




PitRejection2359
Members
-
Joined
-
Last visited
Everything posted by PitRejection2359
-
reboot fixed it - thanks very much - I was starting to get worried!
-
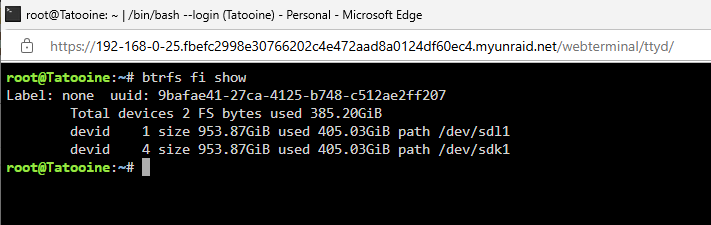
thanks. output and full diagnostics attached tatooine-diagnostics-20250412-1326.zip
-
Hi @JorgeB, I think I did everything as per the above steps, but after creating the new pool and adding the 2 1TB SSDs, then restarting the array, I get the error that: "Unmountable: unsupported or no file system". I tried swapping the 2 cahce drive into position 1 and 2 to see if that helped, but got the same result. I've attached the syslog here as well.
-
thank you so much - I've no idea how I managed to change that!
-
192.168.0.3
-
Hi @binhex, I have recently had my VPN go wibble; I was using an openvpn config file that worked fine for ages but just started getting errors about AES-256-CBC cipher. I've had this before and managed to fix it with a new config file, but thought it would be a good time to switch to Wireguard. So I created the new wireguard config file, changed the config in unraid, uploaded my config file, and rebooted the Deluge docker follwinf the instructions at Q21 here. The logs see to show the wireguard connects fine and it loads the GUI according to the logs (attached below). However, I can't access the GUI from my within my network - it just times out. I suspect I need to change a variable in the unraid docler config, but I'm not sure which. Screengrab of me setup attached too. Any help much appreciated! Unraid Binhex Deluge Load Log.txt
-
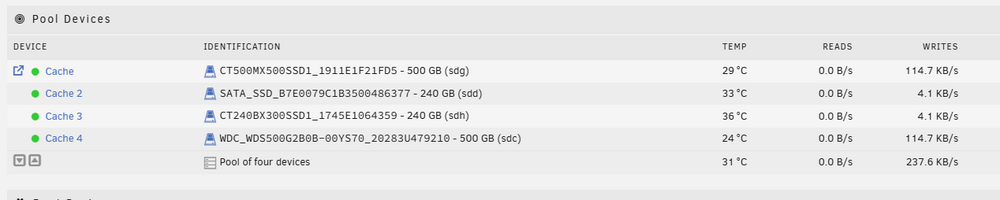
Hi @JorgeB, So I've been away from my server for a few weeks, and now back and ready to proceed, albeit a little nervous! I think I've mapped out all the steps needed, in sequence, using the drive info for my cache as set up in the image below: Steps to Follow (combination of your instructions above and the linked Docs): Turn off Docker & VMs Replace the first disk (sdd / Cache 2) Stop the array. (optional) Physically detach the disk from your system you wish to remove. Attach the replacement disk (must be equal to or larger than the disk being replaced). Refresh the Unraid WebGUI when under the Main tab. Select the pool slot that previously was set to the old disk and assign the new disk to the slot. Start the array. Device replacement will start automatically. Turn off Docker & VMs Replace second disk (sdh / Cache 3) Stop the array. (optional) Physically detach the disk from your system you wish to remove. Attach the replacement disk (must be equal to or larger than the disk being replaced). Refresh the Unraid WebGUI when under the Main tab. Select the pool slot that previously was set to the old disk and assign the new disk to the slot. Start the array. Device replacement will start automatically. Remove unnecessary disk 1 (sdg / Cache) With the array running type on the console: btrfs device remove /dev/sdg1 /mnt/cache Remove unnecessary disk 2 (sdc / Cache 4) With the array running type on the console: btrfs device remove /dev/sdc1 /mnt/cache Turn off Docker & VMs Import the 2 remaining new disks into the pool on main click on the first device for that pool and then "remove pool" back on main, create a new pool with the same name and two slots assign the pool devices, leave the filesystem set to auto start the array to import the pool Hopefully that's right and has everything I need to do...! Many thanks.
-
OK, thanks - I'll give that a go then. Cheers!
-
OK, I'm back at my server and about to start this, but I don't quite understand the instructions above, sorry! To go from the 4 old SSDs currently in the cache to 2 new SSDs and copy all the cache data to the new disks, do I just do the 4 steps above, or do I need to do anything else as well? Thanks.
-
Thanks @JorgeB - I'm glad I checked! I'm now away from my server for a few days due to work, so I'll take a look when I'm back and see if I can complete the upgrade. Is there an easy way to completely back up the cache data to the array (not move, but back up)?
-
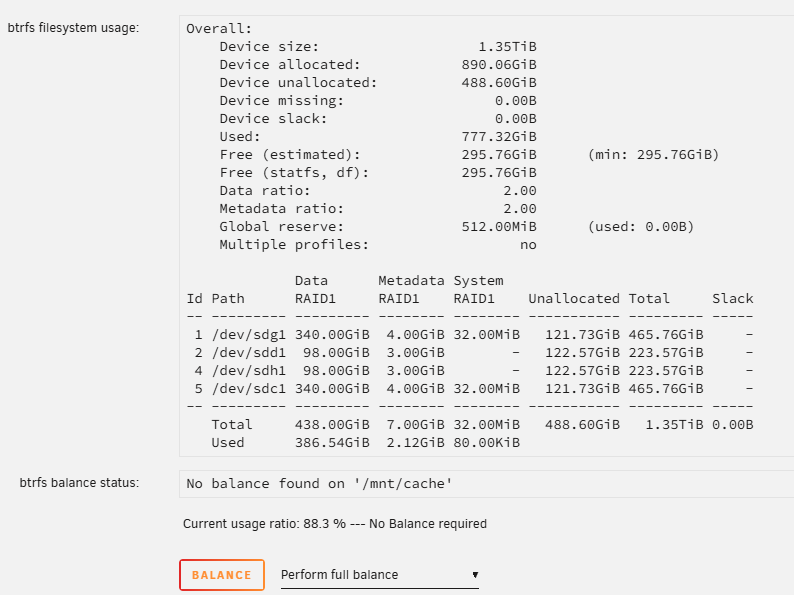
Hi - I've seen a few posts on this but they all refer to version 6.X, so I just want to check what the recommended process is for version 7.0.0. I have a cache pool with 4 drives (2 x 240 GB and 2 x 500 GB) in it using BTRFS in RAID 1. I have 2 new 1TB drives, and want to replace the 4 existing ones. I can see that I can replace 1 drive at a time in the pool and letting the system rebuild after each replacement using the GUI, and I then end up with the 2 new drives, as well as 2 of the old drives. I'm then not sure exactly how to remove the remaining 2 drives. Do i: Remove 1 of them, balance / let it rebuild, then remove the last? This is in the manual here, as long as metadata is turned on (which I think I have - see screenshot below). Use the CLE methos as described in the manual here, which I'd prefer not to do if I can help it. Thanks in advance! I think I have metadata turned on in RAID 1:
-
me too - it seems to show the opposite on my system too!
-
Did you ever find an answer to this? I have a windows 10 VM I've been using intermittently for a few years which has worked fine, which has suddenly started doing this since using it in the last few weeks.
-
Yeah, as far as I'm aware, they're all good and healthy! Thank you.
-
That would be amazing - thank you in advance!
-
Hi - as per the title, I need to remove 3 empty drives from my array. I have used the unbalanced plugin to move data around after purchasing some new disks and now want to remove the older unused disks for another project / use. Having read the docs and a few posts, I think the quickest way (with a small amount of risk) will be to use the first method in the docs: "remove drives then rebuild", i.e. stop the array, remove the 3 disks, re-start the array using the "retain current config" option, then let it rebuild the parity drive. Am I reading it all right - is there anything else I need to consider?
-
Hi @jbrodriguez I'm loving the app - I think its really useful. I have a feature request: would it be possible to add a delay / timer / scheduler to start the move at a specific time in the future? I'd like to be able to set it to start at, for example, 0300 when my mover, and backup tasks have all finished, do it can do all the moves without other disk actions? Thanks for all the work!
-
bump too! I think this would be a very useful feature. It would be particularly useful to be able to load a few dockers to help resolve issues when disks / arrays fail, such as SMART tools, unbalanced, Krusader, etc, etc.
-
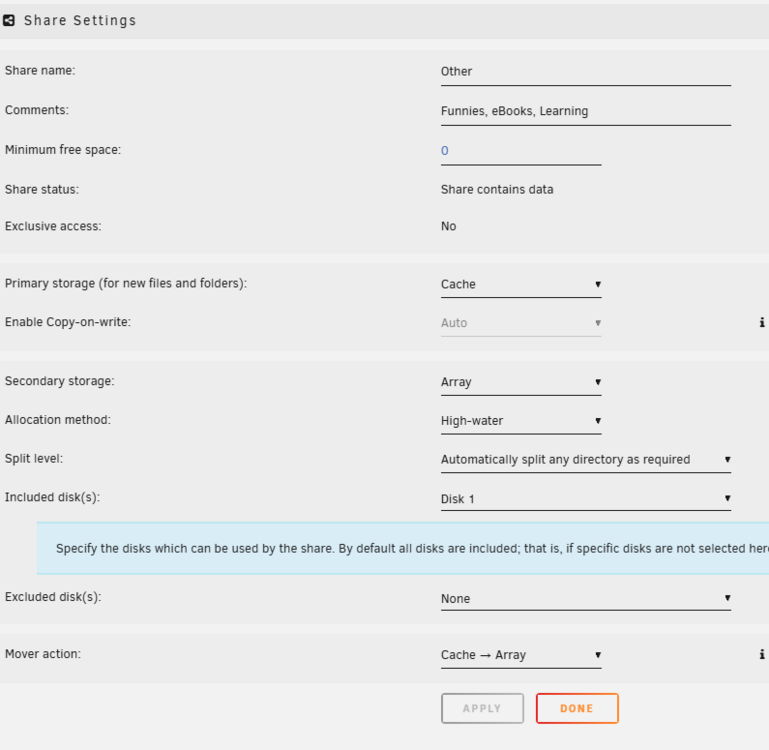
Hi, I'm thinking about using unbalanced to help redistribute and manage my shares. Currently, they are split across 4 disks, and I'm trying to move them back to 2. I'm currently using the "included disks" option on the shares to exclusively have each share on a specific disk. current example of 1 of the shares: If I want to use unbalanced, should I reset all the shares back to the default settings before starting to use unbalanced, or will it overwrite these settings itself? Thanks!
-
I think this would be another great feature to add, if you could! Thanks in Advance!
-
Thanks - I recognised that was there but wasn't sure of the decode, so I'll see if that helps me ID / track all of my disks. I still think it would be great to add custom fields, for whatever we want; I've recent added SMR / CMR to the single comment field, but would be great to add multiple custom fields as required. Thanks and keep up the great work!
-
Thanks - that's a good headmark to work to. Fair one - that at least sets expectations!
-
Hi - I have ben using disk location for while and really like it. Is there any way to add additional columns to the sets of tables? For example, the main user editable field is "Comment" which I use for some information for each disk. I'd love to be able to add additional tables / columns with any title I need. Such as "Connected Controller", "Contoller Port Number", etc, etc. Is there any way to do this, or any way you could implement it in the future? Thanks,
-
This is very interesting: do you have any rough idea when "the near future" is likely to be?! Thanks,
-
Thanks for all the replies. Given all the info, for my particular use case I want to be able to make maximum advantage of the unraid usage efficiency of different sized drives, I can't see a way ahead in Unraid to achieve it with SSDs. Until such a time as ZFS allows 100% usage of drives of different sizes (which seems very unlikely to ever happen), or Unraid develops a way to allow TRIM with SSDs in an array with parity, then I'm going to have to stick to either 1. spinning disks of different sizes with parity, or 2. purchasing same-sized SSD drives for ZFS redundancy, or 3. BTRFS with SSDs of different sizes (effectively RAID 1, which is not as efficient use of space and against the main premise of me using unraid arrays with parity protection). Unless I've completely mis-understood it....!







