




comet424
Members
-
Joined
-
Last visited
Everything posted by comet424
-
i did check my other user scripts for backing up some i had rsync -avzue ssh --partial --append-verify --checksum --exclude rsync -avzue ssh --partial --append-verify --exclude rsync -avzue ssh --exclude rsync --protect-args -avu --stats --numeric-ids --progress now i dont truly understand all 4.. i was learning rysnc and using examples when i set this stuff up like 10 years ago and less so whatever was on google searchs for backup.. as i liked it better then the syncthing i didnt need to relie on a program to do it
-
@Kilrah ah ok ya i didnt record the times.. i know in the past when i rsync' it would go fast it would only do the files it didnt have and skip everything else.. now it seems there is "up to date" it says now before it never did all that stuff.. and just runs slower from saya couple years ago where there was not "up to date" display i just know when i didnt do the >> to export a log file in past it would zip through now it seems its going slow.. and i havent changed my rysnc user scripts just update unraid version but i noticed now there is "up to date" and the sender] expand file_list pointer array to 1024 bytes, did move trhat wasnt there in the past... i guess its just newer version of rsync and possible slower now from past versions? as for the script wouldnt know how to write it.. but this is home use not mission critical.. so i guess just regular rsync i have setup in user scrip good enough
-
and is there a option -whatever dash if rsync looses connection forwhatever reason not to exit out but to just resume.. or you gotta just wait for user script to run again as i do it nightly backup but if it craps out it wont finish till the next day. is there an option that tells it if it craps out wait and restart and resume
-
and is there a option -whatever dash if rsync looses connection forwhatever reason not to exit out but to just resume.. or you gotta just wait for user script to run again as i do it nightly backup but if it craps out it wont finish till the next day. is there an option that tells it if it craps out wait and restart and resume
-
ok so ill use the checksum every 6 months then. so you mean see how long it takes to use the checksum? so say if it takes 2 hours or more now... record that and do it again in 6 months and see if it takes longer or the same.. and how would it tell if there is a failing drive just by being slower?
-
@Kilrah ok that seems to speed it up more faster.. now as it was over an hour and still not done yet.. when do you want to have the checksum and when dont you want it?
-
so my rsync command line is rsync -avzue ssh --checksum --exclude-from='/boot/config/plugins/user.scripts/scripts/exclude1.txt' --protect-args -avue ssh --stats --numeric-ids --progress '/mnt/user/Family Files/' [email protected]:'/mnt/user/Backup_Tardis_Folders/Family Files/'and its always hanging used to be rsync would say increminting list. and then things would zip zip zip.. now it just hangs . all the time.. i dunno what its doing here is some of it its stuck.. !Home Videos/2019/boat engine issues still September/20190908_185100.mp4 is uptodate !Home Videos/2019/boat engine issues still September/20190910_145821.mp4 is uptodate !Home Videos/2019/boat engine issues still September/20190910_150014.mp4 is uptodate !Home Videos/2019/boat engine issues still September/20190910_150249.mp4 is uptodate !Home Videos/2019/boat engine issues still September/20190914_115630.mp4 is uptodate !Home Videos/2019/boat engine issues still September/20191004_120828.mp4 is uptodate [sender] expand file_list pointer array to 1024 bytes, did move [sender] expand file_list pointer array to 1024 bytes, did move [sender] expand file_list pointer array to 4096 bytes, did move [sender] expand file_list pointer array to 1024 bytes, did not move [sender] expand file_list pointer array to 4096 bytes, did not move is there a way to get rysnc to work like it worked a couple years ago where it just went fast ... like its just crazy
-
so i was copying a bunch of files from my windows machine nvme drive to the array folder and found it just slow only getting 20meg -50meg a sec so then i just deciided to copy from windows to a share on the cache drive that is just cache.. and i get 20-50 spikes at 130mb/s but if i copy from nvme windows to appdata folder which is a nvme also i getting 500+mb/s same files is there a test i can do if its the sata ssd wd 1tb drive the issue if its cuz its on a HBA card and its my pcie slots slowed down are there tests to see why its slow there?
-
@JorgeB ohy ok ya i had unpluged it as its hot swap did it show other errors why rsync and just windows copying desktop files to desktop files on the 2 server are crapping out so bad and just failing
-
so i been trying for a week to rysnc or use windows to copy from tardis server to backup server copying 5tb well it keeps crapping out now i getting messed up errors Jun 20 18:45:29 Tardis kernel: Buffer I/O error on dev sdj1, logical block 30708689, async page read Jun 20 18:45:29 Tardis ntfs-3g[17264]: ntfs_attr_pread_i: ntfs_pread failed: Input/output error Jun 20 18:45:29 Tardis ntfs-3g[17264]: Failed to read vcn 0x0 from inode 297: Input/output error Jun 20 18:45:29 Tardis kernel: Buffer I/O error on dev sdj1, logical block 30708689, async page read Jun 20 18:50:06 Tardis ntfs-3g[17264]: ntfs_attr_pread_i: ntfs_pread failed: Input/output error Jun 20 18:50:06 Tardis ntfs-3g[17264]: Failed to read index block: Input/output error what is going on? almost seems i need to go back to 6.9 i posted rsync issues and diagnostics but no one checked them to see whats going on not sure what i need to fix to be able to copy properly tardis-diagnostics-20260620-1903.zip backupserver-diagnostics-20260620-1903.zip
-
cuz even with windows copying the files are spinning through there is no disk activity on 2nd unraid server or main unraid... unless cuz the files are small files its just going through them fast. and not registering a speed.. as ive tried copying the same 4tb folder of my desktop files of computer backups and ive been trying last 4 days before i tried asking help on here any my logs are full of Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1 Jun 19 03:59:09 Tardis nginx: 2026/06/19 03:59:09 [error] 1409846#1409846: MEMSTORE:00: force-reaping msg with refcount 1which i constantly see alot of times and googling never helps it doesnt say what caused it and its copying tardis desktop files to backupserver desktop files tardis-diagnostics-20260619-0530.zip backupserver-diagnostics-20260619-0530.zip
-
im doing unraid to unraid rysncing so 7.3.1v to 7.3.1v i even finding if i do windows copy unraid share to 2nd unraid share it stalls out too the 4.5TB copy small copies seem fine but when you try to copy everything then it just craps itself it seems if i stop copying and restart the 4.5tb 1.6+ mil files i find it doesnt copy says it is the files keep running through the file names but nothing happening going to let it keep copyingg see if it catches up what it copied but since 7.3.1 things just seem a bit buggy here and there
-
i was usually have scripts update but i was doing a manual copy for a new share and i noticed i see now [sender] expand file_list pointer array to 4096 bytes, did move [sender] expand file_list pointer array to 1024 bytes, did move [sender] expand file_list pointer array to 4096 bytes, did move [sender] expand file_list pointer array to 16384 bytes, did move [sender] expand file_list pointer array to 32768 bytes, did move [sender] expand file_list pointer array to 65536 bytes, did not move [sender] expand file_list pointer array to 131072 bytes, did not move [sender] expand file_list pointer array to 262144 bytes, did move [sender] expand file_list pointer array to 524288 bytes, did move [sender] expand file_list pointer array to 1048576 bytes, did move [receiver] expand file_list pointer array to 524288 bytes, did move [generator] expand file_list pointer array to 524288 bytes, did moveor at end of the file says uptodate.. i find rsync locks up more now doesnt say incremently list i also got it hanging after 30 min run protocol incompatibility this is my code i use in a script i altered it for just command line test rsync -avzue ssh --exclude-from='/boot/config/plugins/user.scripts/scripts/exclude1.txt' --protect-args -avue ssh --stats --numeric-ids --progress '/mnt/user/Documents/' root@$serverip:'/mnt/user/Backup Files/Mikes Files/Documents/'so did things change? get more glitchty etc and or are some the rsync commands no longer used anymore?? and what is this sender, receiver, generator really meaning and this error constantly comes up after a while rsync error: protocol incompatibility (code 2) at receiver.c(358) [receiver=3.4.3] rsync: [sender] write error: Broken pipe (32) and if i keep running my command after so long it craps out with protocol data stream code 12 rsync error: error in rsync protocol data stream (code 12) at io.c(232) [generator=3.4.3] rsync: [sender] write error: Broken pipe (32) rsync error: error in rsync protocol data stream (code 12) at io.c(849) [sender=3.4.3] its like rysnc can no longer transfer 4 tb over 1 million files anymore its like it has a fit.. is there a way to fix it like it used to work fine since this is constantly broken and then the hard drives spin down and rysnc still running supposeldy saying uptodate or the other stuff and the drives arent even running and i running like less then 2 meg a sec copying has rsync busted in unraid 7.3.1 rsync error: protocol incompatibility (code 2) at receiver.c(358) [receiver=3.4.3] rsync: [sender] write error: Broken pipe (32)
-
@tshorts my repository is linuxserver/transmission you can try my setup minus the extra completed folder locations i made them 5 6 years ago or longer when i was learning transmission and the downlload location stuff
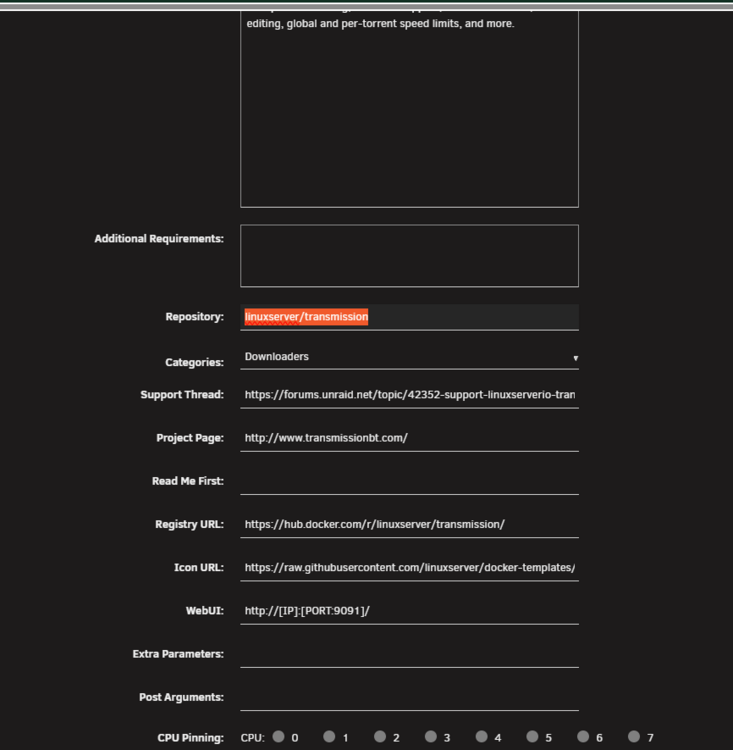
-
@tshorts i dont have a umask in the container maybe cuz i installed transmission like 5 6 years ago i only have UID GID so the 99 100 so i edited the transmission settings json and changed the umask in there so back then no umask in the container
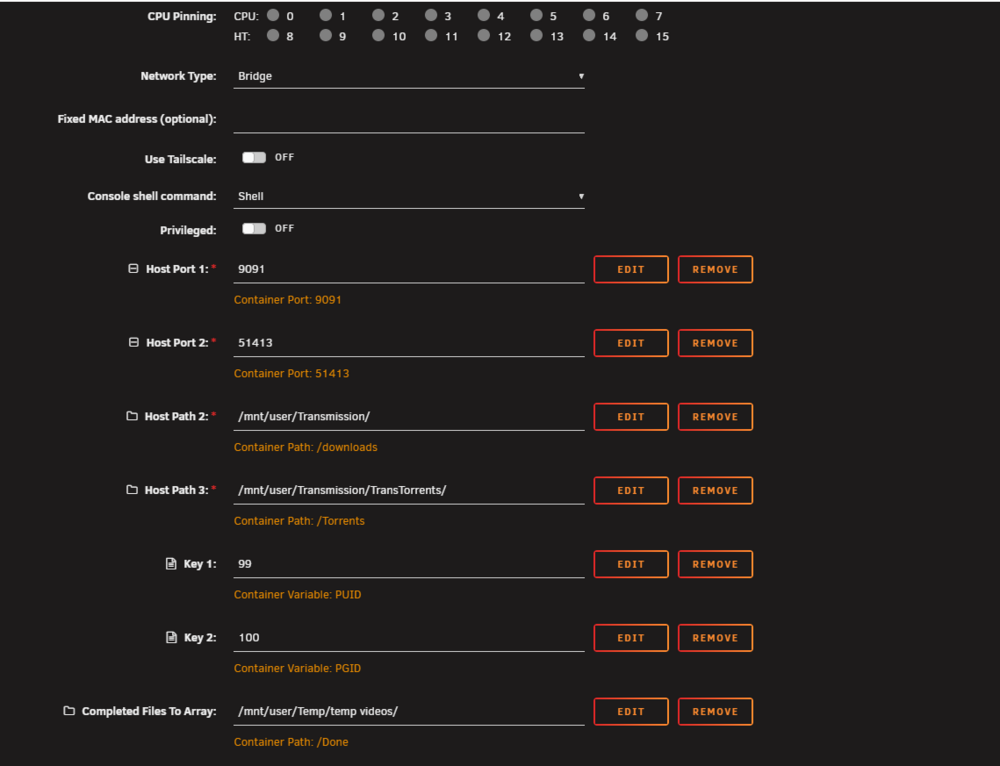
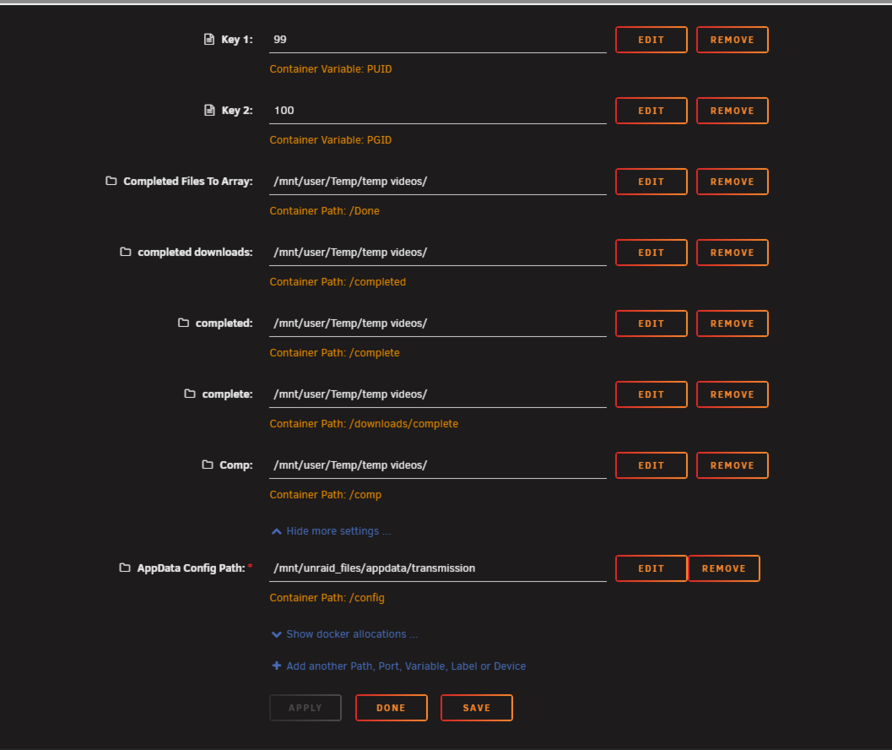
-
@tshorts whats working for me for now anyways is i stopped transmission i edited the settings file and changed umask from 022 to 000 i ran Tools/New Permissions on the drive or location of the transmission incomplete files let it finish then run transmission and that seems to be working now that worked for me i not sure if works for you but if you try it in that order maybe it works for ya and time will tell if i get that 644 permission but stay at 666
-
@Frank1940 ya edit no good cuz like the program Caddy,, you gotta edit the configuration file under appdata/caddy well you cant edit it with the notepad ,, as you cant save always tells you to save a different file as you cant save so you gotta nano the configuration file so Edit is for the Docker container template but u still gotta edit the configuration file same with Plex and Jellyfin or autheli Authelia you gotta modify the json or the settings.xml file and they usually write protected so i have to nano edit them.. and notepad is better easier to edit.. and i tried your goto the console to be able to edit a configuration file.. but there is no "nano" in console of the dockers but i hear ya u dont wanna bugger up the container i just figured if you new permission it to nobody with the lowest that anyone can edit even if the container had higher write access or what not it wouldnt harm it? but like you already know i dont really know that much iabout the permissions i just figured if you reset all them to a lower restriction the user with the higher access not going to ruin it cuz its like same user or less security sorry my dislexia may messed up my explanation sorry in advance.. but always learning something new everyday... that when your modify the container your hacking it..
-
from the one site i read i guess nobody is the lowest secure so basiclly i guess its like public access like for sharess public secure private and the 99 100 is the low level nobody account that anyone should be able to access and the 22 umask supposed to give the default access something like that i did post in the transmission forums to see why it glitchs and gets the 644 but who knows if i get answer but i asked
-
@Frank1940 ah ok ya i guess i get frustrated too like some of the apps you gotta alter the configuration file after you install.. and when i access file from windows accessing the appdata i cant i dont have write all i can do is that darn nano and its not as nice as note pad... and that frustrates me but i guess the root has the nobody has writes over everything universal god mod.. as i also find sometimes i cant delete an appdata folder app in windows or krusdader.. i found if i run rm -r <container name> is the only time i can delete something as i uninstall apps and try to get rid of the old stuff.. so i found that is frustrating too.. so how does it break some cointainers if you make appdata all nobodys god mode.. as if you have a different owner wouldnt it just go along with nobody user.. i dunno i dont understand this linux stuff my linux days stopped 25 years ago with redhat 5 and i i had to do tricks just do mount a cdrom in the gui i got fed up and stuck with windows.. and then when i out grew windows home server 2003 and 2011 and ms doesnt make home server os anymore... so i found unraid but still learning.. ill look for more offical thats what i usally install... what drives me nuts too if there ins a app and there is 4 version one says offical, another says linuxserver, another says tools and one other i saw like i never know what one to install be nice not to have dupes,, especially with the info text is the exact same across the 4 types.. so you never know what to install... like the krusader there is like 2 or 3 but you trully never know what to install madding at times
-
is there a work around or reason why transmission even though its 99 100 uid pig and the umask is 022 that sometimes transmission cant move files off the download drive to the array permission denied or when it does i loose right to alter the file i get 644 permission or some files 777 766 755 666 but the 644 i cant change... why does transmission do it? or is there a work around other then the new permissions? but is there a variable i need to add.. this is been going on for serveral years i just keep doing new permissions but its getting dumb i gotta do it... is there something i need to alter? so it works fine everytime and not when it decides to do... frig who knows if its when transmission updates...
-
is there a work around or reason why transmission even though its 99 100 uid pig and the umask is 022 that sometimes transmission cant move files off the download drive to the array permission denied or when it does i loose right to alter the file i get 644 permission or some files 777 766 755 666 but the 644 i cant change... why does transmission do it? or is there a work around other then the new permissions? but is there a variable i need to add.. this is been going on for serveral years i just keep doing new permissions but its getting dumb i gotta do it... is there something i need to alter? so it works fine everytime and not when it decides to do... frig who knows if its when transmission updates...
-
@Frank1940 ya thats what i normally do is set the new permissions so ya i read you dont wanna use the new permissions on appdata.. i have done that in the past as i wasnt able to delete certain folders unless i was using like krusader or midnight commander... its frustrating ... and why dont you want to use new permissions on all the the folders really... if we are only doing users with certain read write access to the specific shares it shouldnt matter right? so i guess the only work around is user script that runs like twice a day or so that does new permissions on shares so it doesnt mess stuff up? and what is the reason you really dont wanna run new permissions on the appdata... dont you want everything to be nobody.. so you mentioned "nobody" is an assigned user... do you mean under users they made a user account nobody... and if so is that some kind of work around i appreciate your help so far it is frustrating with these permissions etc..as you think jus copy a file or move and its just how it is as i been a windows user for 40 years and you never needed to deal with permissions really sure you had in the properties of a file but really copy and paste or what not and boom bobs your uncle lol i see the transmission support page is on unraid site so ill ask there for help too..
-
@Frank1940 with my dyslexia and learning disabilityi have to re read those 2 links i read the first one a bit and ya brain not functioniing to understand it fully yet and ya most of the or all my shares are private and i got 1 public share,, and some shares that are - dash i guessing thats because i dont export it so basiclly unraid has gone a different route for permissions then basic linux permissions from how i understanding what you were saying and how do you know if a docker container for unraid is perpared for unraid... is there something i can fix transmission or the krusder or windows that prevents messed up permissions? i like the permissions of the users they can get read write for this share or that share.. so is there a way to mod transmission to change the 644? and what is the permission should be fore files? since the files are 644 and i cant alter them.. but it doesnt do it to all the files transmission downloads.. its like hit and miss when you can alter the files why is it hit and miss? so is there something i can add to transmission docker to fix the issue? so regular linux uses 755 and 644 so what does unraid or windows use when we copy to unraid from windows
-
and if you copy from windows to a folder on the array should that be all access? as i noticed some of the files i either copy from hot swap ssd in my array but i move off the drive and onto the array using windows i just have a auto share on it gets a different permission and i guess if i use a move in unraid file manager that be a different permission and if i use krusader thats a different permission?
-
i googled what 022 means anyone can read or run them i guess but only the owner can modify it but if the owner is 00 100 supposedly thats nobody.. then eitehr nobody can modify it or its anyone can modify it.. these permissions stuff drives me nuts sometimes