like the issue I am experiencing now. I was previously using deluge (as it played nice with CP, Sonarr, and Headphones without any of these issues) but I found it was more resource heavy (RAM wise) than I liked, my Plex machine is the older of my two UnRAID systems and the board only supports a maximum of 8GB (budget build lulz) and deluge was using 3GB before I stopped it.
-
Hey guys, I am using LinuxServer.io's Sonarr docker and BinHex's rtorrentvpn docker and I am having an issue with sonarr passing magnet links to rtorrent and the torrent not keeping the properties of the magnet link after it is removed (hope this makes sense). I did some research online and I found some info on the sonarr forums and in the issue tracker on GitHub and was wondering if anyone could tell me if this fix has been incorporated into the Sonarr docker (I am not a coder or an expert in navigating GitHub so I was hoping someone here could help). Here is the forum post that led me to the pull request on github: https://forums.sonarr.tv/t/rtorrent-magnet-not-resolved/8608/6 The forum post doesn't exactly describe the issue I am having but after reading through the whole discussion on GitHub it sounds like it was resolved with the pull requests they made. This post specifically describes the behavior I am experiencing: https://github.com/Sonarr/Sonarr/pull/1033#issuecomment-173240458 -Sonarr pushes magnet to rtorrent. -Sonarr starts magnet. -Magnet gets downloaded as meta file. -Rtorrent deletes magnet download, replaces it with a torrent download attached to the meta file. But doesn't transfer any other property. So the torrent gets the default download dir set without a label Could anyone tell me if this has made it into this docker? I am still experiencing the issue and I am a Git noob so I don't know how to check whether the pull was committed to the repository or anything like that.
-
It sounds like the route (I assume in iptables) that the script is trying to add is failing to add and as binhex mentioned if the VPN connection fails this docker will not download anything as a protection measure for the user so you aren't downloading anything without the protection of the VPN. Binhex: I noticed this in my logs today: Authenticate/Decrypt packet error: packet HMAC authentication failed I saw your posts in your Docker archive thread here and I am using PIA so I'm not sure what my issue is. I checked the file permissions and they are fine, the VPN tunnel is working and I can verify that my IP address is not my ISP given IP, I have looked through the log files and can't find anything out of the ordinary besides a few small warnings but they were present before this hmac issue popped up so I think they are unrelated. [info] Env var PUID defined as 99 [info] Env var PGID defined as 100 [info] Permissions already set for /config [info] Starting Supervisor... 2016-05-03 12:41:31,385 CRIT Set uid to user 0 2016-05-03 12:41:31,385 WARN Included extra file "/etc/supervisor/conf.d/delugevpn.conf" during parsing 2016-05-03 12:41:31,399 INFO supervisord started with pid 12 2016-05-03 12:41:32,401 INFO spawned: 'start-script' with pid 15 2016-05-03 12:41:32,404 INFO spawned: 'webui-script' with pid 16 2016-05-03 12:41:32,406 INFO spawned: 'deluge-script' with pid 17 2016-05-03 12:41:32,408 INFO spawned: 'privoxy-script' with pid 18 2016-05-03 12:41:32,420 DEBG 'deluge-script' stdout output: [info] VPN is enabled, checking VPN tunnel local ip is valid 2016-05-03 12:41:32,420 INFO success: start-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-05-03 12:41:32,420 INFO success: webui-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-05-03 12:41:32,420 INFO success: deluge-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-05-03 12:41:32,420 INFO success: privoxy-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2016-05-03 12:41:32,421 DEBG 'privoxy-script' stdout output: [info] VPN is enabled, checking VPN tunnel local ip is valid 2016-05-03 12:41:32,467 DEBG 'start-script' stdout output: [info] VPN is enabled, beginning configuration of VPN 2016-05-03 12:41:32,701 DEBG 'start-script' stdout output: [info] VPN provider defined as pia [info] VPN config file (ovpn extension) is located at /config/openvpn/openvpn.ovpn 2016-05-03 12:41:32,746 DEBG 'start-script' stdout output: [info] Env vars defined via docker -e flags for remote host, port and protocol, writing values to ovpn file... 2016-05-03 12:41:32,777 DEBG 'start-script' stdout output: [info] VPN provider remote gateway defined as nl.privateinternetaccess.com [info] VPN provider remote port defined as 1194 [info] VPN provider remote protocol defined as udp 2016-05-03 12:41:32,789 DEBG 'start-script' stdout output: [info] VPN provider username defined as SNIP 2016-05-03 12:41:32,798 DEBG 'start-script' stdout output: [info] VPN provider password defined as SNIP 2016-05-03 12:41:32,830 DEBG 'start-script' stdout output: [info] Default route for container is 172.17.42.1 2016-05-03 12:41:32,843 DEBG 'start-script' stdout output: [info] Setting permissions recursively on /config/openvpn... 2016-05-03 12:41:32,849 DEBG 'start-script' stdout output: [info] Adding 192.168.0.0/24 as route via docker eth0 2016-05-03 12:41:32,850 DEBG 'start-script' stdout output: [info] ip route defined as follows... 2016-05-03 12:41:32,851 DEBG 'start-script' stdout output: -------------------- 2016-05-03 12:41:32,852 DEBG 'start-script' stdout output: default via 172.17.42.1 dev eth0 2016-05-03 12:41:32,852 DEBG 'start-script' stdout output: 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.24 192.168.0.0/24 via 172.17.42.1 dev eth0 2016-05-03 12:41:32,852 DEBG 'start-script' stdout output: -------------------- 2016-05-03 12:41:32,860 DEBG 'start-script' stdout output: [info] iptable_mangle module not supported, attempting to load... 2016-05-03 12:41:32,861 DEBG 'start-script' stderr output: modprobe: FATAL: Module iptable_mangle not found in directory /lib/modules/4.1.18-unRAID 2016-05-03 12:41:32,861 DEBG 'start-script' stdout output: [warn] iptable_mangle module not supported, you will not be able to connect to Deluge webui or Privoxy outside of your LAN 2016-05-03 12:41:32,951 DEBG 'start-script' stdout output: [info] iptables defined as follows... -------------------- 2016-05-03 12:41:32,952 DEBG 'start-script' stdout output: -P INPUT DROP -P FORWARD ACCEPT -P OUTPUT DROP -A INPUT -i tun0 -j ACCEPT -A INPUT -s 172.17.0.0/16 -d 172.17.0.0/16 -j ACCEPT -A INPUT -i eth0 -p udp -m udp --sport 1194 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --dport 8112 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --sport 8112 -j ACCEPT -A INPUT -s 192.168.0.0/24 -i eth0 -p tcp -m tcp --dport 58846 -j ACCEPT -A INPUT -p udp -m udp --sport 53 -j ACCEPT -A INPUT -p icmp -m icmp --icmp-type 0 -j ACCEPT -A INPUT -i lo -j ACCEPT -A OUTPUT -o tun0 -j ACCEPT -A OUTPUT -s 172.17.0.0/16 -d 172.17.0.0/16 -j ACCEPT -A OUTPUT -o eth0 -p udp -m udp --dport 1194 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --dport 8112 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --sport 8112 -j ACCEPT -A OUTPUT -d 192.168.0.0/24 -o eth0 -p tcp -m tcp --sport 58846 -j ACCEPT -A OUTPUT -p udp -m udp --dport 53 -j ACCEPT -A OUTPUT -p icmp -m icmp --icmp-type 8 -j ACCEPT -A OUTPUT -o lo -j ACCEPT 2016-05-03 12:41:32,953 DEBG 'start-script' stdout output: -------------------- [info] nameservers 2016-05-03 12:41:32,954 DEBG 'start-script' stdout output: nameserver 8.8.8.8 nameserver 8.8.4.4 2016-05-03 12:41:32,954 DEBG 'start-script' stdout output: -------------------- [info] Starting OpenVPN... 2016-05-03 12:41:33,012 DEBG 'start-script' stdout output: Tue May 3 12:41:33 2016 OpenVPN 2.3.9 x86_64-unknown-linux-gnu [sSL (OpenSSL)] [LZO] [EPOLL] [MH] [iPv6] built on Dec 24 2015 Tue May 3 12:41:33 2016 library versions: OpenSSL 1.0.2f 28 Jan 2016, LZO 2.09 Tue May 3 12:41:33 2016 WARNING: file 'credentials.conf' is group or others accessible 2016-05-03 12:41:33,041 DEBG 'start-script' stdout output: Tue May 3 12:41:33 2016 UDPv4 link local: [undef] Tue May 3 12:41:33 2016 UDPv4 link remote: [AF_INET]46.166.190.236:1194 2016-05-03 12:41:33,162 DEBG 'start-script' stdout output: Tue May 3 12:41:33 2016 WARNING: this configuration may cache passwords in memory -- use the auth-nocache option to prevent this 2016-05-03 12:41:33,562 DEBG 'start-script' stdout output: Tue May 3 12:41:33 2016 [Private Internet Access] Peer Connection Initiated with [AF_INET]46.166.190.236:1194 2016-05-03 12:41:36,195 DEBG 'start-script' stdout output: Tue May 3 12:41:36 2016 TUN/TAP device tun0 opened Tue May 3 12:41:36 2016 do_ifconfig, tt->ipv6=0, tt->did_ifconfig_ipv6_setup=0 Tue May 3 12:41:36 2016 /usr/bin/ip link set dev tun0 up mtu 1500 2016-05-03 12:41:36,196 DEBG 'start-script' stdout output: Tue May 3 12:41:36 2016 /usr/bin/ip addr add dev tun0 local 10.183.1.6 peer 10.183.1.5 2016-05-03 12:41:36,205 DEBG 'start-script' stdout output: Tue May 3 12:41:36 2016 Initialization Sequence Completed 2016-05-03 12:41:36,225 DEBG 'deluge-script' stdout output: [info] First run detected, setting Deluge listening interface 10.183.1.6 2016-05-03 12:41:36,341 DEBG 'privoxy-script' stdout output: [info] Privoxy set to disabled 2016-05-03 12:41:36,341 DEBG fd 24 closed, stopped monitoring <POutputDispatcher at 47066811981624 for <Subprocess at 47066811978312 with name privoxy-script in state RUNNING> (stderr)> 2016-05-03 12:41:36,341 DEBG fd 20 closed, stopped monitoring <POutputDispatcher at 47066811981192 for <Subprocess at 47066811978312 with name privoxy-script in state RUNNING> (stdout)> 2016-05-03 12:41:36,341 INFO exited: privoxy-script (exit status 0; expected) 2016-05-03 12:41:36,342 DEBG received SIGCLD indicating a child quit 2016-05-03 12:41:32,954 DEBG 'start-script' stdout output: nameserver 8.8.8.8 nameserver 8.8.4.4 2016-05-03 12:41:32,954 DEBG 'start-script' stdout output: -------------------- [info] Starting OpenVPN... 2016-05-03 12:41:33,012 DEBG 'start-script' stdout output: Tue May 3 12:41:33 2016 OpenVPN 2.3.9 x86_64-unknown-linux-gnu [sSL (OpenSSL)] [LZO] [EPOLL] [MH] [iPv6] built on Dec 24 2015 Tue May 3 12:41:33 2016 library versions: OpenSSL 1.0.2f 28 Jan 2016, LZO 2.09 Tue May 3 12:41:33 2016 WARNING: file 'credentials.conf' is group or others accessible 2016-05-03 12:41:33,041 DEBG 'start-script' stdout output: Tue May 3 12:41:33 2016 UDPv4 link local: [undef] Tue May 3 12:41:33 2016 UDPv4 link remote: [AF_INET]46.166.190.236:1194 2016-05-03 12:41:33,162 DEBG 'start-script' stdout output: Tue May 3 12:41:33 2016 WARNING: this configuration may cache passwords in memory -- use the auth-nocache option to prevent this 2016-05-03 12:41:33,562 DEBG 'start-script' stdout output: Tue May 3 12:41:33 2016 [Private Internet Access] Peer Connection Initiated with [AF_INET]46.166.190.236:1194 2016-05-03 12:41:36,195 DEBG 'start-script' stdout output: Tue May 3 12:41:36 2016 TUN/TAP device tun0 opened Tue May 3 12:41:36 2016 do_ifconfig, tt->ipv6=0, tt->did_ifconfig_ipv6_setup=0 Tue May 3 12:41:36 2016 /usr/bin/ip link set dev tun0 up mtu 1500 2016-05-03 12:41:36,196 DEBG 'start-script' stdout output: Tue May 3 12:41:36 2016 /usr/bin/ip addr add dev tun0 local 10.183.1.6 peer 10.183.1.5 2016-05-03 12:41:36,205 DEBG 'start-script' stdout output: Tue May 3 12:41:36 2016 Initialization Sequence Completed 2016-05-03 12:41:36,225 DEBG 'deluge-script' stdout output: [info] First run detected, setting Deluge listening interface 10.183.1.6 2016-05-03 12:41:36,341 DEBG 'privoxy-script' stdout output: [info] Privoxy set to disabled 2016-05-03 12:41:36,341 DEBG fd 24 closed, stopped monitoring <POutputDispatcher at 47066811981624 for <Subprocess at 47066811978312 with name privoxy-script in state RUNNING> (stderr)> 2016-05-03 12:41:36,341 DEBG fd 20 closed, stopped monitoring <POutputDispatcher at 47066811981192 for <Subprocess at 47066811978312 with name privoxy-script in state RUNNING> (stdout)> 2016-05-03 12:41:36,341 INFO exited: privoxy-script (exit status 0; expected) 2016-05-03 12:41:36,342 DEBG received SIGCLD indicating a child quit 2016-05-03 12:41:37,775 DEBG 'deluge-script' stdout output: [info] First run detected, setting Deluge incoming port 51366 2016-05-03 12:41:37,775 DEBG 'deluge-script' stdout output: [info] Setting listening interface for Deluge... 2016-05-03 12:41:37,786 DEBG 'deluge-script' stdout output: [info] All checks complete, starting Deluge... 2016-05-03 12:41:37,999 DEBG 'deluge-script' stdout output: [info] Setting incoming port for Deluge... 2016-05-03 12:41:39,426 DEBG 'webui-script' stdout output: [info] Starting Deluge webui... 2016-05-03 12:41:40,004 DEBG 'deluge-script' stdout output: Setting random_port to False.. Configuration value successfully updated. 2016-05-03 12:41:40,533 DEBG 'deluge-script' stdout output: Setting listen_ports to (51366, 51366).. Configuration value successfully updated. 2016-05-03 12:41:40,580 DEBG 'deluge-script' stdout output: [info] Sleeping for 5 mins before rechecking listen interface and port (port checking is for PIA only) 2016-05-03 12:41:41,866 DEBG 'webui-script' stderr output: /usr/lib/python2.7/site-packages/pkg_resources/__init__.py:1246: UserWarning: /home/nobody/.python-eggs is writable by group/others and vulnerable to attack when used with get_resource_filename. Consider a more secure location (set with .set_extraction_path or the PYTHON_EGG_CACHE environment variable). warnings.warn(msg, UserWarning) 2016-05-03 12:43:13,201 DEBG 'start-script' stdout output: Tue May 3 12:43:13 2016 Authenticate/Decrypt packet error: packet HMAC authentication failed 2016-05-03 12:44:14,571 DEBG 'start-script' stdout output: Tue May 3 12:44:14 2016 Authenticate/Decrypt packet error: packet HMAC authentication failed I did some googling and other people who have experienced this error say it is some kind of TLS error and mention some ways to address it but I wanted to see what you thought about the issue first. EDIT: and now it seems to have stopped. I guess it must have been one of the torrents I was downloading? EDIT2: It seems to have stopped right after this: 2016-05-03 14:14:20,784 DEBG 'webui-script' stderr output: Unhandled error in Deferred: 2016-05-03 14:14:20,890 DEBG 'webui-script' stderr output: Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/twisted/protocols/policies.py", line 120, in dataReceived self.wrappedProtocol.dataReceived(data) File "/usr/lib/python2.7/site-packages/deluge/ui/client.py", line 179, in dataReceived d.callback(request[2]) File "/usr/lib/python2.7/site-packages/twisted/internet/defer.py", line 393, in callback self._startRunCallbacks(result) File "/usr/lib/python2.7/site-packages/twisted/internet/defer.py", line 501, in _startRunCallbacks self._runCallbacks() --- <exception caught here> --- File "/usr/lib/python2.7/site-packages/twisted/internet/defer.py", line 588, in _runCallbacks current.result = callback(current.result, *args, **kw) File "/usr/lib/python2.7/site-packages/deluge/ui/web/json_api.py", line 579, in _on_got_files for index, torrent_file in enumerate(files): exceptions.TypeError: 'NoneType' object is not iterable
-
So it is. What would be the proper way to rectify this? Just move any content out of the appdata folders under user and/or user0 into the /mnt/cache/appdata folder and delete the root appdata directories from user and user0? I must not have something set up right in UnRAID in the first place as even folders that I had explicitly created on the cache drive under /mnt/cache are showing up in the /mnt/user (or user0) folder. These are folders that I SSH into the machine and created with mkdir under /mnt/cache. Could this be because I have disk shares turned on?
-
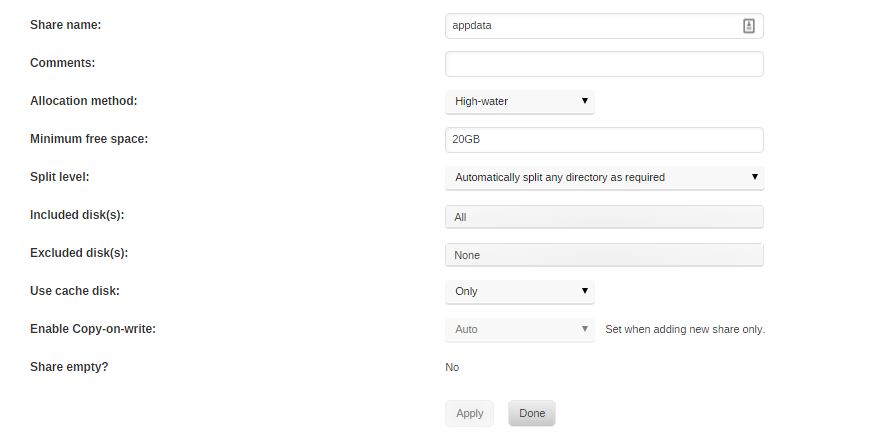
Hey Squid, I am trying to setup the backup feature of CA and my appdata share isn't listed even though I triple checked that it is set to cache only (see attachment). Any ideas on what I am missing? UnRAID v6.1.9 with latest CA installed.
-
Ah okay, that makes sense. Would using a port forward enabled end point put me at risk of having my ip leaked? Still new to the whole VPN thing and PIA warns in their support area that "Port Forwarding reduces privacy. For maximum privacy, please keep port forwarding disabled." I seem to be able to connect to other peers just fine without actually using a forwarding enabled end point (all though it does take longer and my speeds suffer somewhat because of it).
-
Any thoughts?
-
I have noticed this running through my docker log for DelugeVPN (referring to the "Error: Invalid port specification" & the "malformed expression"): 2016-04-24 14:09:27,263 DEBG 'deluge-script' stdout output: [info] Sleeping for 5 mins before rechecking listen interface and port (port checking is for PIA only) 2016-04-24 14:14:27,270 DEBG 'deluge-script' stdout output: [info] Deluge listening interface IP 10.117.1.6 and VPN provider IP 10.117.1.6 match 2016-04-24 14:14:27,342 DEBG 'deluge-script' stderr output: Error: Invalid port specification: 2016-04-24 14:14:27,342 DEBG 'deluge-script' stdout output: [info] Deluge incoming port closed 2016-04-24 14:14:28,089 DEBG 'deluge-script' stdout output: [info] Reconfiguring for VPN provider port 2016-04-24 14:14:28,089 DEBG 'deluge-script' stdout output: [info] Setting listening interface for Deluge... 2016-04-24 14:14:28,530 DEBG 'deluge-script' stdout output: Setting listen_interface to 10.117.1.6.. Configuration value successfully updated. 2016-04-24 14:14:28,574 DEBG 'deluge-script' stdout output: [info] Setting incoming port for Deluge... 2016-04-24 14:14:29,008 DEBG 'deluge-script' stdout output: Setting random_port to False.. Configuration value successfully updated. 2016-04-24 14:14:29,478 DEBG 'deluge-script' stderr output: [ERROR ] 14:14:29 main:347 malformed expression (,) Traceback (most recent call last): File "/usr/lib/python2.7/site-packages/deluge/ui/console/main.py", line 344, in do_command ret = self._commands[cmd].handle(*args, **options.__dict__) File "/usr/lib/python2.7/site-packages/deluge/ui/console/commands/config.py", line 102, in handle return self._set_config(*args, **options) File "/usr/lib/python2.7/site-packages/deluge/ui/console/commands/config.py", line 136, in _set_config val = simple_eval(options["set"][1] + " " .join(args)) File "/usr/lib/python2.7/site-packages/deluge/ui/console/commands/config.py", line 85, in simple_eval res = atom(src.next, src.next()) File "/usr/lib/python2.7/site-packages/deluge/ui/console/commands/config.py", line 54, in atom out.append(atom(next, token)) File "/usr/lib/python2.7/site-packages/deluge/ui/console/commands/config.py", line 77, in atom raise SyntaxError("malformed expression (%s)" % token[1]) I think this might have to do with the fact that I changed the privoxy port so deluge and sabnzbd could run side by side but figured I had better check with you to be sure. Even though privoxy is disabled in sab it still appears to bind the port so deluge wouldn't start until I changed it. Is it safe to just remove the port bindings from both if I don't intend on using privoxy with either of them?
-
For clarification of your statement on GitHub about Privoxy: "It also includes Privoxy to allow unfiltered access to index sites." Privoxy is only necessary if your ISP is filtering access to index sites and privoxy tunnels that access through the VPN? So if I don't have any ISP filtering like that I can simply leave privoxy disabled? EDIT: Nevermind, found the explanation I was looking for in your DelugeVPN support thread. To answer my own question, yes.
-
Will this be something handled by the update process when that feature is removed? Or will users need to go in and manually un-map the transcode directory when this change takes affect? I had to unmap mine What version of PMS are you using, the latest update? I tried removing the mapping after I updated today and plex got pissed and wouldn't play anything that required transcoding. Sent from my XT1096 using Tapatalk I'm running 0.9.16.4 I'm referring to the DOCKER mapping I had for /transcode, not the one under PMS/Server/Transcoder. I've let that one blank so that it just defaults to config has intended. I am also on 0.9.16.4. That is probably where my issue is, I had removed the docker mapping but left the mapping to /transcode under PMS/Server/Transcoder as I was fairly certain that was the default value when I first installed PMS. EDIT: Yes that was indeed my problem, thanks!
-
Will this be something handled by the update process when that feature is removed? Or will users need to go in and manually un-map the transcode directory when this change takes affect? I had to unmap mine What version of PMS are you using, the latest update? I tried removing the mapping after I updated today and plex got pissed and wouldn't play anything that required transcoding. Did you have to change the directory for transcoding in the server interface as well to something other than /transcode? I assumed that since plex would force transcoding to the config directory I wouldn't need to change anything in the server settings besides removing the docker mapping. Sent from my XT1096 using Tapatalk
-
Will this be something handled by the update process when that feature is removed? Or will users need to go in and manually un-map the transcode directory when this change takes affect?
-
Ok I created a test account so I wouldn't hose my real dropbox if I did something stupid. Where exactly is the dropbox.py file, in the docker.img itself? I assumed that it would be in one of the mapped container volumes but I can't seem to find it. Well I think I found. It appears as though dropbox.py is in /usr/local/bin/dropbox.py inside the docker but when I run the exclude add command I get an error. I am trying to follow along loosely with these instructions but am getting an error that Dropbox isn't running. The command I tried: root@VOID:/# docker exec Dropbox /usr/local/bin/dropbox.py exclude add Dropbox/test Dropbox isn't running!
-
Try running swapoff on this swapfile and then swapon again. Same issue. It will create the swap file fine but it won't start it. Let me know what info you might need from me to troubleshoot. root@VOID:~# swapoff -v /mnt/cache/swapfile swapoff on /mnt/cache/swapfile swapoff: /mnt/cache/swapfile: swapoff failed: Invalid argument root@VOID:~# swapon -v /mnt/cache/swapfile swapon on /mnt/cache/swapfile swapon: /mnt/cache/swapfile: found swap signature: version 1, page-size 4, same byte order swapon: /mnt/cache/swapfile: pagesize=4096, swapsize=4294967296, devsize=4294967296 swapon: /mnt/cache/swapfile: swapon failed: Invalid argument
-
Had some issues with my cache drive yesterday and ended up reformatting it. Now when I try to start the swap I get "swapon failed: Invalid argument". I am creating the swap on /mnt/cache as recommended and I didn't have any issues with the plugin until I reformatted the cache drive. Any ideas? Tried to do it manually via SSH and encountered the same error: root@VOID:~# swapon -v /mnt/cache/swapfile swapon on /mnt/cache/swapfile swapon: /mnt/cache/swapfile: found swap signature: version 1, page-size 4, same byte order swapon: /mnt/cache/swapfile: pagesize=4096, swapsize=4294967296, devsize=4294967296 swapon: /mnt/cache/swapfile: swapon failed: Invalid argument
-
Well it turns out the icons are there and display correctly when viewing Tower/Main but not under Tower/Main/UnassignedDevices. I tried to view the page in both Firefox and Chrome after clearing the browser cache. That is quite curious. You put Tower/Main/UnassignedDevices in the browser URL. I did that and reproduced what you found. I didn't know that even worked. Let me take a look. Well I am still new to UnRAID 6 and the whole plugin/docker interface and I found that by simply clicking the plugin image under the installed plugins page (at least for some plugins like swap file) I could quickly get to the settings/interface for that plugin. So that is what I did with this plugin thinking that was the quickest way to get to the interface.
-
Does your Dropbox docker support selective sync (ie I can pick which folders I want to be synchronized)? Do any of the current Dropbox dockers support this? I know it is possible in the official application so if not I might just make a Linux VM and use the official dropbox application for my needs.
-
Well it turns out the icons are there and display correctly when viewing Tower/Main but not under Tower/Main/UnassignedDevices. I tried to view the page in both Firefox and Chrome after clearing the browser cache.
-
I just installed your plugin and it seems to be working fine (I haven't tried to mount anything yet as I am not home) except I seem to be missing the log and script icons in the webgui. I tried removing the plugin and reinstalling from the repo to no avail. Looking in the flash\config\plguins\unassigned.devices\ directory there is no icons folder (which is where the plugin appears to be looking for these icons). Here is a link to my Diagnostics dump: https://dl.dropboxusercontent.com/u/70586667/void-diagnostics-20160210-1707.zip Let me know if there is further information you would like me to provide.


