AppleJon
Members
-
Joined
-
Last visited
Everything posted by AppleJon
-
Thank you i did even know that was a option. Not sure how that happenend but it fix it. again thank you!
-
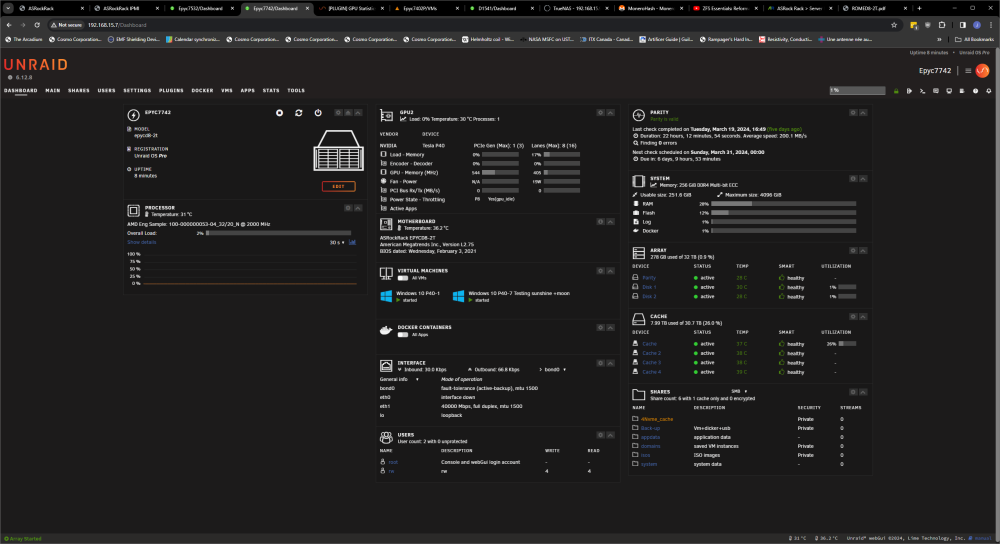
Now added a second GPU with the same name and only see GPU2?
-
Hi, Had two gpu inside and now back to newer single one taking more slot space but after changing the cheack box for the new one had only gpu2 empty in the dashboard after a reboot new gpu still selected in settings but nothing displaying in the dashboard now? Any ideas?
-
Thank you both Was actually looking for a reason I have one core a 100% on my EPYCD8-2T. My othe machine with RomeD8-2T deos not seem to have that issue. Both systhem had a card in slot 6. Moving my HBA off slot 6 of my EPYCD8-2T removed tha one peg core from 100%. Weird but it "fixed" the issue.
-
same for me any one have a quick explination for nob like us. Should we not be ruuning these commands from the unraid docker shell?
-
Thank you the update got it working
-
Thanks for this plugin. I was wondering is there a way to have the plugin display more then one GPU? Selecting more then one GPu does not seem to work for me?
-
For other finding this thread these link help me figure things out more proxmox but section on vGPU and UUID and MDEV creation is helpfull https://wvthoog.nl/proxmox-7-vgpu/ this for the bottom section on mediated device and getting them assigned to the vm https://ubuntu.com/server/docs/gpu-virtualization-with-qemu-kvm
-
Hi anyone gotten to the poin and can share how to setup the VM to actually use a vgpu device?
-
did you make any progress after this?
-
any info on these would be appreciated as if you want 4 or 8 instance of windows and then how to you pass it to the vm ## Modify the following variables to suit your environment WIN="2b6976dd-8620-49de-8d8d-ae9ba47a50db" #do you need one per vm or just one UBU="5fd6286d-06ac-4406-8b06-f26511c260d3" MDEVLIST="nvidia-65" #say you want mode 64 that is 4 instance with 2gig of ram on teslaP4 with 8gig also how to configure the vm onces de mdev are created edit: From waht i am readin you need to manually edit the vm in xml vieu after installing windows probably best. THe UUID is the UUID of the mdev you have created with the script. YOu need to create one mdev/UUI per VM and need to use the same mdev mode for all. SO in my case I have created moded the script to make 4 UUID that use in my VMs. I am using a tesla P4 and mode 64. But not using the unlock and not using the profile overide as the T4 is supported directly. <hostdev mode='subsystem' type='mdev' managed='yes' model='vfio-pci' display='off'> <source> <address uuid='2b6976dd-8620-49de-8d8d-ae9ba47a50d1'/> </source> <alias name='hostdev0'/> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </hostdev>
-
Can you share a bit more info on version used or other thing seem to be getting error
-
Sorry slow to post this had issue merging my accoutn for the forum. Was trying to get a new systhem online and was having alot of issue with it. On some boots could ping it when it got a address but gui was not reachable. Settig the setup to a manual address could always ping it but nopt get to GUI. Some setup would soemtimes not get a IP when in DHCP. Tryed manaul install and also the new flash creator all would not work. Tryed many diffrent network card intel, broadcom was thinking it was a driver thing. Also swapped many USB drive. But when shuting down the systhem i noticed a message saying ngix was not running. And remembered it would list all the core in the dashboard. So after some slep just desided to limit the chip to one core per CCD and deactivate SMT and that did the trick. Then reactivated all the cores in the ccds but left smt off. As soon as I put SMT back on i lose acces to the GUI. Attach are the two diagnotic log of the systhem with the issue while have SMT on and then ok with SMT off in bios. This is probably a edge case du to so many thread on the systhem? tower-diagnostics-20240217-1332.ziptower-diagnostics-20240217-1304.zip
-
Strange if your cache is Sata SSD you seem to be able to benchmark them but if nvme you cant (via the benchall option not via the individual drive option there even if sata ssd it will not let you)
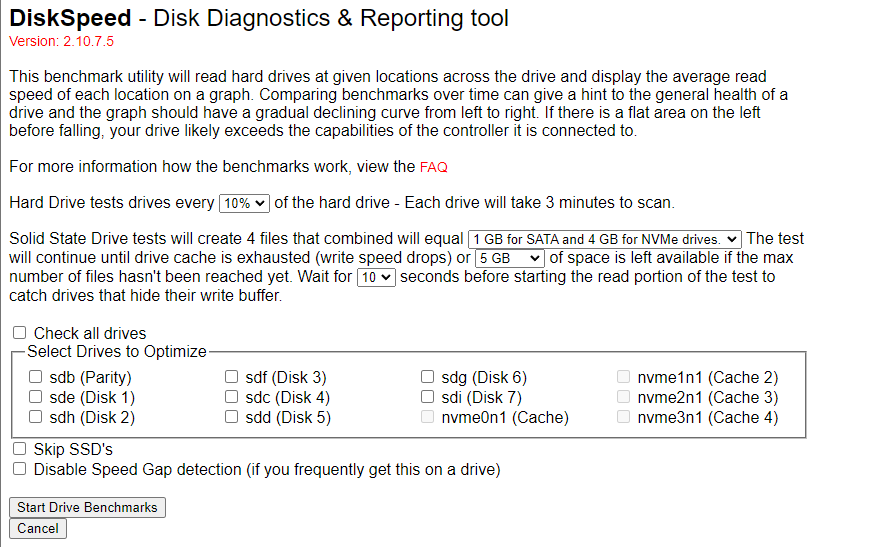
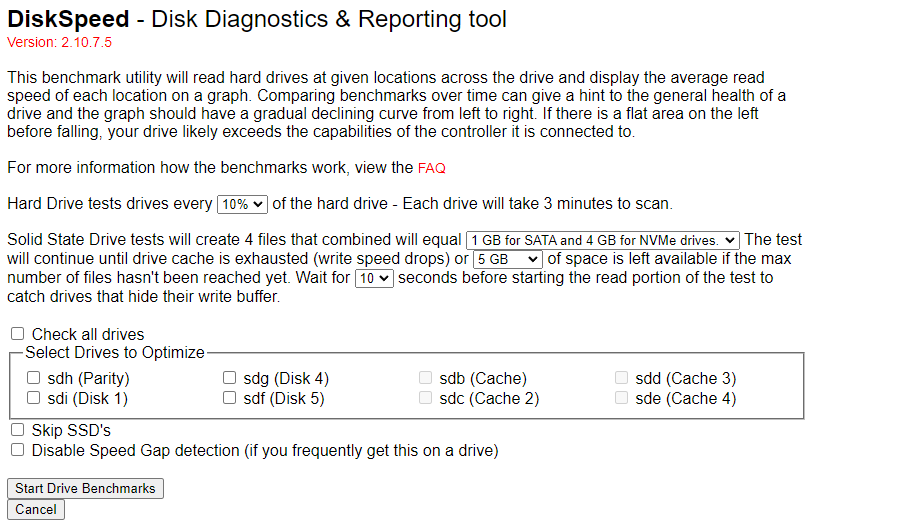

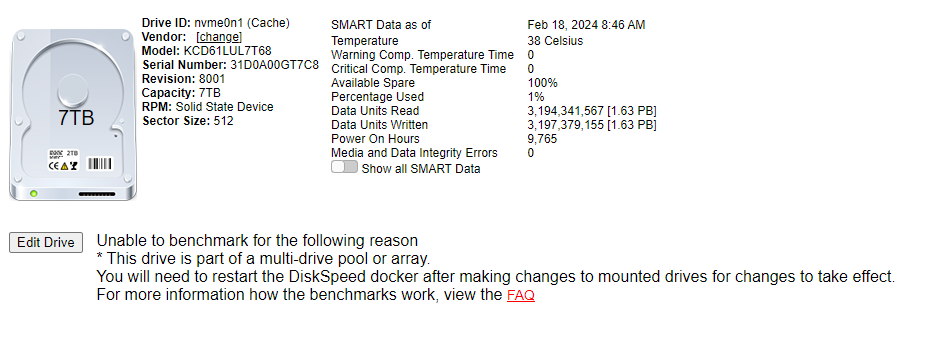
-
Ok was the machine type changed back i440fx from Q35 and nic and driver now work in the win10VM and a Server2012 VM
-
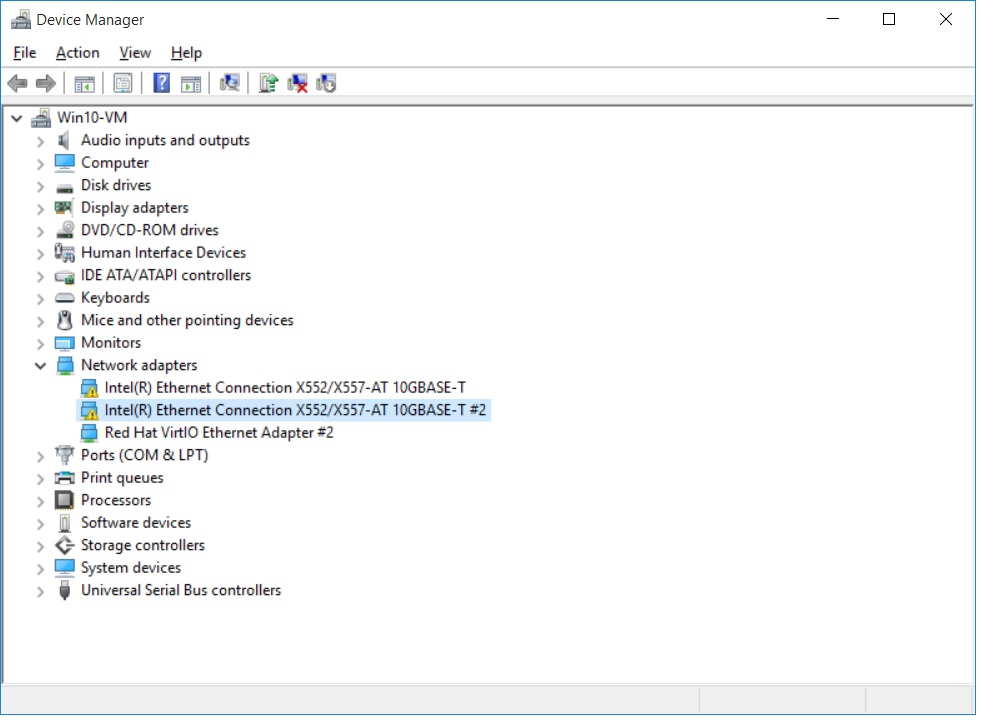
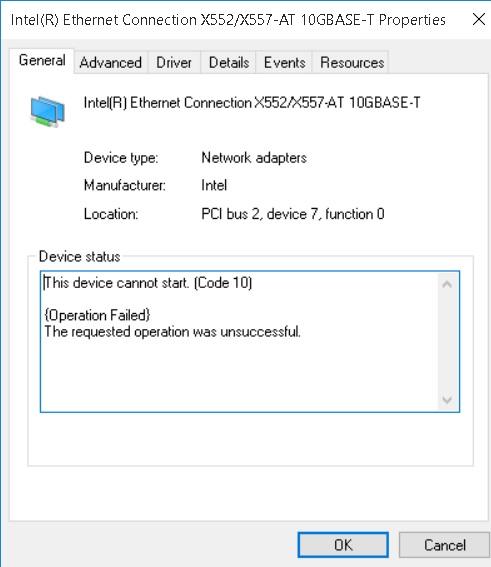
Hi Getting device cannot start in the VM windows 10 machine? Any ideas? 10GBe nic not supported by unraid so was thinking of passing them to a VM till driver get added to unraid. <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </source> </hostdev> 03:00.0 Ethernet controller: Intel Corporation Ethernet Connection X552/X557-AT 10GBASE-T 03:00.1 Ethernet controller: Intel Corporation Ethernet Connection X552/X557-AT 10GBASE-T 04:00.0 Serial Attached SCSI controller: LSI Logic / Symbios Logic SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 03) 05:00.0 Ethernet controller: Intel Corporation I350 Gigabit Network Connection (rev 01) 05:00.1 Ethernet controller: Intel Corporation I350 Gigabit Network Connection (rev 01)