




Maticks
Members
-
Joined
-
Last visited
Everything posted by Maticks
-
Thank you for adding that in Squid, i just tracked down my problems to Mover yesterday. Sent over a Beer your way.
-
not arguing I just assumed you might run plex like some other people
-
Don't use plex or turn off Maintenance ?
-
Another option to add to the plugin which will make it even better. We have the check every hour on the Cronjob if not at the threshold or over that percent don't run the Mover. How about an exception, if all Data Disks are spun up already during the cronjob check you might as well run the Mover. Since 90% of people running this plugin are to not move unless at X Threshold to stop disks from being spun up, if they are already all spinning why wait to the threshold and force all drives to spin up then. Just an idea for offloading the data to the parity array when it makes sense too.
-
I get what you are saying here, you could fill the cache drive to 100% while mover is running. I have experienced this and if you have unraid setup incorrectly dockers will crash which is probably what you are getting at here. Under Shares make sure Cache Drive is set to Prefer on any of the Shares you have set to Only. If the Cache drive fills too 100% any files that need to be changed will be written to the array, when mover runs next time it will have free space and move those files back to the Cache Drive. Its the same as wanting those files on your Cache Drive only but in the event of 100% full Cache the system has a place to keep operating. You have to also Include some drives from your array within the Share where you want this overflow to take place. The only thing that is going to happen here is any accesses to that file that is on the array instead of the cache drive will read at array speed. Once Mover runs again that file will now be at Cache Drive at Cache speed. Completely opposite in my opinion the Unraid setup between Cache and Array is amazing. If you use the Prefer option on your Share you will run into a bad day, once the Cache Drive nears 100% you will get I/O errors and at somepoint docker crashes or system lockup. If you are running into some weird problems like Disk Full when the Cache Drive is only at 70% or 80%, that is a BTRFS bug you can run a rebalance on the Cache Drive to clear the space. Look at your Cache Drive Used Space then click on the Cache drive on the left under balance you should see "Data, single: total=83.01GiB, used=80.65GiB" See if the total is around what your used space is in Unraid. You can manually press Balance and it will clean it up for you. I have a cron job that runs "btrfs balance start -dusage=75 /mnt/cache" every week just to clean it up. Might be useful actually if this plugin checked the Cache Folder in DF and compared it with the BTRFS Filesystem Database if they don't match run rebalance. Maybe another plugin should keep an eye on that, anyway i find the Cron job enough to do the job.
-
not sure if i missed something here. But checking syslog there is no new data there at all saying that it didnt run for some reason. But i've tried a few setting changes and each hour mover doesn't start. Any pointers of something i might have missed or do i need to reboot after installing the plugin?
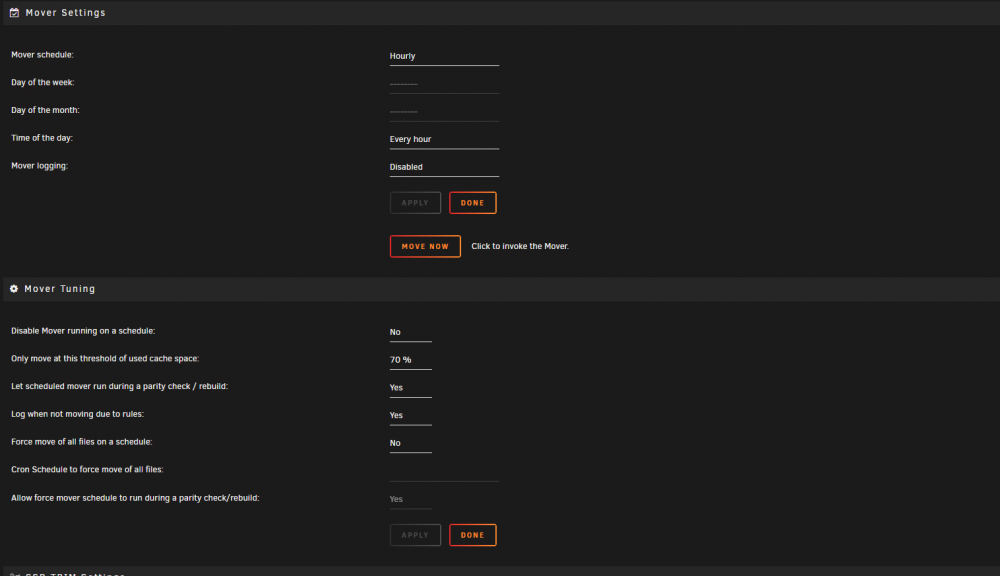

-
looks to be fixed after a reboot and the plugin changed.
-
With the plugin disabled the drives spin down as per below, but without the cachedir plugin a Plex scan will spin up all the disks that are part of that share. The plugin did stop that from happening by holding the directories in memory during the scan. Though disks are spun down without the cachedir its not an ideal situation. In all fairness when i did my plugin upgrade i never rebooted, so i will go do that now. But my settings for cachedir are below as well, do they look right.
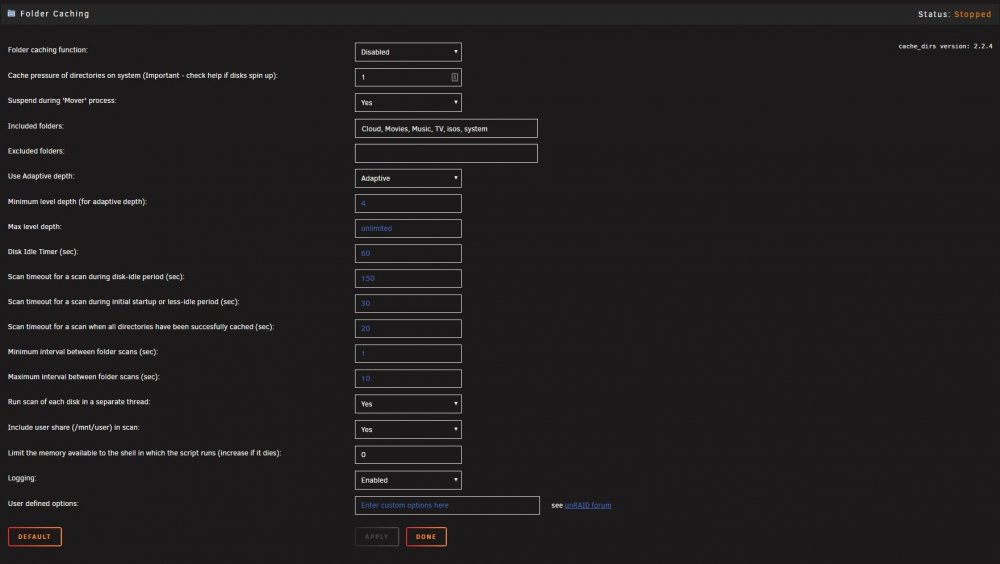
-
i upgraded the plugin and turned on user share, didn't make any difference for me still has activity. There is less activity when the plugin is off. The plugin use to work really well maybe something in 6.x.x has upset it.
-
i've added -u to set user shares. Nov 8 00:45:44 Vault cache_dirs: Starting cache_dirs: Nov 8 00:45:44 Vault cache_dirs: Arguments=-i Cloud -i Movies -i Music -i TV -i isos -i system -p 0 -U 0 -l on -u -d 20 Nov 8 00:45:44 Vault cache_dirs: Cache Pressure=0 Nov 8 00:45:44 Vault cache_dirs: Max Scan Secs=10, Min Scan Secs=1 (min scan seconds ignored, always sleep max) Nov 8 00:45:44 Vault cache_dirs: Scan Type=adaptive Nov 8 00:45:44 Vault cache_dirs: Max Scan Depth=none Nov 8 00:45:44 Vault cache_dirs: Use Command='find -noleaf' Nov 8 00:45:44 Vault cache_dirs: Version=2.2.0j Nov 8 00:45:44 Vault cache_dirs: ---------- Caching Directories --------------- Nov 8 00:45:44 Vault cache_dirs: Cloud Nov 8 00:45:44 Vault cache_dirs: Movies Nov 8 00:45:44 Vault cache_dirs: Music Nov 8 00:45:44 Vault cache_dirs: TV Nov 8 00:45:44 Vault cache_dirs: isos Nov 8 00:45:44 Vault cache_dirs: system Nov 8 00:45:44 Vault cache_dirs: ---------------------------------------------- Nov 8 00:45:45 Vault cache_dirs: cache_dirs process ID 19516 started
-
I am running cache_dirs version: 2.2.0j which is saying its the latest version.
-
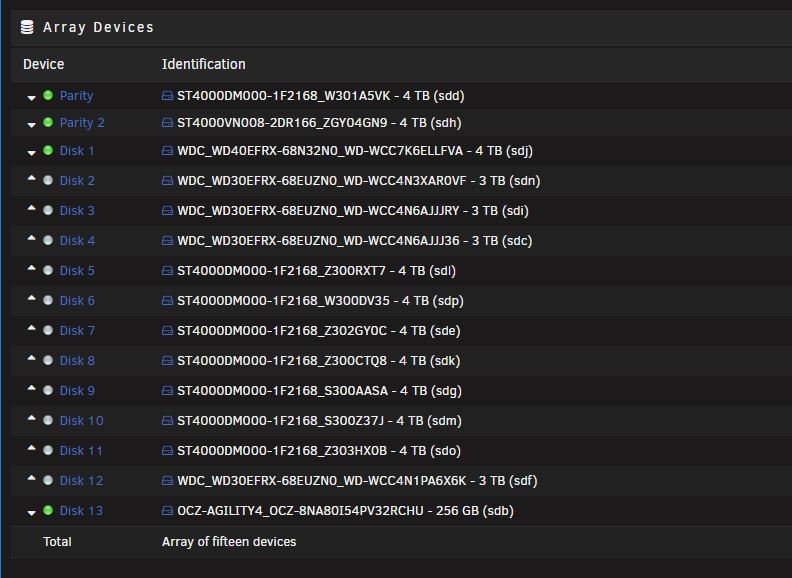
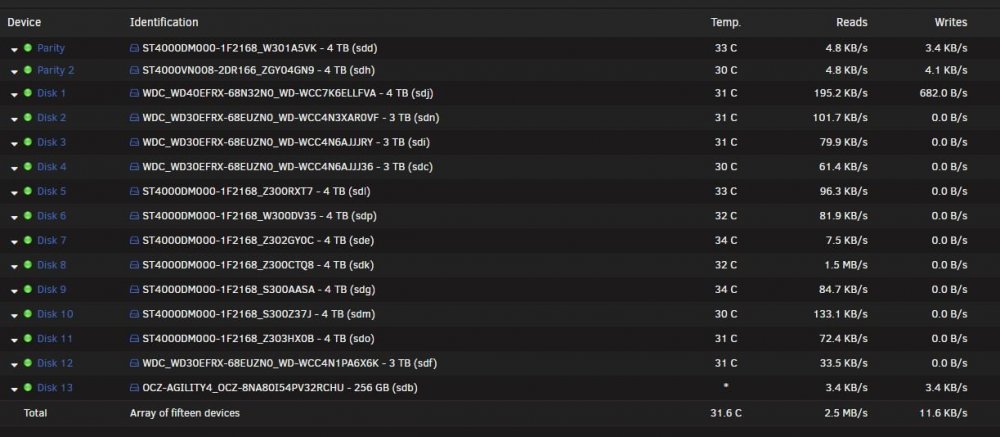
Ran into this thread after noticing my disks not spinning down for quite some time. When i turned off Cache Dir it finally spun disks down for the first time in months. I have my depth set to 20 i only need 17 to catch all my files but i set this for headroom. Adaptive makes no difference however. 2018.11.07 12:32:40 Executed find in (1s) 01.70s, wavg=03.99s Idle____________ depth 20 slept 10s Disks idle before/after 1541554359s/1541554361s suc/fail cnt=8/9/0 mode=4 scan_tmo=150s maxCur=20 maxWeek=20 isMaxDepthComputed=1 CPU=13%, filecount[20]=73711 2018.11.07 12:32:51 Executed find in (1s) 01.75s, wavg=03.89s Idle____________ depth 20 slept 10s Disks idle before/after 1541554371s/1541554373s suc/fail cnt=9/10/0 mode=4 scan_tmo=150s maxCur=20 maxWeek=20 isMaxDepthComputed=1 CPU=15%, filecount[20]=73711 2018.11.07 12:33:03 Executed find in (5s) 05.43s, wavg=04.14s Idle____________ depth 20 slept 10s Disks idle before/after 1541554383s/1541554388s suc/fail cnt=10/11/0 mode=4 scan_tmo=150s maxCur=20 maxWeek=20 isMaxDepthComputed=1 CPU=17%, filecount[20]=73711 2018.11.07 12:33:19 Executed find in (1s) 01.09s, wavg=03.95s Idle____________ depth 20 slept 10s Disks idle before/after 1541554399s/1541554400s suc/fail cnt=11/12/0 mode=4 scan_tmo=150s maxCur=20 maxWeek=20 isMaxDepthComputed=1 CPU=14%, filecount[20]=73711 2018.11.07 12:33:30 Executed find in (0s) 00.09s, wavg=03.67s Idle____________ depth 20 slept 10s Disks idle before/after 1541554410s/1541554410s suc/fail cnt=12/13/0 mode=4 scan_tmo=150s maxCur=20 maxWeek=20 isMaxDepthComputed=1 CPU=15%, filecount[20]=73711 2018.11.07 12:33:40 Executed find in (1s) 01.41s, wavg=03.51s Idle____________ depth 20 slept 10s Disks idle before/after 1541554420s/1541554421s suc/fail cnt=13/14/0 mode=4 scan_tmo=150s maxCur=20 maxWeek=20 isMaxDepthComputed=1 CPU=15%, filecount[20]=73711 2018.11.07 12:33:51 Executed find in (0s) 00.71s, wavg=03.27s Idle____________ depth 20 slept 10s Disks idle before/after 1541554431s/1541554432s suc/fail cnt=14/15/0 mode=4 scan_tmo=150s maxCur=20 maxWeek=20 isMaxDepthComputed=1 CPU=15%, filecount[20]=73711 2018.11.07 12:34:02 Executed find in (6s) 06.39s, wavg=03.58s Idle____________ depth 20 slept 10s Disks idle before/after 1541554442s/1541554448s suc/fail cnt=15/16/0 mode=4 scan_tmo=150s maxCur=20 maxWeek=20 isMaxDepthComputed=1 CPU=21%, filecount[20]=73711 2018.11.07 12:34:19 Executed find in (0s) 00.09s, wavg=03.26s Idle____________ depth 20 slept 10s Disks idle before/after 1541554459s/1541554459s suc/fail cnt=16/17/0 mode=4 scan_tmo=150s maxCur=20 maxWeek=20 isMaxDepthComputed=1 CPU=17%, filecount[20]=73711 2018.11.07 12:34:29 Executed find in (0s) 00.09s, wavg=02.94s Idle____________ depth 20 slept 10s Disks idle before/after 1541554469s/1541554469s suc/fail cnt=17/18/0 mode=4 scan_tmo=150s maxCur=20 maxWeek=20 isMaxDepthComputed=1 CPU=14%, filecount[20]=73711 2018.11.07 12:34:39 Executed find in (0s) 00.09s, wavg=02.62s Idle____________ depth 20 slept 10s Disks idle before/after 1541554479s/1541554479s suc/fail cnt=18/19/0 mode=4 scan_tmo=150s maxCur=20 maxWeek=20 isMaxDepthComputed=1 CPU=15%, filecount[20]=73711 I've tried setting my cache pressure to 0 and memory limit to 0 but makes no difference for me. attached are my settings. As per my attachments, i basically see every scan in the cache_dir.log file increments the disks all spike with read accesses. Even though the content on all the drives is unchanged. Even went i shutdown VM and Docker completely and unplug it from the network i still see these disk reads that coincidence with cache_dir.log find. This seems to be preventing the disks spinning down, which seem to be the point of this plugin Maybe someone can point me in the right direction here. Not all my shares are across all my disks either, but my included folders in Cache Dir will include all the disks except my Disk 13.
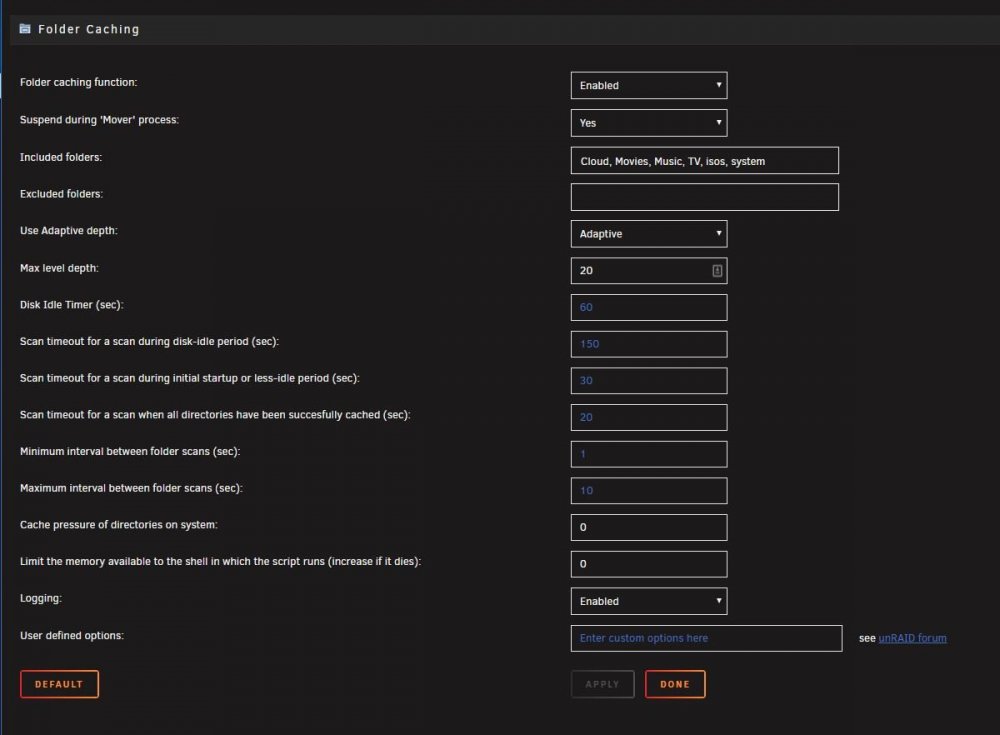
-
I upgraded to 6.6.0 when it came out and within 30 minutes my drives started throwing read errors. I rolled back and discovered the issues were still there, but i did have a faulty power supply it seems. I've replaced my Power Supply and everything is stable again. I tried upgrading to 6.6.1 again and within 30 minutes read errors. I have rolled back to 6.5.3 till its fixed but something seems to have changed with the mpt2sas driver. Looking for LSI and 6.6.0 i've found a few others running into the same issue. I am back on 6.5.3, happy to test anything out if you want me to add any custom commands. I'll attach my diag file if that helps. A friend of mine who runs Unraid upgraded and has the same 9211-8i card i have for his array and it did the same thing. He has a 6700 and i have a 4770 CPU both are Intel. Sep 29 01:50:39 Vault kernel: mpt2sas_cm0: SAS host is non-operational !!!! ### [PREVIOUS LINE REPEATED 5 TIMES] ### Sep 29 01:50:44 Vault kernel: mpt2sas_cm0: _base_fault_reset_work: Running mpt3sas_dead_ioc thread success !!!! vault-diagnostics-20180929-0959.zip
-
Thank you guys for making this plugin. Had two corrupted files on a hard drive that threw some read errors a while back. Discovered the two corrupted files and restored from another machine, works perfectly.
-
Firstly great work on the docker, the preconfigured proxy files make NGINX so easy to setup. I did a search but nothing came up so i thought i’d Ask the question, is there an easy way to enable Modsecurity. There are some public dockers intergrating it with nginx and it seems to add an extra layer of protection given it stops some attacks for the end applications being proxied. ModSecurity protects against attacks by looking for: SQL Injection Insuring the content type matches the body data. Protection against malformed POST requests. HTTP Protocol Protection Real-time Blacklist Lookups HTTP Denial of Service Protections Generic Web Attack Protection Error Detection and Hiding Is there an easy way to load in the module myself, maybe someone here has done it before ?
-
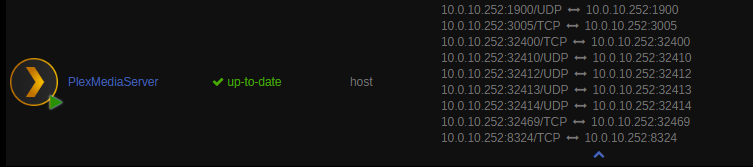
Anyone know what this weird problem is when i change my Plex from Host to Custom it doesn't maintain the same ports it wipes out the config. In the port details it seems to change to a 172 range and has ???? as the port.

-
im running Nextcloud https://hub.docker.com/r/linuxserver/nextcloud/ It's been updated often from pulling down in unraid without any issues. I noticed in the webui today that the version is 12.0.4 and the latest is 13.0.4. Do i need to do something manual to update this other than pull down the docker ?
-
is there a way to exclude a folder in the watch folder. I am converting my Plex DVR recordings from TS to MP4 every night by starting the Handbrake Docker at midnight and shutting it down at 5AM. The issue is all the videos i want to convert are in the folder but so is the plex .grab folder which is where the recordings are as the system runs. Is there a way to blacklist a folder from the watching. Thanks
-
When transcoding to the hard drive yeah its going to take a bit extra for the movie to start, you can use your SSD Cache drive to get a bit faster. But Memory would be best if you can find out how to fix that issue.
-
I think there is a limit on how much memory the docker is allowed to use. But it seems a bit odd i have 4-5 streams on my Plex docker using memory without much issue at all and i only have 14GB in my Unraid server. But another person had the same issue with the /transcode folder as you did. I think he was on a Ryzen system and i am on an Intel one that seem to be the only difference.
-
maybe try changing the /transcode folder from the ram to a hard drive again. i remember one guy was having a weird problem had heaps of memory free and yet had issues with the /transcode folder it went away when he changed it back to a hard drive.
-
I keep getting Torrent file contents are empty when I download anything from torrentleech. Since Sunday anyone know how to fix that?
-
ok that was easy.. in case anyone else needs to copy their current view states over it takes seconds. https://support.plex.tv/articles/201154527-move-viewstate-ratings-from-one-install-to-another/
-
How did you copy over your watched status ? Looks like the traktv plug also is broken these days.
-
Ok i just installed the plex docker, i still linked transcode to /tmp but i can convert and stream eac3 audio files finally... so yes something in the linuxserver.io container is broken that isn’t broken in the plex docker.







