



almulder
Members
-
Joined
-
Last visited
Everything posted by almulder
-
@SimonF any luck getting it to show booting and array starting and such before its fully up and running?
-
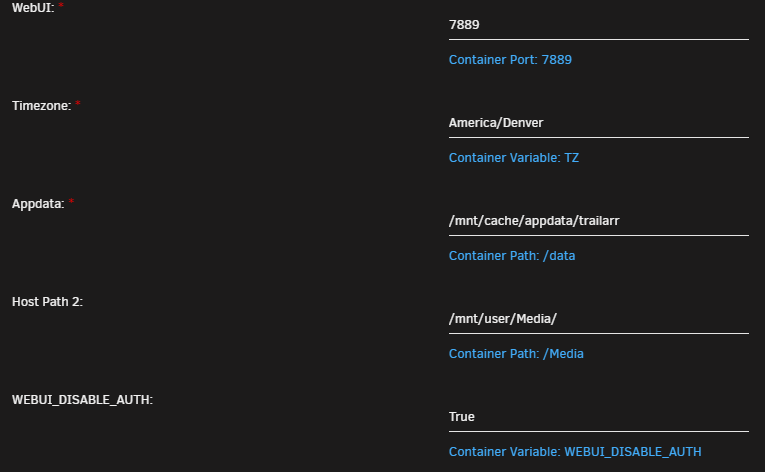
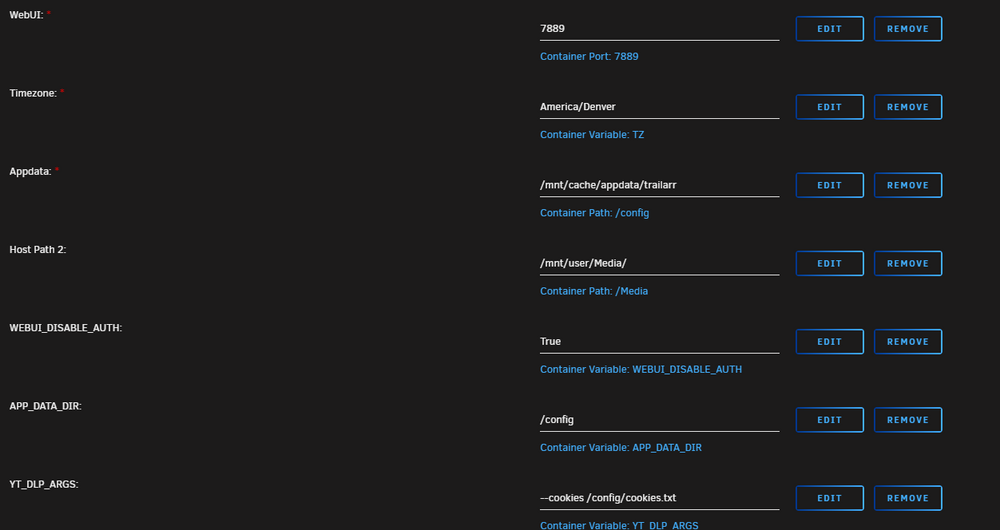
yes that does do it. myabe you can help with one more. i am getting Some trailers will not download, in the log it says "Sign in to confirm your age. " So i looked into how to export my cookies as load then into the docker, but they never seem to take (Exported them from firefox using ym per their github) see my updated screenshots above. Also the docker defaulted to /mnt/docker_v/appdata/trailarr/, it should be defaulting to /mnt/user/appdata/trailarr
-
Need help with Trailarr. I have it setup as follows: No config files are ever saved at the app data location. The app will work, but if it gets shutdown and restarted, it looses all info. and I have to resetup everything. this happens every time. I don't belive it was setup corectly since it will not save the config info. Please help! Update: Ok I have it saving the files, but it will not download videos. here is my config: I get this error: Exception: ERROR: [youtube] 8Zv7wd1a-5A: Sign in to confirm you’re not a bot. Use --cookies-from-browser or --cookies for the authentication. See https://github.com/yt-dlp/yt-dlp/wiki/FAQ#how-do-i-pass-cookies-to-yt-dlp for how to manually pass cookies. Also see https://github.com/yt-dlp/yt-dlp/wiki/Extractors#exporting-youtube-cookies for tips on effectively exporting YouTube cookies I logged into youtube via firefox and exported my cookies and addded them into trailarr, but continue to get the error.
-
system says there is an update to "Fix Common Problems" Installed Version2024.12.04 Upgrade Version2024.12.19a but when I run the update i get this message: plugin: updating: fix.common.problems.plg Executing hook script: pre_plugin_checks +============================================================================== | Skipping package fix.common.problems-2024.12.04-x86_64-1 (already installed) +============================================================================== ---------------------------------------------------- fix.common.problems has been installed. Copyright 2016-2024, Andrew Zawadzki Version: 2024.12.04 ---------------------------------------------------- plugin: fix.common.problems.plg updated Executing hook script: gui_search_post_hook.sh Executing hook script: post_plugin_checks Just wanted to make you aware as I am sure a line of code was missed.
-
I might just look into using user scripts to make a backup of what is needed i nexcloud-aio so I dont backup useless stuff.
-
So what is the best way to get Nextcloud-aio to backup and restart properly. I have been trying appdata backup but it seems to have issue and all the sub containers dont work after Nextcloud-aio-mastercontainer is backed and restarted, I have to go into the GUI and tell it to restart them. Not sure what I am missing. thoughs
-
yes the nvme is passed through from the IOMMU, But all the times I have been doing this, I never noticed the boot order section, I was always doing it in the bios. did it here and now it works flawlessly thanks
-
can you clarify what you mean
-
So I have my stuff setup for passthrough, but what is the proper way to setup for windows 11 to be able to boot from the NVME as a standard drive not a img on the nvme. I have installed, but then windows never reboots to the nvme. I have to manualy select it in the vm bios. I have nuked everything a few times retrying. i have looked at a few videos but no luck. please help.
-
anyone?
-
nic2 is passed through to VM2, VM1 shares nic1 with unraid and uses the vitrio driver.
-
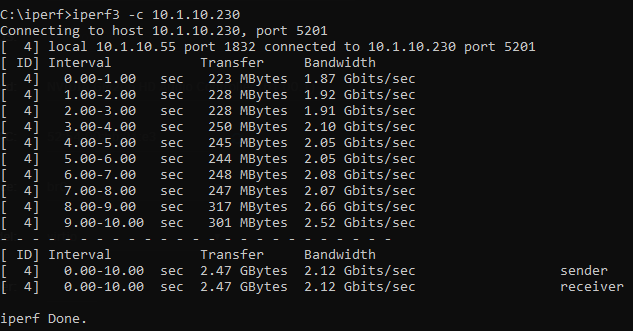
So I have a Pro WS WRX80E-SAGE SE that has 2 10GB nic's One is passed through to a VM (Connected to a switch at 1GB) and the other is used for unraid and shared to a different VM (And this nic is connected via a 10GB switch and shows "10000 Mbps, full duplex, mtu 1500" so its connected 10GB however my VM is only getting 2GB when testing using iperf3 The VM is using virtio and in windows set jumbo frames to 9014. Any idea how to get the full 10GB speed between them?
-
anyone else have issues with the UPS plugin not working?
-
So I have a Minutman E1000RTXL2U UPS and it was working, I got a second one and was going to use that and have unraid monitor that one instead, put in the info and is never populates, changed it back to the original and now that one does not populate. Anyone else have this issue? (they both had different IP address, so that is not the issue, Even removed the second one from the network, same issue)
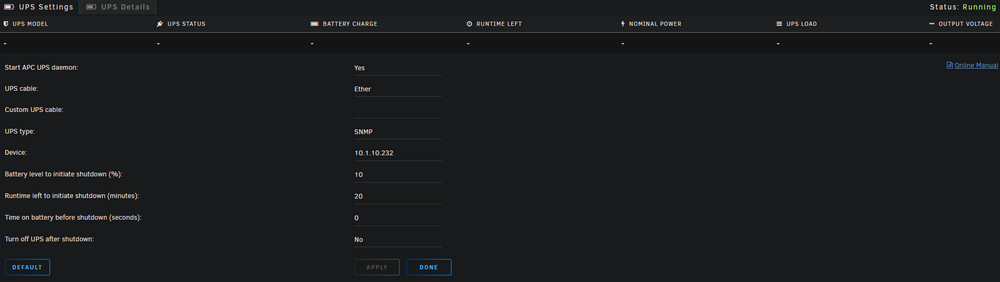
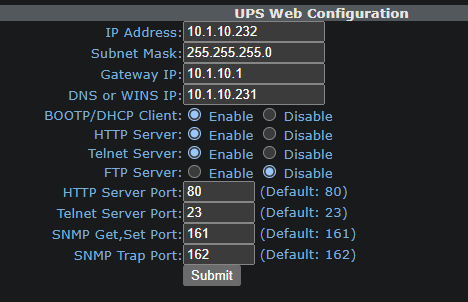
-
The issue has gone away. I did nothing (6.12.8)
-
Bump!
-
I currently have two VMs running Windows 11 on separate pass-through hardware configurations. One of these VMs, dedicated for personal use, operates without any issues. However, the other VM, which I primarily use for work, encounters occasional problems. Both VMs utilize different NVME drives as their primary storage (with Windows installed directly rather than on a virtual disk). The hardware pass-through for both VMs includes USB ports, NVME storage (designated as 😄 drives), and dedicated graphics cards. While the personal VM functions smoothly, the work VM occasionally experiences lock-ups over the weekend, requiring a forced stop instead of a simple reset. Upon attempting to restart the work VM, I encounter an error message. The only effective solution I've found is to shut down the entire server, as rebooting alone leads to an IOMU error persisting on the device. After a complete server shutdown and subsequent restart, the work VM functions again. I've attempted troubleshooting by swapping the NVME drives location between the personal and work VMs, as well as realigning the IOMU allocation in the VM settings. However, these efforts haven't resolved the issue, indicating it's not related to the NVME port allocation. Even after cloning the NVME drive and installing it anew, the problem persists, ruling out a fault with the NVME drive itself. Both VMs share identical power settings within Windows, with all peripherals configured to remain active and prevent sleep mode. Despite these measures, the issue persists, particularly noticeable during periods of VM inactivity over weekends. I suspect the problem lies either with Unraid or within the Windows environment, but I've been unable to pinpoint the exact cause. I'm reaching out here in hopes that someone might offer insights or suggestions toward resolving this perplexing issue.
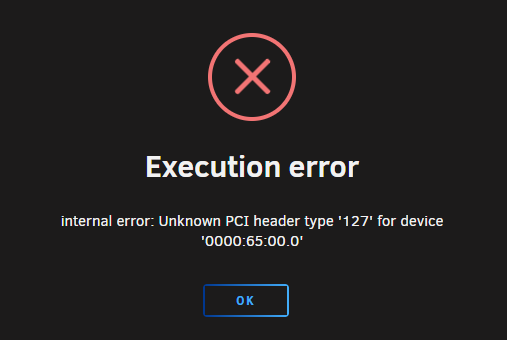

-
@SimonF So I have my QNAP TVS-871 and running the plugin and seems to work. My question is this: Is there a way to completely customize the screen? Like I want to enable it during boot and have it say something like loading Loading Unraid..., then once loaded change to Array Stooped, then once Array is started say Array Loading. then once loaded say Array Loaded. then wait 10 seconds and show IP address then after 10 mins turn screen off, if button is pressed (the 2 buttons on qnap) the turn display on and show x if button is pressed again show y, if pressed again show z ect... I am thinking something along the lines of user scripts to control the screen once loaded if possible?? Is this even possible? Also Thanks form getting this far. It was annoying to see the screen never update to anything until now. Note: That on the setting page in unraid you have the "Online Manual" link still back to the APC UPS Manual. maybe update to bring you to this thread? I changed line 66 of the 'LCDSettings.page' to this <span style="float:right;margin-right:10px"><a href="https://forums.unraid.net/topic/136952-plugin-lcd_manager/" target="_blank" title="_(UNRAID Forums: [PLUGIN] LCD_MANAGER)_"><i class="fa fa-file-text-o"></i> <u>_(Unraid Plugin Forum)_</u></a></span> and now looks like this: I also updated the ICON to be more inline with UNRAID Icons (Attached if you want to use)


-
I don't have drives spin down. So that's not the issue. Other thoughts?
-
SO I have my trusty qnap TS-871 and have unraid (Current version) running on it. I never get crc errors on spinning drives, but I have 5 SSD's I have tested 2 brand new and they all throw CRC errors. Did a pre Clear and still got CRC errors. But if I replace them with a spinning disk I get no issues. My other server also hates SSD's. So my question is this. Does unraid hate SSD's (Also my NVME's are fine) Seems like almost anyone I know who uses SSD's get CRC errors. Just seems odd (atleast 10 people)
-
So I just updated for 6.12.6 to 6.12.8, and now when I run or resume a parity check the GUI locks up especially the Dashboard Tab. If I am on any other tab then they work, but if I click the Dashboard tab then it does not populate, if I then click on main (Or any other tab), it take like 2 mins for that tab to populate, but once it populates I can click on any tab without issue (Except the Dashboard Tab) If I stop the parity check or pause the parity check, and wait 5 mins then all tabs work without delay. This was not a issue on 6.12.6. (Friend having the same issue) and it is not a low spec PC. Specs: Motherboard: WRX80E-SAGE SE WIFI CPU: Threadripper Pro 5975WX 32-Core Ram: 512GB ECC DDR4
-
So I just downloaded and installed the docker, can you elaborate on the settings you show and where I enter in the info? And are you just using you external IP address or using an cname?
-
Can someone make this a community application. It's toncomplicated for most and I have a few people who would love to install but they would have no clue how to set it up. So hopefully someone here can make it into a community app. https://community.hubitat.com/t/guide-echo-speaks-server-on-docker-or-without/111186?u=steve.maddigan&fbclid=IwAR17n7Dcs_O1FbCDP0sKgknIP1GkXXCjJvn8OZueH1XPCnagyTHLHswzx9I
-
So I have my UPS do weekly test for 10 seconds, when it does it triggers an email that its on battery, but does not send that its back on main. The test is very short and looking at the logs its happens so fast it only sends the one email. Is there a way to set a time that it must be on batteries before sending notification, something like 15-30 seconds? Oct 9 11:05:08 HuskyServer apcupsd[12213]: Power failure. Oct 9 11:05:14 HuskyServer apcupsd[12213]: Running on UPS batteries. Oct 9 11:05:14 HuskyServer apcupsd[12213]: Mains returned. No longer on UPS batteries. Oct 9 11:05:14 HuskyServer apcupsd[12213]: Power is back. UPS running on mains. Oct 9 11:05:14 HuskyServer sSMTP[23651]: Creating SSL connection to host Oct 9 11:05:14 HuskyServer sSMTP[23651]: SSL connection using TLS_AES_256_GCM_SHA384 Oct 9 11:05:17 HuskyServer sSMTP[23651]: Sent mail for ***********@gmail.com (221 2.0.0 closing connection x14-20020aa784ce000000b0068fb5e44827sm6553524pfn.67 - gsmtp) uid=0 username=****** outbytes=778 Also what is an android free push notification that works best with the unraid agents? I see several option but wonder what one is free.
-
got my new server up and running and reinstalled, however I am unable to access GUI. Looking at the log I see this error: (Token removed from my post) 2023-10-02 16:49:15,300 DEBG 'start-script' stdout output: [warn] Unable to successfully download PIA json payload from URL 'https://10.10.112.1:19999/getSignature' using token It tries this 10 times and then stops and never connects. Never had an issue on old server.











