





sreknob
Members
-
Joined
-
Last visited
Everything posted by sreknob
-
Looks more likely a general networking connectivity error. If you login and open up the console, can you resolve external hostnames from the machine? ping google.com -c 3 If no response and this times out, it either can't access your DNS server or there is some other networking problem. First try rebooting and if still the same symptoms, I'd check your networking configuration for invalid name servers. If you don't see anything there unusual, you can reset your networking stack by deleting the network.cfg file from /flash/config/network.cfg and rebooting.
-
Is it populated in the server details section and just missing from the dashboard? Mine is missing from both areas. Interestingly, it's the first server (and newest) in the list (of 6 servers), similarly to yours being first in your list. I issued unraid-api restart commands on several devices with no change and restarted the affected one without resolution. As a side note, flash backup wasn't enabled on this device and I tried turning it on, but the backup failed. MOST interesting it that the displayed values are all wrong. The plugin version on all my machines is "2025.03.27.0004" but all of my machines are displaying "2024.01.11.1434" on the connect website. I suspect that reporting of this value has been broken since "2024.01.11.1434" or thereabouts (you have 2024.05.15.1138) and servers that have been setup with later plugin versions have never reported a value. Tried to check the repo https://github.com/unraid/api/ but it appears that its vanished from github (or maybe private all along, don't know)?
-
You did not install the dependencies for borgbackup. You need to also install msgpack-python, python3-pkgconfig, python-packaging, python-setuptools, python3 for borg to work. Repeat the process you noted for all of these packages and you should be good to go. And +1 for moving this to some other thread....
-
As a follow-up, this one disk eventually completely failed and no longer is recognized on multiple devices, despite spinning up. Removed splitters and re-did all the cabling. May have been the power, may have been bad luck. Thanks again.
-
Thank you two for the replies. That was my inclination as well, just wanted to see if I was missing anything in the logs. Will do some re-wiring and rebuild with the same disk for now. Will update with any additional events.
-
Hello Friends! One of my drives errored out today and, looking at the logs, it appears that it was around a power-retract event. Short SMART test passed and no SMART errors on the dashboard but some suspect things in the drive SMART logs (attached). Looking for advice on where to start - checking cables, change out PSU vs drive, or is there something I'm missing? Dec 11 09:19:37 Neo root: Fix Common Problems: Error: disk7 (WDC_WD120EMFZ-11A6JA0_X1G4PTEL) is disabled Dec 11 09:19:37 Neo root: Fix Common Problems: Error: disk7 (WDC_WD120EMFZ-11A6JA0_X1G4PTEL) has read errors Looking back at the logs: Dec 10 19:50:59 Neo emhttpd: read SMART /dev/sdd Dec 10 19:50:59 Neo emhttpd: read SMART /dev/sdc Dec 10 19:51:43 Neo kernel: sd 7:0:0:0: Power-on or device reset occurred Dec 10 20:07:15 Neo emhttpd: spinning down /dev/sdd Dec 10 20:07:15 Neo emhttpd: spinning down /dev/sdc Dec 10 20:51:10 Neo kernel: sd 7:0:0:0: Power-on or device reset occurred Dec 10 20:51:10 Neo emhttpd: read SMART /dev/sdd Dec 10 20:51:10 Neo emhttpd: read SMART /dev/sdc Dec 10 21:07:40 Neo emhttpd: spinning down /dev/sdd Dec 10 21:07:40 Neo emhttpd: spinning down /dev/sdc Dec 10 21:51:21 Neo emhttpd: read SMART /dev/sdd Dec 10 21:51:21 Neo emhttpd: read SMART /dev/sdc Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#458 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#458 Sense Key : 0x2 [current] Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#458 ASC=0x4 ASCQ=0x0 Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#458 CDB: opcode=0x35 35 00 00 00 00 00 00 00 00 00 Dec 10 21:52:02 Neo kernel: I/O error, dev sdd, sector 0 op 0x1:(WRITE) flags 0x800 phys_seg 0 prio class 2 Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#459 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#459 Sense Key : 0x2 [current] Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#459 ASC=0x4 ASCQ=0x0 Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#459 CDB: opcode=0x8a 8a 08 00 00 00 02 80 03 1a 88 00 00 00 08 00 00 Dec 10 21:52:02 Neo kernel: I/O error, dev sdd, sector 10737621640 op 0x1:(WRITE) flags 0x20800 phys_seg 1 prio class 2 Dec 10 21:52:02 Neo kernel: md: disk7 write error, sector=10737621576 Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#460 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#460 Sense Key : 0x2 [current] Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#460 ASC=0x4 ASCQ=0x0 Dec 10 21:52:02 Neo kernel: sd 7:0:0:0: [sdd] tag#460 CDB: opcode=0x88 88 00 00 00 00 02 80 03 1a 90 00 00 00 08 00 00 Dec 10 21:52:02 Neo kernel: I/O error, dev sdd, sector 10737621648 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 2 Dec 10 21:52:02 Neo kernel: md: disk7 read error, sector=10737621584 Dec 10 21:52:02 Neo emhttpd: read SMART /dev/sdj Dec 10 21:52:02 Neo emhttpd: read SMART /dev/sdk Dec 10 21:52:02 Neo emhttpd: read SMART /dev/sdh Dec 10 21:52:02 Neo emhttpd: read SMART /dev/sdg Dec 10 21:52:02 Neo emhttpd: read SMART /dev/sde Dec 10 21:52:02 Neo emhttpd: read SMART /dev/sdf Dec 10 21:52:02 Neo emhttpd: read SMART /dev/sdi Dec 10 21:52:12 Neo kernel: sd 7:0:0:0: Power-on or device reset occurred Dec 10 21:54:11 Neo kernel: mdcmd (50): set md_write_method 1 Dec 10 21:54:11 Neo kernel: In the drive SMART logs (attached), here are the things that stand out to me: Device Statistics (GP Log 0x04) Page Offset Size Value Flags Description 0x03 ===== = = === == Rotating Media Statistics (rev 1) == 0x03 0x028 4 10 --- Read Recovery Attempts 0x03 0x030 4 1 --- Number of Mechanical Start Failures The only only drive that has a non-zero Number of Mechanical Start Failures (also 1) is of the exact same model (and have been in another server before, so not certain how new it is). Thanks in advance! WDC_WD120EMFZ-11A6JA0_X1G4PTEL-2024-07-16 disk7 (sdd) - DISK_DSBL.txt
-
PSA: For the new HEVC Encoding Forum Preview, it appears you need to add back in NVIDIA_DRIVER_CAPABILITIES=all for things to work properly. The new preview looks like it needs to find a supported card before it shows you the new options and Plex does not log that it is recognized without using all (dockerfile include "compute,video,utility" as the default for this variable) I also wonder if this has ever always been the case, as my GPU name was not showing up in the drop down list for GPU selection until I added this in, despite hardware transcoding working perfectly!
-
Recommend way is to use the Replace the USB flash device procedure from the guide. When you do this, all of your current settings and shares will be preserved. If you want to start "fresh", then you'd use a brand new flash drive set up as new, boot the fresh drive and then use the "New Config" tool, reassigning all your drives to their proper assignments and selecting the "parity is already valid" checkbox. If you don't select the proper assignments though, there is risk of data loss here. Alternatively, you can set up a new USB drive and just copy the /config folder from your current drive, which should preserve your array and shares configuration as well. I would suggest using the method from the guide - what are you hoping to achieve by "starting fresh"?
-
Thanks for the information - I was not aware of the overly file system issue. Having said this, I've never had a problem in the past, so perhaps I'm just lucky. It would make sense if this was somehow integrated into the new update workflow in this case. There is no reason to overwrite the "previous" folder file as the intermediate version never was booted, so the previous should say as is. I suppose it could be tracked by comparing the versions between what is loaded and what is in the previous folder before copying over the current files.
-
Thanks itimpi - I am aware of the manual process, it's just nicer to hit a button 🙂 Maybe more of a suggestion for the new method as it matures further. For now, using the Update Assistant tool seems to work around this issue. Thanks
-
Hi All - I have one server that I hit the update button on but didn't reboot yet, and now there is a new version. Is there any way with the new upgrade workflow to complete a "double upgrade", meaning skipping an intermediate version if you previously hit upgrade and didn't reboot or if an upgrade came out shortly after starting an upgrade to the previous version? In the past, I could just use the update tool again to get to the current version prior to rebooting, but it appears that there is no easy way to do this "double upgrade" anymore. I now need to reboot to get to the intermediate version, then reboot a second time after updating again to get to latest (save manually doing the upgrade on the flash). Have we lost this ability to do this easily with the new enforced workflow? If so, any chance this could be address in future versions of the new update workflow? Or is this already possible and am I missing something? Thanks! EDIT - Looks like I was able to work around this for now by using the old update method. I use the Update Assistant which checked for a new version as part of it and then click on the banner notification at the top to update the server. Then it used the old update method to successfully complete it. Still, it would be nice to include this ability in the new update workflow instead.
-
Back to the post thread topic here - Is there any way with the new upgrade workflow to complete a "double upgrade". For example, I have one server that I hit the update button on but didn't reboot yet, and now there is a new version. In the past, I could just use the update tool again to get to the current version prior to rebooting, but it appears that there is no easy way to do this "double upgrade" anymore. I now need to reboot to get to the intermediate version, then reboot again to get to latest (save manually doing the upgrade on the flash). Any insights here or am I missing something? Thanks! Edit - for reference, I was able to get this done by using the old method, triggered by using the Update Assistant Tool, more discussion here. Perhaps this could incorporated into the new update workflow somehow by comparing the version in the previous folder to the running version and allowing a new update without overwriting the previous folder again during the upgrade.
-
For those that time machine backups are important, it does seem that the TimeMachine docker application works. It's not native and an additional step, but some appear to have found it useful
-
I just logged onto the forum to get some help with a 12TB drive I was adding to my array that wasn't formatting after pre-clear... If only that upgrade notification came earlier! Will report back if 6.11.3 doesn't solve the problem... Update - Formatting working as expected now. Thanks!
-
Oops, I guess that's what you get when you have multiple shells open and try in on a server on 6.10 by accident! 🙃
-
...and if you could add iperf3, that would be amazing as well 🙂
-
Requesting ddrescue! Thanks for this!
-
@shawnngtq @myusuf3 @troian @mykal.codes @wunyee @kavinci @cheesemarathon For the minio filesystem error, I resolved this by using directIO rather than shfs, which removes the fuse layer from the equation. The only downside is that you need to use a single disk. Rest of settings are default. /mnt/disk1/minio So far uploaded a couple of GBs without issue

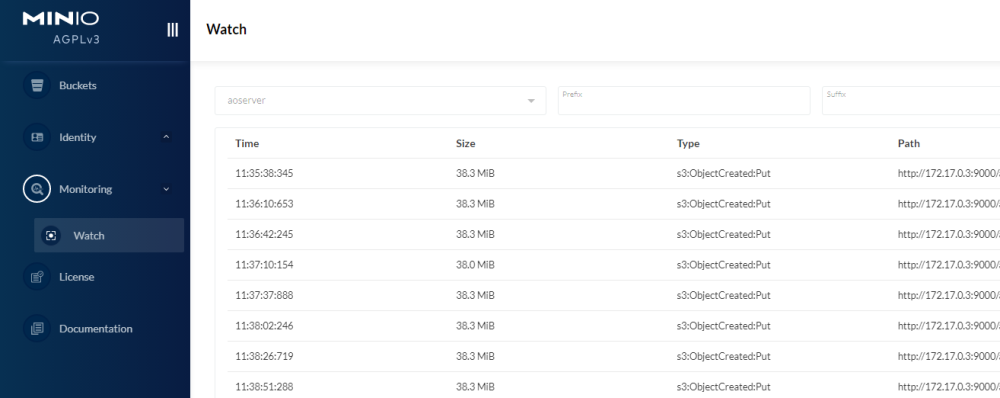
-
Welcome Eli!
-
Hard to do much with a 750 with 2GB. Options are something with a small DAG file size (UBIQ) or a coin without a DAG file, like TON. T-rex doesn't support either of those options, however.
-
You are correct - I was having a look while you were as well. Tag cuda10-latest works fine but 4.2 and latest give the autotune error My config had both lhr-autotune-interval and lhr-autotune-step-size set to "0", which are both invalid. I also don't use autotune but it was set to auto "-1" from the default config that I used. I set the following in my config to resolve it "lhr-autotune-interval" : "5:120", "lhr-autotune-mode" : "off", "lhr-autotune-step-size" : "0.1", For those that do use autotune, you should leave "lhr-autotune-mode" at "-1" Thanks for the update and having a look. Perhaps this will also help someone else 🙂
-
FYI, on latest tag just pushed, I'm now getting ERROR: Can't start T-Rex, LHR autotune increment interval must be positive Cheers!
-
This would be a really nice addition!
-
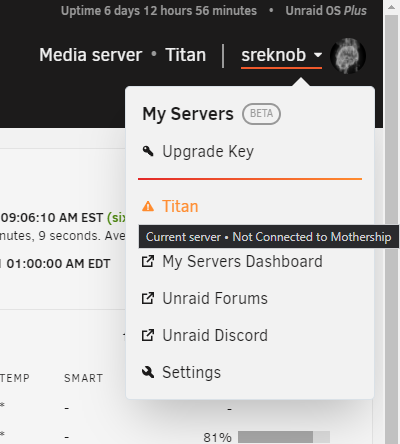
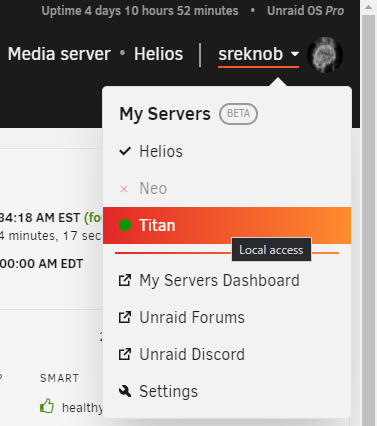
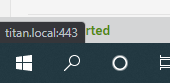
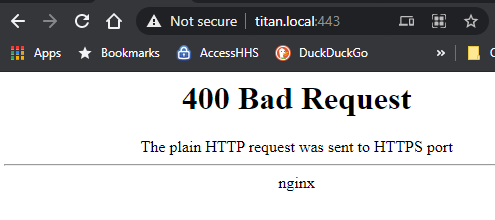
Having the same issue with on server not connected to the mothership, as The funny thing is that it is working from the "My Servers" webpage but when I try and launch it from another server, I have another problem. It tries to launch a webpage with HTTP (no S) to the local hostname at port 443 so I get a 400 (https to non https port --> http://titan.local:443) See the screenshots below and let me know if you want any more info! The menu on the other server shows all normal, but the link doesn't work like it should as noted above - launching http://titan.local:443 instead of https://hash.unraid.net So when I select that, I get a 400: but all launches well from the webui launching the hash.unraid.net properly! EDIT1: The mothership problem is fixed with a `unraid-api restart` on that server but not the incorrect address part. EDIT2: A restart of the API on the server providing the improper link out corrected the second issue - all working properly now. Something wasn't updating the newly provisioned link back to that server from the online API.
-
@limetech thanks so much for addressing some of the potential security concerns. I think that despite this, there still needs to be a BIG RED WARNING that port forwarding will expose your unRAID GUI to the general internet and also a BIG RED WARNING about the recommended complexity of your root password in this case. One way to facilitate this might be that you must enter your root password to turn on the remote webUI feature and/or have a password complexity meter and/or requirement met to do so. The fact that most people will think that they can access their server from their forum account might make them assume that this is the only way to access their webUI, rather than directly via their external IP. Having 2FA on the WebUI would be SUPER nice also 🙂 Yes, this is a little onerous, but probably what is required to keep a large volume of "my server has been hacked" posts happening around here...









