thestraycat
Members
-
Joined
-
Last visited
Everything posted by thestraycat
-
Anyone tried the 'Easy Backup' plugin for backing up unraid vm's? it seems relatively new and beta but at least is actively maintained... I will miss the pre and post script options of the vm_backup plugin however.
-
Agreed. However it does look less than optimal.
-
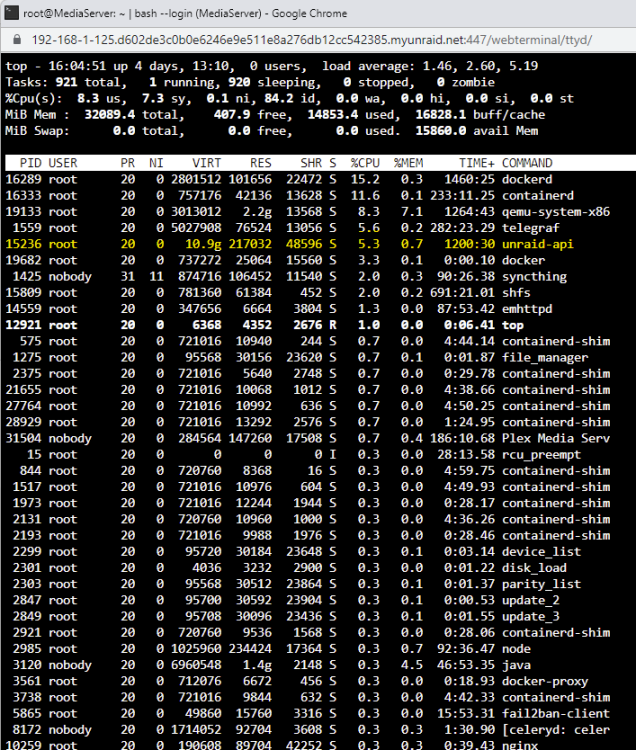
Yup same here.....I'd observed a few changes tbh since updating to the last 2 stable releases. - My idle cpu stats are much more chaotic than they have been on older unraid versions. (I usually idle between 8%-16% cpu now i idle anywhere between 15-50% which has tripled to what it would usually be a few versions back. - After boot my CPU sits at 100% on all cores for around 5 minutes before settling down which is strange behaviour seems to be when loading docker. Didnt do this on previous unraid versions. - Unraid-API seems to always be one of my biggest mem hogs which i hadn't really noticed going back a few versions but it's quite considerable. I've just rebooted the server and unraid-api is straight back up to 10.9g from a cold boot. Maybe the memory handling has changed in a recent version and what im seeing is normal, but with the process being called 'Unraid-API' it dosn't feel like it should be so high. However i have i'm unaware of what this process is doing. I was hoping to not have to go through the painstaking process of inspecting every container and plugin and thought i'd post to see if anyone was experiencing similar...
-
same here.. its been happening for weeks.
-
As observed via top. Seems excessive to me... Can anyone confirm thats a normal usage pattern? Spec: CPU 4c/8t - 32GB ECC.
-
-
Thanks for the info - Yup already running the template authoring mode. Trying to understand why some containers are available directly through the search in CA and other needs you to maually click on "view dockerhub"? I thought this was the difference between 'compliant with unraid' and 'everything else on dockerhub'
-
Thanks - So are you saying the XML is auto generated at the time of 'adding a new container' from the Community Applications plugin? As opposed to being made independantly...
-
Yeah sure. Anything confidential in there though stored in the variables? UPDATE: I've sorted it out now. There were a few dubious files that i've now removed, they may have been down to 2nd instances at some time or failed updates? Either way i had a load of xxx(1).xml files that i've deleted seems to have cleared up the 'installed apps' view nicely. my-radarr.xml my-radarr(1).xml <--deleted. my-radarr.bak @squid - Is there any official documentation for creating containers from scratch using dockerfiles that you want accessible through CA docker apps? I've had to fudge my own XML file to pull down my container nicely... (This was after i noticed the issue with dupes in my 'installed app' view )
-
@JonathanM @Squid Hey Jonathan, yeah i know of the installed/previous option. However it dosn't quite work how i expected. For example, if i view the 'installed apps' and filter by 'docker' i have many 'duplicate entries' in that view, so i'm not sure whether that's a live view or displaying cached entries from somewhere else. nearly all but one of the duplicates are CA containers too. One is imported from dockerhub i believe. Furthermore, If i delete the one of the duplicate instances from 'installed apps' both dissapear, and then when i reinstall the container from 'previous apps' i end up back with 2 identical instances back in 'installed apps'. So i can't even fix it. So as the view is currently polluted with stale entries i cant use it for what which is getting a list of running containers. Is there an API call for grabbing all known running containers built into Unraid or should i just query and filter all this from the native docker engine commands? Bonus points - Is there an unraid container building/compliancy guide on the forum that you know of that i can use to contribute containers to the community and have them display in CA?
-
Did you get to the bottom of it?
-
Hi guys I know the templates live in: /boot/config/plugins/dockerMan/templates-user However any old templates also live in that folder and also old instance and attempts of by-gone years! How can i generate a list of currently live/used XML files? I was wondering if i could query the dockerman parser for a list of XML files that are actively being used right now, but being a parser assumed it's likely unaware of it's state. There must be some info to query to get that list as the containers are obviously re-started ater reboot. Thought i'd ask the forum prior to putting something together to do this, but was hoping for an easier solution. @Squid - Maybe one for you?
-
@dlandon - Thanks, I'll keep both then. Any reason Unassigned Disks+ functionality isn't wrapped up in the standard Unassigned Disks plugin?
-
Hey guys, Do i still need the "Unassigned Devices" plugin if i have the "Unassigned Devices Plus" plugin installed? Do you need unassigned devices plugin as a pre-req for unassigned devices plug or is it more of a case of install one or the other? @dlandon
-
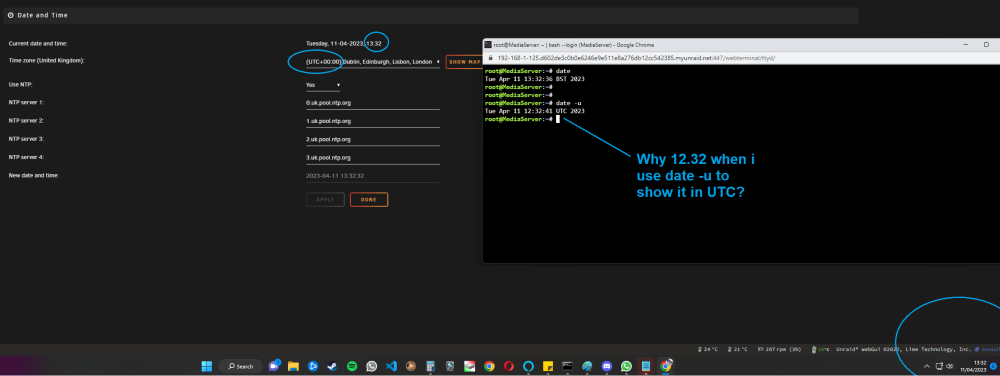
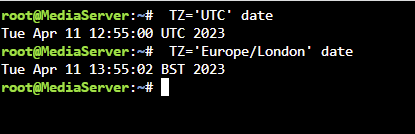
Hi guys - Quick one. I'm trying to troubleshoot some time issues in a container that i use (healthchecks.io) and to outrule any issues being passed to the container i'm looking for some confirmation on how the unraid time is displayed. The time at the time of writing this was 13:32pm when i look in unraid in settings > date and time (UTC, via NTP.) it shows as 13:32pm when i goto the console in unraid and type 'date' i get 13:32pm (which i assume is NTP adjusting my time for BST?) when i goto the console in unraid and type 'date -u' i get 12:32pm (which i assume is forcing UTC time which shows as 12.32pm!) Can someone explain to me why UTC looks different in both? Lastly if i goto the unraid console and view time as per the timezone i see if i set London/Europe time displays as the correct BST time. And when i force UTC timezone i see the older and incorrect time. (time was 13.55pm when i ran the command) In the mean time i'm going to check the BIOS time. But i'm fully expecting this to be correct.
-
Been battling deluge all morning. My Deluge Web UI was prompting me for a password as is usual, and wouldn't accept my usual password. Some how deluges web ui password had defaulted back to 'deluge'. However, when i tried to reset the password back to my previous peronsal password in the web ui, deluge would hang and crash and need a reboot to become responsive. Seemed that my web.conf file was rammed full of stale sessions as the web.conf file had bloated up to 40MB in size and i think deluge was crasing due to it. Since deleting 99% of the stale sessions in my web.conf deluge loads up a lot quicker from a cold restart, is more responsive and also now allows me to save my password again in the web ui. Leaving it here in case anyone else has this issue! @binhex Should the stale sessions not be removed from the web.conf at some time?
-
@u.stu - Perfect! Thank you.
-
Hi, i was wondering if there was a place where i can see/track the current list of packages for nerdtools? I'm hanging back on 6.10 with the older 'nerdpack' until a few of the packages that i rely on are added to nerdtools. is there a list of packages on github or similar?
-
@JorgeB - Sorry it was just a bad example of a made up unraid share (I didnt mean to reference the /user share of unraid! My bad!) /work or similar would have been more fitting!
-
@JorgeB Sweet. Obviously i'll just need to remap my shares with the new explicit disk names right... If for example my share /user was explicitly mapped to disk 19 and disk 19 is now disk 10 i'll need to go into each and re-map the new disk number right?
-
@trurl @JorgeB I'm just about to remove 10 x 2tb disks from my array which will leave the disk numbering all over the place... in escense it'll go from this: To this: Is it possible for me to assign my 10 x 6tb remaining disks to disk slots 1 > 10 without losing any data (obviously i would reassign the new disk slot number in my shares if they were previously explicitly set.) And obviously i'd re-assign parity1 and parity2 back to the same slots that they were before. Would that work? Want it to like this after reassignment:
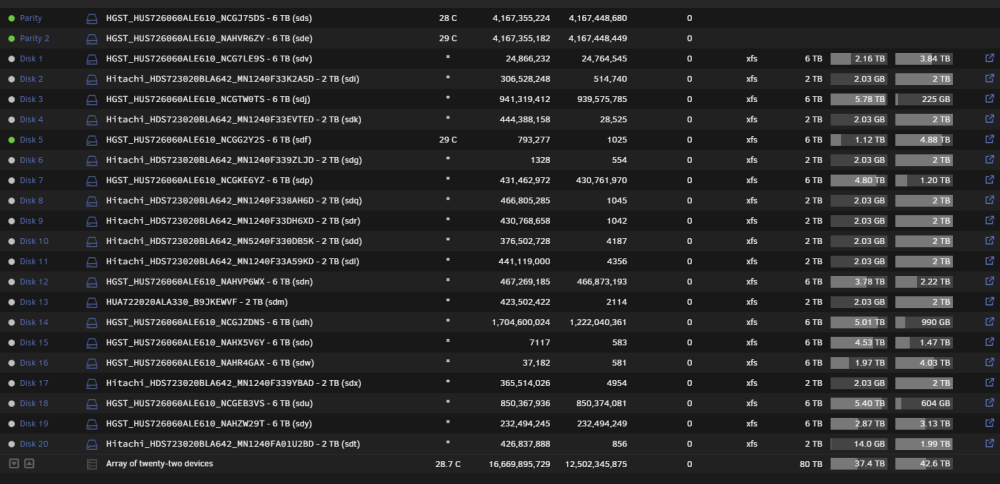
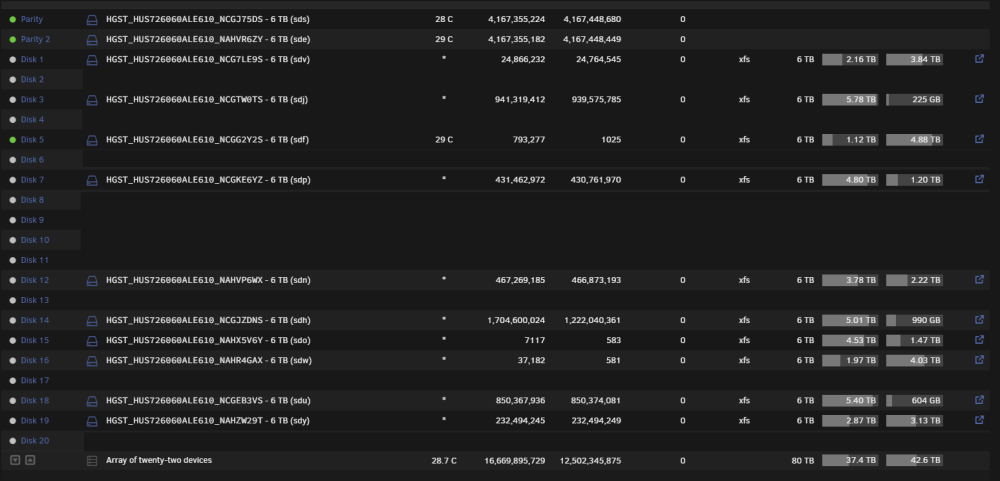
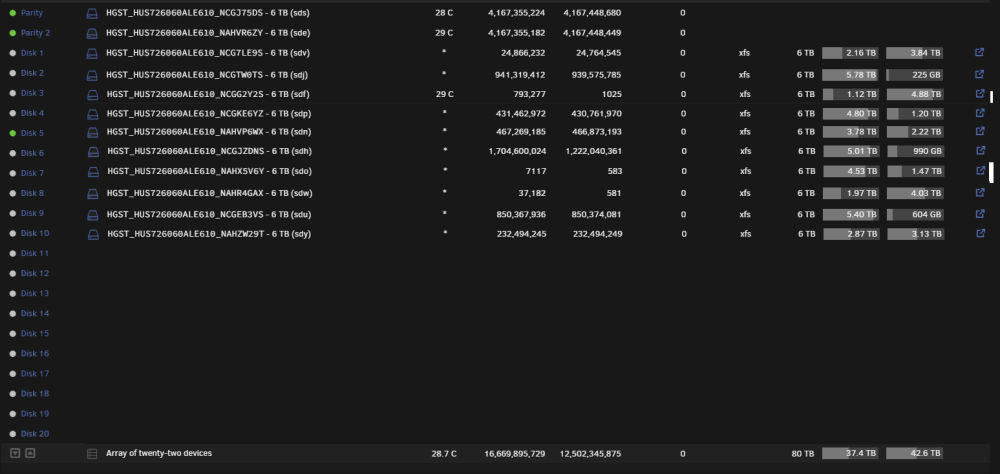
-
@trurlThanks.
-
I thought that might be it
-
Thanks for this - How can i disable parity temporarily?
-
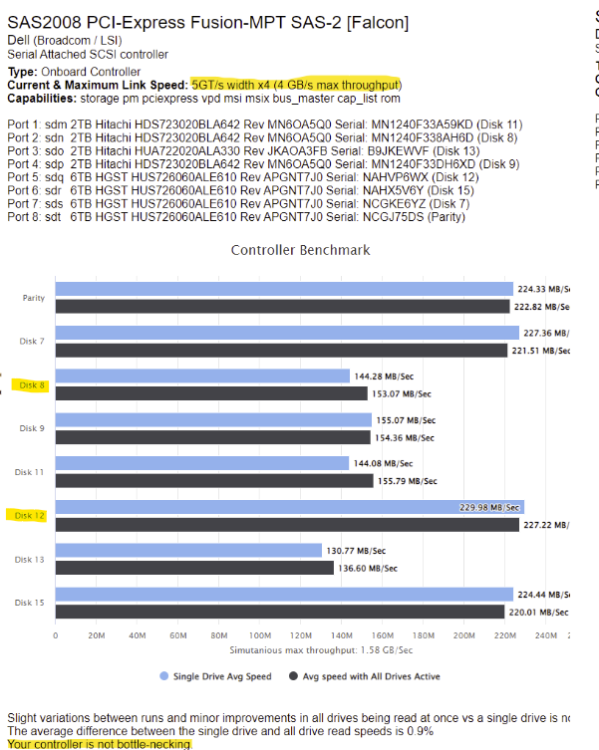
@trurl I'm following the "remove drives then rebuild parity" Method for the removal of multiple disks. As i can only run unbalance on a single disk at a time and have 10 to do, i was initially assuming my parity would be invalid until i've finished the last disk and rebuilt it. However i think after a re-read the only time my parity is at risk is at the end of the process when i run 'new config' to finish removing the drives and unraid runs a parity rebuild when the disks are finally removed. In regards to the disks I've tried Moving and Copying and both transfer at around 54mb/s with unbalance. Wondering whether it's because the 2TB disks are 99% full. The disks are very old (2010) but the SMART reports for all the 2tb disks all pass so no issue with the disks. I have the disk speed plugin and it shows no bottlenecks with the disk or controller config. I'm currently copying from Disk8 > Disk12 and as per the screenshot it seems there's lots more bandwidth between the 2 disks than unbalance is using. I know i'll lose some from running dual parity but it does seem a little slow regardless. Current Unbalance Copy Disk8 > Disk12 Disk Speed Plugin screenshot showing Disk8 and Disk 12 and the bandwidth available Any idea on how to speed it up?