




bally12345
Members
-
Joined
-
Last visited
Everything posted by bally12345
-
Created a new VM and copied everything across and seems to be working great so not sure whats going on with the original VM, whethers its OS issue or VM config.
-
server-diagnostics-20260625-0814.zip I have attached diagnositcs, anyone able to see if there is something very obviously wrong? also fixed the passthrough I believe but made no difference <?xml version='1.0' encoding='UTF-8'?> <domain type='kvm' id='5'> <name>Windows 11</name> <uuid>996dd70b-875d-f9ba-0d9c-b1cd88f2825a</uuid> <metadata> <vmtemplate xmlns="unraid" name="Windows 11" icon="windows11.png" os="windowstpm" iconold="windows11.png" webui=""/> </metadata> <memory unit='KiB'>16777216</memory> <currentMemory unit='KiB'>16777216</currentMemory> <memoryBacking> <nosharepages/> </memoryBacking> <vcpu placement='static'>10</vcpu> <cputune> <vcpupin vcpu='0' cpuset='2'/> <vcpupin vcpu='1' cpuset='3'/> <vcpupin vcpu='2' cpuset='4'/> <vcpupin vcpu='3' cpuset='5'/> <vcpupin vcpu='4' cpuset='6'/> <vcpupin vcpu='5' cpuset='7'/> <vcpupin vcpu='6' cpuset='8'/> <vcpupin vcpu='7' cpuset='9'/> <vcpupin vcpu='8' cpuset='10'/> <vcpupin vcpu='9' cpuset='11'/> <emulatorpin cpuset='0-1'/> </cputune> <resource> <partition>/machine</partition> </resource> <os> <type arch='x86_64' machine='pc-q35-10.2'>hvm</type> <loader readonly='yes' type='pflash' format='raw'>/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi-tpm.fd</loader> <nvram format='raw'>/etc/libvirt/qemu/nvram/996dd70b-875d-f9ba-0d9c-b1cd88f2825a_VARS-pure-efi-tpm.fd</nvram> </os> <features> <acpi/> <apic/> <hyperv mode='custom'> <relaxed state='on'/> <vapic state='on'/> <spinlocks state='on' retries='8191'/> <vpindex state='on'/> <synic state='on'/> <stimer state='on'/> <vendor_id state='on' value='none'/> </hyperv> <kvm> <hidden state='on'/> </kvm> <vmport state='off'/> <ioapic driver='kvm'/> </features> <cpu mode='host-passthrough' check='none' migratable='on'> <topology sockets='1' dies='1' clusters='1' cores='5' threads='2'/> <cache mode='passthrough'/> </cpu> <clock offset='localtime'> <timer name='hpet' present='no'/> <timer name='hypervclock' present='yes'/> </clock> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <devices> <emulator>/usr/local/sbin/qemu</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback' discard='unmap'/> <source file='/mnt/cache/domains/Windows 10/vdisk1.img' index='2'/> <backingStore/> <target dev='hdc' bus='virtio'/> <serial>vdisk1</serial> <boot order='1'/> <alias name='virtio-disk2'/> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </disk> <disk type='file' device='cdrom'> <driver name='qemu' type='raw'/> <source file='/mnt/user/iso/virtio-win-0.1.285-1.iso' index='1'/> <backingStore/> <target dev='hdb' bus='scsi'/> <readonly/> <alias name='scsi0-0-0-1'/> <address type='drive' controller='0' bus='0' target='0' unit='1'/> </disk> <controller type='scsi' index='0' model='virtio-scsi'> <alias name='scsi0'/> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </controller> <controller type='pci' index='0' model='pcie-root'> <alias name='pcie.0'/> </controller> <controller type='pci' index='1' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='1' port='0x8'/> <alias name='pci.1'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x0' multifunction='on'/> </controller> <controller type='pci' index='2' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='2' port='0x9'/> <alias name='pci.2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x1'/> </controller> <controller type='pci' index='3' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='3' port='0xa'/> <alias name='pci.3'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x2'/> </controller> <controller type='pci' index='4' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='4' port='0xb'/> <alias name='pci.4'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x3'/> </controller> <controller type='pci' index='5' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='5' port='0xc'/> <alias name='pci.5'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x4'/> </controller> <controller type='pci' index='6' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='6' port='0xd'/> <alias name='pci.6'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x5'/> </controller> <controller type='pci' index='7' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='7' port='0xe'/> <alias name='pci.7'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x6'/> </controller> <controller type='pci' index='8' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='8' port='0xf'/> <alias name='pci.8'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x7'/> </controller> <controller type='sata' index='0'> <alias name='ide'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x1f' function='0x2'/> </controller> <controller type='virtio-serial' index='0'> <alias name='virtio-serial0'/> <address type='pci' domain='0x0000' bus='0x02' slot='0x00' function='0x0'/> </controller> <controller type='usb' index='0' model='qemu-xhci' ports='15'> <alias name='usb'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0'/> </controller> <interface type='bridge'> <mac address='52:54:00:62:97:d2'/> <source bridge='br0'/> <target dev='vnet4'/> <model type='virtio-net'/> <alias name='net0'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </interface> <serial type='pty'> <source path='/dev/pts/0'/> <target type='isa-serial' port='0'> <model name='isa-serial'/> </target> <alias name='serial0'/> </serial> <console type='pty' tty='/dev/pts/0'> <source path='/dev/pts/0'/> <target type='serial' port='0'/> <alias name='serial0'/> </console> <channel type='unix'> <source mode='bind' path='/run/libvirt/qemu/channel/5-Windows 11/org.qemu.guest_agent.0'/> <target type='virtio' name='org.qemu.guest_agent.0' state='connected'/> <alias name='channel0'/> <address type='virtio-serial' controller='0' bus='0' port='1'/> </channel> <input type='mouse' bus='ps2'> <alias name='input0'/> </input> <input type='keyboard' bus='ps2'> <alias name='input1'/> </input> <tpm model='tpm-tis'> <backend type='emulator' version='2.0' persistent_state='yes'/> <alias name='tpm0'/> </tpm> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </source> <alias name='hostdev0'/> <rom file='/mnt/user/iso/vbios/GTX1650-mod.rom'/> <address type='pci' domain='0x0000' bus='0x05' slot='0x00' function='0x0' multifunction='on'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x1'/> </source> <alias name='hostdev1'/> <address type='pci' domain='0x0000' bus='0x05' slot='0x00' function='0x1'/> </hostdev> <watchdog model='itco' action='reset'> <alias name='watchdog0'/> </watchdog> <memballoon model='none'/> </devices> <seclabel type='dynamic' model='dac' relabel='yes'> <label>+0:+100</label> <imagelabel>+0:+100</imagelabel> </seclabel> </domain>
-
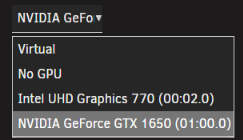
Graphics card is on 01.00.0 and sound card on 01.00.1
-
Not sure what is going on but I have noticed since upgrading to V7.3.1 my Win11 VM is running weirdly, its slow and laggy. Is it still the case when you add GPU passthru you need to configure using XML mode or can you do it all through the gui now? This VM has been setup for about 4 years at a guess, using spaceinvader video. Not sure if the XML is the issue or its OS level fault. <?xml version='1.0' encoding='UTF-8'?> <domain type='kvm' id='5'> <name>Windows 11</name> <uuid>996dd70b-875d-f9ba-0d9c-b1cd88f2825a</uuid> <metadata> <vmtemplate xmlns="unraid" name="Windows 11" icon="windows11.png" os="windowstpm" iconold="windows11.png" webui=""/> </metadata> <memory unit='KiB'>16777216</memory> <currentMemory unit='KiB'>16777216</currentMemory> <memoryBacking> <nosharepages/> </memoryBacking> <vcpu placement='static'>10</vcpu> <cputune> <vcpupin vcpu='0' cpuset='2'/> <vcpupin vcpu='1' cpuset='3'/> <vcpupin vcpu='2' cpuset='4'/> <vcpupin vcpu='3' cpuset='5'/> <vcpupin vcpu='4' cpuset='6'/> <vcpupin vcpu='5' cpuset='7'/> <vcpupin vcpu='6' cpuset='8'/> <vcpupin vcpu='7' cpuset='9'/> <vcpupin vcpu='8' cpuset='10'/> <vcpupin vcpu='9' cpuset='11'/> <emulatorpin cpuset='0-1'/> </cputune> <resource> <partition>/machine</partition> </resource> <os> <type arch='x86_64' machine='pc-q35-10.2'>hvm</type> <loader readonly='yes' type='pflash' format='raw'>/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi-tpm.fd</loader> <nvram format='raw'>/etc/libvirt/qemu/nvram/996dd70b-875d-f9ba-0d9c-b1cd88f2825a_VARS-pure-efi-tpm.fd</nvram> </os> <features> <acpi/> <apic/> <hyperv mode='custom'> <relaxed state='on'/> <vapic state='on'/> <spinlocks state='on' retries='8191'/> <vpindex state='on'/> <synic state='on'/> <stimer state='on'/> <vendor_id state='on' value='none'/> </hyperv> </features> <cpu mode='host-passthrough' check='none' migratable='on'> <topology sockets='1' dies='1' clusters='1' cores='5' threads='2'/> <cache mode='passthrough'/> </cpu> <clock offset='localtime'> <timer name='hpet' present='no'/> <timer name='hypervclock' present='yes'/> </clock> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <devices> <emulator>/usr/local/sbin/qemu</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback' discard='unmap'/> <source file='/mnt/cache/domains/Windows 10/vdisk1.img' index='2'/> <backingStore/> <target dev='hdc' bus='virtio'/> <serial>vdisk1</serial> <boot order='1'/> <alias name='virtio-disk2'/> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </disk> <disk type='file' device='cdrom'> <driver name='qemu' type='raw'/> <source file='/mnt/user/iso/virtio-win-0.1.285-1.iso' index='1'/> <backingStore/> <target dev='hdb' bus='scsi'/> <readonly/> <alias name='scsi0-0-0-1'/> <address type='drive' controller='0' bus='0' target='0' unit='1'/> </disk> <controller type='scsi' index='0' model='virtio-scsi'> <alias name='scsi0'/> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </controller> <controller type='pci' index='0' model='pcie-root'> <alias name='pcie.0'/> </controller> <controller type='pci' index='1' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='1' port='0x8'/> <alias name='pci.1'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x0' multifunction='on'/> </controller> <controller type='pci' index='2' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='2' port='0x9'/> <alias name='pci.2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x1'/> </controller> <controller type='pci' index='3' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='3' port='0xa'/> <alias name='pci.3'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x2'/> </controller> <controller type='pci' index='4' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='4' port='0xb'/> <alias name='pci.4'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x3'/> </controller> <controller type='pci' index='5' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='5' port='0xc'/> <alias name='pci.5'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x4'/> </controller> <controller type='pci' index='6' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='6' port='0xd'/> <alias name='pci.6'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x5'/> </controller> <controller type='pci' index='7' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='7' port='0xe'/> <alias name='pci.7'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x6'/> </controller> <controller type='pci' index='8' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='8' port='0xf'/> <alias name='pci.8'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x7'/> </controller> <controller type='sata' index='0'> <alias name='ide'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x1f' function='0x2'/> </controller> <controller type='virtio-serial' index='0'> <alias name='virtio-serial0'/> <address type='pci' domain='0x0000' bus='0x02' slot='0x00' function='0x0'/> </controller> <controller type='usb' index='0' model='qemu-xhci' ports='15'> <alias name='usb'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0'/> </controller> <interface type='bridge'> <mac address='52:54:00:62:97:d2'/> <source bridge='br0'/> <target dev='vnet4'/> <model type='virtio-net'/> <alias name='net0'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </interface> <serial type='pty'> <source path='/dev/pts/0'/> <target type='isa-serial' port='0'> <model name='isa-serial'/> </target> <alias name='serial0'/> </serial> <console type='pty' tty='/dev/pts/0'> <source path='/dev/pts/0'/> <target type='serial' port='0'/> <alias name='serial0'/> </console> <channel type='unix'> <source mode='bind' path='/run/libvirt/qemu/channel/5-Windows 11/org.qemu.guest_agent.0'/> <target type='virtio' name='org.qemu.guest_agent.0' state='connected'/> <alias name='channel0'/> <address type='virtio-serial' controller='0' bus='0' port='1'/> </channel> <input type='mouse' bus='ps2'> <alias name='input0'/> </input> <input type='keyboard' bus='ps2'> <alias name='input1'/> </input> <tpm model='tpm-tis'> <backend type='emulator' version='2.0' persistent_state='yes'/> <alias name='tpm0'/> </tpm> <audio id='1' type='none'/> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </source> <alias name='hostdev0'/> <rom file='/mnt/user/iso/vbios/GTX1650-mod.rom'/> <address type='pci' domain='0x0000' bus='0x05' slot='0x00' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x1'/> </source> <alias name='hostdev1'/> <address type='pci' domain='0x0000' bus='0x06' slot='0x00' function='0x0'/> </hostdev> <watchdog model='itco' action='reset'> <alias name='watchdog0'/> </watchdog> <memballoon model='none'/> </devices> <seclabel type='dynamic' model='dac' relabel='yes'> <label>+0:+100</label> <imagelabel>+0:+100</imagelabel> </seclabel> </domain> In the log 2026-06-20 09:13:25.384+0000: Domain id=7 is tainted: high-privileges char device redirected to /dev/pts/0 (label charserial0) 2026-06-20T09:13:27.952700Z qemu-system-x86_64: warning: vfio_container_dma_map(0x14977b3d0d80, 0x382000000000, 0x10000000, 0x149760000000) = -22 (Invalid argument) 0000:01:00.0: PCI peer-to-peer transactions on BARs are not supported. GPT and Grok said disable Resizable BAR in BIOS but that was already disabled and BIOS settings are unchanged also. Want just rule out config issue before I nuke the windows install and start again.
-
Just a quick post to share its been over 12 years since starting with Unraid 5.0.5 plus licence and Unraid is still pretty much a part of my daily life!
-
I still have 4TB WD reds that have over 10 years run time and refuse to die!
-
When using the Update OS from Tools menu I get I had to go to top right, open dropdown and do check for updates

-
Just checked the logs and it hasn't occured again since 1 November and it does look like NUT was updated too Nov 1 09:25:44 Server plugin-manager: executing inline script: /bin/bash '/tmp/inline1-nut-dw.sh' Nov 1 09:25:48 Server upsmon[8786]: Signal 15: exiting Nov 1 09:25:48 Server upsd[8783]: User [email protected] logged out from UPS [ups] Nov 1 09:25:48 Server upsd[8783]: mainloop: Interrupted system call Nov 1 09:25:48 Server upsd[8783]: Signal 15: exiting Nov 1 09:25:50 Server usbhid-ups[8776]: Signal 15: exiting Nov 1 09:25:52 Server plugin-manager: checking: /boot/config/plugins/nut-dw/nut-2.8.4-x86_64-2master.ssl31.txz - MD5 Nov 1 09:25:52 Server plugin-manager: skipping: /boot/config/plugins/nut-dw/nut-2.8.4-x86_64-2master.ssl31.txz already exists Nov 1 09:25:52 Server plugin-manager: checking: /boot/config/plugins/nut-dw/nut-2.8.4-x86_64-1stable.ssl31.txz - MD5 Nov 1 09:25:52 Server plugin-manager: skipping: /boot/config/plugins/nut-dw/nut-2.8.4-x86_64-1stable.ssl31.txz already exists Nov 1 09:25:52 Server plugin-manager: checking: /boot/config/plugins/nut-dw/nut-2.8.3-x86_64-2stable.ssl31.txz - MD5 Nov 1 09:25:53 Server plugin-manager: skipping: /boot/config/plugins/nut-dw/nut-2.8.3-x86_64-2stable.ssl31.txz already exists Nov 1 09:25:53 Server plugin-manager: checking: /boot/config/plugins/nut-dw/nut-2.8.2-x86_64-1stable.ssl31.txz - MD5 Nov 1 09:25:53 Server plugin-manager: skipping: /boot/config/plugins/nut-dw/nut-2.8.2-x86_64-1stable.ssl31.txz already exists Nov 1 09:25:53 Server plugin-manager: checking: /boot/config/plugins/nut-dw/nut-2.7.4.20200318-x86_64-1.txz - MD5 Nov 1 09:25:53 Server plugin-manager: skipping: /boot/config/plugins/nut-dw/nut-2.7.4.20200318-x86_64-1.txz already exists Nov 1 09:25:53 Server plugin-manager: executing inline script: /bin/bash '/tmp/inline7-nut-dw.sh' Nov 1 09:25:53 Server plugin-manager: checking: /boot/config/plugins/nut-dw/net-snmp-5.9.4-x86_64-1.txz - MD5 Nov 1 09:25:53 Server plugin-manager: skipping: /boot/config/plugins/nut-dw/net-snmp-5.9.4-x86_64-1.txz already exists Nov 1 09:25:53 Server plugin-manager: running: upgradepkg --install-new /boot/config/plugins/nut-dw/net-snmp-5.9.4-x86_64-1.txz Nov 1 09:25:53 Server plugin-manager: checking: /boot/config/plugins/nut-dw/libmodbus-3.1.11-x86_64-1nut_slack15.1.txz - MD5 Nov 1 09:25:53 Server plugin-manager: skipping: /boot/config/plugins/nut-dw/libmodbus-3.1.11-x86_64-1nut_slack15.1.txz already exists Nov 1 09:25:53 Server plugin-manager: running: upgradepkg --install-new /boot/config/plugins/nut-dw/libmodbus-3.1.11-x86_64-1nut_slack15.1.txz Nov 1 09:25:53 Server plugin-manager: creating: /boot/config/plugins/nut-dw/nut-plugin-2025.11.01-x86_64-2.txz - downloading from URL https://raw.githubusercontent.com/desertwitch/NUT-unRAID/master/archive/nut-plugin-2025.11.01-x86_64-2.txz Nov 1 09:25:53 Server plugin-manager: checking: /boot/config/plugins/nut-dw/nut-plugin-2025.11.01-x86_64-2.txz - MD5 Nov 1 09:25:53 Server plugin-manager: running: upgradepkg --install-new /boot/config/plugins/nut-dw/nut-plugin-2025.11.01-x86_64-2.txz Nov 1 09:25:54 Server plugin-manager: executing inline script: /bin/bash '/tmp/inline23-nut-dw.sh' Nov 1 09:25:55 Server rc.nut: Writing NUT configuration... Nov 1 09:25:57 Server rc.nut: Updating permissions for NUT... Nov 1 09:25:57 Server rc.nut: Checking if the NUT Runtime Statistics Module should be enabled... Nov 1 09:25:57 Server rc.nut: Disabling the NUT Runtime Statistics Module... Nov 1 09:25:58 Server rc.nut: WARNING: NUT was user-configured to disable power management for all USB devices. Nov 1 09:25:58 Server rc.nut: WARNING: NUT is now forcing all USB devices to permanent [on] power state as requested... Nov 1 09:25:58 Server rc.nut: Network UPS Tools upsdrvctl - UPS driver controller 2.8.4 release Nov 1 09:25:58 Server rc.nut: Network UPS Tools 2.8.4 release - Generic HID driver 0.67 Nov 1 09:25:58 Server rc.nut: USB communication driver (libusb 1.0) 0.50 Nov 1 09:25:58 Server rc.nut: interrupt pipe disabled (add 'pollonly' flag to 'ups.conf' to get rid of this message) Nov 1 09:25:58 Server rc.nut: Using subdriver: APC HID 0.100 Nov 1 09:25:58 Server rc.nut: Listening on socket /var/run/nut/usbhid-ups-ups Nov 1 09:25:58 Server usbhid-ups[4058256]: Listening on socket /var/run/nut/usbhid-ups-ups Nov 1 09:25:58 Server usbhid-ups[4058258]: Startup successful Nov 1 09:25:59 Server rc.nut: Network UPS Tools upsd 2.8.4 release Nov 1 09:25:59 Server rc.nut: listening on 0.0.0.0 port 3493 Nov 1 09:25:59 Server upsd[4058269]: listening on 0.0.0.0 port 3493 Nov 1 09:25:59 Server upsd[4058269]: Connected to UPS [ups]: usbhid-ups-ups Nov 1 09:25:59 Server usbhid-ups[4058258]: sock_connect: enabling asynchronous mode (auto) Nov 1 09:25:59 Server upsd[4058269]: Found 1 UPS defined in ups.conf Nov 1 09:25:59 Server rc.nut: Connected to UPS [ups]: usbhid-ups-ups Nov 1 09:25:59 Server rc.nut: Found 1 UPS defined in ups.conf Nov 1 09:25:59 Server upsd[4058270]: Startup successful Nov 1 09:25:59 Server rc.nut: Network UPS Tools upsmon 2.8.4 release Nov 1 09:25:59 Server rc.nut: UPS: [email protected] (primary) (power value 1) Nov 1 09:25:59 Server rc.nut: Using power down flag file /etc/nut/no_killpower Nov 1 09:25:59 Server upsmon[4058276]: Startup successful Nov 1 09:25:59 Server upsmon[4058276]: Warning: running as one big root process by request (upsmon -p) Nov 1 09:25:59 Server upsd[4058270]: User [email protected] logged into UPS [ups] Nov 1 09:25:59 Server plugin-manager: nut-dw.plg updatedWill keep an eye on it just in case it happens again.
-
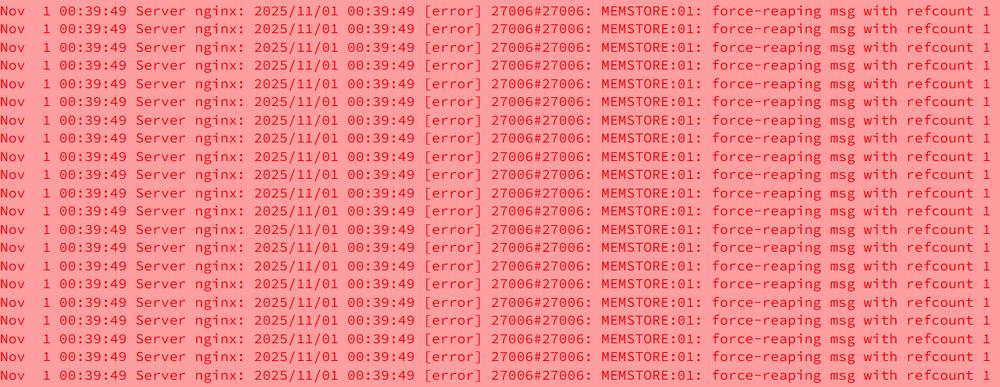
Hi I am on 7.2.0 and noticed in my syslog repeated lines for MEMSTORE:01: force-reaping msg with refcount 1 I haven't been doing much except running mover, theres also autofan script running but not sure if thats related or not. Parity check is also running. server-diagnostics-20251103-1017.zip
-
Didn'r realise google blocked the API access, so switching to googletakeout every 2months instead of weekly backups instead. If anyone has a better way please let me know!
-
Never noticed but looks like my gsync stopped working in May and is returning a 403, tried removeing the client_secret and token but getting anywhere. Does anyone know how I can reactivate the permissions? root@Server:~# docker exec -it GooglePhotosSync gphotos-sync /storage 10-24 10:04:35 WARNING gphotos-sync 3.1.2 2025-10-24 10:04:35.318740 10-24 10:04:35 WARNING Indexing Google Photos Files ... 10-24 10:04:35 ERROR Request failed with status 403: b'{\n "error": {\n "code": 403,\n "message": "Request had insufficient authentication scopes.",\n "status": "PERMISSION_DENIED"\n }\n}\n' 10-24 10:04:35 ERROR Process failed. Traceback (most recent call last): File "/usr/lib/python3.9/site-packages/gphotos_sync/Main.py", line 507, in main self.start(args) File "/usr/lib/python3.9/site-packages/gphotos_sync/Main.py", line 447, in start self.do_sync(args) File "/usr/lib/python3.9/site-packages/gphotos_sync/Main.py", line 411, in do_sync self.google_photos_idx.index_photos_media() File "/usr/lib/python3.9/site-packages/gphotos_sync/GooglePhotosIndex.py", line 148, in index_photos_media items_json = self.search_media( File "/usr/lib/python3.9/site-packages/gphotos_sync/GooglePhotosIndex.py", line 135, in search_media return self._api.mediaItems.search.execute(body).json() # type: ignore File "/usr/lib/python3.9/site-packages/gphotos_sync/restclient.py", line 106, in execute result.raise_for_status() File "/usr/lib/python3.9/site-packages/requests/models.py", line 953, in raise_for_status raise HTTPError(http_error_msg, response=self) requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://photoslibrary.googleapis.com/v1/mediaItems:search 10-24 10:04:35 WARNING Done. root@Server:~#
-
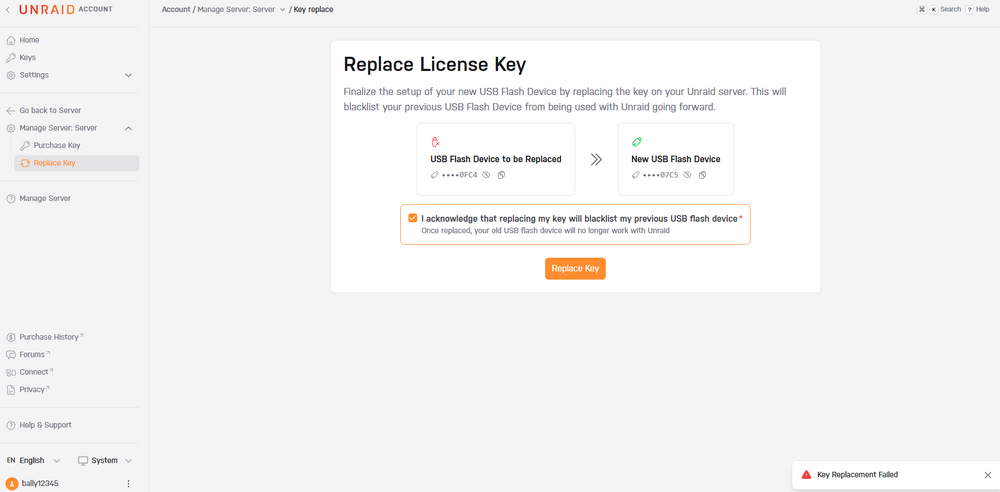
Seem to be having an issue with replacing key so have submitted a ticket this time #15625
-
Copied everything over to new USB and trying replace but get replace key failed message
-
Damn! My bad I have unintentionally blacklisted my USB, will order another one and give that to the kids 😂
-
Found the old USB so hopefully I can copy content over and get server up and running, is there anyway to get USB whitelisted?
-
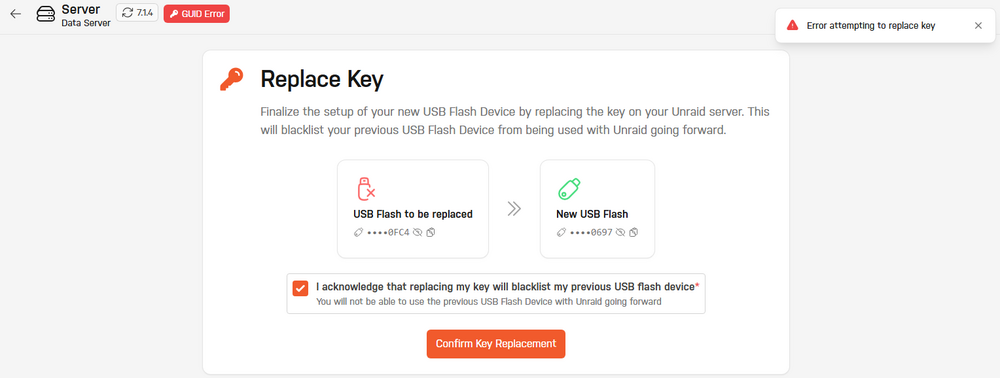
Noticed my flash wasnt backing up and I wasnt able to renew expired certificate. Tried deleting it and provisioning again but get the below in log Aug 11 20:26:40 Server emhttpd: shcmd (201): /usr/bin/php -f /usr/local/emhttp/webGui/include/ProvisionCert.php Aug 11 20:26:40 Server root: Error: Server was unable to provision SSL certificate - Key file missing or contains an invalid GUID Aug 11 20:26:40 Server emhttpd: shcmd (201): exit status: 1 Aug 11 20:26:40 Server emhttpd: shcmd (202): /etc/rc.d/rc.nginx reload Aug 11 20:26:40 Server rc.nginx: Reloading Nginx server daemon... Aug 11 20:26:40 Server rc.nginx: Checking configuration for correct syntax and then trying to open files referenced in configuration... Aug 11 20:26:40 Server rc.nginx: /usr/sbin/nginx -t -c /etc/nginx/nginx.conf Aug 11 20:26:41 Server rc.nginx: Reloading Nginx server daemon configuration... Aug 11 20:26:41 Server root: Stopping nchan processes... Aug 11 20:26:42 Server root: Starting nchan processes...Does anyone know how to fix this, tried to unregister server but it just errors FFS as I was looking deeper for some reason my USB GUID flash is wrong, stopped array and tried to correct but getting error again A few months ago I was troubleshooting problem with my server but I dont remember transferring a key to another USB.
-
I would suggest looking at Kometa instead.
-
Had a quick look at my profile page and joined the forum February 25, 2014, that makes it 11 years!
-
Narrowed it down to CoreFreq plugin, removed it and that sorted everything!
-
Think I might have found the issue Yannick's Tech Blog: Modding a Dell Perc 6 / Dell H310 / Dell H710 (other LSI 1078 or 9223-8i based) SAS Raidcontroller
-
Still seeing this issue and its annoying, got the latest bios version installed, defaulted bios settings moved ram slots but still only showing half the memory. Anyone else having this issue or just me? root@Server:~# lshw -class memory *-firmware:0 description: BIOS vendor: American Megatrends International, LLC. physical id: 1 version: 1.D0 date: 09/26/2024 size: 64KiB capacity: 32MiB capabilities: pci upgrade shadowing cdboot bootselect socketedrom edd int13floppynec int13floppytoshiba int13floppy360 int13floppy1200 int13floppy720 int13floppy2880 int5printscreen int9keyboard int14serial int17printer int10video acpi usb biosbootspecification uefi *-memory description: System Memory physical id: 3a slot: System board or motherboard size: 64GiB *-bank:0 description: [empty] physical id: 0 slot: Controller0-DIMMA1 *-bank:1 description: DIMM DDR4 Synchronous 3200 MHz (0.3 ns) product: CT32G4DFD832A.M16FF vendor: Crucial Technology physical id: 1 serial: E7F10F79 slot: Controller0-DIMMA2 size: 32GiB width: 64 bits clock: 3200MHz (0.3ns) *-firmware:1 description: BIOS physical id: 3d5c size: 8KiB capacity: 64KiB *-firmware:2 description: BIOS physical id: 2 size: 1MiB *-firmware:3 description: BIOS physical id: 3 size: 1MiB *-firmware:4 description: BIOS physical id: 4 size: 1MiB *-firmware:5 description: BIOS physical id: 5 size: 1MiB *-firmware:6 description: BIOS physical id: 6 size: 1MiB capabilities: edd *-firmware:7 description: BIOS physical id: 7 size: 1MiB *-firmware:8 description: BIOS physical id: 9 size: 1MiB *-firmware:9 description: BIOS physical id: a size: 1023KiB *-firmware:10 description: BIOS physical id: b size: 1MiB *-firmware:11 description: BIOS physical id: 8 size: 1MiB *-firmware:12 description: BIOS physical id: c size: 1MiB *-firmware:13 description: BIOS physical id: d size: 1MiB *-firmware:14 description: BIOS physical id: e size: 1MiB *-firmware:15 description: BIOS physical id: f size: 1MiB *-firmware:16 description: BIOS physical id: 10 size: 1MiB *-firmware:17 description: BIOS physical id: 11 size: 1MiB *-firmware:18 description: BIOS physical id: 12 size: 1MiB *-firmware:19 description: BIOS physical id: 13 size: 1MiB *-firmware:20 description: BIOS physical id: 14 size: 1MiB *-firmware:21 description: BIOS physical id: 15 size: 1MiB *-firmware:22 description: BIOS physical id: 16 size: 1MiB *-firmware:23 description: BIOS physical id: 17 size: 1MiB *-firmware:24 description: BIOS physical id: 18 size: 1MiB *-firmware:25 description: BIOS physical id: 19 size: 1MiB *-firmware:26 description: BIOS physical id: 1a size: 1MiB *-firmware:27 description: BIOS physical id: 1b size: 1MiB *-firmware:28 description: BIOS physical id: 1c size: 1MiB *-firmware:29 description: BIOS physical id: 1d size: 1MiB *-firmware:30 description: BIOS physical id: 1e size: 1MiB capabilities: bootselect socketedrom int13floppy360 int13floppy720 int13floppy2880 int5printscreen int9keyboard int17printer int10video *-firmware:31 description: BIOS physical id: 1f size: 1MiB capabilities: eisa pcmcia pnp apm upgrade vesa escd socketedrom pcmciaboot edd int13floppytoshiba int13floppy360 int5printscreen int14serial int17printer int10video *-firmware:32 description: BIOS physical id: 20 size: 1MiB capacity: 7MiB *-firmware:33 description: BIOS physical id: 21 size: 578KiB capacity: 7488KiB capabilities: isa mca eisa pcmcia pnp apm upgrade vesa escd pcmciaboot edd int13floppytoshiba int13floppy360 int5printscreen int9keyboard int17printer int10video *-firmware:34 description: BIOS vendor: Crucial Technology physical id: 22 size: 558KiB capacity: 7MiB *-firmware:35 description: BIOS vendor: TPM 2.0 physical id: 6f43 size: 578KiB capacity: 6976KiB capabilities: mca eisa pnp shadowing vesa escd bootselect int13floppynec int13floppytoshiba int13floppy720 int5printscreen int9keyboard int17printer *-firmware:36 description: BIOS physical id: 23 size: 1MiB *-firmware:37 description: BIOS physical id: 24 size: 1MiB *-firmware:38 description: BIOS physical id: 25 size: 1MiB capabilities: int13floppy720 int13floppy2880 int10video *-firmware:39 description: BIOS physical id: 26 size: 1MiB capabilities: pcmcia pnp escd bootselect socketedrom pcmciaboot edd int13floppytoshiba int13floppy360 int13floppy2880 int5printscreen int9keyboard int17printer int10video *-firmware:40 description: BIOS physical id: 27 size: 1MiB capacity: 4352KiB *-firmware:41 description: BIOS physical id: 28 size: 756KiB capacity: 7104KiB capabilities: isa mca eisa pnp shadowing vesa escd bootselect socketedrom pcmciaboot edd int13floppytoshiba int13floppy360 int5printscreen int9keyboard int17printer int10video *-firmware:42 description: BIOS physical id: 29 size: 582KiB capacity: 7360KiB *-firmware:43 description: BIOS physical id: 4300 size: 566KiB capacity: 6976KiB *-firmware:44 description: BIOS physical id: 6e6f size: 590KiB capacity: 6528KiB capabilities: isa mca eisa pcmcia shadowing vesa bootselect pcmciaboot edd int13floppytoshiba int5printscreen int10video usb ls120boot zipboot *-firmware:45 description: BIOS physical id: 3f1f size: 1MiB capacity: 16MiB *-firmware:46 description: BIOS physical id: 2a size: 1MiB capabilities: int13floppy720 int13floppy2880 int9keyboard int17printer *-firmware:47 description: BIOS physical id: 2b size: 1MiB capabilities: pcmcia pnp upgrade vesa bootselect socketedrom pcmciaboot edd int13floppynec int10video *-firmware:48 description: BIOS physical id: 2c size: 1MiB capacity: 2816KiB *-firmware:49 description: BIOS physical id: 2d size: 852KiB capacity: 4160KiB capabilities: pcmcia upgrade escd socketedrom pcmciaboot edd int13floppy360 int5printscreen int14serial int10video *-firmware:50 description: BIOS physical id: 0 size: 767KiB capacity: 4736KiB *-firmware:51 description: BIOS vendor: 2021-05-15T00:00:00Z physical id: 2b00 version: ? size: 732KiB capacity: 5440KiB capabilities: eisa pnp int13floppy2880 int14serial *-firmware:52 description: BIOS physical id: 401f size: 686KiB capabilities: pnp shadowing int9keyboard int14serial int10video netboot *-cache:0 description: L1 cache physical id: 49 slot: L1 Cache size: 288KiB capacity: 288KiB capabilities: synchronous internal write-back data configuration: level=1 *-cache:1 description: L1 cache physical id: 4a slot: L1 Cache size: 192KiB capacity: 192KiB capabilities: synchronous internal write-back instruction configuration: level=1 *-cache:2 description: L2 cache physical id: 4b slot: L2 Cache size: 7680KiB capacity: 7680KiB capabilities: synchronous internal write-back unified configuration: level=2 *-cache:3 description: L3 cache physical id: 4c slot: L3 Cache size: 24MiB capacity: 24MiB capabilities: synchronous internal write-back unified configuration: level=3 *-cache:4 description: L1 cache physical id: 4d slot: L1 Cache size: 256KiB capacity: 256KiB capabilities: synchronous internal write-back data root@Server:~# lshw -class memory *-firmware:0 description: BIOS vendor: American Megatrends International, LLC. physical id: 1 version: 1.D0 date: 09/26/2024 size: 64KiB capacity: 32MiB capabilities: pci upgrade shadowing cdboot bootselect socketedrom edd int13floppynec int13floppytoshiba int13floppy360 int13floppy1200 int13floppy720 int13floppy2880 int5printscreen int9keyboard int14serial int17printer int10video acpi usb biosbootspecification uefi *-memory description: System Memory physical id: 3a slot: System board or motherboard size: 64GiB *-bank:0 description: [empty] physical id: 0 slot: Controller0-DIMMA1 *-bank:1 description: DIMM DDR4 Synchronous 3200 MHz (0.3 ns) product: CT32G4DFD832A.M16FF vendor: Crucial Technology physical id: 1 serial: E7F10F79 slot: Controller0-DIMMA2 size: 32GiB width: 64 bits clock: 3200MHz (0.3ns) *-firmware:1 description: BIOS physical id: 3d5c size: 8KiB capacity: 64KiB *-firmware:2 description: BIOS physical id: 2 size: 1MiB *-firmware:3 description: BIOS physical id: 3 size: 1MiB *-firmware:4 description: BIOS physical id: 4 size: 1MiB *-firmware:5 description: BIOS physical id: 5 size: 1MiB *-firmware:6 description: BIOS physical id: 6 size: 1MiB capabilities: edd *-firmware:7 description: BIOS physical id: 7 size: 1MiB *-firmware:8 description: BIOS physical id: 9 size: 1MiB *-firmware:9 description: BIOS physical id: a size: 1023KiB *-firmware:10 description: BIOS physical id: b size: 1MiB *-firmware:11 description: BIOS physical id: 8 size: 1MiB *-firmware:12 description: BIOS physical id: c size: 1MiB *-firmware:13 description: BIOS physical id: d size: 1MiB *-firmware:14 description: BIOS physical id: e size: 1MiB *-firmware:15 description: BIOS physical id: f size: 1MiB *-firmware:16 description: BIOS physical id: 10 size: 1MiB *-firmware:17 description: BIOS physical id: 11 size: 1MiB *-firmware:18 description: BIOS physical id: 12 size: 1MiB *-firmware:19 description: BIOS physical id: 13 size: 1MiB *-firmware:20 description: BIOS physical id: 14 size: 1MiB *-firmware:21 description: BIOS physical id: 15 size: 1MiB *-firmware:22 description: BIOS physical id: 16 size: 1MiB *-firmware:23 description: BIOS physical id: 17 size: 1MiB *-firmware:24 description: BIOS physical id: 18 size: 1MiB *-firmware:25 description: BIOS physical id: 19 size: 1MiB *-firmware:26 description: BIOS physical id: 1a size: 1MiB *-firmware:27 description: BIOS physical id: 1b size: 1MiB *-firmware:28 description: BIOS physical id: 1c size: 1MiB *-firmware:29 description: BIOS physical id: 1d size: 1MiB *-firmware:30 description: BIOS physical id: 1e size: 1MiB capabilities: bootselect socketedrom int13floppy360 int13floppy720 int13floppy2880 int5printscreen int9keyboard int17printer int10video *-firmware:31 description: BIOS physical id: 1f size: 1MiB capabilities: eisa pcmcia pnp apm upgrade vesa escd socketedrom pcmciaboot edd int13floppytoshiba int13floppy360 int5printscreen int14serial int17printer int10video *-firmware:32 description: BIOS physical id: 20 size: 1MiB capacity: 7MiB *-firmware:33 description: BIOS physical id: 21 size: 578KiB capacity: 7488KiB capabilities: isa mca eisa pcmcia pnp apm upgrade vesa escd pcmciaboot edd int13floppytoshiba int13floppy360 int5printscreen int9keyboard int17printer int10video *-firmware:34 description: BIOS vendor: Crucial Technology physical id: 22 size: 558KiB capacity: 7MiB *-firmware:35 description: BIOS vendor: TPM 2.0 physical id: 6f43 size: 578KiB capacity: 6976KiB capabilities: mca eisa pnp shadowing vesa escd bootselect int13floppynec int13floppytoshiba int13floppy720 int5printscreen int9keyboard int17printer *-firmware:36 description: BIOS physical id: 23 size: 1MiB *-firmware:37 description: BIOS physical id: 24 size: 1MiB *-firmware:38 description: BIOS physical id: 25 size: 1MiB capabilities: int13floppy720 int13floppy2880 int10video *-firmware:39 description: BIOS physical id: 26 size: 1MiB capabilities: pcmcia pnp escd bootselect socketedrom pcmciaboot edd int13floppytoshiba int13floppy360 int13floppy2880 int5printscreen int9keyboard int17printer int10video *-firmware:40 description: BIOS physical id: 27 size: 1MiB capacity: 4352KiB *-firmware:41 description: BIOS physical id: 28 size: 756KiB capacity: 7104KiB capabilities: isa mca eisa pnp shadowing vesa escd bootselect socketedrom pcmciaboot edd int13floppytoshiba int13floppy360 int5printscreen int9keyboard int17printer int10video *-firmware:42 description: BIOS physical id: 29 size: 582KiB capacity: 7360KiB *-firmware:43 description: BIOS physical id: 4300 size: 566KiB capacity: 6976KiB *-firmware:44 description: BIOS physical id: 6e6f size: 590KiB capacity: 6528KiB capabilities: isa mca eisa pcmcia shadowing vesa bootselect pcmciaboot edd int13floppytoshiba int5printscreen int10video usb ls120boot zipboot *-firmware:45 description: BIOS physical id: 3f1f size: 1MiB capacity: 16MiB *-firmware:46 description: BIOS physical id: 2a size: 1MiB capabilities: int13floppy720 int13floppy2880 int9keyboard int17printer *-firmware:47 description: BIOS physical id: 2b size: 1MiB capabilities: pcmcia pnp upgrade vesa bootselect socketedrom pcmciaboot edd int13floppynec int10video *-firmware:48 description: BIOS physical id: 2c size: 1MiB capacity: 2816KiB *-firmware:49 description: BIOS physical id: 2d size: 852KiB capacity: 4160KiB capabilities: pcmcia upgrade escd socketedrom pcmciaboot edd int13floppy360 int5printscreen int14serial int10video *-firmware:50 description: BIOS physical id: 0 size: 767KiB capacity: 4736KiB *-firmware:51 description: BIOS vendor: 2021-05-15T00:00:00Z physical id: 2b00 version: ? size: 732KiB capacity: 5440KiB capabilities: eisa pnp int13floppy2880 int14serial *-firmware:52 description: BIOS physical id: 401f size: 686KiB capabilities: pnp shadowing int9keyboard int14serial int10video netboot *-cache:0 description: L1 cache physical id: 49 slot: L1 Cache size: 288KiB capacity: 288KiB capabilities: synchronous internal write-back data configuration: level=1 *-cache:1 description: L1 cache physical id: 4a slot: L1 Cache size: 192KiB capacity: 192KiB capabilities: synchronous internal write-back instruction configuration: level=1 *-cache:2 description: L2 cache physical id: 4b slot: L2 Cache size: 7680KiB capacity: 7680KiB capabilities: synchronous internal write-back unified configuration: level=2 *-cache:3 description: L3 cache physical id: 4c slot: L3 Cache size: 24MiB capacity: 24MiB capabilities: synchronous internal write-back unified configuration: level=3 *-cache:4 description: L1 cache physical id: 4d slot: L1 Cache size: 256KiB capacity: 256KiB capabilities: synchronous internal write-back data configuration: level=1 *-cache:5 description: L1 cache physical id: 4e slot: L1 Cache size: 512KiB capacity: 512KiB capabilities: synchronous internal write-back instruction configuration: level=1 *-cache:6 description: L2 cache physical id: 4f slot: L2 Cache size: 4MiB capacity: 4MiB capabilities: synchronous internal write-back unified configuration: level=2 *-cache:7 description: L3 cache physical id: 50 slot: L3 Cache size: 24MiB capacity: 24MiB capabilities: synchronous internal write-back unified configuration: level=3 *-memory UNCLAIMED description: RAM memory product: Raptor Lake-S PCH Shared SRAM vendor: Intel Corporation physical id: 14.2 bus info: pci@0000:00:14.2 version: 11 width: 64 bits clock: 33MHz (30.3ns) capabilities: pm cap_list configuration: latency=0 resources: iomemory:610-60f iomemory:610-60f memory:6101124000-6101127fff memory:610112a000-610112afff root@Server:~#
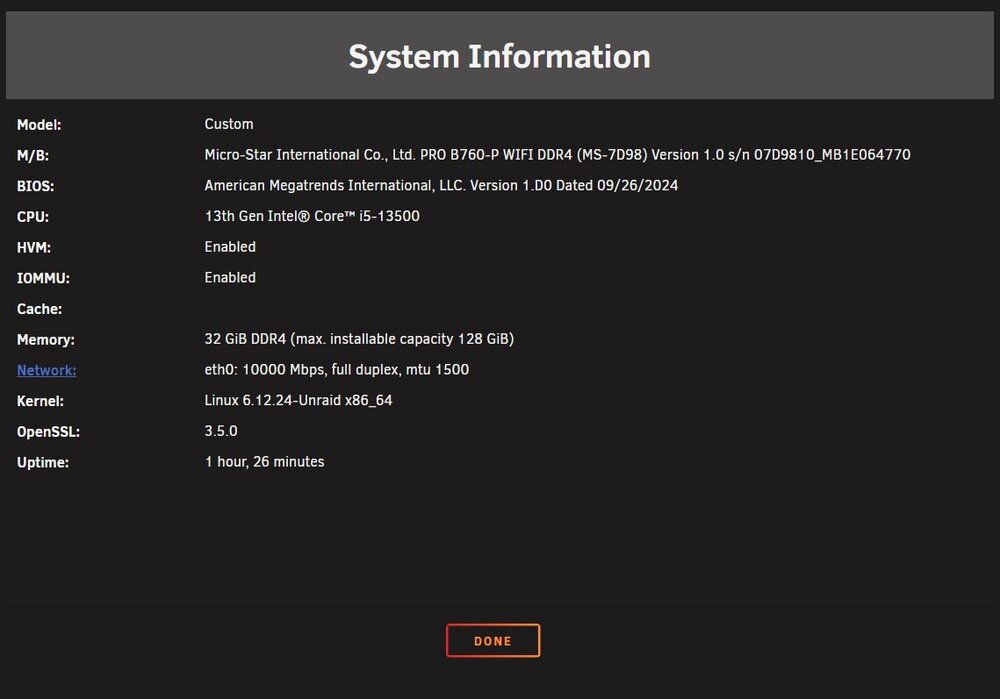
-
Ok got it, drive is rebuilding! Thanks
-
Checked all the connections and removed and added the HBA card back in. I think the breakout cable was loose this is now clicked in. The disk is available and emulated and has option to spin down but dont see how to start rebuild.
-
Replaced disk but something happened and all the drives went offline, the disk rebuild paused, so went shutdown and went back to check everything and started server up again. But now it doesnt seem to be rebuilding the disk. I have just stopped the array. server-diagnostics-20250626-1437.zip Do I need to set disk1 back to no device start array, stop array then assign the new 12TB drive?
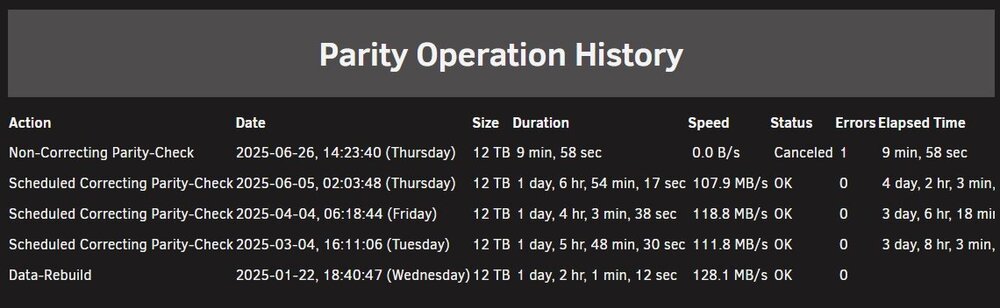
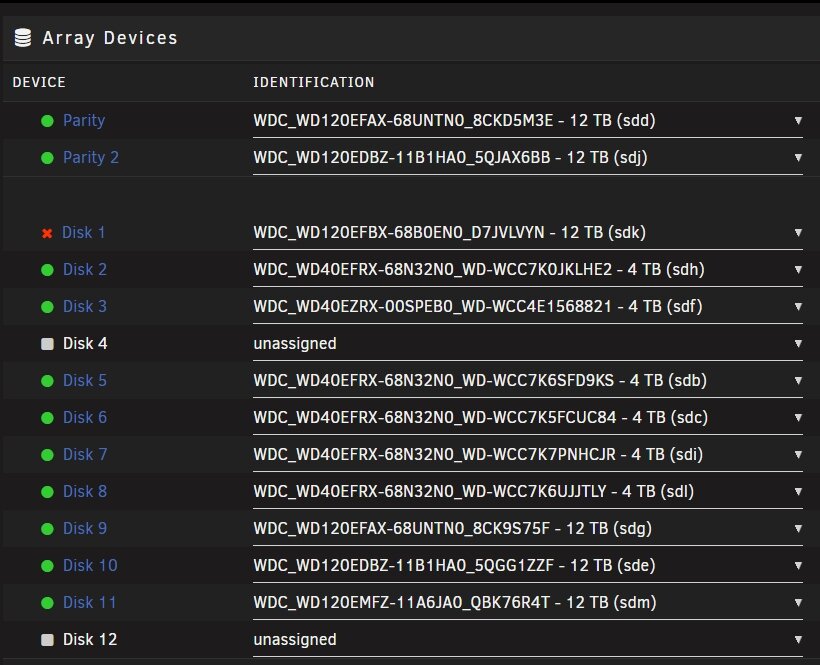
-
Just noticed the test compelted as after 10% Last SMART test result: Completed: servo/seek failure









