




gzibell
Members
-
Joined
-
Last visited
Everything posted by gzibell
-
Just came to say Thank You! This seems very fair and reasonable to me. Kudos to the team that put this together.
-
Any ideas where this error would be coming from? Temporary directory /data/tmp is not present or writable? Showing up in my logs every 10 seconds or so. I have been running Nextcloud for years and no changes. /data is mapped to a folder called Nextcloud for me. Went into my nextcloud folder and created a folder called /tmp and the error stopped. Remove the folder and it starts again. Is having a tmp folder normal/required in the data directory for nextcloud? And if so, why did it not just make one?
-
Just tested, seeing the same.
-
Had a faulty nvme drive. Replaced over the weekend. Maybe that was contributing? Time will tell
-
It's so random I don't know what would tell me anything. The last one was 2/21 and the time before was 2/15. So anywhere between 6 and 12 days from one occourance to the next. Not on the same day of the week or time either so it doesn't seem to be triggered by any scheduled event.
-
Attached and just for good measure this is what I get in the syslog. Nothing after a 2am email sent until 9:55 when I had to hard shutdown and reboot. Mar 4 02:00:09 unGEO crond[1545]: exit status 1 from user root /usr/local/sbin/mover &> /dev/null Mar 4 05:00:01 unGEO kernel: BTRFS info (device nvme1n1p1): scrub: started on devid 1 Mar 4 05:00:01 unGEO kernel: BTRFS info (device nvme1n1p1): scrub: started on devid 2 Mar 4 05:00:49 unGEO kernel: BTRFS info (device nvme1n1p1): scrub: finished on devid 2 with status: 0 Mar 4 05:00:51 unGEO kernel: BTRFS info (device nvme1n1p1): scrub: finished on devid 1 with status: 0 Mar 5 00:20:02 unGEO sSMTP[30925]: Creating SSL connection to host Mar 5 00:20:02 unGEO sSMTP[30925]: SSL connection using TLS_AES_256_GCM_SHA384 Mar 5 00:20:04 unGEO sSMTP[30925]: Sent mail for [email protected] Mar 5 02:02:54 unGEO crond[1545]: exit status 1 from user root /usr/local/sbin/mover &> /dev/null Mar 5 09:55:34 unGEO root: Delaying execution of fix common problems scan for 10 minutes Mar 5 09:55:34 unGEO unassigned.devices: Mounting 'Auto Mount' Devices... Mar 5 09:55:34 unGEO unassigned.devices: Mounting partition 'sdh1' at mountpoint '/mnt/disks/WDBlueVMDrive'... Mar 5 09:55:34 unGEO unassigned.devices: Mount cmd: /sbin/mount -t 'xfs' -o rw,noatime,nodiratime,discard '/dev/sdh1' '/mnt/disks/WDBlueVMDrive' Mar 5 09:55:34 unGEO kernel: XFS (sdh1): Mounting V5 Filesystem Mar 5 09:55:34 unGEO kernel: XFS (sdh1): Starting recovery (logdev: internal) Mar 5 09:55:34 unGEO kernel: XFS (sdh1): Ending recovery (logdev: internal) Mar 5 09:55:34 unGEO unassigned.devices: Successfully mounted 'sdh1' on '/mnt/disks/WDBlueVMDrive'. Mar 5 09:55:34 unGEO unassigned.devices: Unassigned Devices are not set to be shared with SMB. Mar 5 09:55:34 unGEO unassigned.devices: Unassigned Devices are not set to be shared with NFS. Mar 5 09:55:34 unGEO emhttpd: Starting services... Mar 5 09:55:34 unGEO emhttpd: shcmd (63): /etc/rc.d/rc.samba restart Mar 5 09:55:34 unGEO wsdd2[4872]: 'Terminated' signal received. Mar 5 09:55:34 unGEO winbindd[4877]: [2023/03/05 09:55:34.159001, 0] ../../source3/winbindd/winbindd_dual.c ungeo-diagnostics-20230306-0838.zip
-
Upgraded my server a few months back and have had this happen maybe 5 times. The server becomes completely unresponsive and this is what the display output shows. I tired setting up the syslog server to get details there but it didn't seem to contain any relevant info. My understanding is diagnostics are reset on reboot so not sure if they'll help but I can grab them if needed. It looked to be something network related so I did switch from the dragon lan to the Intel lan on the MB but just had the issue so not sure where to go from here. Any help would be greatly appreciated!
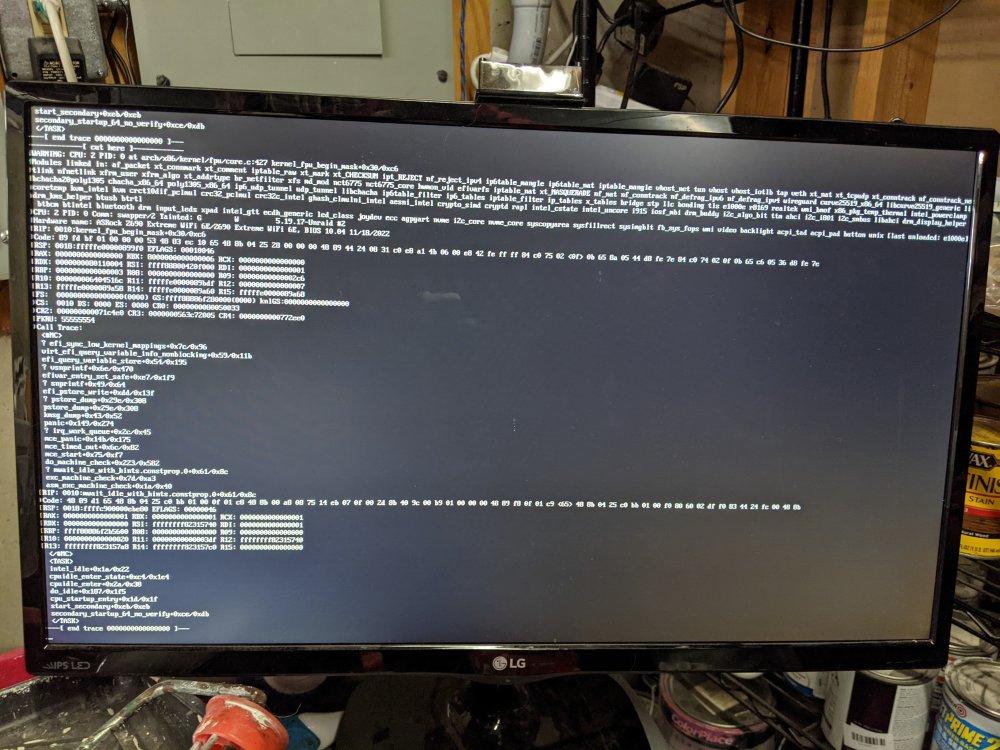
-
Was having the same issue and the same worked for me. Haven't experienced this before. Wonder if we'll have to do this on expiration every time or is there is a programmatic resolution.
-
If you want to peak sure, here they are! ungeo-diagnostics-20221222-1433.zip
-
No luck in the chipset slot. Same behavior. Swapped in my 1060 got it to work once randomly, then back to the same. Removed driver, checked plugins folder on flash, rebooted, re-installed no change, tried a bunch of plex versions no luck. Same PCIe drop seen in SMI. I think I did solve it though....12700 with rush processing and next day delivery😁...QuickSync here I come.
-
That would make sense as my primary is an AMD rig and my backup is an Intel rig. Works on the Intel, not on the AMD. Going to give it a shot in the slot controlled by the chipset and if that fails, will swap the 1660 with my 1060 and see if that does the trick. Thanks for everything you do!
-
BIOS is up-to-date Forced to Gen3 - No Change Also removed one video card - No Change Disabled CSM - Enabled Above 4G Decoding and Resizable BAR - No Change (Had to disable to change those 2 settings) Re-Enabled CMS so I could switch back to Legacy - Had switched to UEIF to see if that resolved - No Change Also tested with current plex version, and we back a few releases to see if there was an issue with plex but no change there either. Have reviewed plex logs and don't see anything to interesting other than the transcoding process just stops. Generaly no, I don't use plex web but used it for testing purposes. This does not seem to be an issue in native plex clients. Do have some users that use plex web and was creating issues for them so had to disable HW transcoding in the meantime. Is this just a compatibility issue where my MB isn't playing nice? Is it time to just bit the bullet and go for a 12th gen with quicksync?
-
What would cause GPU Link/PCIe Generation to change? Been pulling my hair out trying to figure out why transcoding won't work sometimes with my 1660 super. In testing, I pulled the card, put it in my backup server, installed nvidia, gpu stats, plex set it all up the same, same video file and it works flawlessly. In my primary server if I force the quality via plex web to 720 2MB before starting the video it'll hardware transcode and play just fine. If I set the video quality to max and user reccomended for home streaming, then start the video it'll direct play, but then if I pick 720 2MB, I briefly see GPU activity, then the process drops, and nothing ever plays. When I run nvidia-smi -q during this, I see the following in PCIe Generation. Prior to attempting to play the video it was 33334. And if I force quality in plex web back to 720 2MB and play the video again, it'll play just fine and then I will see the 33334 again. I am assuming at this point it has something to do with a BIOS setting but I am not ever sure what to look for at this point. I have 2 GPU's in the server so in Dual mode both are 4.0 x8 slots. I do have another slot that is off the X570 Chipset which is 4.0 x4 and moving the GPU to that slot is about the only idea I have left at this point. GPU Link Info PCIe Generation Max : 3 Current : 1 Device Current : 1 Device Max : 3 Host Max : 4 ungeo-diagnostics-20221221-1043.zip
-
Still trying to figure this out no more VAAPI errors but still not working. This morning I moved the 1660 to my backup server and setup plex with the same video file, and put my 960 back in my main server. Both play the video fine, setup to 720p 2MB to test transcoding they both keep chugging along transcoding normally. Weird, ok lets delete my plex docker and start fresh not from my existing template to ensure everything is the same. Now swap the 1660 back to my main server and start playing the file all is fine. Set to 720p 2MB and nothing just a black screen and get a "Transcode runner appears to have died." in the logs. All testing in plex web app. Why would this work with a different card(960 vs 1660) on the same server, but the same card (1660) performs this normally when installed in another server. AND if I open the same video file on my android phone and set to 720 2MB it plays fine.
-
Hey All, So just swapped a 1660 super into my server for plex transcoding. AMD system so no quicksync. When attempting to transcode a video via plex web the video will not start and I am seeing VAAPI errors in the logs. When I open the same video on my andriod and transcode it works just fine. The research I have done seems to indicate that VAAPI is related to quicksync and not nvdidia gpu. Any suggestions? I cleared codec folder. Have NVIDIA_VISIBLE_DEVICES, NVIDIA_DRIVER_CAPABILITIES, and --runtime=nvidia on the container with the appropriate values, plexpass version. Didn't have any issues transcoding on the 960 I had in the system prior. Seems to be new with the 1660. . Dec 15, 2022 05:51:33.794 [0x15083df5db38] ERROR - [Req#d79/Transcode] [FFMPEG] - Failed to initialise VAAPI connection: -1 (unknown libva error). Dec 15, 2022 05:51:34.314 [0x15083df5db38] ERROR - [Req#d79/Transcode] [FFMPEG] - Failed to initialise VAAPI connection: -1 (unknown libva error). Dec 15, 2022 05:51:34.828 [0x15083df5db38] ERROR - [Req#d79/Transcode] [FFMPEG] - Failed to initialise VAAPI connection: -1 (unknown libva error). Dec 15, 2022 05:51:35.366 [0x15083df5db38] ERROR - [Req#d79/Transcode] [FFMPEG] - Failed to initialise VAAPI connection: -1 (unknown libva error). Dec 15, 2022 05:51:35.823 [0x15083df5db38] ERROR - [Req#d79/Transcode] [FFMPEG] - Failed to initialise VAAPI connection: -1 (unknown libva error). Dec 15, 2022 05:51:36.262 [0x15083df5db38] ERROR - [Req#d79/Transcode] [FFMPEG] - Failed to initialise VAAPI connection: -1 (unknown libva error). Dec 15, 2022 05:51:36.495 [0x15083b24cb38] WARN - [Req#dcf/Transcode/xvyh2y66y68l0zw3zs4bgpjv] Transcode runner appears to have died. Dec 15, 2022 05:51:36.499 [0x15083d689b38] WARN - [Req#dcc/Transcode/xvyh2y66y68l0zw3zs4bgpjv] Transcode runner appears to have died.
-
Oh it totally works. The learn more says, "It is highly recommended to restrict WOPI requests to the IP addresses of the Collabora servers that are expected to request files from the Nextcloud installation. This can be done by setting the Allow list for WOPI requests option from the Office admin settings." So I think it means someone could use WOPI to grab files from my nextcloud instance without permission and I need to only allow ip's that should be allowed to access wopi. I tried local IP's and that didn't work. Assuming it would have to be my public or cloudflare proxied ip but haven't tried those yet
-
Running Collabora-CODE saw this. Is this something I should worry about? Both services are running via cloudflare and NPM. "You have not configured the allow-list for WOPI requests. Without this setting users may download restricted files via WOPI requests to the Nextcloud server."
-
Well this is about the strangest thing I have came across. Not sure if there is actually a question in here but figured I would throw it out there just in case someone has seen something like it. Been trying to track down something funky that has been happening. Grab 6 linux distros and add them to deluge. Runs for 5-10 mins and I completely lose connectivity(my whole house). Odd, ssh into my USG, can't ping google 8.8.8.8 nothing. K, lets disconnect the WAN cable and reconnect. Boom, internet back up house wide....ok lets start the download again. Same thing over and over and over again. WTF? So then the smart guy in me says ok download utorrent to your desktop and do the same thing. A short while later I have 6 shiny new distros in my downloads folder. ok... Another idea. Lets set VPN_ENABLED to no. Fire it back up, 6 shiny new distros on my server with no issues. This seems like a stretch but could traffic from deluge be breaking my USG somehow or could my ISP be doing something funky?
-
waiting for connection - I did clear my cache and it started doing the sync file information so that is a good sign I think. Will keep an eye on it once it finishes
-
Anyone seeing "Waiting for Connection"? I have gotten a couple alerts that server hasn't backed up in X days and I log in to check and it just says waiting for connection. It will sometimes flash for a second over to preparing...or something but it's so quick I can't catch it all. Says the last backup was 5.2 hours ago though so maybe working? I flipped it from bridge to host just for kicks and there was no change. Odd thing is flipping it back to bridge I am no longer to access the webui but if I leave it on host I can. Still shows the waiting for connection. Not sure if there is any issue with it being on host.
-
Hey, Just wanted to throw this out there in case anyone else runs into it. Have 2 servers updated one to 6.9.0 everything seemed fine so I updated my primary server as well. Then noticed I could not access shares either via SMB or dolphin docker. Also when attempting to reboot/shutdown it just failed and never actually went offline. Did a bit of research and figured I would look at my go file and see if anything seemed off. Only stuff in the go file was for server to server backups from the unraid blog. I removed all of that just to see, and had to do an hold the power button shutdown but after reboot everything came back up and seems fine now. Since it worked on my backup server I did the same on primary and same result. Back up and running. I don't know if anything in the go file had anything to do with it or not, or if just a hard shutdown/reboot would have resolved as well. Any logs or files that I can share in case this happens to anyone else?
-
Edit - Looks to be something with using the proxy in Sonarr/Radarr. It was checked to bypass proxy for local addresses but if I set everything back to bridge and disabled the proxy everything worked normally. Enable the proxy lose connection to sab. Added server ip to ignored addresses in sonarr/radarr all back up and running Anyone having issues with Sab/Radarr/Sonarr today? Updated all dockers this AM and now Sonarr and Radarr are both unable to communicate with Sab. Has been working fine for years and know it was working yesterday so assuming it was something in the update this am. I can navigate webui's of all three like normal. Now I noticed on Status and interface options page it lists the ip as 172.17.0.8 which is not in my network range. If I throw that into Radarr/Sonarr they work but that isn't right since Sab lives at 192.168.1.100. If I flip network type to host the status and interface options shows the 1.100 as it should but then radarr/sonarr can't communicate. If I then flip sonarr to host as well instead of bridge those 2 communicate but same things is not working for Radarr I wonder what changed or why host works vs bridge.
-
+1 on the Life Saver!!! Appreciate everything you do. Was pulling my hair out trying to figure out what happened and why it was no longer working. Rolling back got me back up and running.
-
all good for me as well!
-
Thanks for everything you do!!! PIA/Wiregaurd was not working for me after updating today as well. Just flipped back to openvpn and that worked so I'll watch for the fix!

